Remarque perev. : Les employés de Tinder ont récemment partagé certains détails techniques de la migration de leur infrastructure vers Kubernetes. Le processus a duré près de deux ans et s'est traduit par le lancement sur K8 d'une plateforme à très grande échelle composée de 200 services hébergés sur 48 000 conteneurs. Quelles difficultés intéressantes les ingénieurs de Tinder ont-ils rencontrées et quels résultats sont-ils arrivés à lire dans cette traduction.
Pourquoi?
Il y a près de deux ans, Tinder a décidé de passer sa plateforme à Kubernetes. Kubernetes permettrait à l'équipe Tinder de conteneuriser et de passer à l'opération avec un effort minimal grâce à un
déploiement immuable . Dans ce cas, l'assemblage des applications, leur déploiement et l'infrastructure elle-même seraient uniquement déterminés par le code.
Nous avons également cherché une solution au problème d'évolutivité et de stabilité. Lorsque la mise à l'échelle est devenue critique, nous avons souvent dû attendre plusieurs minutes pour lancer de nouvelles instances EC2. Par conséquent, l'idée de lancer des conteneurs et de commencer à servir le trafic en quelques secondes au lieu de minutes est devenue très intéressante pour nous.
Le processus n'a pas été facile. Au cours de la migration, début 2019, le cluster Kubernetes a atteint une masse critique et nous avons commencé à faire face à divers problèmes en raison de la quantité de trafic, de la taille du cluster et du DNS. Au cours de ce voyage, nous avons résolu de nombreux problèmes intéressants liés au transfert de 200 services et à la maintenance du cluster Kubernetes, qui comprend 1 000 nœuds, 15 000 pods et 48 000 conteneurs de travail.
Comment?
Depuis janvier 2018, nous sommes passés par différentes étapes de migration. Nous avons commencé par conteneuriser tous nos services et les déployer dans des environnements de test Kubernetes. En octobre, le processus de transfert méthodique de tous les services existants vers Kubernetes a commencé. En mars de l'année suivante, la «relocalisation» était terminée et maintenant la plateforme Tinder fonctionne exclusivement sur Kubernetes.
Créer des images pour Kubernetes
Nous avons plus de 30 référentiels de code source pour les microservices fonctionnant dans un cluster Kubernetes. Le code de ces référentiels est écrit dans différents langages (par exemple, Node.js, Java, Scala, Go) avec de nombreux environnements d'exécution pour le même langage.
Le système de construction est conçu pour fournir un «contexte de construction» entièrement personnalisable pour chaque microservice. Il se compose généralement d'un Dockerfile et d'une liste de commandes shell. Leur contenu est entièrement personnalisable et, en même temps, tous ces contextes de construction sont écrits selon un format standardisé. La standardisation des contextes de génération permet à un système de génération unique de gérer tous les microservices.
 Figure 1-1. Processus de construction standardisé via le constructeur de conteneurs (Builder)
Figure 1-1. Processus de construction standardisé via le constructeur de conteneurs (Builder)Pour obtenir une cohérence maximale entre les exécutions, le même processus de génération est utilisé pendant le développement et les tests. Nous avons été confrontés à un problème très intéressant: nous avons dû développer un moyen de garantir la cohérence de l'environnement d'assemblage sur toute la plateforme. Pour ce faire, tous les processus d'assemblage sont exécutés dans un conteneur
Builder spécial.
Son implémentation a nécessité des techniques avancées pour travailler avec Docker. Builder hérite de l'ID utilisateur local et des secrets (tels que la clé SSH, les informations d'identification AWS, etc.) nécessaires pour accéder aux référentiels privés Tinder. Il monte des répertoires locaux contenant la source pour stocker naturellement les artefacts d'assemblage. Cette approche améliore les performances en éliminant la nécessité de copier les artefacts d'assemblage entre le conteneur Builder et l'hôte. Les artefacts d'assemblage stockés peuvent être réutilisés sans configuration supplémentaire.
Pour certains services, nous avons dû créer un autre conteneur pour faire correspondre l'environnement de compilation avec le runtime (par exemple, pendant le processus d'installation, la bibliothèque bcrypt Node.js génère des artefacts binaires spécifiques à la plate-forme). Pendant la compilation, les exigences peuvent varier pour différents services et le Dockerfile final est compilé à la volée.
