Quelle est la complexité du sujet de l'apprentissage automatique? Si vous êtes bon en mathématiques, mais que la quantité de connaissances sur l'apprentissage automatique tend à zéro, jusqu'où pouvez-vous aller dans une compétition sérieuse sur la plate-forme
Kaggle ?

À propos du site et du concours
Kaggle est une communauté de personnes intéressées par le ML (des débutants aux pros sympas) et un lieu de compétitions (souvent avec un prize pool impressionnant).
Pour plonger immédiatement dans tous les charmes du ML, j'ai décidé de choisir immédiatement une compétition sérieuse. Telle était juste disponible:
Two Sigma: Utilisation des nouvelles pour prédire les mouvements de stock . L'essence du concours en bref est de prédire le prix des actions de diverses sociétés en fonction du statut de l'actif et des nouvelles liées à cet actif. Le prix du concours est de 100 000 $, qui sera distribué aux participants ayant remporté les 7 premières places.
Le concours est spécial pour deux raisons:
- il s'agit d'un concours réservé aux noyaux: vous ne pouvez former des modèles que dans le cloud Kaggle Kernels;
- la répartition finale des sièges ne sera connue que six mois après la fin du processus décisionnel; pendant cette période, les décisions prévoiront les prix à la date actuelle.
À propos de la tâche
Par condition, il faut prédire la confiance
en ce que le rendement de l'actif augmentera. Le rendement d'un actif est considéré par rapport au rendement du marché dans son ensemble. La métrique cible est personnalisée - ce n'est pas la
RMSE ou la
MAE la plus connue, mais
le ratio de Sharpe , qui dans ce cas est considéré comme suit:
où
,
- le rendement de l'actif i par rapport au marché au jour t sur un horizon de 10 jours,
- une variable booléenne indiquant si le ième actif est inclus dans la valorisation du jour t,
- valeur moyenne
,
- écart type
.
Le ratio de Sharpe est le rendement ajusté au risque, les valeurs du coefficient montrent l'efficacité du trader:
- moins de 1: performances médiocres
- 1 - 2: efficacité moyenne, normale,
- 2 - 3: excellentes performances,
- plus de 3: parfait.
Données sur les mouvements du marché- time (datetime64 [ns, UTC]) - heure actuelle (dans les données sur les mouvements du marché sur toutes les lignes à 22:00 UTC)
- assetCode (object) - identifiant d'actif
- assetName (category) - identifiant d'un groupe d'actifs pour la communication avec les données d'actualités
- univers (float64) - une valeur booléenne indiquant si cet actif sera pris en compte dans le calcul du score
- volume (float64) - volume de négociation quotidien
- close (float64) - cours de clôture de ce jour
- open (float64) - prix ouvert pour cette journée
- returnClosePrevRaw1 (float64) - rendement de la fermeture à la fermeture de la veille
- returnOpenPrevRaw1 (float64) - rentabilité de l'ouverture à l'ouverture pour la veille
- returnClosePrevMktres1 (float64) - rentabilité de clôture à clôture de la veille, ajustée en fonction de l'évolution du marché dans son ensemble
- returnOpenPrevMktres1 (float64) - rentabilité d'ouverture à ouverture de la veille, ajustée en fonction de l'évolution du marché dans son ensemble
- returnClosePrevRaw10 (float64) - rendement de près à près pour les 10 jours précédents
- returnOpenPrevRaw10 (float64) - rentabilité de l'ouverture à l'ouverture pour les 10 derniers jours
- returnClosePrevMktres10 (float64) - rendement de près à près pour les 10 jours précédents, ajusté en fonction du mouvement du marché dans son ensemble
- returnOpenPrevMktres10 (float64) - rendement d'ouverture à ouverture des 10 derniers jours, ajusté en fonction du mouvement du marché dans son ensemble
- returnOpenNextMktres10 (float64) - rendement de l'ouverture à l'ouverture au cours des 10 prochains jours, ajusté en fonction de l'évolution du marché dans son ensemble. Nous prédirons cette valeur.
Données d'actualités- time (datetime64 [ns, UTC]) - heure de disponibilité des données UTC
- sourceTimestamp (datetime64 [ns, UTC]) - heure dans les nouvelles de publication UTC
- firstCreated (datetime64 [ns, UTC]) - heure en UTC de la première version des données
- sourceId (object) - identifiant d'enregistrement
- titre (objet) - titre
- urgence (int8) - types d'actualités (1: alerte, 3: article)
- takeSequence (int16) - paramètre pas tout à fait clair, nombre dans une séquence
- provider (category) - identifiant du fournisseur de nouvelles
- sujets (catégorie) - une liste de codes de sujets d'actualité (peut être un signe géographique, un événement, un secteur industriel, etc.)
- audiences (catégorie) - liste des actualités des codes d'audience
- bodySize (int32) - nombre de caractères dans le corps de l'actualité
- companyCount (int8) - nombre d'entreprises explicitement mentionnées dans les actualités
- headlineTag (object) - une certaine balise de titre de Thomson Reuters
- marketCommentary (bool) - un signe que l'actualité concerne les conditions générales du marché
- sentenceCount (int16) - nombre d'offres dans l'actualité
- wordCount (int32) - nombre de mots et de signes de ponctuation dans les actualités
- assetCodes (category) - liste des actifs mentionnés dans l'actualité
- assetName (category) - code de groupe d'actifs
- firstMentionSentence (int16) - une phrase qui mentionne d'abord un actif:
- pertinence (float32) - un nombre de 0 à 1, montrant la pertinence des nouvelles concernant l'actif
- sentimentClass (int8) - nouvelle classe de tonalité
- sentimentNegative (float32) - probabilité que la tonalité soit négative
- sentimentNeutral (float32) - probabilité que le ton soit neutre
- sentimentPositive (float32) - probabilité que la clé soit positive
- sentimentWordCount (int32) - le nombre de mots dans le texte qui sont liés à l'actif
- noveltyCount12H (int16) - Actualités «nouveauté» en 12 heures, calculées par rapport aux informations précédentes sur cet actif
- noveltyCount24H (int16) - identique, en 24 heures
- noveltyCount3D (int16) - identique, en 3 jours
- noveltyCount5D (int16) - identique, dans 5 jours
- noveltyCount7D (int16) - identique, en 7 jours
- volumeCounts12H (int16) - la quantité de nouvelles sur cet actif en 12 heures
- volumeCounts24H (int16) - identique, en 24 heures
- volumeCounts3D (int16) - identique, en 3 jours
- volumeCounts5D (int16) - identique, pendant 5 jours
- volumeCounts7D (int16) - identique, en 7 jours
La tâche est essentiellement la tâche de classification binaire, c'est-à-dire que nous prédisons un signe binaire, le rendement augmentera (1 classe) ou diminuera (classe 0).
À propos des outils
Kaggle Kernels est une plateforme de cloud computing qui prend en charge la collaboration. Les types de noyaux suivants sont pris en charge:
- Script Python
- Script R
- Carnet Jupyter
- RMarkdown
Chaque noyau s'exécute dans son conteneur Docker. Un grand nombre de packages sont installés dans le conteneur, une liste pour python peut être trouvée
ici . Les spécifications techniques sont les suivantes:
- CPU: 4 cœurs,
- RAM: 17 Go,
- lecteur: 5 Go permanent et 16 Go temporaire,
- durée maximale d'exécution du script: 9 heures (au moment du début de la compétition, elle était de 6 heures).
Les GPU sont également disponibles dans Kernels, cependant, les GPU étaient interdits dans ce concours.
Keras est une infrastructure de réseau neuronal de haut niveau qui s'exécute au-dessus de
TensorFlow ,
CNTK ou
Theano . Il s'agit d'une API très pratique et compréhensible, et il est possible d'ajouter vos topologies de réseau, fonctions de perte, etc. à l'aide de l'API backend.
Scikit-learn est une grande bibliothèque d'algorithmes d'apprentissage automatique. Une source utile d'algorithmes de prétraitement et d'analyse de données à utiliser avec des cadres plus spécialisés.
Validation du modèle
Avant de soumettre un modèle pour évaluation, vous devez d'une manière ou d'une autre vérifier localement s'il fonctionne bien, c'est-à-dire trouver un moyen de validation locale. J'ai essayé les approches suivantes:
- validation croisée vs division proportionnelle simple en ensembles de formation / test;
- calcul local du ratio de Sharpe vs ROC AUC .
En conséquence, les résultats les plus proches de l'évaluation concurrentielle, curieusement, ont montré une combinaison de la partition proportionnelle (choisie empiriquement la partition 0,85 / 0,15) et l'ASC. La validation croisée n'est probablement pas très appropriée, car le comportement du marché est très différent aux premiers stades des données de formation et pendant la période d'évaluation. Pourquoi l'AUC a mieux fonctionné que le ratio de Sharpe - je ne peux pas du tout dire.
Premières tentatives
La tâche étant de prédire les séries chronologiques, la première a été testée la solution classique - un réseau de neurones récurrents (
RNN ), ou plutôt ses variantes
LSTM et
GRU .
Le principe principal des réseaux récurrents est que pour chaque valeur de sortie, pas un échantillon n'est entré, mais une séquence entière. Il en résulte que:
- nous avons besoin d'un prétraitement des données initiales - la génération de ces séquences mêmes de longueur t jours pour chaque actif;
- un modèle basé sur un réseau récurrent ne peut pas prédire la valeur de sortie s'il n'y a pas de données pour les t jours précédents.
J'ai généré des séquences pour chaque jour, en commençant par t, donc pour un t assez grand (à partir de 20), l'ensemble complet des échantillons d'apprentissage a cessé de tenir en mémoire. Le problème a été résolu en utilisant des générateurs, car Keras peut utiliser des générateurs comme ensembles de données d'entrée et de sortie pour la formation et la prévision.
La préparation initiale des données a été aussi naïve que possible: nous prenons l'ensemble des données du marché et ajoutons quelques fonctionnalités (jour de la semaine, mois, numéro de semaine de l'année), et nous ne touchons pas du tout aux données d'actualité.
Le premier modèle utilisait t = 10 et ressemblait à ceci:
model = Sequential() model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features))) model.add(LSTM(256, activation=act.relu)) model.add(Dense(data.assets, activation=act.relu)) model.add(Dense(data.assets))
Rien de suffisant n'a été retiré de ce modèle, le score était proche de zéro (même un peu moins).
Réseaux convolutifs temporels
TCN est une solution de réseau neuronal plus moderne pour la prédiction de séries chronologiques. L'essence de cette topologie est très simple: nous prenons un réseau convolutionnel unidimensionnel et l'appliquons à notre séquence de longueur t. Des options plus avancées utilisent plusieurs couches convolutives avec une dilatation différente. L'implémentation TCN a été partiellement copiée (parfois au niveau de l'idée) à
partir d'ici (visualisation de la pile TCN tirée de
l'article de Wavenet ).
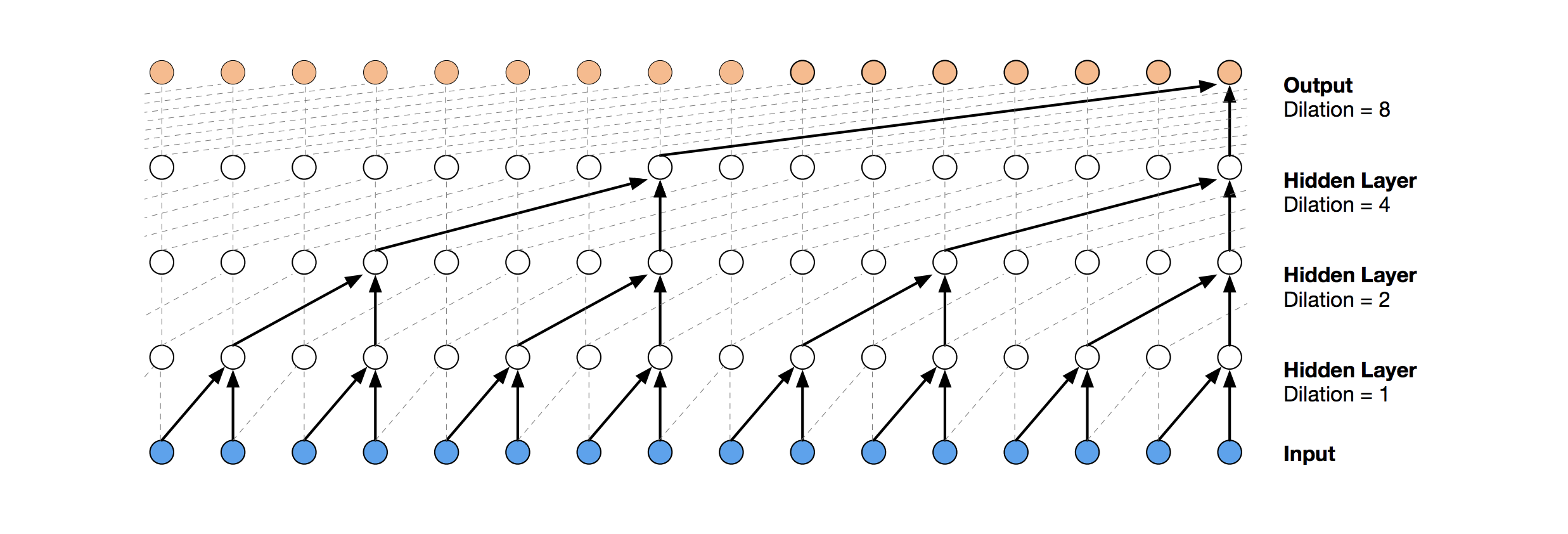
La première solution relativement réussie a été ce modèle, qui comprend une couche GRU au-dessus de TCN:
model = Sequential() model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(256)) model.add(Dense(data.assets, activation=act.relu))
Un tel modèle produit un score = 0,27668. Avec un peu de réglage (nombre de filtres TCN, taille de batch) et une augmentation de t à 100, on obtient déjà 0.41092:
batch_size = 512 model = Sequential() model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(16)) model.add(Dense(1, activation=act.sigmoid))
Ensuite, nous ajoutons la normalisation et le décrochage:
Code batch_size = 512 dropout_rate = 0.05 def channel_normalization(x): max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5 out = x / max_values return out model = Sequential() if(data.timesteps > 1): model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features))) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) for i in range(1, 6): model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i)) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) model.add(Flatten()) else: model.add(Flatten(input_shape=(data.timesteps, data.features))) model.add(Dense(256, activation=act.relu)) model.add(Dense(1, activation=act.sigmoid))
En appliquant ce modèle, y compris dans les premières étapes (avec t = 1), nous obtenons un score = 0,53578.
Machines de renforcement de gradient
À ce stade, les idées ont pris fin et j'ai décidé de faire ce qui devait être fait au tout début: voir les décisions publiques des autres participants. La plupart des bonnes solutions n'utilisaient pas du tout les réseaux de neurones, préférant le GBM.
Gradient Boosting est une méthode ML, à la sortie de laquelle on obtient un ensemble de modèles simples (le plus souvent des arbres de décision). En raison du grand nombre de ces modèles simples, la fonction de perte est optimisée. Vous pouvez en savoir plus sur le renforcement des dégradés, par exemple,
ici .
Comme l'implémentation de GBM a utilisé
lightgbm - un
framework assez connu de Microsoft.
Le prétraitement du modèle et des données pris
ici donne immédiatement un score d'environ 0,64:
Code def prepare_data(marketdf, newsdf):
Le prétraitement ici inclut déjà des données d'actualités, en les combinant avec des données de marché (cependant, en le faisant de manière assez naïve, un seul code d'actif parmi tous ceux mentionnés dans l'actualité est pris en compte). J'ai pris cette option de prétraitement comme base pour toutes les décisions ultérieures.
En ajoutant une petite fonctionnalité (firstMentionSentence, marketCommentary, sentimentClass), et en remplaçant également la métrique par
ROC AUC , nous obtenons un score de 0,65389.
Ensemble
La prochaine décision réussie a été d'utiliser un ensemble composé d'un modèle de réseau neuronal et de GBM (bien que «ensemble» soit un grand nom pour deux modèles). La prédiction résultante est obtenue en faisant la moyenne des prédictions des deux modèles, appliquant ainsi le mécanisme de vote doux. Cette décision a permis d'obtenir un score de 0,66879.
Analyse exploratoire des données et ingénierie des fonctionnalités
Une autre chose pour commencer était EDA. Après avoir lu qu'il est important de comprendre la corrélation entre les fonctionnalités, nous construisons une telle image (les images de cette section sont cliquables):
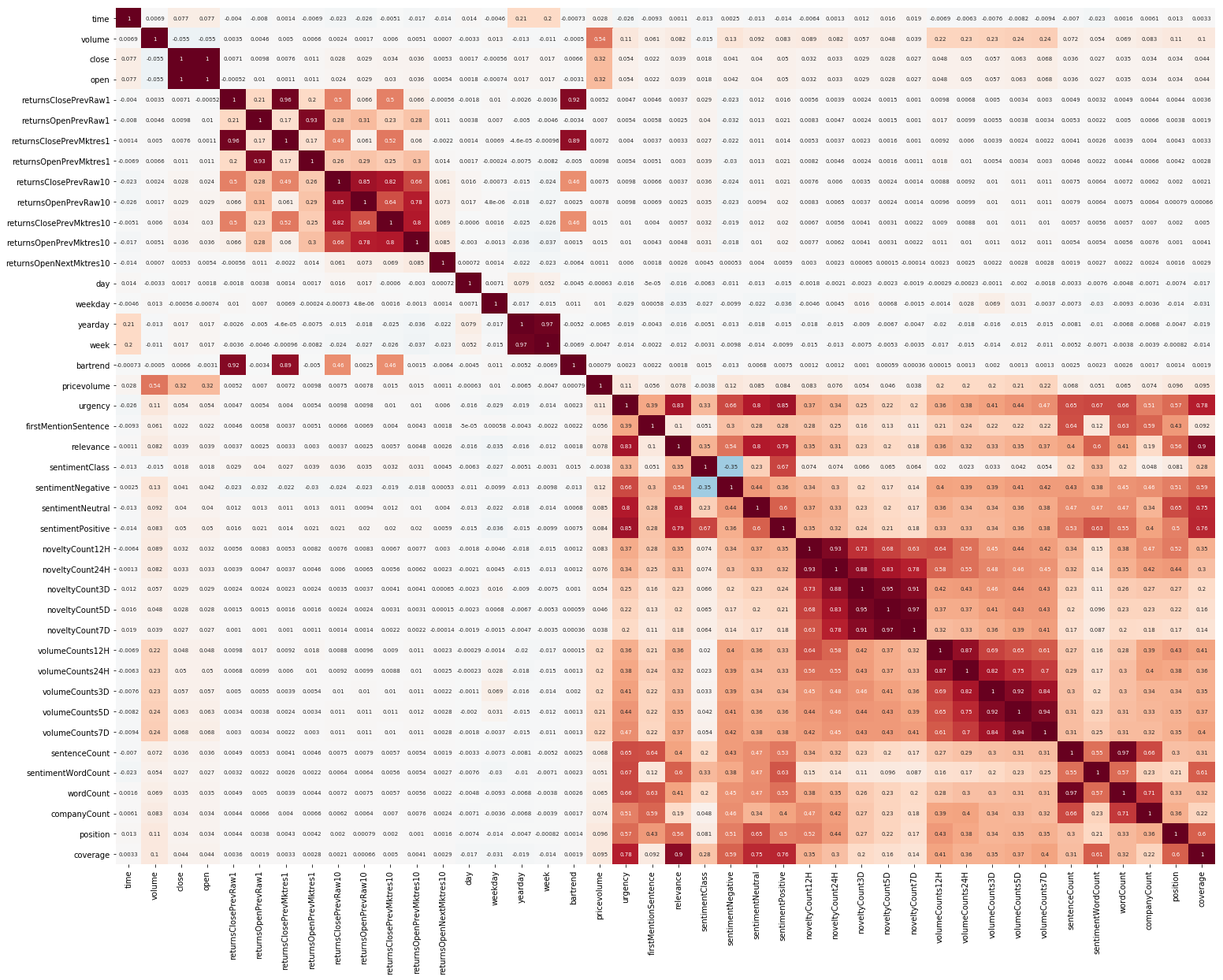
On voit clairement ici que la corrélation séparément au sein du marché et des données d'actualités est assez élevée, cependant, seules les valeurs des rendements sont en corrélation avec la valeur cible au moins d'une manière ou d'une autre. Étant donné que les données représentent une série chronologique, il est logique d'examiner également l'autocorrélation de la valeur cible:
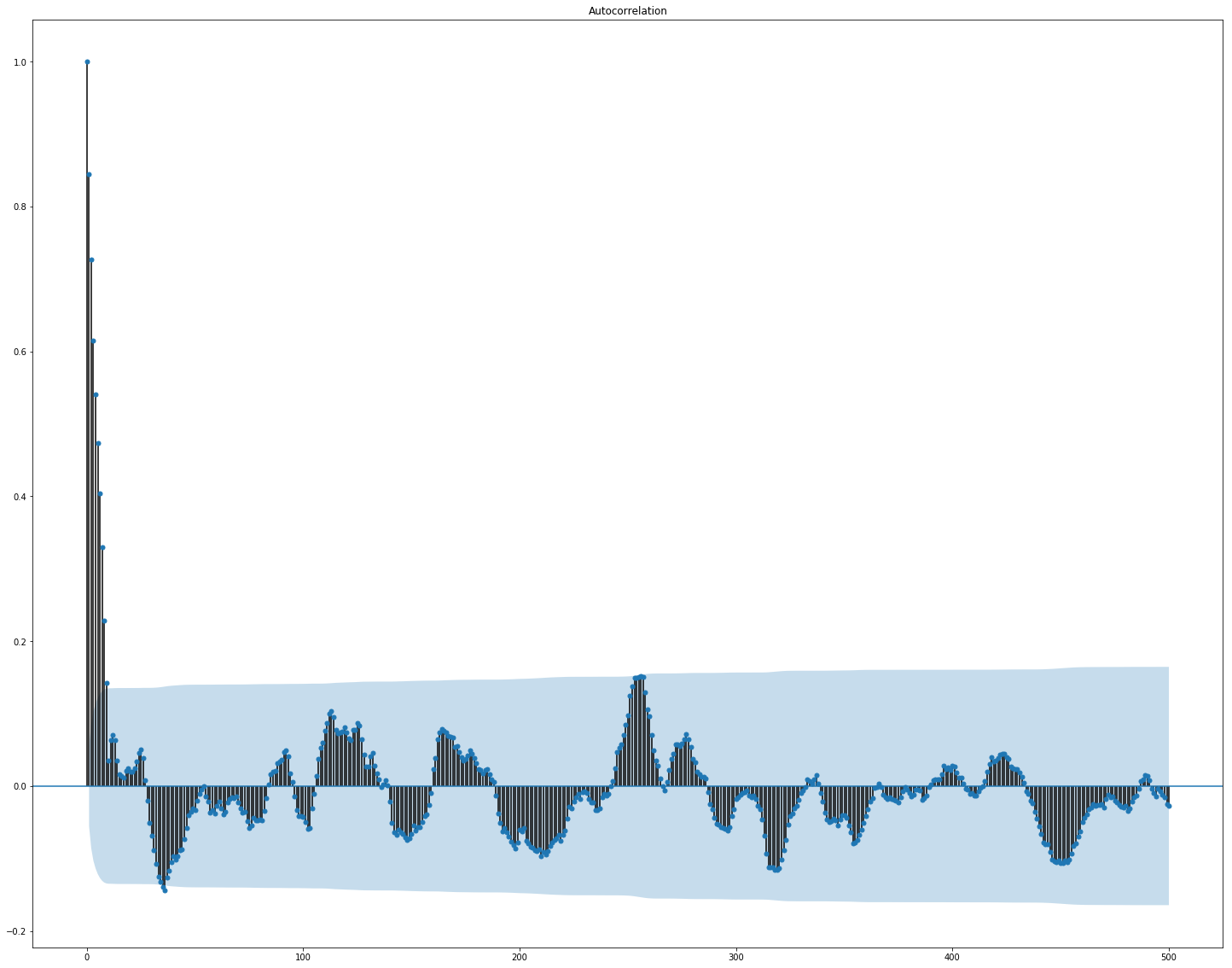
On peut voir qu'après une période de 10 jours, la dépendance diminue considérablement. C'est probablement ce qui fait que GBM fonctionne bien, en ne prenant en compte que les fonctionnalités avec un délai de 10 jours (qui sont déjà dans l'ensemble de données d'origine).
La sélection et le prétraitement des fonctionnalités sont cruciaux pour tous les algorithmes ML. Essayons d'utiliser des moyens automatiques pour extraire des fonctionnalités, à savoir
l' analyse du composant principal (
PCA ):
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler market_x = market_data.loc[:,features] scaler = StandardScaler() scaler.fit(market_x) market_x = scaler.transform(market_x) pca = PCA(.95) pca.fit(market_x) market_pca = pca.transform(market_x)
Voyons quelles fonctionnalités le PCA génère:

Nous voyons que la méthode ne fonctionne pas très bien sur nos données, car la corrélation finale des nouvelles fonctionnalités avec la valeur cible est faible.
Réglage fin et si c'est nécessaire
De nombreux modèles ML ont un assez grand nombre d'hyperparamètres, c'est-à-dire les «paramètres» de l'algorithme lui-même. Ils peuvent être sélectionnés manuellement, mais il existe également des mécanismes de sélection automatique. Pour ce dernier, il existe une bibliothèque
hyperoptique qui implémente deux algorithmes de correspondance: la recherche aléatoire et l'
arborescence Parzen Estimator (TPE) . J'ai essayé d'optimiser:
- paramètres lightgbm (type d'algorithme, nombre de feuilles, taux d'apprentissage et autres),
- paramètres des modèles de réseaux de neurones (nombre de filtres TCN , nombre de blocs de mémoire GRU , taux de décrochage, taux d'apprentissage, type de solveur).
En conséquence, toutes les solutions trouvées en utilisant cette optimisation ont donné un score inférieur, bien qu'elles aient mieux fonctionné sur les données de test. La raison réside probablement dans le fait que les données pour lesquelles le score est pris en compte ne sont pas très similaires aux données de validation sélectionnées dans la formation. Ainsi, pour cette tâche, un réglage fin n'est pas très approprié, car il conduit à un recyclage du modèle.
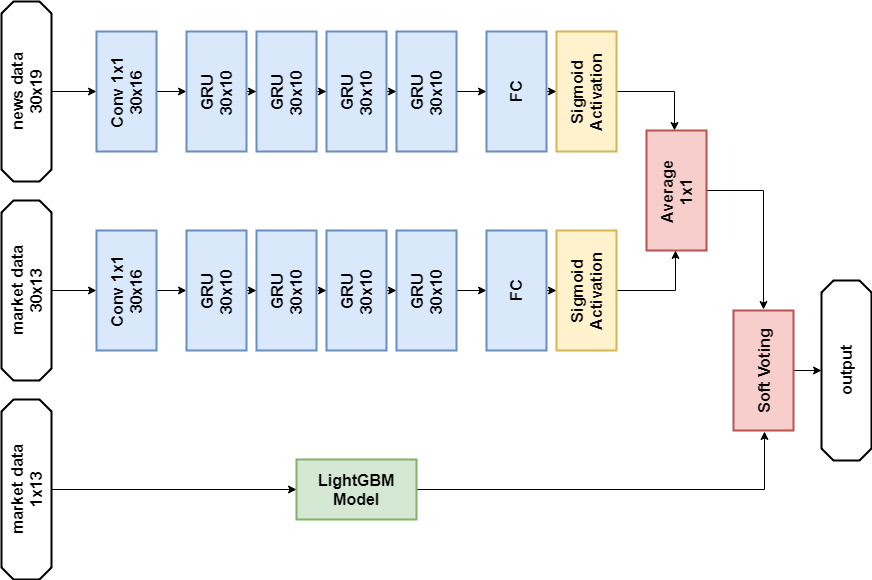
Décision finale
Selon les règles du concours, les participants peuvent choisir deux solutions pour la phase finale. Mes décisions finales sont presque les mêmes et contiennent un ensemble de deux modèles -
GBM et
GRU multicouches. La seule différence est qu'une solution n'utilise pas du tout de données d'actualité, et que l'autre l'utilise, mais uniquement pour le modèle de réseau neuronal.
Solution de données d'actualités:
Importations import numpy as np import pandas as p import itertools import functools from kaggle.competitions import twosigmanews from sklearn.preprocessing import StandardScaler, LabelEncoder import tensorflow as tf from keras.models import Sequential, Model from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average from keras.optimizers import Adam, SGD, RMSprop from keras import losses as ls from keras import activations as act import keras.backend as K import lightgbm as lgb
Prétraitement des données Modèle de réseau neuronal def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) x2 = Lambda(lambda x: x[:,:,13:])(i) x2 = Conv1D(16,1, padding='valid')(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10)(x2) x2 = Dense(1, activation=act.sigmoid)(x2) x = Average()([x1, x2]) model = Model(inputs=i, outputs=x) return model def train_model_time_series(model, data, val_data=None): print('Building model...') batch_size = 4096 optimizer = RMSprop()
Modèle GBM def train_model(data, val_data=None): print('Building model...') params = { "objective" : "binary", "metric" : "auc", "num_leaves" : 60, "max_depth": -1, "learning_rate" : 0.01, "bagging_fraction" : 0.9,
La formation n_timesteps = 30 market_data, news_data = cleanData(market_train_df, news_train_df) dates = market_data['time'].unique() train = range(len(dates))[:int(0.85*len(dates))] val = range(len(dates))[int(0.85*len(dates)):] train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])]) val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler) model_gbm = train_model(train_data_prepared, val_data_prepared) train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps) val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps) rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features) model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
Prédiction def make_predictions(data, template, model): if(hasattr(data, 'gen')): prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1] else: prediction = model.predict(data.x) * 2 - 1 predsdf = p.DataFrame({'ast':data.assets,'conf':prediction}) template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values return template day = 1 days_data = p.DataFrame({}) days_data_len = [] days_data_n = p.DataFrame({}) days_data_n_len = [] for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days(): print(f'Predicting day {day}') days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False) days_data_len.append(len(market_obs_df)) days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False) days_data_n_len.append(len(news_obs_df)) data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler) predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm) if(day >= n_timesteps): data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler) data = generateTimeSeries(data, n_timesteps=n_timesteps) predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn) predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2 days_data = days_data[days_data_len[0]:] days_data_n = days_data_n[days_data_n_len[0]:] days_data_len = days_data_len[1:] days_data_n_len = days_data_n_len[1:] env.predict(predictions_df) day += 1 env.write_submission_file()
Solution sans données d'actualités:

Code (uniquement une méthode différente) def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Les deux décisions ont donné un résultat similaire (environ 0,69) lors de la première étape du concours, ce qui correspondait à 566 sur 2 927 places. Après le premier mois de nouvelles données, les positions dans la liste des participants étaient mélangées, et la solution avec les données d'actualité était en 65ème position sur les 697 équipes restantes avec le résultat de 3,19251, et ce qui se passera au cours des cinq prochains mois, personne ne le sait.
Quoi d'autre ai-je essayé
Mesures personnalisées
Étant donné que les décisions sont évaluées à l'aide du ratio de Sharpe, il est logique d'essayer de l'utiliser comme une mesure pour l'arrêt précoce de la formation.
Métrique pour lightgbm:
def sharpe_metric(y_pred, train_data): y_true = train_data.get_label() * 2 - 1 std = np.std(y_true * y_pred) mean = np.mean(y_true * y_pred) sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0) return "sharpe", sharpe, True
La vérification a montré qu'une telle métrique fonctionne moins bien dans ce problème que l'AUC.
Mécanisme d'attention
Le mécanisme d'attention permet au réseau neuronal de se concentrer sur les caractéristiques «les plus importantes» des données sources. Techniquement, l'attention est représentée par un vecteur de poids (le plus souvent obtenus à l'aide d'une couche entièrement connectée avec activation
softmax ), qui sont multipliés par la sortie d'une autre couche. J'ai utilisé une implémentation dans laquelle l'attention est appliquée à l'axe du temps:
def buildRNN(timesteps, features): def attention_3d_block(inputs): a = Permute((2, 1))(inputs) a = Dense(timesteps, activation=act.softmax)(a) a = Permute((2, 1))(a) mul = Multiply()([inputs, a]) return mul i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Ce modèle a l'air assez joli, mais cette approche n'a pas donné d'augmentation du score, il s'est avéré être d'environ 0,67.
Ce qui n'a pas eu le temps de faire
Plusieurs domaines qui semblent prometteurs:
Conclusions
Notre aventure est terminée, vous pouvez essayer de résumer. La compétition s'est avérée difficile, mais nous n'avons pas pu faire face à la saleté. Cela laisse entendre que le seuil d'entrée dans le ML n'est pas si élevé, mais, comme dans toute entreprise, la vraie magie (et il y en a beaucoup dans l'apprentissage automatique) est déjà disponible pour les professionnels.
Résultats en chiffres:
- Le score maximum dans la première étape: ~ 0,69 contre ~ 1,5 en premier lieu. Quelque chose comme la moyenne de l'hôpital, une valeur de 0,7 a été dépassée par quelques-uns, le score maximum de la décision publique était également de ~ 0,69, un peu plus que le mien.
- Classement en première étape: 566 sur 2927.
- Score en deuxième étape: 3,19251 après le premier mois.
- Place en deuxième étape: 65 sur 697 après le premier mois.
J'attire votre attention sur le fait que les chiffres de la deuxième étape ne parlent pas particulièrement de quoi que ce soit, car il existe encore très peu de données pour une évaluation qualitative des décisions.
Les références
La solution finale en utilisant les actualitésTwo Sigma: Utilisation des actualités pour prédire les mouvements de stock - Page du concours
Keras -
Cadre de réseau neuronal
LightGBM -
Framework GBM
Scikit-learn - bibliothèque d'algorithmes d'apprentissage automatique
Hyperopt - bibliothèque pour optimiser les hyperparamètres
Article sur WaveNet