Grâce à une analyse en temps réel, nous, les employés d'Uber, nous faisons une idée de la situation et de l'efficacité du travail, et sur la base des données, nous décidons comment améliorer la qualité du travail sur la plate-forme Uber. Par exemple, l'équipe de projet surveille l'état du marché et identifie les problèmes potentiels sur notre plateforme; un logiciel basé sur des modèles d'apprentissage automatique prédit les offres de passagers et la demande de conducteurs; Les spécialistes du traitement des données améliorent les modèles d'apprentissage automatique - à leur tour, pour améliorer la qualité des prévisions.

Dans le passé, pour l'analyse en temps réel, nous utilisions des solutions de base de données d'autres sociétés, mais aucune ne répondait à tous nos critères de fonctionnalité, d'évolutivité, d'efficacité, de coût et d'exigences opérationnelles.
Sorti en novembre 2018, AresDB est un outil d'analyse open source en temps réel. Il utilise une alimentation non conventionnelle, des processeurs graphiques (GPU), ce qui vous permet d'augmenter l'échelle de l'analyse. La technologie GPU, un outil d'analyse en temps réel prometteur, a considérablement progressé ces dernières années, ce qui la rend idéale pour le calcul parallèle et le traitement de données en temps réel.
Dans les sections suivantes, nous décrivons la structure d'AresDB et comment cette solution intéressante pour l'analyse en temps réel nous a permis d'unifier, de simplifier et d'améliorer plus efficacement et plus rationnellement les solutions de base de données Uber pour l'analyse en temps réel. Nous espérons qu'après avoir lu cet article, vous essayerez AresDB dans le cadre de vos propres projets et vous assurerez également de son utilité!
Applications d'analyse en temps réel Uber
L'analyse des données est essentielle au succès d'Uber. Entre autres fonctions, des outils analytiques sont utilisés pour résoudre les tâches suivantes:
- Création de tableaux de bord pour la surveillance des mesures commerciales.
- Prendre des décisions automatiques (par exemple, déterminer le coût d'un voyage et identifier les cas de fraude ) sur la base des métriques récapitulatives collectées.
- Créez des requêtes aléatoires pour diagnostiquer, dépanner et dépanner les opérations commerciales.
Nous classons ces fonctions avec différentes exigences comme suit:

Les tableaux de bord et les systèmes de prise de décision utilisent des systèmes d'analyse en temps réel pour créer des requêtes similaires sur des sous-ensembles de données relativement petits mais très importants (avec le plus haut niveau de pertinence des données) avec un QPS élevé et une faible latence.
Besoin d'un autre module analytique
Le problème le plus courant qu'Uber utilise des outils d'analyse en temps réel pour résoudre est le calcul des populations de séries chronologiques. Ces calculs donnent une idée des interactions des utilisateurs afin que nous puissions améliorer la qualité des services en conséquence. Sur cette base, nous demandons des indicateurs pour certains paramètres (par exemple, jour, heure, identifiant de ville et état du trajet) pendant une certaine période de temps pour des données filtrées de manière aléatoire (ou parfois combinées). Au fil des ans, Uber a déployé plusieurs systèmes conçus pour résoudre ce problème de diverses manières.
Voici quelques solutions tierces que nous avons utilisées pour résoudre ce type de problème:
- Apache Pinot , une base de données analytique open source distribuée écrite en Java, convient à l'analyse de données à grande échelle. Pinot utilise une architecture lambda interne pour interroger les données des paquets et les données en temps réel dans le stockage des colonnes, un index binaire inversé pour le filtrage et un arbre en étoile pour mettre en cache les résultats agrégés. Cependant, il ne prend pas en charge la déduplication, la mise à jour ou l'insertion, la fusion ou les fonctionnalités de requête avancées telles que le filtrage géospatial. De plus, étant donné que Pinot est une base de données basée sur JVM, les requêtes sont très coûteuses en termes d'utilisation de la mémoire.
- Elasticsearch est utilisé par Uber pour résoudre diverses tâches d'analyse de streaming. Il est construit sur la base de la bibliothèque Apache Lucene , qui stocke des documents, pour la recherche de mots clés en texte intégral et un index inversé. Le système est répandu et étendu pour prendre en charge des données agrégées. Un index inversé fournit un filtrage mais n'est pas optimisé pour le stockage et le filtrage des données en fonction des plages de temps. Les enregistrements sont stockés sous forme de documents JSON, ce qui impose des coûts supplémentaires pour fournir l'accès au référentiel et aux requêtes. Comme Pinot, Elasticsearch est une base de données basée sur JVM et, par conséquent, ne prend pas en charge la fonction de jointure, et l'exécution des requêtes occupe une grande quantité de mémoire.
Bien que ces technologies aient leurs points forts, il leur manquait certaines des fonctionnalités nécessaires à notre cas d'utilisation. Nous avions besoin d'une solution unifiée, simplifiée et optimisée, et dans sa recherche nous avons travaillé dans une direction non standard (plus précisément, à l'intérieur du GPU).
