Lors du dernier rassemblement interne de Pyrus, nous avons parlé du stockage distribué moderne et Maxim Nalsky, PDG et fondateur de Pyrus, a partagé sa première impression de FoundationDB. Dans cet article, nous parlons des nuances techniques que vous rencontrez lorsque vous choisissez une technologie pour dimensionner le stockage de données structurées.
Lorsque le service n'est pas accessible aux utilisateurs pendant un certain temps, il est extrêmement désagréable, mais toujours pas mortel. Mais perdre des données client est absolument inacceptable. Par conséquent, nous évaluons scrupuleusement toute technologie de stockage de données par deux à trois douzaines de paramètres.
Certains d'entre eux dictent la charge actuelle du service.
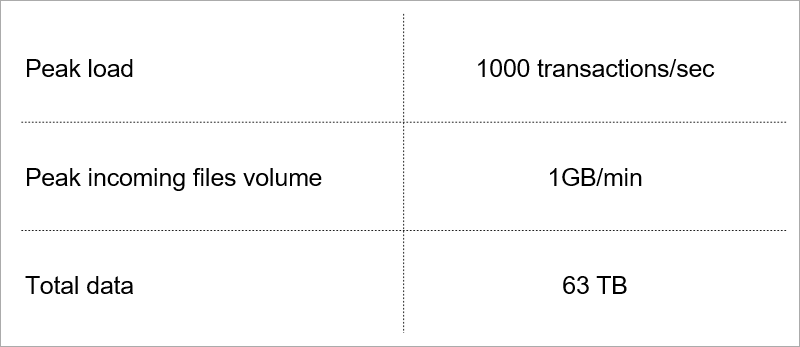 Charge actuelle. Nous sélectionnons la technologie en tenant compte de la croissance de ces indicateurs.
Charge actuelle. Nous sélectionnons la technologie en tenant compte de la croissance de ces indicateurs.Architecture client-serveur
Le modèle client-serveur classique est l'exemple le plus simple d'un système distribué. Un serveur est un point de synchronisation; il permet à plusieurs clients de faire quelque chose ensemble de manière coordonnée.
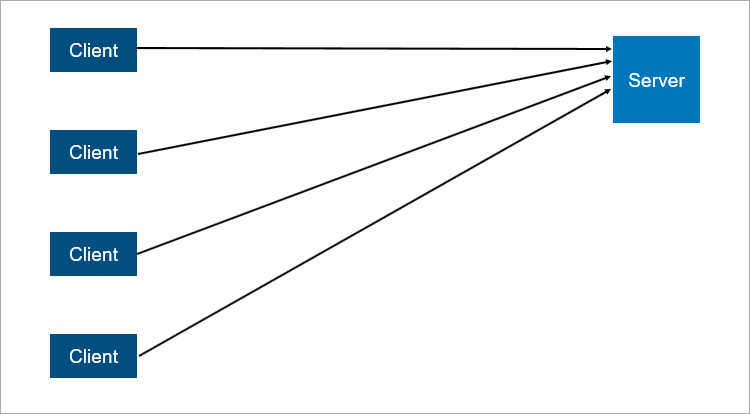 Un schéma très simplifié d'interaction client-serveur.
Un schéma très simplifié d'interaction client-serveur.Qu'est-ce qui n'est pas fiable dans l'architecture client-serveur? De toute évidence, le serveur peut se bloquer. Et lorsque le serveur tombe en panne, tous les clients ne peuvent pas fonctionner. Pour éviter cela, les gens ont trouvé une connexion maître-esclave (qui est maintenant
politiquement correcte appelée leader-suiveur ). L'essentiel, c'est qu'il y a deux serveurs, tous les clients communiquent avec le principal, et sur le second, toutes les données sont simplement répliquées.
