Bonjour à tous.
J'ai décidé de partager une solution simple et volumineuse à mon avis d'un réseau de neurones en C ++.
Pourquoi ces informations devraient-elles être intéressantes?Réponse: J'ai essayé de programmer le travail du perceptron multicouche dans un ensemble minimal, afin qu'il puisse être configuré comme j'aime en quelques lignes de code, et la mise en œuvre des algorithmes de base pour travailler sur «C» vous permettra de transférer facilement des langues orientées vers «C» (dans et à tout autre)
sans utiliser de bibliothèques tierces!Veuillez jeter un coup d'œil à ce qui en est sorti
Je ne vais pas vous parler de l'
objectif des réseaux de neurones , j'espère que vous n'avez pas été banni de
Google et que vous pourrez trouver les informations qui vous intéressent (objectif, capacités, applications, etc.).
Vous trouverez le
code source à la fin de l'article, mais pour l'instant, dans l'ordre.
Commençons l'analyse
1) Architecture et détails techniques
-
Perceptron multicouche avec la possibilité de configurer n'importe quel nombre de couches avec une largeur donnée. Ci-dessous est présenté
exemple de configurationmyNeuero.cppinputNeurons = 100;
Notez que le réglage de la largeur de l'entrée et de la sortie pour chaque couche est effectué selon une certaine règle - l'entrée de la couche actuelle = la sortie de la précédente. Une exception est la couche d'entrée.
Ainsi, vous avez la possibilité de configurer n'importe quelle configuration manuellement ou selon une règle donnée avant de compiler ou après la compilation pour lire les données des fichiers source.
- mise en place du mécanisme de
rétro-propagation des erreurs avec possibilité de régler la vitesse d'apprentissage
myNeuero.h #define learnRate 0.1
- installation des
poids initiauxmyNeuero.h #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5))
Remarque : s'il y a plus de trois couches (nlCount> 4), alors pow (out, -0.5) doit être augmenté de sorte que lorsque le signal passe directement, son énergie ne se réduit pas à 0. Exemple pow (out, -0.2)
- la
base du code en C. Les algorithmes de base et le stockage des coefficients de pondération sont implémentés comme une structure en C, tout le reste est la coquille de la fonction appelante de cette structure, c'est aussi le reflet de l'une des couches prises séparément
Structure de couchemyNeuero.h struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; };
2) Application
Le test du projet avec l'ensemble mnist a réussi, nous avons réussi à obtenir une probabilité de reconnaissance conditionnelle de l'écriture manuscrite de 0,9795 (nlCount = 4, learnRate = 0,03 et plusieurs époques). Le but principal du test était de tester les performances du réseau de neurones, avec lequel il s'est adapté.
Ci-dessous, nous considérons les travaux sur la
"tâche conditionnelle" .
Données sources:-2 vecteurs d'entrée aléatoires de 100 valeurs
réseau de neurones avec génération aléatoire de poids
-2 objectifs fixés
Le code dans la fonction main ()
{
Le résultat du réseau neuronal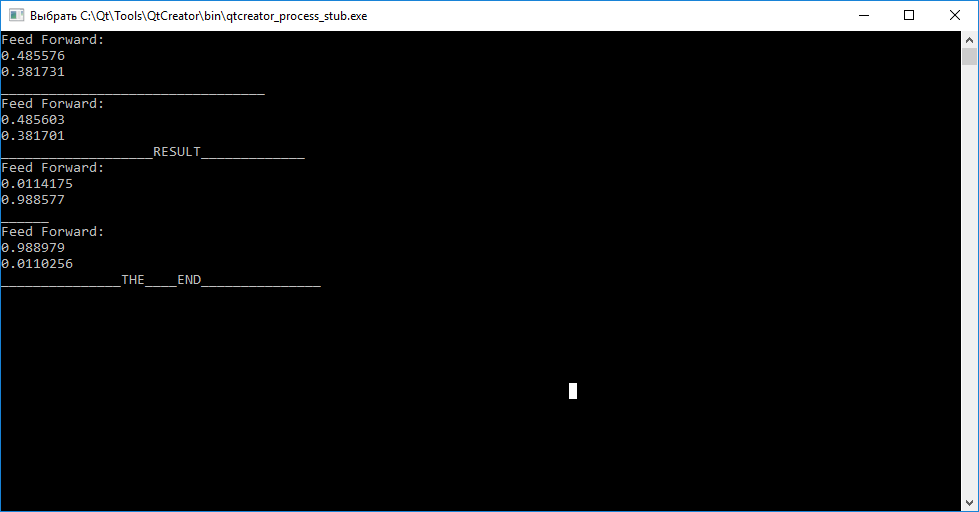
Résumé
Comme vous pouvez le voir, appeler la fonction de requête (entrées) avant l'entraînement pour chacun des vecteurs ne nous permet pas de juger de leurs différences. En outre, en appelant la fonction train (entrée, cible), pour la formation dans le but d'arranger les coefficients de poids de sorte que le réseau neuronal puisse ensuite distinguer les vecteurs d'entrée.