Architecture et migration du cluster Kubernetes
Gestion de la taille du cluster
Nous avons décidé d'utiliser
kube-aws pour déployer automatiquement le cluster sur les instances Amazon EC2. Au tout début, tout fonctionnait dans un pool commun de nœuds. Nous avons rapidement réalisé la nécessité de séparer les charges de travail par taille et type d'instances pour une utilisation plus efficace des ressources. La logique était que le lancement de plusieurs pods multi-threads chargés s'est avéré être plus prévisible en termes de performances que leur coexistence avec un grand nombre de pods mono-thread.
En conséquence, nous nous sommes entendus sur:
- m5.4xlarge - pour la surveillance (Prometheus);
- c5.4xlarge - pour la charge de travail Node.js (charge de travail monothread );
- c5.2xlarge - pour Java et Go (charge de travail multithread);
- c5.4xlarge - pour le panneau de commande (3 nœuds).
La migration
L'une des étapes préparatoires à la migration de l'ancienne infrastructure vers Kubernetes a été de rediriger l'interaction directe existante entre les services vers les nouveaux équilibreurs de charge (ELB, Elastic Load Balancers). Ils ont été créés sur un sous-réseau de cloud privé virtuel (VPC) spécifique. Ce sous-réseau était connecté au VPC Kubernetes. Cela nous a permis de migrer progressivement les modules, sans tenir compte de l'ordre spécifique des dépendances de service.
Ces points de terminaison ont été créés à l'aide d'ensembles pondérés d'enregistrements DNS avec des CNAME pointant vers chaque nouvel ELB. Pour basculer, nous avons ajouté un nouvel enregistrement pointant vers la nouvelle ELB du service Kubernetes avec un poids de 0. Ensuite, nous avons défini le Time To Live (TTL) du jeu d'enregistrements sur 0. Après cela, l'ancien et le nouveau poids ont été lentement ajustés, et finalement 100% de la charge est passée sur le nouveau serveur. Une fois le changement terminé, la valeur TTL est revenue à un niveau plus adéquat.
Nos modules Java existants géraient un DNS TTL faible, mais pas les applications Node. L'un des ingénieurs a réécrit une partie du code du pool de connexions, en l'enveloppant dans un gestionnaire qui mettait à jour les pools toutes les 60 secondes. L'approche choisie a très bien fonctionné et sans diminution notable des performances.
Les leçons
Restrictions relatives aux périphériques réseau
Au petit matin du 8 janvier 2019, la plateforme Tinder s'est soudainement écrasée. En réponse à une augmentation non liée de la latence de la plateforme plus tôt dans la matinée, le nombre de pods et de nœuds dans le cluster a augmenté. Cela a conduit à l'épuisement du cache ARP sur tous nos nœuds.
Il existe trois options Linux associées au cache ARP:

(
source )
gc_thresh3 est une limite
stricte . L'apparition dans le journal des entrées du formulaire «débordement de table voisine» signifiait que même après un garbage collection synchrone (GC) dans le cache ARP, il n'y avait pas assez d'espace pour stocker l'enregistrement voisin. Dans ce cas, le noyau a simplement complètement supprimé le paquet.
Nous utilisons
Flannel comme structure de
réseau dans Kubernetes. Les paquets sont transmis via VXLAN. VXLAN est un tunnel L2, levé sur un réseau L3. La technologie utilise l'encapsulation MAC-in-UDP (MAC Address-in-User Datagram Protocol) et vous permet d'étendre les segments de réseau du 2ème niveau. Le protocole de transport dans le réseau physique du centre de données est IP plus UDP.