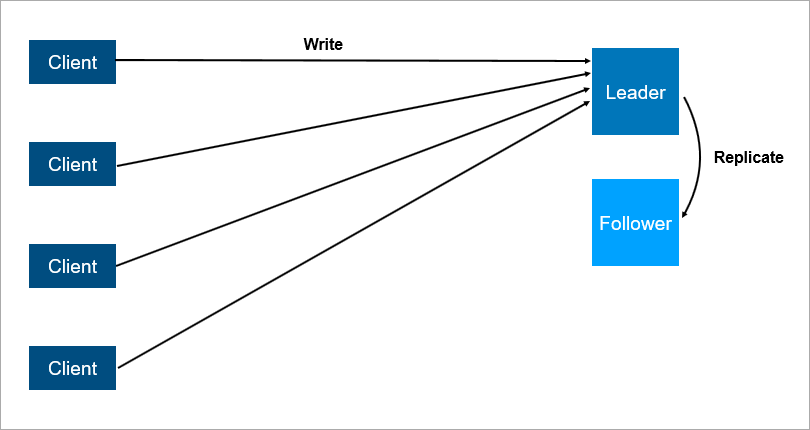 Architecture client-serveur avec réplication des données vers les abonnés.
Architecture client-serveur avec réplication des données vers les abonnés.Il est clair qu'il s'agit d'un système plus fiable: si le serveur principal tombe en panne, alors une copie de toutes les données est sur le suiveur et peut être rapidement levée.
Il est important de comprendre le fonctionnement de la réplication. S'il est synchrone, la transaction doit être stockée simultanément sur le leader et sur le suiveur, ce qui peut être lent. Si la réplication est asynchrone, vous pouvez perdre certaines des données après un basculement.
Et que se passera-t-il si le chef tombe la nuit alors que tout le monde dort? Il existe des données sur le suiveur, mais personne ne lui a dit qu'il était maintenant un leader et que les clients ne se connectaient pas avec lui. OK, dotons le suiveur de la logique qu'il commence à se considérer comme la chose principale lorsque la connexion avec le leader est perdue. Ensuite, nous pouvons facilement obtenir un cerveau divisé - un conflit lorsque la connexion entre le leader et le suiveur est rompue, et les deux pensent qu'ils sont les principaux. Cela se produit vraiment sur de nombreux systèmes,
tels que RabbitMQ , la technologie de mise en file d'attente la plus populaire d'aujourd'hui.
Pour résoudre ces problèmes, organisez le basculement automatique - ajoutez un troisième serveur (témoin, témoin). Cela garantit que nous n'avons qu'un seul leader. Et si le leader tombe, le suiveur s'allume automatiquement avec un temps d'arrêt minimum, qui peut être réduit à quelques secondes. Bien entendu, les clients de ce schéma doivent connaître à l'avance les adresses du leader et du suiveur et mettre en œuvre la logique de reconnexion automatique entre eux.
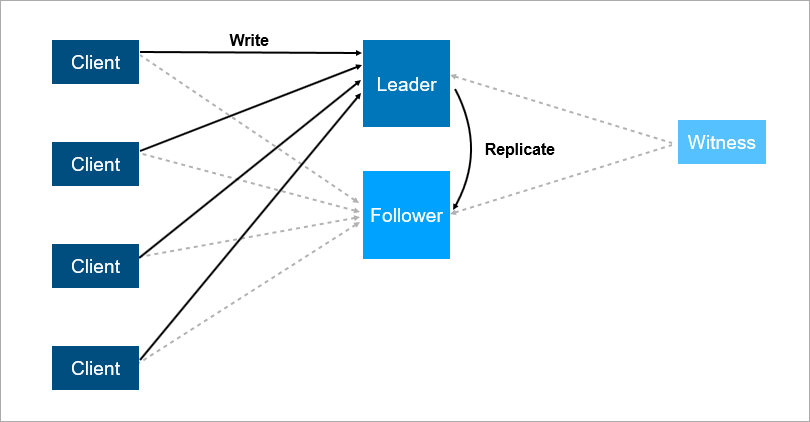 Le témoin garantit qu'il n'y a qu'un seul chef. Si le leader tombe, le suiveur s'allume automatiquement.
Le témoin garantit qu'il n'y a qu'un seul chef. Si le leader tombe, le suiveur s'allume automatiquement.Un tel système fonctionne maintenant avec nous. Il y a une base de données principale, une base de données de rechange, il y a un témoin et oui - parfois nous venons le matin et voyons que le changement s'est produit la nuit.