Utilisation du GPU pour une analyse en temps réel
Pour un rendu réaliste des images avec une fréquence d'images élevée, les GPU traitent simultanément un grand nombre de formes et de pixels à grande vitesse. Bien que la tendance à augmenter la fréquence d'horloge des unités de traitement des données au cours des dernières années ait commencé à décliner, le nombre de transistors dans la puce n'a augmenté que conformément à la loi de Moore . En conséquence, la vitesse de calcul du GPU, mesurée en gigaflops par seconde (Gflops / s), augmente rapidement. La figure 1 ci-dessous montre une comparaison de la tendance de vitesse théorique (Gflops / s) du GPU NVIDIA et du CPU Intel au fil des ans:
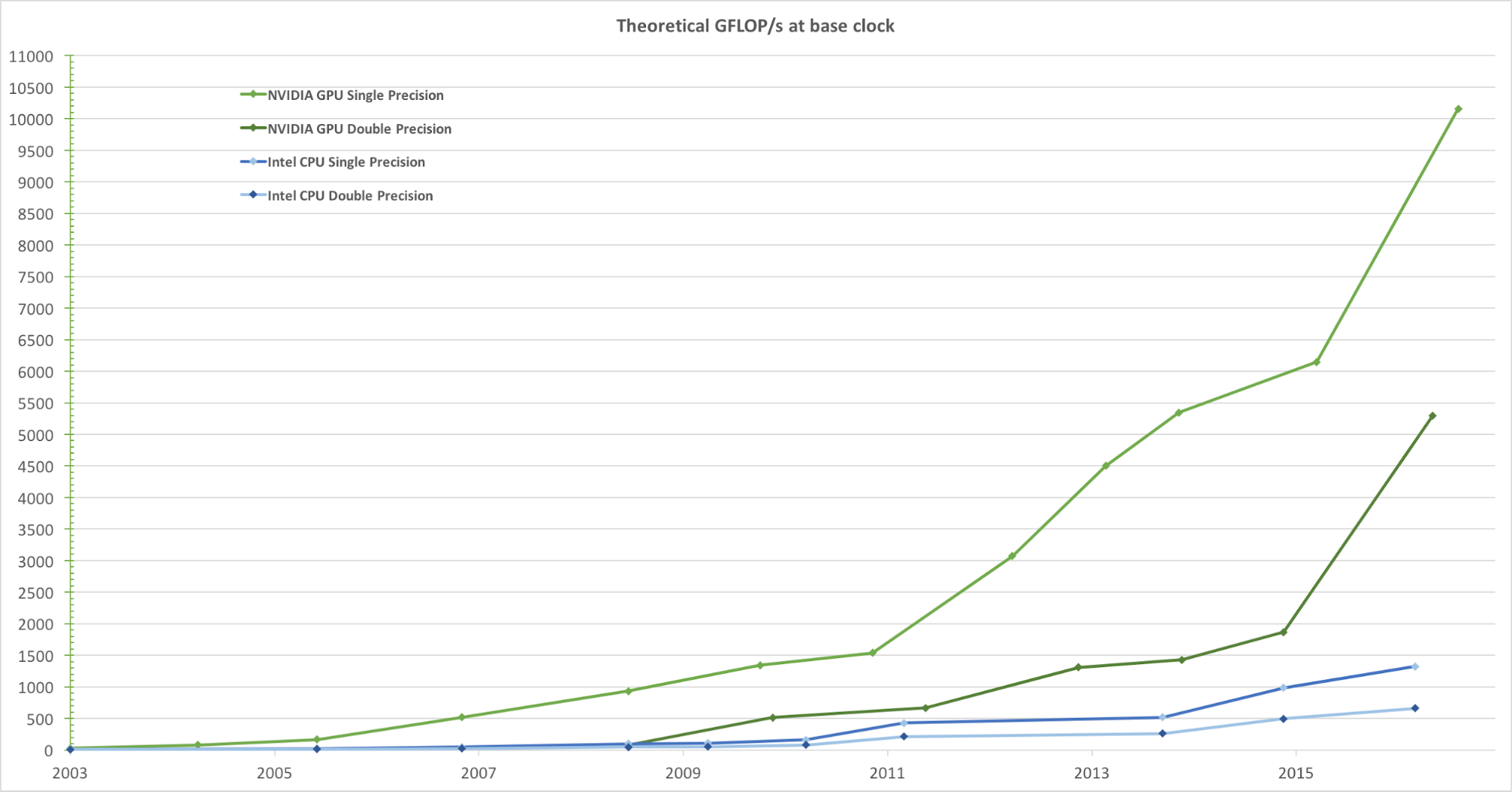
Figure 1. Comparaison des performances du processeur à virgule flottante simple précision sur plusieurs années. Image tirée du guide de programmation CUDA C de Nvidia.
Lors du développement du mécanisme de demande d'analyse en temps réel, la décision d'intégrer le GPU était naturelle. Dans Uber, une demande d'analyse en temps réel typique nécessite de traiter les données en quelques jours avec des millions, voire des milliards d'enregistrements, puis de les filtrer et de les résumer en peu de temps. Cette tâche de calcul s'intègre parfaitement dans le modèle de traitement parallèle GPU à usage général, car ils:
- Ils traitent les données en parallèle à très grande vitesse.
- Ils fournissent une vitesse de calcul plus élevée (Gflops / s), ce qui les rend excellents pour effectuer des tâches de calcul complexes (dans des blocs de données) qui peuvent être parallélisées.
- Ils fournissent des performances supérieures (sans délai) dans l'échange de données entre l'unité de calcul et le stockage (ALU et GPU de mémoire globale) par rapport aux unités de traitement centrales (CPU), ce qui les rend idéales pour le traitement des tâches d'E / S de mémoire parallèle, qui nécessite une quantité importante de données.
En nous concentrant sur l'utilisation d'une base de données analytique basée sur GPU, nous - du point de vue de nos besoins - avons évalué plusieurs solutions analytiques existantes qui utilisent des GPU:
- Kinetica , un outil analytique basé sur GPU, est arrivé sur le marché en 2009, initialement destiné à l'armée américaine et aux agences de renseignement. Bien qu'elle démontre le potentiel élevé de la technologie GPU dans l'analyse, nous avons constaté que pour nos conditions d'utilisation, de nombreuses fonctions clés manquent, y compris la modification du schéma, l'insertion ou la mise à jour partielle, la compression des données, la configuration du disque et de la mémoire au niveau de la colonne, ainsi qu'une connexion relations géospatiales.
- OmniSci , un module de requête SQL open source, semblait être une option prometteuse, mais lors de l'évaluation du produit, nous avons réalisé qu'il lui manquait des fonctionnalités importantes pour une utilisation dans Uber, telles que la déduplication. Bien qu'OminiSci ait introduit le code open source de son projet en 2017, après avoir analysé leur solution basée sur C ++, nous sommes arrivés à la conclusion que ni changer ni brancher leur base de code n'est pratiquement faisable.
- Les outils d'analyse en temps réel basés sur GPU, notamment GPUQP , CoGaDB , GPUDB , Ocelot , OmniDB et Virginian , sont souvent utilisés dans les établissements de recherche et d'enseignement. Cependant, compte tenu de leurs objectifs académiques, ces décisions se concentrent sur le développement d'algorithmes et de tests de concepts, plutôt que sur la résolution de problèmes réels. Pour cette raison, nous ne les avons pas pris en compte - dans les conditions de notre volume et de notre échelle.
Dans l'ensemble, ces systèmes démontrent l'énorme avantage et le potentiel du traitement des données à l'aide de la technologie GPU, et ils nous ont inspiré pour créer notre propre solution d'analyse GPU en temps réel adaptée aux besoins d'Uber. Sur la base de ces concepts, nous avons développé et ouvert le code source d'AresDB.
Présentation de l'architecture AresDB
À un niveau élevé, AresDB stocke la plupart des données dans la mémoire hôte (RAM, qui est connectée au CPU), utilise le CPU pour traiter les données reçues et les disques pour récupérer les données. Pendant la période de demande, AresDB transfère les données de la mémoire hôte vers la mémoire GPU pour un traitement parallèle dans le GPU. Comme le montre la figure 2 ci-dessous, AresDB comprend le stockage en mémoire, le stockage des métadonnées et le disque:

Figure 2. L'architecture unique d'AresDB comprend le stockage en mémoire, le disque et le stockage des métadonnées.
Des tables
Contrairement à la plupart des systèmes de gestion de bases de données relationnelles (SGBDR), AresDB n'a pas de portée de base de données ou de schéma. Toutes les tables appartiennent à la même portée dans un cluster / instance d'AresDB, ce qui permet aux utilisateurs d'y accéder directement. Les utilisateurs stockent leurs données sous forme de tables de faits et de tables de dimensions.