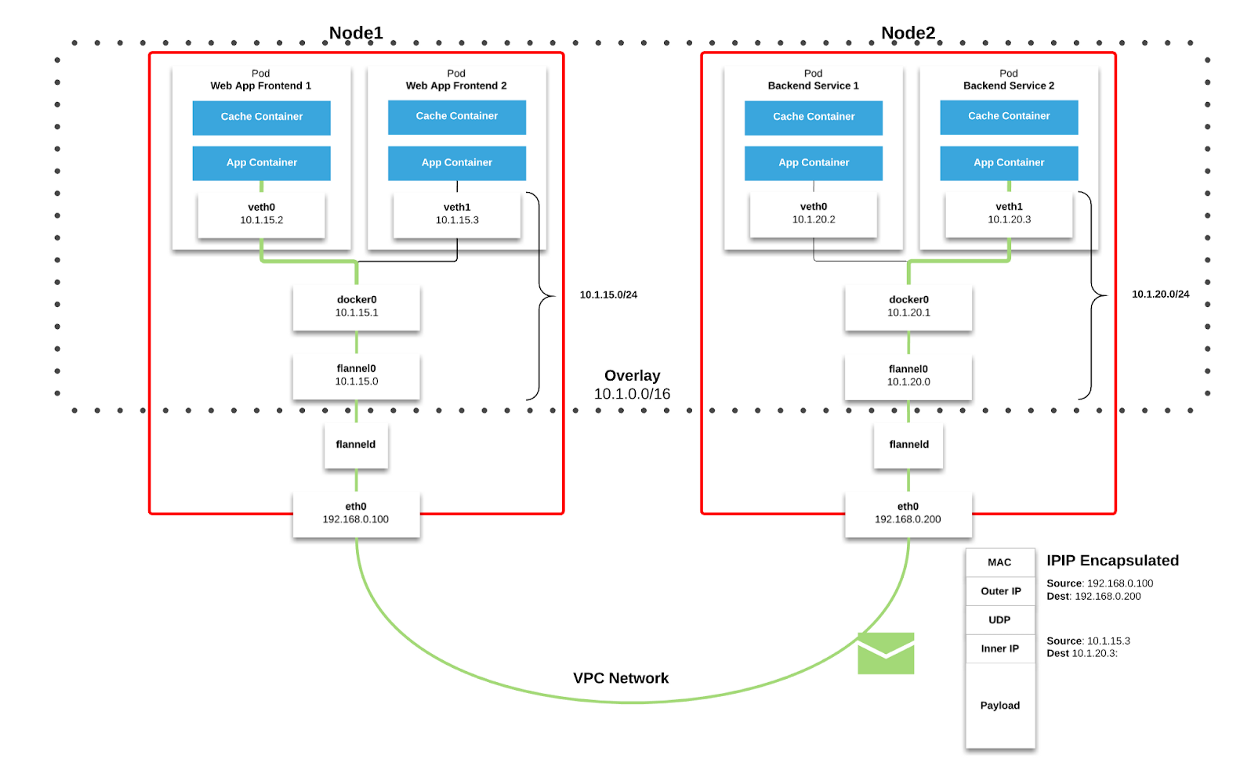 Figure 2–1. Tableau de flanelle ( source )
Figure 2–1. Tableau de flanelle ( source ) Figure 2–2. Paquet VXLAN ( source )
Figure 2–2. Paquet VXLAN ( source )Chaque nœud de travail Kubernetes alloue un espace d'adressage virtuel avec masque / 24 à partir du bloc plus grand / 9. Pour chaque nœud, cela
signifie une entrée dans la table de routage, une entrée dans la table ARP (sur l'interface
flannel.1 ) et une entrée dans la table de commutation (FDB). Ils sont ajoutés lors du premier démarrage du nœud de travail ou lorsque chaque nouveau nœud est détecté.
De plus, la connexion node-pod (ou pod-pod) passe finalement par l'interface
eth0 (comme illustré dans le diagramme Flannel ci-dessus). Il en résulte une entrée supplémentaire dans la table ARP pour chaque source et destination correspondante du nœud.
Dans notre environnement, ce type de communication est très courant. Pour les objets de type service dans Kubernetes, un ELB est créé et Kubernetes enregistre chaque nœud dans l'ELB. ELB ne sait rien des pods et le nœud sélectionné peut ne pas être la destination finale du paquet. Le fait est que lorsqu'un nœud reçoit un paquet de ELB, il le considère en tenant compte des règles
iptables pour un service particulier et sélectionne aléatoirement le pod sur un autre nœud.
Au moment de l'échec, le cluster comptait 605 nœuds. Pour les raisons indiquées ci-dessus, cela suffisait pour surmonter la
valeur par défaut gc_thresh3 . Lorsque cela se produit, non seulement les paquets commencent à être supprimés, mais tout l'espace d'adressage virtuel Flannel avec le masque / 24 disparaît de la table ARP. Les communications Node-pod et les requêtes DNS sont interrompues (DNS est hébergé dans un cluster; voir le reste de cet article pour plus de détails).
Pour résoudre ce problème, augmentez les valeurs de
gc_thresh1 ,
gc_thresh2 et
gc_thresh3 et redémarrez Flannel pour réenregistrer les réseaux manquants.
