La méthode de descente coordonnée est l'une des méthodes les plus simples d'optimisation multidimensionnelle et fait un bon travail pour trouver un minimum local de fonctions avec une topographie relativement lisse, il est donc préférable de commencer à vous familiariser avec les méthodes d'optimisation.
La recherche de l'extremum s'effectue dans la direction des axes de coordonnées, c'est-à-dire pendant le processus de recherche, une seule coordonnée est modifiée. Ainsi, le problème multidimensionnel est réduit à unidimensionnel.
Algorithme
Premier cycle:
- , , , ..., .
- Recherche de fonctions extremum . Mettre l'extremum de la fonction au point .
- , , , ..., . Fonction Extremum est égal à
- ...
- , , , ..., .
À la suite de l'exécution de n étapes, un nouveau point d'approche de l'extremum a été trouvé . Ensuite, nous vérifions le critère de fin de compte: s'il est rempli, la solution est trouvée, sinon nous effectuons un cycle de plus.
La préparation
Vérifiez les versions du package:
(v1.1) pkg> status Status `C:\Users\User\.julia\environments\v1.1\Project.toml` [336ed68f] CSV v0.4.3 [a93c6f00] DataFrames v0.17.1 [7073ff75] IJulia v1.16.0 [47be7bcc] ORCA v0.2.1 [58dd65bb] Plotly v0.2.0 [f0f68f2c] PlotlyJS v0.12.3 [91a5bcdd] Plots v0.23.0 [ce6b1742] RDatasets v0.6.1 [90137ffa] StaticArrays v0.10.2 [8bb1440f] DelimitedFiles [10745b16] Statistics
Nous définissons une fonction pour dessiner les lignes de surface ou de niveau dans laquelle il serait pratique d'ajuster les limites du graphique:
using Plots plotly()
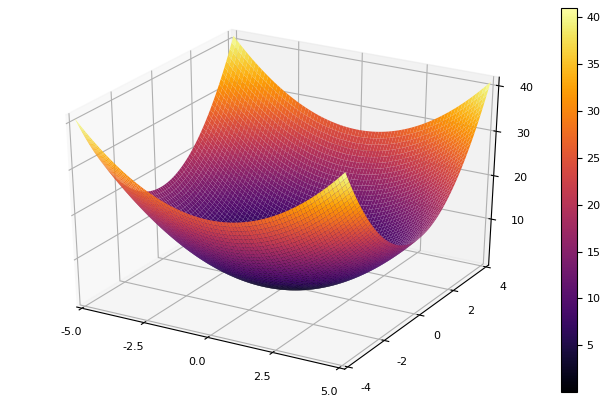
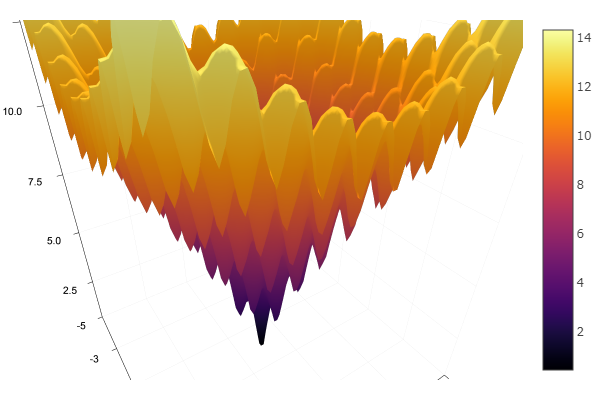
En tant que fonction modèle, nous choisissons un paraboloïde elliptique
parabol(x) = sum(u->u*u, x) fun = parabol plotter(surface, low = [-1 -1], up = [1 1])
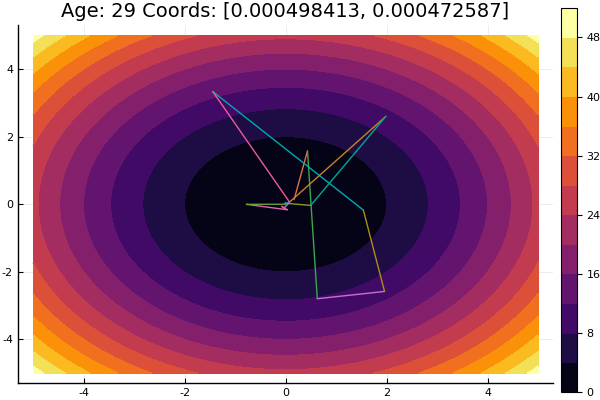
Descente coordonnée
Nous implémentons la méthode dans une fonction qui prend le nom de la méthode d'optimisation unidimensionnelle, la dimension du problème, l'erreur souhaitée, l'approximation initiale et les restrictions pour tracer des lignes de niveau. Tous les paramètres sont définis sur les valeurs par défaut.
function ofDescent(odm; ndimes = 2, ε = 1e-4, fit = [.5 .5], low = [-1 -1], up = [1 1]) k = 1
Ensuite, nous allons essayer différentes méthodes d'optimisation unidimensionnelle.