Table de faits
La table de faits stocke un flux infini d'événements de séries chronologiques. Les utilisateurs utilisent une table de faits pour stocker les événements / faits qui se produisent en temps réel, et chaque événement est associé à l'heure de l'événement, et la table est souvent interrogée par l'heure de l'événement. À titre d'exemple du type d'informations stockées dans la table de faits, nous pouvons nommer les trajets, où chaque trajet est un événement, et l'heure de la demande de voyage est souvent appelée l'heure de l'événement. Si plusieurs horodatages sont associés à un événement, un seul horodatage est indiqué comme heure de l'événement et s'affiche dans la table des faits.
Table de mesure
Le tableau de mesure enregistre les caractéristiques actuelles des installations (y compris les villes, les clients et les chauffeurs). Par exemple, les utilisateurs peuvent stocker des informations sur la ville, en particulier le nom de la ville, le fuseau horaire et le pays, dans le tableau de mesure. Contrairement aux tables de faits, qui ne cessent de croître, les tables de dimensions sont toujours de taille limitée (par exemple, pour Uber, la table des villes est limitée par le nombre réel de villes dans le monde). Les tableaux de mesure ne nécessitent pas de colonne de temps spéciale.
Types de données
Le tableau ci-dessous montre les types de données actuels pris en charge par AresDB:
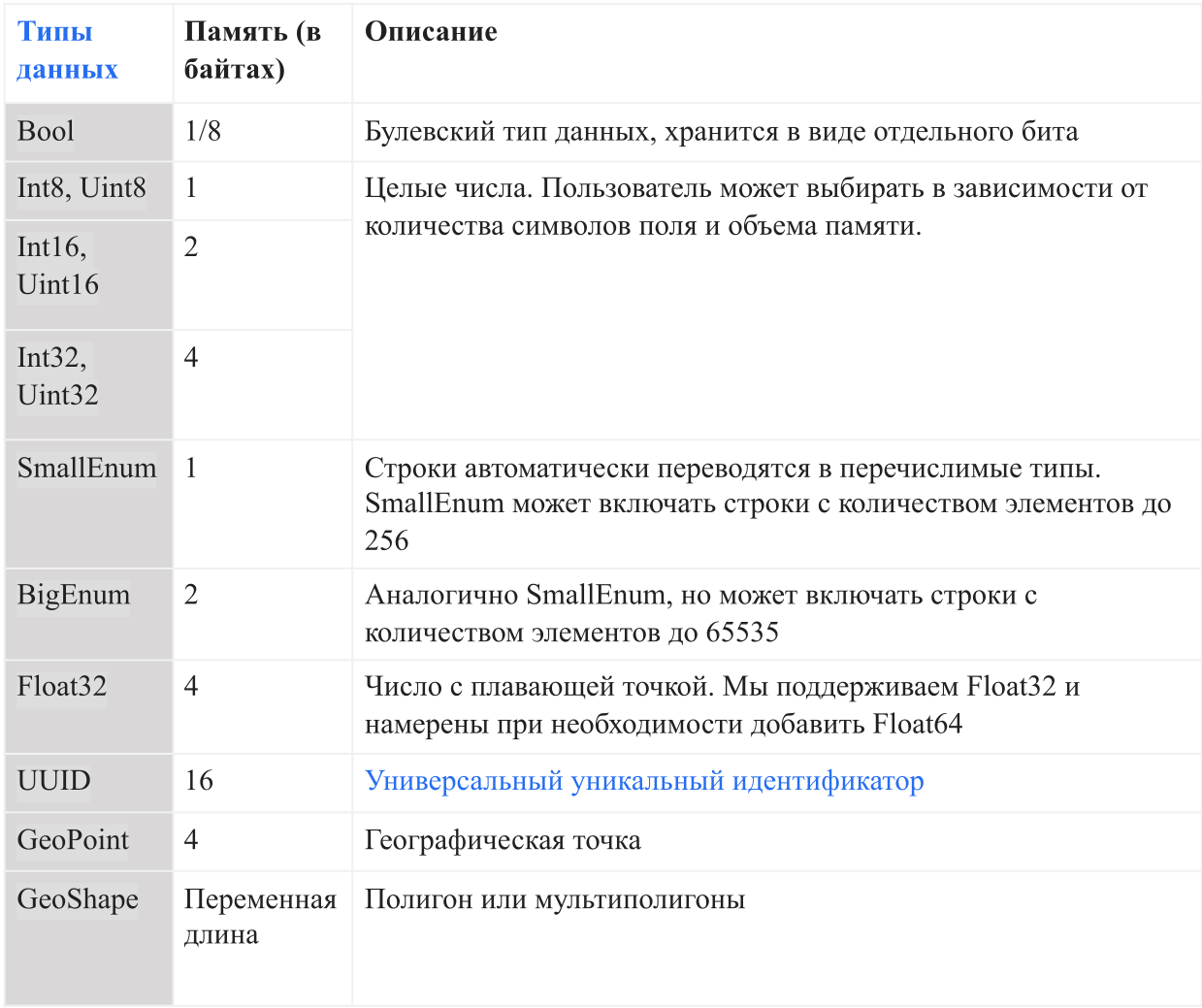
Dans AresDB, les chaînes sont automatiquement converties en énumérations avant d'entrer dans la base de données pour augmenter la commodité du stockage et l'efficacité des requêtes. Cela permet des vérifications d'égalité sensibles à la casse, mais ne prend pas en charge les opérations avancées telles que la concaténation, les sous-chaînes, les masques et la correspondance d'expressions régulières. À l'avenir, nous avons l'intention d'ajouter l'option de support de ligne complète.
Fonctions principales
L'architecture AresDB prend en charge les fonctionnalités suivantes:
- Stockage sur colonne avec compression pour augmenter l'efficacité du stockage (moins de mémoire en octets pour le stockage des données) et l'efficacité des requêtes (moins d'échange de données entre la mémoire CPU et la mémoire GPU lors du traitement d'une demande)
- Mise à jour ou insertion en temps réel avec déduplication de clé primaire pour améliorer la précision des données et mettre à jour les données en temps réel en quelques secondes
- Traitement des requêtes GPU pour un traitement des données GPU hautement parallèle avec une faible latence des requêtes (de quelques fractions de seconde à plusieurs secondes)
Stockage sur colonne
Vecteur
AresDB stocke toutes les données dans un format de colonne. Les valeurs de chaque colonne sont stockées en tant que vecteur de valeur de colonne. Le marqueur de confiance / incertitude des valeurs de chaque colonne est stocké dans un vecteur zéro séparé, tandis que le marqueur de confiance de chaque valeur est présenté sous la forme d'un bit.