Mise à l'échelle DNS inattendue
Au cours du processus de migration, nous avons activement utilisé DNS pour gérer le trafic et transférer progressivement les services de l'ancienne infrastructure vers Kubernetes. Nous avons défini des valeurs TTL relativement faibles pour les jeux d'enregistrements associés dans Route53. Lorsque l'ancienne infrastructure fonctionnait sur des instances EC2, notre configuration de résolveur pointait vers Amazon DNS. Nous l'avons pris pour acquis et l'impact du faible TTL sur nos services Amazon (comme DynamoDB) est passé presque inaperçu.
Au fur et à mesure de la migration des services vers Kubernetes, nous avons constaté que DNS traitait 250 000 requêtes par seconde. En conséquence, les applications ont commencé à subir des délais d'expiration constants et sérieux pour les requêtes DNS. Cela s'est produit malgré des efforts incroyables pour optimiser et basculer le fournisseur DNS vers CoreDNS (qui a atteint 1000 pods fonctionnant sur 120 cœurs à pleine charge).
En explorant d'autres causes et solutions possibles, nous avons trouvé
un article décrivant les conditions de
concurrence qui affectent le framework de filtrage de paquets
netfilter sous Linux. Les délais d'attente que nous avons observés, ainsi que l'augmentation
du compteur
insert_failed dans l'interface Flannel, correspondaient aux conclusions de l'article.
Le problème survient au stade de la traduction des adresses de réseau source et de destination (SNAT et DNAT) et lors de l'entrée suivante dans la table
conntrack . L'une des solutions de contournement discutées au sein de l'entreprise et proposée par la communauté était le transfert du DNS vers le nœud de travail lui-même. Dans ce cas:
- SNAT n'est pas nécessaire car le trafic reste à l'intérieur du nœud. Il n'a pas besoin d'être acheminé via l'interface eth0 .
- DNAT n'est pas nécessaire, car l'IP de destination est locale à l'hôte, et non un pod sélectionné au hasard selon les règles iptables .
Nous avons décidé de nous en tenir à cette approche. CoreDNS a été déployé en tant que DaemonSet dans Kubernetes et nous avons implémenté un serveur DNS hôte local dans
resolv.conf de chaque pod en configurant l'
indicateur --cluster-dns de la commande
kubelet . Cette solution s'est avérée efficace pour les délais d'attente DNS.
Cependant, nous avons toujours observé une perte de paquets et une augmentation du compteur
insert_failed dans l'interface Flannel. Cette situation s'est poursuivie après l'introduction de la solution de contournement, car nous avons pu exclure SNAT et / ou DNAT uniquement pour le trafic DNS. Les conditions de course ont persisté pour d'autres types de trafic. Heureusement, la plupart de nos packages sont TCP, et lorsqu'un problème survient, ils sont simplement retransmis. Nous essayons toujours de trouver une solution adaptée à tous les types de trafic.
Utilisation d'Envoy pour un meilleur équilibrage de charge
Alors que nous migrions les services backend vers Kubernetes, nous avons commencé à souffrir d'une charge déséquilibrée entre les pods. Nous avons constaté qu'en raison de HTTP Keepalive, les connexions ELB étaient suspendues aux premiers pods prêts à l'emploi de chaque déploiement. Ainsi, la majeure partie du trafic a transité par un petit pourcentage des modules disponibles. La première solution que nous avons testée a été de définir le paramètre MaxSurge à 100% sur les nouveaux déploiements pour les pires cas. L'effet était insignifiant et peu prometteur en termes de déploiements plus importants.
Une autre solution que nous avons utilisée consistait à augmenter artificiellement les demandes de ressources pour les services essentiels à la mission. Dans ce cas, les pods adjacents auraient plus de marge de manœuvre que les autres pods lourds. À long terme, cela ne fonctionnerait pas non plus en raison du gaspillage de ressources. De plus, nos applications Node étaient monothread et, par conséquent, ne pouvaient utiliser qu'un seul cœur. La seule vraie solution était d'utiliser un meilleur équilibrage de charge.