Mais ce schéma présente également des inconvénients. Imaginez que vous installez des Service Packs ou mettez à jour le système d'exploitation sur un serveur leader. Avant cela, vous avez mis manuellement la charge sur le suiveur puis ... ça tombe! En cas de catastrophe, votre service n'est pas disponible. Que faire pour vous protéger de cela? Ajoutez un troisième serveur de sauvegarde - un autre suiveur. Trois est une sorte de nombre magique. Si vous voulez que le système fonctionne de manière fiable, deux serveurs ne suffisent pas, vous en avez besoin de trois. Un pour l'entretien, le deuxième tombe, le troisième reste.
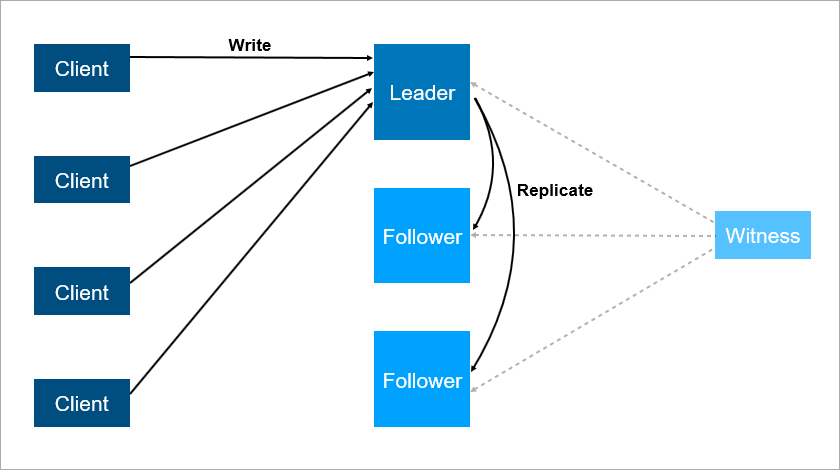 Le troisième serveur fournit un fonctionnement fiable si les deux premiers ne sont pas disponibles.
Le troisième serveur fournit un fonctionnement fiable si les deux premiers ne sont pas disponibles.Pour résumer, la redondance doit être égale à deux. Une redondance d'un ne suffit pas. Pour cette raison, dans les baies de disques, les gens ont commencé à utiliser le schéma RAID6 au lieu de RAID5, survivant à la chute de deux disques à la fois.
Les transactions
Quatre exigences de base pour les transactions sont bien connues: atomicité, cohérence, isolation et durabilité (atomicité, cohérence, isolation, durabilité - ACID).
Lorsque nous parlons de bases de données distribuées, nous voulons dire que les données doivent être mises à l'échelle. La lecture évolue très bien - des milliers de transactions peuvent lire des données en parallèle sans aucun problème. Mais lorsque d'autres transactions écrivent des données en même temps que la lecture, divers effets indésirables sont possibles. Il est très facile d'obtenir une situation où une transaction lira différentes valeurs des mêmes enregistrements. Voici quelques exemples.
Lectures sales. Dans la première transaction, nous envoyons la même demande deux fois: prenez tous les utilisateurs dont l'ID = 1. Si la deuxième transaction modifie cette ligne puis annule, la base de données ne verra aucune modification d'une part, mais d'autre part la première transaction lira différentes valeurs d'âge pour Joe.
 Lectures non reproductibles.
Lectures non reproductibles. Un autre cas est si la transaction d'écriture s'est terminée avec succès et que la transaction de lecture a reçu des données différentes pendant l'exécution de la même demande.

Dans le premier cas, le client a lu des données qui étaient généralement absentes de la base de données. Dans le second cas, le client lit les deux fois les données de la base de données, mais elles sont différentes, bien que la lecture se produise au sein de la même transaction.
La lecture fantôme consiste à relire une plage dans la même transaction et à obtenir un ensemble de lignes différent. Quelque part au milieu, une autre transaction est entrée et a inséré ou supprimé des enregistrements.