Après avoir terminé la formation, nous observons que la tentative de mappage du vecteur «abc» à «tar1» et «cba» à «tar2» a échoué.
Vous avez la possibilité, en utilisant le code source, de tester indépendamment les performances et d'expérimenter la configuration!PS: ce code a été écrit depuis QtCreator, j'espère que vous pourrez facilement remplacer la sortie, laissez vos commentaires et commentaires.
PPS: si quelqu'un est intéressé par une analyse détaillée du travail d'écriture de struct nnLay {}, il y aura un nouveau message.
PPPS: J'espère que quelqu'un pourra utiliser le code orienté «C» pour le portage vers d'autres outils.
Code sourcemain.cpp #include <QCoreApplication> #include <QDebug> #include <QTime> #include "myneuro.h" int main(int argc, char *argv[]) { QCoreApplication a(argc, argv); myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) { abc[i] =(qrand()%98)*0.01+0.01; } float *cba = new float[100]; for(int i=0; i<100;i++) { cba[i] =(qrand()%98)*0.01+0.01; } //---------------------------------TARGETS----GENERATOR------------- float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- bb->query(abc); qDebug()<<"_________________________________"; bb->query(cba); int i=0; while(i<100000) { bb->train(abc,tar1); bb->train(cba,tar2); i++; } qDebug()<<"___________________RESULT_____________"; bb->query(abc); qDebug()<<"______"; bb->query(cba); qDebug()<<"_______________THE____END_______________"; return a.exec(); }
myNeuro.cpp #include "myneuro.h" #include <QDebug> myNeuro::myNeuro() { //-------- inputNeurons = 100; outputNeurons =2; nlCount = 4; list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); list[1].setIO(20,6); list[2].setIO(6,3); list[3].setIO(3,2); //----------------- // inputNeurons = 100; // outputNeurons =2; // nlCount = 2; // list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); // inputs = (float*) malloc((inputNeurons)*sizeof(float)); // targets = (float*) malloc((outputNeurons)*sizeof(float)); // list[0].setIO(100,10); // list[1].setIO(10,2); } void myNeuro::feedForwarding(bool ok) { list[0].makeHidden(inputs); for (int i =1; i<nlCount; i++) list[i].makeHidden(list[i-1].getHidden()); if (!ok) { qDebug()<<"Feed Forward: "; for(int out =0; out < outputNeurons; out++) { qDebug()<<list[nlCount-1].hidden[out]; } return; } else { // printArray(list[3].getErrors(),list[3].getOutCount()); backPropagate(); } } void myNeuro::backPropagate() { //-------------------------------ERRORS-----CALC--------- list[nlCount-1].calcOutError(targets); for (int i =nlCount-2; i>=0; i--) list[i].calcHidError(list[i+1].getErrors(),list[i+1].getMatrix(), list[i+1].getInCount(),list[i+1].getOutCount()); //-------------------------------UPD-----WEIGHT--------- for (int i =nlCount-1; i>0; i--) list[i].updMatrix(list[i-1].getHidden()); list[0].updMatrix(inputs); } void myNeuro::train(float *in, float *targ) { inputs = in; targets = targ; feedForwarding(true); } void myNeuro::query(float *in) { inputs=in; feedForwarding(false); } void myNeuro::printArray(float *arr, int s) { qDebug()<<"__"; for(int inp =0; inp < s; inp++) { qDebug()<<arr[inp]; } }
myNeuro.h #ifndef MYNEURO_H #define MYNEURO_H #include <iostream> #include <math.h> #include <QtGlobal> #include <QDebug> #define learnRate 0.1 #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) class myNeuro { public: myNeuro(); struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; }; void feedForwarding(bool ok); void backPropagate(); void train(float *in, float *targ); void query(float *in); void printArray(float *arr,int s); private: struct nnLay *list; int inputNeurons; int outputNeurons; int nlCount; float *inputs; float *targets; }; #endif // MYNEURO_H
UPD:
Les sources de vérification sur mnist sont par
le lien1) Projet
"
Github.com/mamkin-itshnik/simple-neuro-network "
Il y a aussi une description graphique du travail. En bref, lors de l'interrogation du réseau avec des données de test, vous obtenez la valeur de chacun des neurones de sortie (10 neurones correspondent à des nombres de 0 à 9). Pour prendre une décision sur le chiffre représenté, vous devez connaître l'indice du neurone maximum. Digit = index + 1 (n'oubliez pas d'où les numéros des tableaux sont numérotés))
2) MNIST
"
Www.kaggle.com/oddrationale/mnist-in-csv " (si vous avez besoin d'utiliser un ensemble de données plus petit, limitez simplement le compteur while lors de la lecture du fichier CSV du PS: il y a un exemple pour git)