La méthode de Newton
L'idée de la méthode est simple tout comme l'implémentation

Newton est assez exigeant sur l'approximation initiale, et sans limitation sur les marches, il peut facilement rouler à des distances inconnues. Le calcul de la dérivée est souhaitable, mais vous pouvez vous en tirer avec une petite variation. Nous modifions notre fonction:
function newton(i, fit, ϵ) k = 1 oldfit = Inf x = [] y = [] push!(x, fit[1]) push!(y, fit[2]) while ( abs(oldfit - fit[i]) > ϵ && k<50 ) fx = fun(fit) oldfit = fit[i] fit[i] += 0.01 dfx = fun(fit) fit[i] -= 0.01 tryfit = fx*0.01 / (dfx-fx)

Interpolation parabolique inverse
Une méthode qui ne nécessite pas de connaissance du dérivé et qui a une bonne convergence
function ipi(i, fit, ϵ)
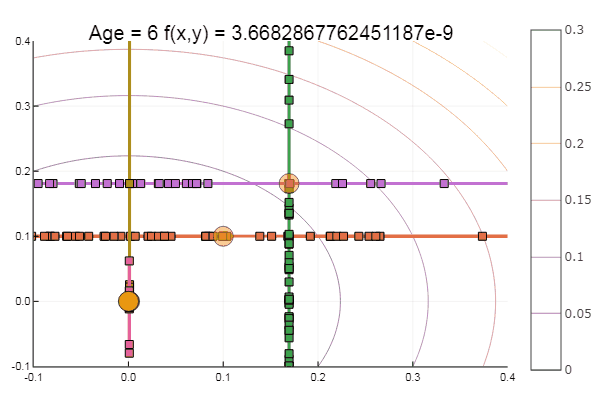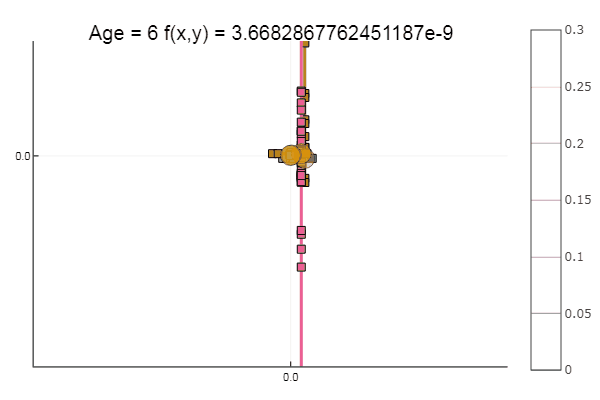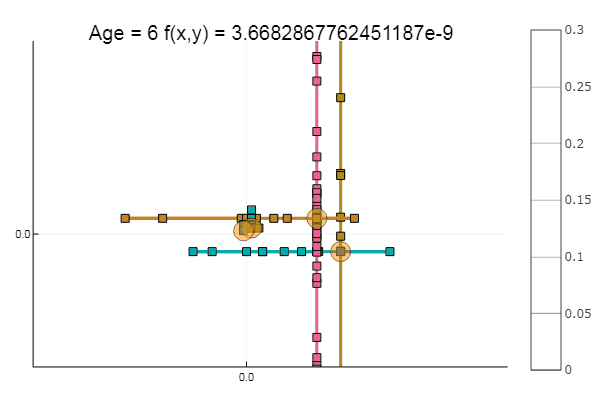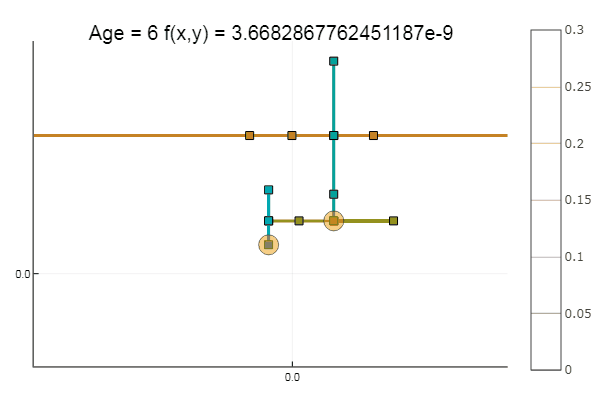
Si l'on aggrave l'approximation initiale, la méthode commencera à nécessiter un nombre immense d'étapes pour chaque époque de descente de coordonnées. À cet égard, son frère gagne
Interpolation parabolique séquentielle
Il nécessite également trois points de départ , mais sur de nombreuses fonctions de test, il donne des résultats plus satisfaisants.