Stockage actif
AresDB stocke les données de colonne non compressées et non triées (vecteurs actifs) dans le stockage actif. Les enregistrements de données dans le stockage actif sont divisés en paquets (actifs) d'un volume donné. De nouveaux paquets sont créés lors de la réception des données, tandis que les anciens paquets sont supprimés après l'archivage des enregistrements. L'index de clé primaire est utilisé pour localiser la déduplication et mettre à jour les enregistrements. La figure 3 ci-dessous montre comment nous organisons les enregistrements actifs et utilisons la valeur de clé primaire pour déterminer leur emplacement:
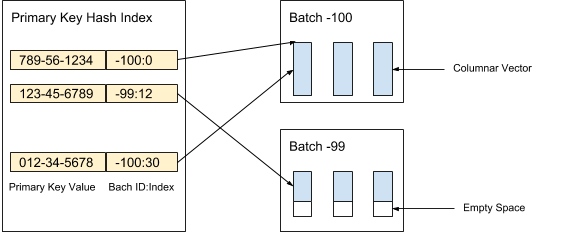
Figure 3. Nous utilisons la valeur de clé primaire pour déterminer l'emplacement du package et la position de chaque enregistrement dans le package.
Les valeurs de chaque colonne du package sont stockées en tant que vecteur de colonne. Le marqueur de fiabilité / incertitude des valeurs dans chaque vecteur de valeur est stocké en tant que vecteur zéro séparé, et le marqueur de fiabilité de chaque valeur est présenté comme un bit. Dans la figure 4 ci-dessous, nous proposons un exemple avec cinq valeurs pour la colonne city_id :
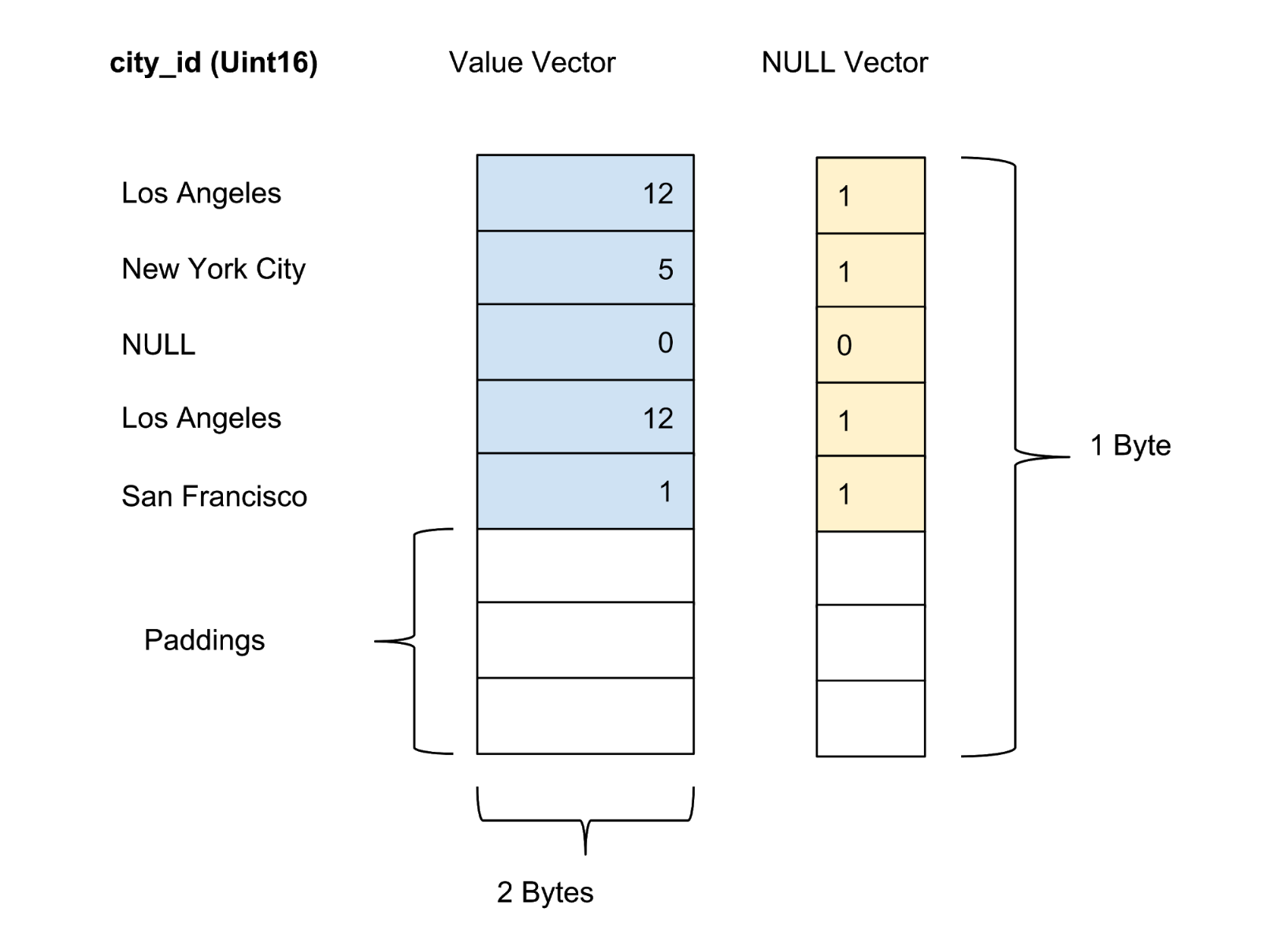
Figure 4. Nous stockons les valeurs (valeur réelle) et les vecteurs zéro (marqueur de confiance) des colonnes non compressées dans le tableau de données.
Stockage d'archives
AresDB stocke également les données de colonne complétées, triées et compressées (vecteurs d'archive) dans le stockage d'archive via des tables de faits. Les enregistrements dans le stockage d'archives sont également distribués par lots. Contrairement aux packages actifs, le package d'archives stocke les enregistrements par jour en fonction du temps universel coordonné (UTC). Un paquet d'archives utilise le nombre de jours comme identifiant de paquet depuis Unix Epoch.