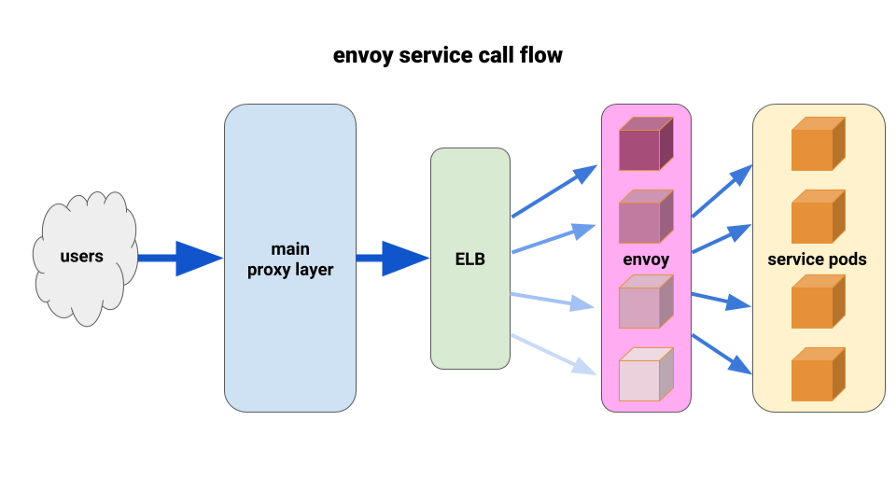
Nous voulons depuis longtemps apprécier pleinement l'
Envoy . La situation actuelle nous a permis de le déployer de manière très limitée et d'obtenir des résultats immédiats. Envoy est un proxy open source de septième niveau hautes performances conçu pour les grandes applications SOA. Il est capable d'appliquer des techniques avancées d'équilibrage de charge, notamment des tentatives automatiques, des disjoncteurs et des limites de vitesse globales.
( Remarque sur la traduction : pour plus de détails, consultez le récent article sur Istio - le maillage de service, qui est basé sur Envoy.)Nous sommes arrivés avec la configuration suivante: avoir un side-car Envoy pour chaque pod et une seule route, et le cluster - se connecter au conteneur localement par le port. Pour minimiser les cascades potentielles et maintenir un petit rayon de «dommages», nous avons utilisé le parc de pods proxy frontal Envoy, un pour chaque zone de disponibilité (AZ) pour chaque service. Ils se sont tournés vers un mécanisme de découverte de service simple écrit par l'un de nos ingénieurs, qui a simplement renvoyé une liste de pods dans chaque AZ pour un service donné.
Ensuite, les envoyés de service ont utilisé ce mécanisme de découverte de service avec un cluster et une route en amont. Nous avons défini des délais d'expiration adéquats, augmenté tous les paramètres du disjoncteur et ajouté une configuration de relance minimale pour aider à des pannes uniques et assurer des déploiements transparents. Avant chacun de ces front-Envoys de service, nous avons placé un TCP ELB. Même si le Keepalive de notre couche proxy principale était suspendu à certains pods Envoy, ils pouvaient toujours gérer la charge beaucoup mieux et étaient configurés pour s'équilibrer via au moins_une demande dans le backend.
Pour le déploiement, nous avons utilisé le crochet preStop sur les modules d'application et les modules side-car. Le hook a déclenché une erreur lors de la vérification de l'état du point de terminaison admin situé sur le sidecar-container et a "dormi" pendant un certain temps afin de permettre aux connexions actives de se terminer.
L'une des raisons pour lesquelles nous avons pu avancer si rapidement dans la résolution de problèmes est liée à des mesures détaillées que nous avons pu intégrer facilement dans une installation standard de Prometheus. Avec eux, il est devenu possible de voir exactement ce qui se passait pendant que nous sélectionnions les paramètres de configuration et redistribuions le trafic.
Les résultats ont été immédiats et évidents. Nous avons commencé avec les services les plus déséquilibrés, et pour le moment, il fonctionne déjà avant les 12 services les plus importants du cluster. Cette année, nous prévoyons de passer à un maillage de service complet avec une découverte de service plus avancée, une coupure de circuit, une détection des valeurs aberrantes, une limitation de la vitesse et un traçage.