function spi(i, fit, ϵ)
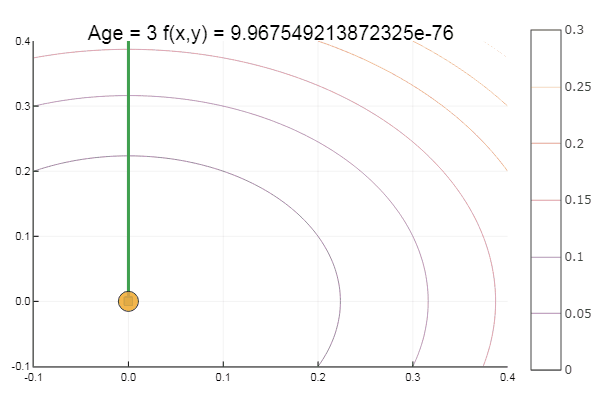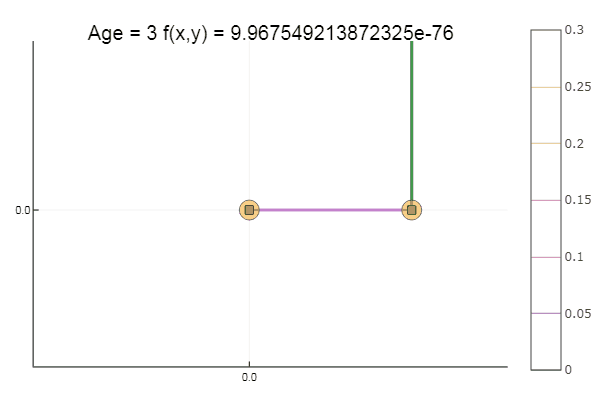
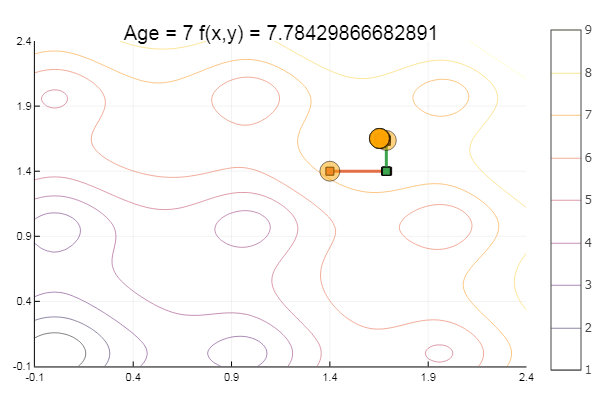
Sortir d'un point de départ très merdique s'est fait en trois étapes! Bon ... Mais toutes les méthodes ont un inconvénient - elles convergent vers un minimum local. Prenons maintenant la fonction d'Ackley pour la recherche
ekly(x) = -20exp(-0.2sqrt(0.5(x[1]*x[1]+x[2]*x[2]))) - exp(0.5(cospi(2x[1])+cospi(2x[2]))) + 20 + ℯ

ofDescent(spi, fit = [1.4 1.4], low = [-.1 -.1], up = [2.4 2.4])
Méthode du ratio d'or
Théorie Bien que l'implémentation soit compliquée, la méthode se montre parfois bien en sautant les minima locaux
function interval(i, fit, st) d = 0. ab = zeros(2) fitc = copy(fit) ab[1] = fitc[i] Fa = fun(fitc) fitc[i] -= st Fdx = fun(fitc) fitc[i] += st if Fdx < Fa st = -st end fitc[i] += st ab[2] = fitc[i] Fb = fun(fitc) while Fb < Fa d = ab[1] ab[1] = ab[2] Fa = Fb fitc[i] += st ab[2] = fitc[i] Fb = fun(fitc)

C’est tout avec une descente coordonnée. Les algorithmes des méthodes présentées sont assez simples, il n'est donc pas difficile de les implémenter dans votre langue préférée. À l'avenir, vous pouvez envisager les outils intégrés du langage Julia , mais pour l'instant, vous voulez tout ressentir avec vos mains, pour ainsi dire, envisager des méthodes plus compliquées et plus efficaces, puis vous pouvez passer à l'optimisation globale, en comparant simultanément avec la mise en œuvre dans une autre langue.
Littérature
- Zaitsev V.V. Méthodes numériques pour les physiciens. Equations non linéaires et optimisation: un tutoriel. - Samara, 2005 - 86s.
- Ivanov A.V. Méthodes informatiques pour l'optimisation des systèmes optiques. Guide d'étude. –SPb: SPbSU ITMO, 2010 - 114s.
- Popova T. M. Méthodes d'optimisation multidimensionnelle: lignes directrices et tâches pour les travaux de laboratoire dans la discipline "Méthodes d'optimisation" pour les étudiants de la direction "Mathématiques Appliquées" / comp. T. M. Popova. - Khabarovsk: maison d'édition du Pacifique. état Université, 2012 .-- 44 p.