Les enregistrements sont stockés sous forme triée conformément à un ordre de tri des colonnes défini par l'utilisateur. Comme le montre la figure 5 ci-dessous, nous trions d'abord par la colonne city_id , puis par la colonne status:
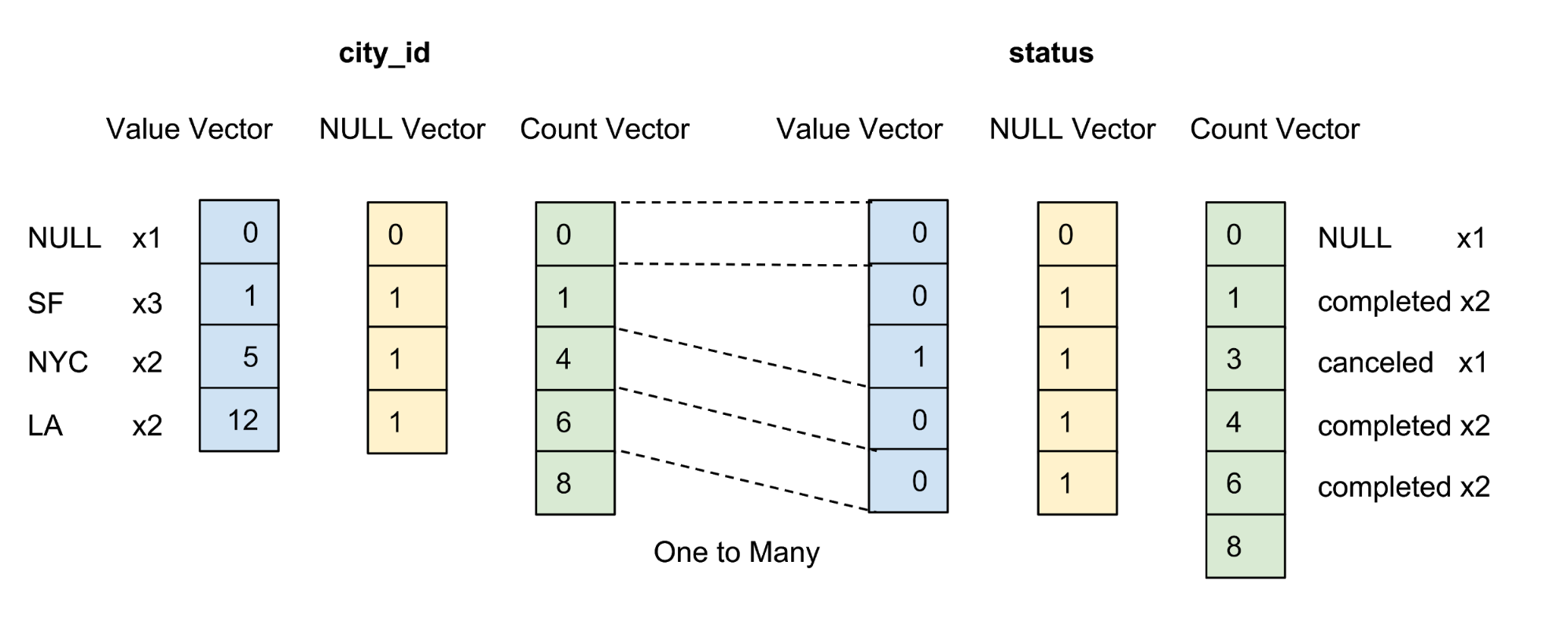
Figure 5. Nous trions toutes les lignes par city_id, puis par état, puis compressons chaque colonne par codage de groupe. Après tri et compression, chaque colonne recevra un vecteur comptable.
L'objectif de la définition de l'ordre de tri utilisateur pour les colonnes est le suivant:
- Maximiser l'effet de compression en triant les colonnes avec un petit nombre d'éléments en premier lieu. La compression maximale améliore l'efficacité du stockage (moins d'octets sont nécessaires pour stocker les données) et l'efficacité des requêtes (moins d'octets sont transférés entre la mémoire CPU et la mémoire GPU).
- Fournir un pré-filtrage pratique basé sur la plage pour les filtres équivalents courants, par exemple city_id = 12. Le pré-filtrage minimise le nombre d'octets nécessaires pour transférer des données entre la mémoire CPU et la mémoire GPU, ce qui maximise l'efficacité des requêtes.
Une colonne n'est compressée que si elle est présente dans l'ordre de tri spécifié par l'utilisateur. Nous n'essayons pas de compresser les colonnes avec un grand nombre d'éléments, car cela économise peu de mémoire.
Après le tri, les données de chaque colonne qualifiée sont compressées à l'aide d'une option de codage de groupe spécifique. En plus du vecteur valeur et du vecteur zéro, nous introduisons un vecteur comptable pour représenter à nouveau la même valeur.
Réception de données en temps réel avec prise en charge des fonctions de mise à jour et d'insertion
Les clients reçoivent des données via l'API HTTP en publiant un service pack. Un Service Pack est un format binaire ordonné spécial qui minimise l'utilisation de l'espace tout en conservant un accès aléatoire aux données.
Lorsque AresDB reçoit le Service Pack, il écrit d'abord le Service Pack dans le journal des opérations de récupération. Lorsqu'un service pack est ajouté à la fin du journal des événements, AresDB identifie et ignore les entrées tardives dans les tables de faits à utiliser dans le stockage actif. Un enregistrement est considéré comme «en retard» si l'heure de l'événement est antérieure à l'heure archivée de l'événement de déconnexion. Pour les enregistrements qui ne sont pas considérés comme «en retard», AresDB utilise l'index de clé primaire pour localiser le package dans le magasin actif où vous souhaitez les insérer. Comme le montre la figure 6 ci-dessous, les nouveaux enregistrements (non rencontrés précédemment en fonction de la valeur de la clé primaire) sont insérés dans l'espace vide et les enregistrements existants sont mis à jour directement:
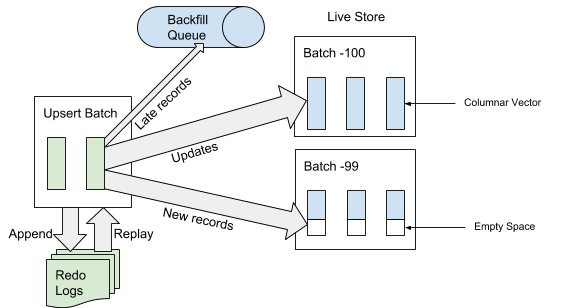
Figure 6. Lorsque des données sont reçues, après avoir ajouté le Service Pack au journal des événements, les entrées «tardives» sont ajoutées à la file d'attente inversée et les autres entrées au stockage actif.
Archivage
Lorsque les données sont reçues, les enregistrements sont soit ajoutés / mis à jour dans le stockage actif, soit ajoutés à la file d'attente inversée, en attente de placement dans le stockage d'archives.
Nous commençons périodiquement un processus planifié, appelé archivage, en relation avec les enregistrements du stockage actif pour attacher de nouveaux enregistrements (enregistrements qui n'ont jamais été archivés auparavant) au stockage d'archives. Le processus d'archivage traite uniquement les enregistrements dans le stockage actif avec l'heure de l'événement dans la plage comprise entre l'ancien temps d'arrêt (temps d'arrêt du dernier processus d'archivage) et le nouveau temps d'arrêt (nouveau temps d'arrêt basé sur le paramètre de délai d'archivage dans le schéma de table).
L'heure de l'événement d'enregistrement est utilisée pour déterminer dans quels enregistrements de packages d'archives doivent être combinés lors du compactage des données d'archives dans des packages quotidiens. L'archivage ne nécessite pas de déduplication de l'index de la valeur de la clé primaire lors de la fusion, car seuls les enregistrements compris entre l'ancien et le nouveau temps d'arrêt sont archivés.
La figure 7 ci-dessous montre un graphique en fonction de l'heure de l'événement d'un enregistrement particulier.