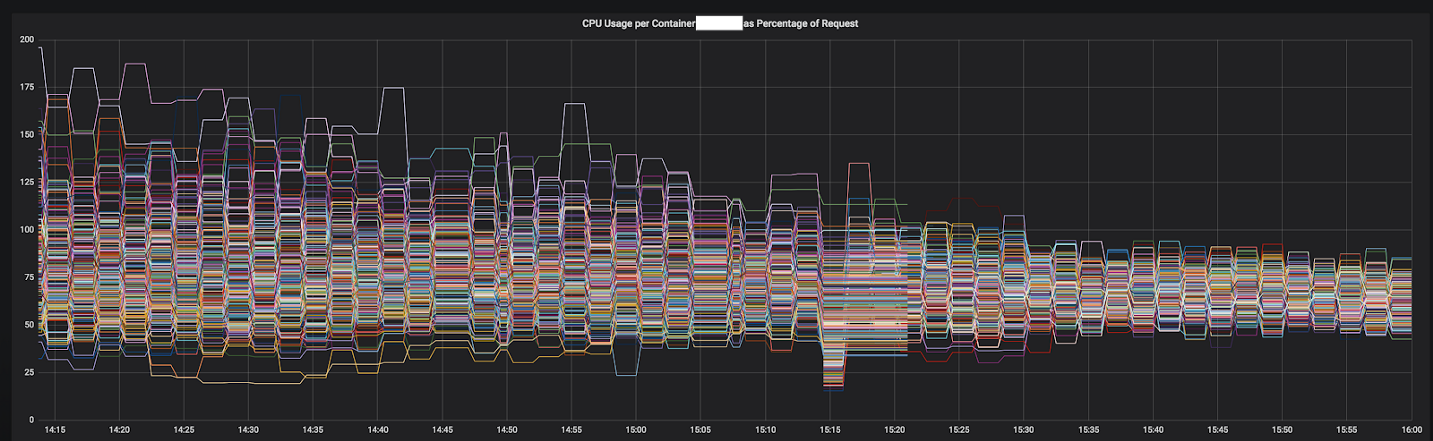 Figure 3–1. Convergence CPU d'un service lors de la transition vers Envoy
Figure 3–1. Convergence CPU d'un service lors de la transition vers Envoy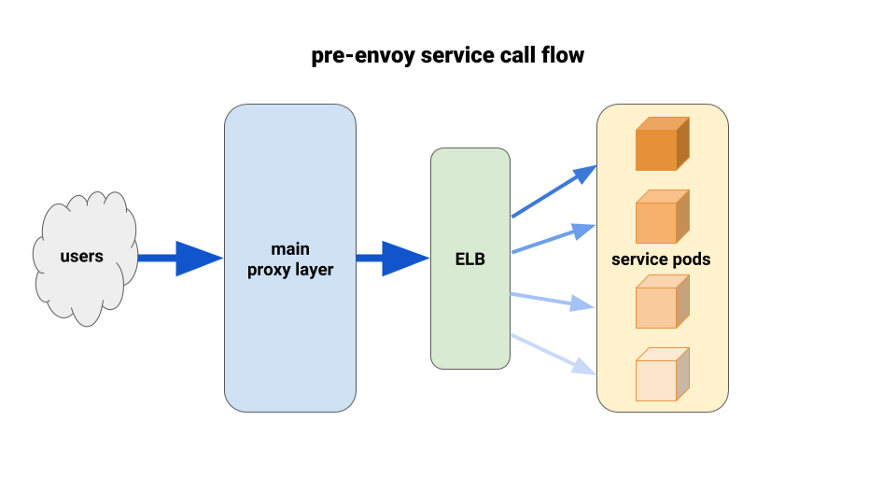
Résultat final
Grâce à notre expérience et à nos recherches supplémentaires, nous avons constitué une solide équipe d'infrastructure dotée de bonnes compétences dans la conception, le déploiement et l'exploitation de grands clusters Kubernetes. Désormais, tous les ingénieurs de Tinder ont les connaissances et l'expérience nécessaires pour emballer des conteneurs et déployer des applications dans Kubernetes.
Lorsque le besoin de capacités supplémentaires s'est fait sentir sur l'ancienne infrastructure, nous avons dû attendre plusieurs minutes pour lancer de nouvelles instances EC2. Maintenant, les conteneurs démarrent et commencent à traiter le trafic pendant plusieurs secondes au lieu de minutes. La planification de plusieurs conteneurs sur une seule instance d'EC2 permet également d'améliorer la concentration horizontale. En conséquence, en 2019, nous prévoyons une réduction significative des coûts EC2 par rapport à l'année dernière.
Il a fallu près de deux ans pour migrer, mais nous l'avons terminée en mars 2019. Actuellement, la plateforme Tinder fonctionne exclusivement sur le cluster Kubernetes, qui comprend 200 services, 1 000 nœuds, 15 000 pods et 48 000 conteneurs en cours d'exécution. L'infrastructure n'est plus la seule responsabilité des équipes opérationnelles. Tous nos ingénieurs partagent cette responsabilité et contrôlent le processus de création et de déploiement de leurs applications en utilisant uniquement du code.
PS du traducteur
Lisez également notre série d'articles sur notre blog: