Nous savons tous comment la patrie commence et le deep learning commence par les données. Sans eux, il est impossible de former un modèle, de l'évaluer et même de l'utiliser. Engagés dans la recherche, en augmentant l'indice de Hirsch avec des articles sur les nouvelles architectures de réseaux de neurones et l'expérimentation, nous nous appuyons sur les sources de données locales les plus simples; généralement des fichiers dans différents formats. Cela fonctionne, mais il serait bon de se souvenir d'un système de combat contenant des téraoctets de données en constante évolution. Et cela signifie que vous devez simplifier et accélérer le transfert de données dans la production, ainsi que pouvoir travailler avec les mégadonnées. C'est là qu'Apache Ignite entre en jeu.
Apache Ignite est une base de données distribuée centrée sur la mémoire, ainsi qu'une plate-forme pour la mise en cache et le traitement des opérations liées aux transactions, aux analyses et aux charges de flux. Le système est capable de broyer des pétaoctets de données à la vitesse de la RAM. L'article se concentrera sur l'intégration entre Apache Ignite et TensorFlow, qui vous permet d'utiliser Apache Ignite comme source de données pour la formation du réseau neuronal et de l'inférence, ainsi qu'un référentiel de modèles formés et un système de gestion de cluster pour l'apprentissage distribué.
Source de données RAM distribuée
Apache Ignite vous permet de stocker et de traiter autant de données que vous le souhaitez dans un cluster distribué. Pour tirer parti de cette Apache Ignite lors de la formation des réseaux de neurones dans TensorFlow, utilisez
Ignite Dataset .
Remarque: Apache Ignite n'est pas seulement l'un des liens du pipeline ETL entre une base de données ou un entrepôt de données et TensorFlow. Apache Ignite est en soi
HTAP (un système hybride pour le traitement transactionnel / analytique des données). En choisissant Apache Ignite et TensorFlow, vous obtenez un système unique pour le traitement transactionnel et analytique, et en même temps, la possibilité d'utiliser des données opérationnelles et historiques pour former le réseau neuronal et l'inférence.
Les benchmarks suivants démontrent qu'Apache Ignite est bien adapté aux scénarios où les données sont stockées sur un seul hôte. Un tel système vous permet d'atteindre un débit supérieur à 850 Mb / s, si l'entrepôt de données et le client sont situés sur le même nœud. Si le stockage est situé sur un hôte distant, le débit est d'environ 800 Mb / s.
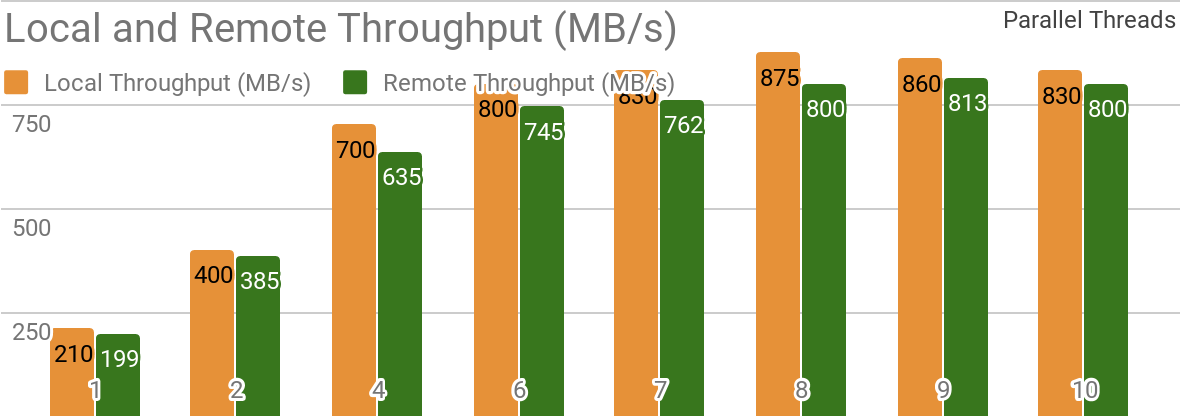
Le graphique montre la bande passante pour Ignite Dataset pour un seul nœud local Apache Ignite. Ces résultats ont été obtenus sur un processeur 2x Xeon E5-2609 v4 1,7 GHz avec 16 Go de RAM et sur un réseau avec une bande passante de 10 Go / s (chaque enregistrement a une taille de 1 Mo, la taille de la page - 20 Mo).
Un autre benchmark montre comment Ignite Dataset fonctionne avec un cluster Apache Ignite distribué. C'est cette configuration qui est sélectionnée par défaut lors de l'utilisation d'Apache Ignite en tant que système HTAP et vous permet d'atteindre un débit pour un seul client supérieur à 1 Go / s sur un cluster avec une bande passante de 10 Gb / s.
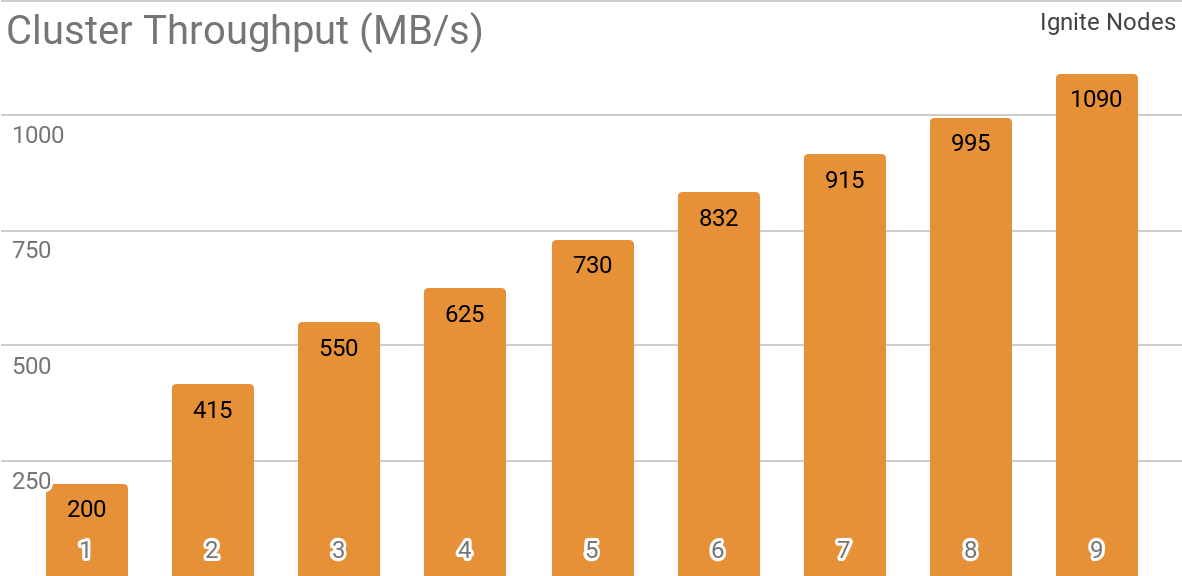
Le graphique montre le débit Ignite Dataset pour un cluster Apache Ignite distribué avec un nombre différent de nœuds (de 1 à 9). Ces résultats ont été obtenus sur un processeur 2x Xeon E5-2609 v4 1,7 GHz avec 16 Go de RAM et sur un réseau avec une bande passante de 10 Go / s (chaque enregistrement a une taille de 1 Mo, la taille de la page - 20 Mo).
Le scénario suivant a été testé: le cache Apache Ignite (avec un nombre variable de partitions dans le premier ensemble de tests et avec 2048 partitions dans le second) est rempli de 10 000 lignes de 1 Mo chacune, après quoi le client TensorFlow lit les données à l'aide d'Ignite Dataset. Le cluster a été construit à partir de machines avec 2x Xeon E5-2609 v4 1,7 GHz, 16 Go de mémoire et connecté via un réseau fonctionnant à une vitesse de 10 Go / s. Sur chaque nœud, Apache Ignite fonctionnait dans la
configuration standard .
Apache Ignite est facile à utiliser comme base de données classique avec interface SQL et en même temps comme source de données pour TensorFlow.
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
Objets structurés
Apache Ignite vous permet de stocker des objets de tout type pouvant être construits dans n'importe quelle hiérarchie. Vous pouvez l'utiliser avec Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
La formation au réseau de neurones et d'autres calculs nécessitent un prétraitement, qui peut être effectué dans le cadre du pipeline
tf.data si vous utilisez Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
Formation distribuée
TensorFlow est un cadre d'apprentissage automatique qui
prend en charge l'apprentissage distribué des réseaux de neurones, l'inférence et d'autres systèmes informatiques. Comme vous le savez, l'entraînement du réseau neuronal est basé sur le calcul des gradients de la fonction de perte. Dans le cas d'une formation distribuée, nous pouvons calculer ces gradients sur chaque partition, puis les agréger. C'est cette méthode qui vous permet de calculer les gradients pour les nœuds individuels sur lesquels les données sont stockées, de les résumer et, enfin, de mettre à jour les paramètres du modèle. Et, puisque nous nous sommes débarrassés de la transmission des données d'échantillons d'apprentissage entre les nœuds, le réseau ne devient pas le «goulot d'étranglement» du système.
Apache Ignite utilise un partitionnement horizontal (partitionnement) pour stocker les données dans un cluster distribué. En créant le cache Apache Ignite (ou une table, en termes de SQL), vous pouvez spécifier le nombre de partitions entre lesquelles les données seront réparties. Par exemple, si un cluster Apache Ignite se compose de 100 machines et que nous créons un cache avec 1000 partitions, chaque machine sera responsable d'environ 10 partitions avec des données.
Ignite Dataset vous permet d'utiliser ces deux aspects pour la formation distribuée des réseaux de neurones. Ignite Dataset est le nœud du
graphe de calcul qui constitue la base de l'architecture TensorFlow. Et, comme tout nœud d'un graphique, il peut s'exécuter sur un nœud distant du cluster. Un tel nœud distant peut remplacer les paramètres Ignite Dataset (par exemple,
host ,
port ou
part ), en définissant les variables d'environnement appropriées pour le flux de travail (par exemple,
IGNITE_DATASET_HOST ,
IGNITE_DATASET_PORT ou
IGNITE_DATASET_PART ). À l'aide d'un tel remplacement, vous pouvez attribuer une partition spécifique à chaque nœud de cluster. Ensuite, un nœud est responsable d'une partition et en même temps, l'utilisateur reçoit une seule façade de travail avec l'ensemble de données.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES")
Apache Ignite permet également un apprentissage distribué à l'aide de la bibliothèque d'
API Estimator de haut niveau TensorFlow. Cette fonctionnalité est basée sur le soi-disant
mode client autonome d' apprentissage distribué dans TensorFlow, où Apache Ignite agit comme une source de données et un système de gestion de cluster. Le prochain article sera entièrement consacré à ce sujet.
Stockage des points de contrôle d'apprentissage
En plus des capacités de base de données, Apache Ignite dispose également d'un système de fichiers
IGFS distribué. Fonctionnellement, il ressemble au système de fichiers Hadoop HDFS, mais uniquement en RAM. Parallèlement à ses propres API, le système de fichiers IGFS implémente l'API Hadoop FileSystem et peut se connecter de manière transparente à Hadoop ou Spark déployé. La bibliothèque TensorFlow sur Apache Ignite fournit une intégration entre IGFS et TensorFlow. L’intégration est basée sur le propre plug-in de
système de fichiers de TensorFlow et
sur l’API IGFS native Apache Ignite. Il existe différents scénarios pour son utilisation, par exemple:
- Les points de contrôle d'état sont stockés dans IGFS pour la fiabilité et la tolérance aux pannes.
- Les processus d'apprentissage interagissent avec TensorBoard en écrivant des fichiers d'événements dans un répertoire surveillé par TensorBoard. IGFS garantit que ces communications sont opérationnelles même lorsque TensorBoard s'exécute dans un autre processus ou sur une autre machine.
Cette fonctionnalité est apparue dans la version de TensorFlow 1.13.0.rc0 et fera également partie de
tensorflow / io dans la version de TensorFlow 2.0.
Connexion SSL
Apache Ignite vous permet de sécuriser les canaux de données à l'aide de
SSL et de l'authentification. Ignite Dataset prend en charge les connexions SSL avec et sans authentification. Voir la documentation
Apache Ignite SSL / TLS pour plus de détails.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
Prise en charge de Windows
Ignite Dataset est entièrement compatible avec Windows. Il peut être utilisé dans le cadre de TensorFlow sur un poste de travail Windows, ainsi que sur les systèmes Linux / MacOS.
Essayez-le vous-même
Les exemples ci-dessous vous aideront à démarrer avec le module.
Igniter le jeu de données
La façon la plus simple de démarrer avec Ignite Dataset est de démarrer le conteneur
Docker avec Apache Ignite et les données
MNIST téléchargées, puis de travailler avec avec Ignite Dataset. Un tel conteneur est disponible dans le Docker Hub:
dmitrievanthony / ignite-with-mnist . Vous devez exécuter le conteneur sur votre machine:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
Après cela, vous pouvez l'utiliser comme suit:
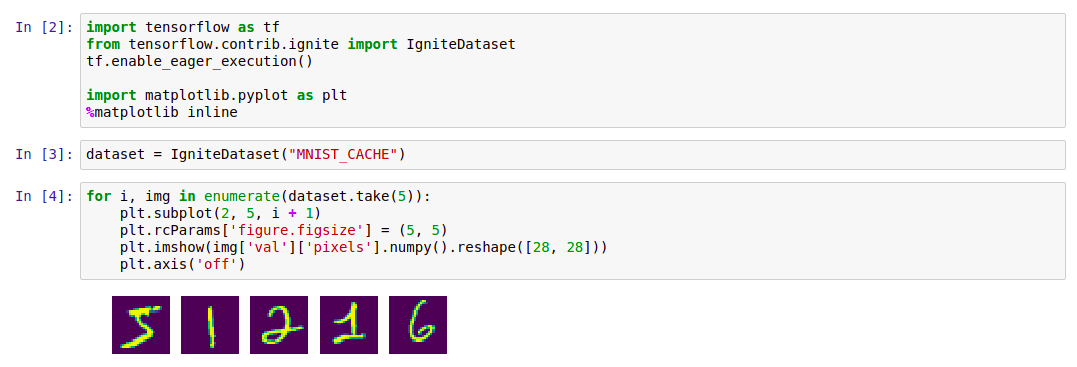
Code import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
La prise en charge TensorFlow IGFS est apparue dans la version TensorFlow 1.13.0rc0 et fera également partie de la version
tensorflow / io dans TensorFlow 2.0. Pour essayer IGFS avec TensorFlow, la façon la plus simple de démarrer le conteneur
Docker est avec Apache Ignite + IGFS, puis de l'utiliser avec TensorFlow
tf.gfile . Un tel conteneur est disponible dans le Docker Hub:
dmitrievanthony / ignite-with-igfs . Ce conteneur peut être exécuté sur votre machine:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
Ensuite, vous pouvez travailler avec comme ceci:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
Limitations
Actuellement, lorsque vous travaillez avec Ignite Dataset, il est supposé que tous les objets du cache ont la même structure (objets homogènes) et que le cache contient au moins un objet nécessaire pour récupérer le schéma. Une autre limitation concerne les objets structurés: Ignite Dataset ne prend pas en charge les UUID, les cartes et les tableaux d'objets, qui peuvent faire partie d'un objet. La suppression de ces restrictions, ainsi que la stabilisation et la synchronisation des versions de TensorFlow et Apache Ignite, est l'une des tâches du développement en cours.
Version TensorFlow 2.0 attendue
Les modifications à venir de TensorFlow 2.0 mettront en évidence ces fonctionnalités dans le module
tensorflow / io . Après quoi, travailler avec eux peut être construit de manière plus flexible. Les exemples changeront un peu, et cela se reflétera dans le gihab et dans la documentation.