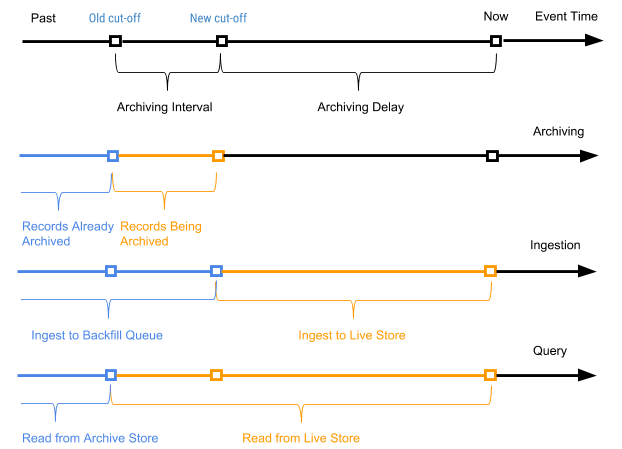
Figure 7. Nous utilisons l'heure de l'événement et l'heure du trajet pour définir les enregistrements comme nouveaux (actifs) et anciens (l'heure de l'événement est antérieure à l'heure archivée de l'événement de voyage).
Dans ce cas, l'intervalle d'archivage est l'intervalle de temps entre les deux processus d'archivage, et le délai d'archivage est la période après l'heure de l'événement, mais jusqu'à ce que l'événement soit archivé. Les deux paramètres sont définis dans les paramètres du schéma de table AresDB.
Remblai
Comme le montre la figure 7 ci-dessus, les anciens enregistrements (dont l'heure de l'événement est antérieure à l'heure d'archivage de l'événement d'arrêt) pour les tables de faits sont ajoutés à la file d'attente inversée et sont finalement traités dans le cadre du processus de renvoi. Les déclencheurs de ce processus sont également le temps ou la taille de la file d'attente inverse, si elle atteint un niveau seuil. Comparé au processus d'ajout de données au stockage actif, le remplissage est asynchrone et relativement plus cher en termes de ressources CPU et mémoire. Le remblayage est utilisé dans les scénarios suivants:
- Traitement de données aléatoires et très tardives
- Capture manuelle des données historiques à partir d'un flux de données en amont
- Saisie de données historiques dans les colonnes récemment ajoutées
Contrairement à l'archivage, le processus de renvoi est idempotent et nécessite une déduplication basée sur la valeur de la clé primaire. Les données remplissables seront finalement visibles par les requêtes.
La file d'attente inversée est conservée en mémoire avec une taille prédéfinie et avec une charge importante de remplissage, le processus sera bloqué pour le client jusqu'à ce que la file d'attente soit effacée en démarrant le processus de remplissage.
Traitement des demandes
Dans l'implémentation actuelle, l'utilisateur doit utiliser le langage de requête Ares (AQL) créé par Uber pour exécuter des requêtes dans AresDB. AQL est un langage efficace pour les requêtes analytiques de séries chronologiques et ne suit pas la syntaxe SQL standard comme «SELECT FROM WHERE GROUP BY» comme d'autres langages similaires à SQL. A la place, AQL est utilisé dans les champs structurés et peut être inclus dans les objets JSON, YAML et Go. Par exemple, au lieu de la /SELECT (*) /FROM /GROUP BY city_id, /WHERE = «» /AND request_at >= 1512000000 , la variante AQL équivalente en JSON s'écrit comme suit:
{ “table”: “trips”, “dimensions”: [ {“sqlExpression”: “city_id”} ], “measures”: [ {“sqlExpression”: “count(*)”} ], ;”> “rowFilters”: [ “status = 'completed'” ], “timeFilter”: { “column”: “request_at”, “from”: “2 days ago” } }
Au format JSON, AQL offre aux développeurs d'un tableau de bord et d'un système décisionnel un algorithme de requête de programme plus pratique que SQL, leur permettant de composer facilement des requêtes et de les manipuler à l'aide de code sans se soucier de choses comme l'injection SQL. Il agit comme un format de requête universel pour les architectures typiques des navigateurs Web, des serveurs externes et internes jusqu'à la base de données (AresDB). De plus, AQL fournit une syntaxe pratique pour le filtrage par heure et le traitement par lots avec prise en charge de son propre fuseau horaire. En outre, le langage prend en charge un certain nombre de fonctions, telles que les sous-requêtes implicites, pour éviter les erreurs courantes dans les requêtes et facilite le processus d'analyse et de réécriture des requêtes pour les développeurs de l'interface interne.
Malgré les nombreux avantages qu'offre AQL, nous savons bien que la plupart des ingénieurs connaissent mieux SQL. Fournir une interface SQL pour exécuter les requêtes est l'une des prochaines étapes que nous examinerons dans le cadre de nos efforts pour améliorer l'interaction avec les utilisateurs d'AresDB.
L'organigramme d'exécution des requêtes AQL est illustré à la figure 8 ci-dessous:
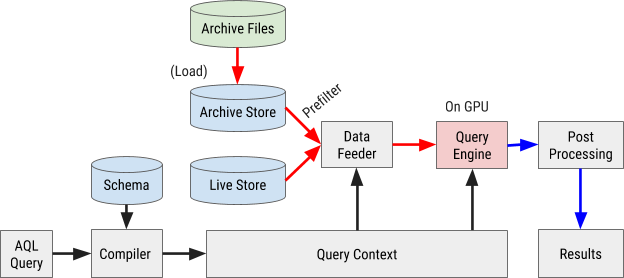
Figure 8. L'organigramme de requête AresDB utilise notre propre langage de requête AQL pour traiter et récupérer rapidement et efficacement les données.
Compilation de requêtes
Une requête AQL est compilée dans le contexte de requête interne. Les expressions dans les filtres, les mesures et les paramètres sont analysées dans des arbres de syntaxe abstraite (AST) pour un traitement ultérieur via un processeur graphique (GPU).
Chargement des données
AresDB utilise des préfiltres pour filtrer les données d'archives à moindre coût avant de les envoyer au GPU pour un traitement parallèle. Étant donné que les données archivées sont triées selon l'ordre des colonnes configuré, certains filtres peuvent utiliser cet ordre de tri et la méthode de recherche binaire pour déterminer la plage de correspondance appropriée. En particulier, des filtres équivalents pour toutes les colonnes X initialement triées et un filtre de plage facultatif pour les colonnes triées X + 1 peuvent être utilisés comme filtres préliminaires, comme le montre la figure 9 ci-dessous.

Figure 9. AresDB pré-filtre les données de la colonne avant de les envoyer au GPU pour traitement.
Après le pré-filtrage, seules les valeurs vertes (répondant à la condition de filtre) doivent être envoyées au GPU pour un traitement parallèle. Les données d'entrée sont chargées dans le GPU et traitées un paquet à la fois. Cela inclut les packages actifs et les packages d'archivage.
AresDB utilise les flux CUDA pour le pipelining et le traitement des données. Pour chaque demande, deux flux sont appliqués alternativement pour un traitement en deux étapes qui se chevauchent. Dans la figure 10 ci-dessous, nous proposons un graphique illustrant ce processus.
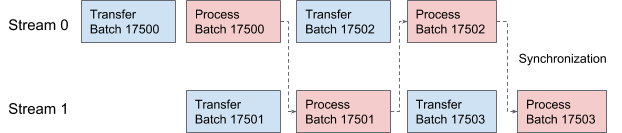
Figure 10. Dans AresDB, deux threads CUDA transmettent et traitent alternativement des données.
Exécution de requête
Pour plus de simplicité, AresDB utilise la bibliothèque Thrust pour implémenter des procédures d'exécution de requête, qui propose des blocs d'un algorithme parallèle finement réglé pour une implémentation rapide des requêtes dans l'outil actuel.
Dans Thrust, les données vectorielles d'entrée et de sortie sont évaluées à l'aide d'itérateurs à accès aléatoire. Chaque thread GPU recherche les itérateurs d'entrée dans sa position de travail, lit les valeurs et effectue des calculs, puis écrit le résultat à la position correspondante dans l'itérateur de sortie.
Pour évaluer les expressions AresDB, le modèle «un opérateur par cœur» (OOPK) suit.
Dans la figure 11 ci-dessous, cette procédure est illustrée à l'aide de l'exemple AST généré à partir de l'expression de dimension request_at – request_at % 86400 au stade de la compilation de la demande:
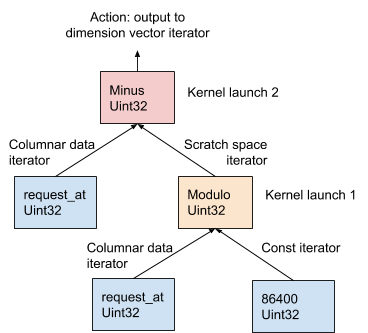
Figure 11. AresDB utilise le modèle OOPK pour évaluer les expressions.
Dans le modèle OOPK, le moteur de requête AresDB contourne chaque nœud feuille de l'arborescence AST et renvoie un itérateur pour le nœud source. Si le nœud racine est également fini, l'action racine est effectuée directement sur l'itérateur d'entrée.
Pour chaque nœud non racine non final ( opération modulo dans cet exemple), un vecteur d'espace de travail temporaire est alloué pour stocker le résultat intermédiaire obtenu à partir de l'expression request_at% 86400 . À l'aide de Thrust, une fonction de noyau est lancée pour calculer le résultat de cette instruction dans le GPU. Les résultats sont stockés dans l'itérateur de l'espace de travail.
Pour un nœud racine, la fonction noyau s'exécute de la même manière que pour un nœud non racine, non fini. Diverses actions de sortie sont effectuées en fonction du type d'expression, qui est décrit en détail ci-dessous:
- Filtrage pour réduire le nombre d'éléments vectoriels d'entrée
- Enregistrement des données de sortie de mesure dans un vecteur de mesure pour une fusion ultérieure des données
- Enregistrer la sortie des paramètres dans le vecteur de paramètres pour une fusion de données ultérieure
Après avoir évalué l'expression, un tri et une transformation sont effectués pour enfin combiner les données. Dans les opérations de tri et de transformation, nous utilisons les valeurs du vecteur de dimension comme valeurs clés pour le tri et la transformation, et les valeurs du vecteur de paramètres comme valeurs pour combiner les données. Ainsi, les lignes avec des valeurs de dimension similaires sont regroupées et combinées. La figure 12 ci-dessous montre ce processus de tri et de conversion.
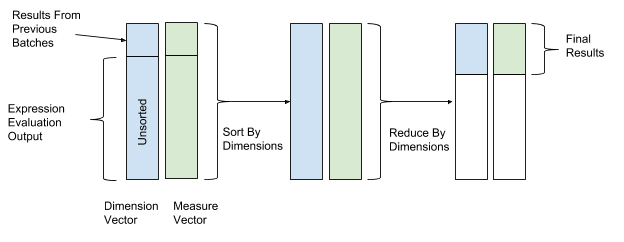
Figure 12. Après avoir évalué l'expression, AresDB trie et convertit les données en fonction des valeurs clés des vecteurs de mesure (valeur clé) et des paramètres (valeur).
AresDB prend également en charge les fonctions de requête avancées suivantes:
- Join : AresDB prend actuellement en charge une option de jointure de hachage entre la table de faits et la table de dimension
- Estimation du nombre d'éléments Hyperloglog: AresDB utilise l'algorithme Hyperloglog
- Geo Intersect : AresDB ne prend actuellement en charge que les opérations interconnectées entre GeoPoint et GeoShape
Gestion des ressources
En tant que base de données basée sur la mémoire interne, AresDB doit gérer les types d'utilisation de la mémoire suivants:
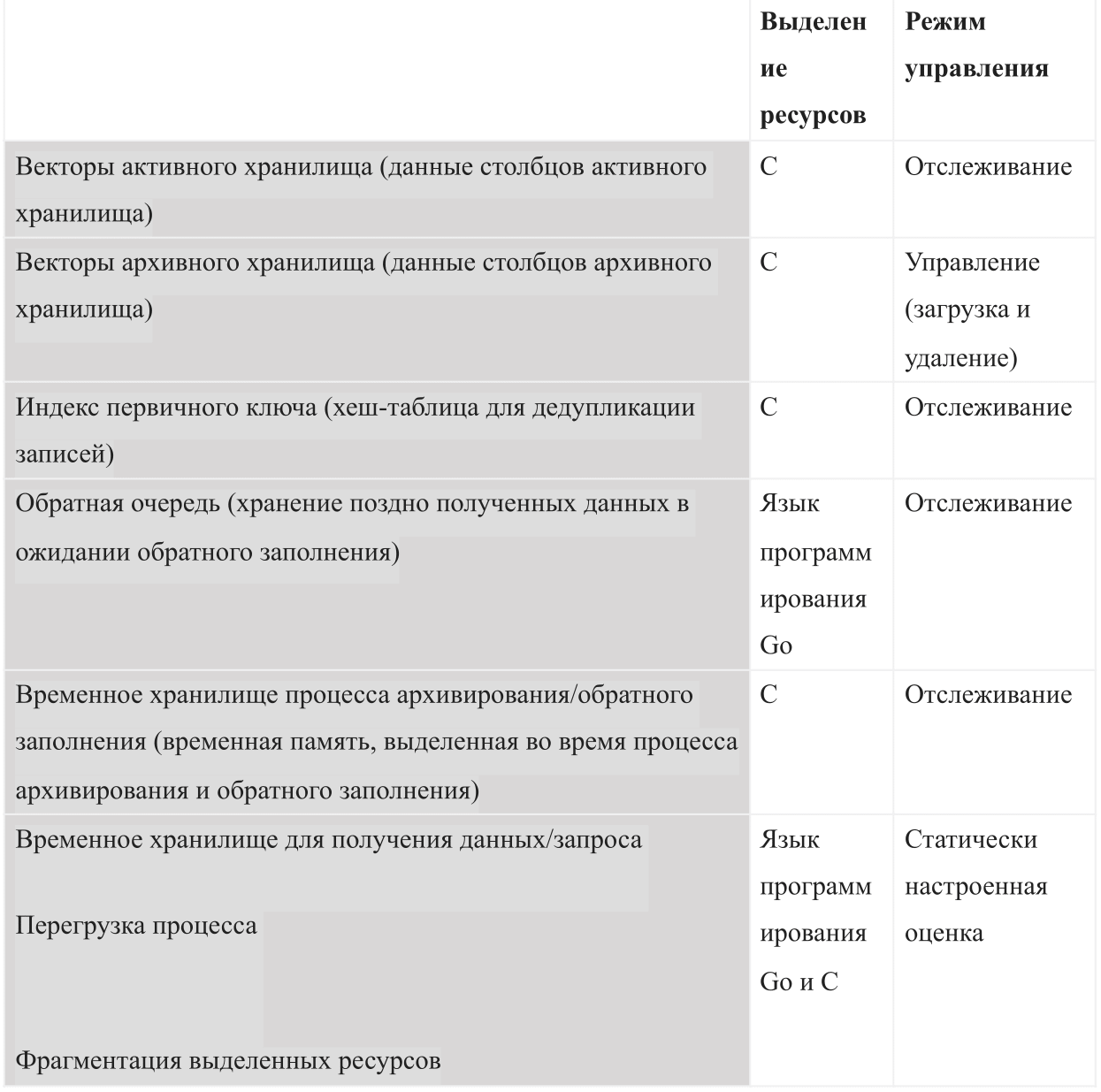
Au démarrage d'AresDB, il utilise le budget de mémoire partagée configuré. Le budget est divisé en six types de mémoire et devrait également laisser suffisamment d'espace pour le système d'exploitation et d'autres processus. Ce budget comprend également une estimation de congestion configurée statiquement, un magasin de données actif surveillé par le serveur et des données archivées que le serveur peut décider de télécharger et de supprimer en fonction du budget de mémoire restant.
La figure 13 ci-dessous montre le modèle de mémoire hôte AresDB.
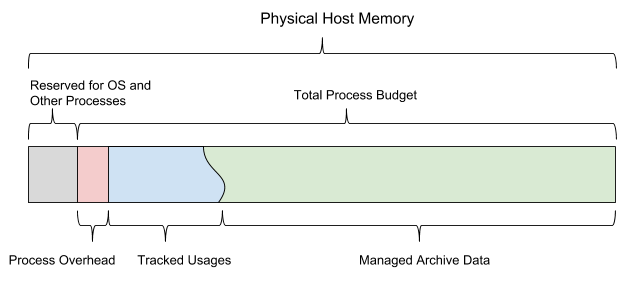
Figure 13. AresDB gère sa propre utilisation de la mémoire afin qu'elle ne dépasse pas le budget de processus total configuré.
AresDB permet aux utilisateurs de définir des jours de préchargement et des priorités au niveau des colonnes pour les tables de faits et les données archivées de préchargement uniquement les jours de préchargement. Les données qui n'ont pas été téléchargées précédemment sont chargées en mémoire à partir du disque sur demande. Une fois rempli, AresDB supprime également les données archivées de la mémoire hôte. Les principes de suppression d'AresDB sont basés sur les paramètres suivants: le nombre de jours de préchargement, les priorités des colonnes, le jour de compilation du package et la taille de la colonne.
AresDB gère également plusieurs périphériques GPU et simule les ressources des périphériques en tant que threads GPU et mémoire de périphérique, en suivant l'utilisation de la mémoire GPU pour le traitement des demandes. AresDB gère les périphériques GPU via un gestionnaire de périphériques qui modélise les ressources des périphériques GPU en deux dimensions (threads GPU et mémoire des périphériques) et suit l'utilisation de la mémoire lors du traitement des demandes. Après avoir compilé la demande, AresDB permet aux utilisateurs d'estimer la quantité de ressources nécessaires pour terminer la demande. Les besoins en mémoire du périphérique doivent être satisfaits avant que la demande ne soit résolue; s'il n'y a actuellement pas assez de mémoire sur un périphérique, la demande doit attendre. Actuellement, AresDB peut exécuter une ou plusieurs demandes sur le même périphérique GPU en même temps si le périphérique répond à toutes les exigences de ressources.
Dans l'implémentation actuelle, AresDB ne met pas en cache les entrées dans la mémoire de l'appareil pour les réutiliser dans plusieurs requêtes. AresDB vise à prendre en charge les requêtes sur des ensembles de données constamment mis à jour en temps réel et mal mis en cache correctement. Dans les futures versions d'AresDB, nous avons l'intention d'implémenter des fonctions de mise en cache des données dans la mémoire du GPU, ce qui aidera à optimiser les performances des requêtes.
Chez Uber, nous utilisons AresDB pour créer des tableaux de bord pour obtenir des informations commerciales en temps réel. AresDB est responsable du stockage des événements principaux avec des mises à jour constantes et du calcul des mesures critiques pour eux en une fraction de seconde grâce aux ressources GPU à faible coût, afin que les utilisateurs puissent utiliser les tableaux de bord de manière interactive. Par exemple, les données de voyage anonymisées qui ont une longue période de validité dans l'entrepôt de données sont mises à jour par plusieurs services, y compris notre système d'expédition, nos systèmes de paiement et de tarification. Pour utiliser efficacement les données de voyage, les utilisateurs divisent et décomposent les données en différentes dimensions pour mieux comprendre les solutions en temps réel.
Lorsque vous utilisez AresDB, le tableau de bord Uber est un tableau de bord d'analyse répandu qui est utilisé par les équipes de l'entreprise pour produire des mesures pertinentes et des réponses en temps réel pour améliorer l'expérience utilisateur.
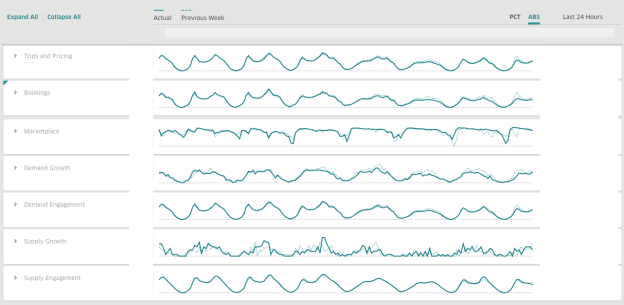
14. Uber AresDB .
, , :
( )

( )

AresDB
, , AresDB :

, , , , , .
AresDB , Apache Kafka , , Apache Flink Apache Spark .
AresDB
, « » « ». , -. 24 AQL:

:
, , .

, AresDB , , . AresDB , , .
AresDB Uber , . , , AresDB .
:
- : AresDB, , , .
- : AresDB 2018 , , AresDB .
- : , , , .
- : , (LLVM) GPU.
AresDB Apache. AresDB .
, .
Remerciements
(Kate Zhang), (Jennifer Anderson), (Nikhil Joshi), (Abhi Khune), (Shengyue Ji), (Chinmay Soman), (Xiang Fu), (David Chen) (Li Ning) , !