Pour éviter ces effets indésirables, les SGBD modernes mettent en œuvre des mécanismes de verrouillage (une transaction restreint l'accès aux données avec lesquelles elle travaille actuellement à d'autres transactions) ou un contrôle de version multiversionnel,
MVCC (une transaction ne modifie jamais les données enregistrées précédemment et crée toujours une nouvelle version).
La norme ANSI / ISO SQL définit 4 niveaux d'isolement pour les transactions qui affectent leur degré de blocage mutuel. Plus le niveau d'isolement est élevé, moins les effets indésirables sont importants. Le prix à payer est de ralentir l'application (car les transactions attendent plus souvent pour déverrouiller les données dont elles ont besoin) et d'augmenter la probabilité de blocages.
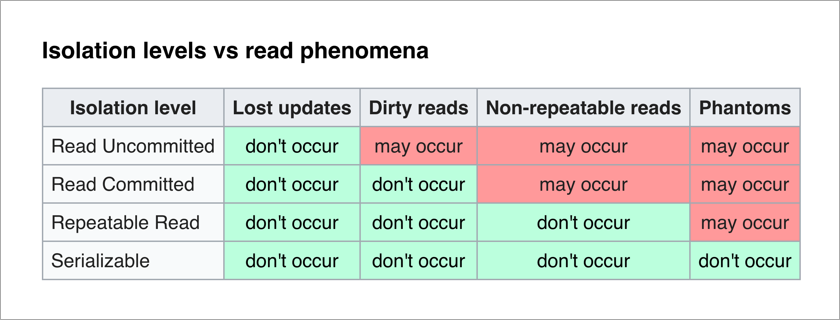
Le plus agréable pour un programmeur d'applications est le niveau sérialisable - il n'y a pas d'effets indésirables et toute la complexité de garantir l'intégrité des données est transférée vers le SGBD.
Pensons à l'implémentation naïve du niveau Sérialisable - à chaque transaction, nous bloquons tout le monde. Chaque transaction d'écriture peut théoriquement être effectuée en 50 µs (le temps d'une opération d'écriture sur les disques SSD modernes). Et nous voulons enregistrer les données sur trois machines, vous vous souvenez? S'ils se trouvent dans le même centre de données, l'enregistrement prendra 1 à 3 ms. Et si, pour plus de fiabilité, ils se trouvent dans différentes villes, l'enregistrement peut facilement prendre 10 à 12 ms (le temps de trajet d'un paquet réseau de Moscou à Saint-Pétersbourg et vice versa). Autrement dit, avec une implémentation naïve du niveau Sérialisable par enregistrement séquentiel, nous ne pouvons pas effectuer plus de 100 transactions par seconde. Alors qu'un SSD séparé vous permet d'effectuer environ 20 000 opérations d'écriture par seconde!
Conclusion: les transactions d'écriture doivent être effectuées en parallèle, et pour les mettre à l'échelle, vous avez besoin d'un bon mécanisme de résolution des conflits.
Partage
Que faire lorsque les données ne parviennent plus sur un serveur? Il existe deux mécanismes de zoom standard:
- Droit lorsque nous ajoutons simplement de la mémoire et des disques à ce serveur. Cela a ses limites - en termes de nombre de cœurs par processeur, de nombre de processeurs et de quantité de mémoire.
- Horizontal, lorsque nous utilisons de nombreuses machines et que nous répartissons des données entre elles. Les ensembles de ces machines sont appelés clusters. Pour placer les données dans un cluster, elles doivent être fragmentées - c'est-à-dire, pour chaque enregistrement, déterminer sur quel serveur elles seront situées.
Une clé de partitionnement est un paramètre par lequel les données sont distribuées entre les serveurs, par exemple, un identifiant de client ou d'organisation.
Imaginez que vous devez enregistrer des données sur tous les habitants de la Terre dans un cluster. En tant que clé de partition, vous pouvez prendre, par exemple, l'année de naissance de la personne. Ensuite, 116 serveurs suffiront (et chaque année il faudra ajouter un nouveau serveur). Ou vous pouvez prendre comme clé le pays où la personne vit, alors vous aurez besoin d'environ 250 serveurs. Néanmoins, la première option est préférable, car la date de naissance de la personne ne change pas et vous n'aurez jamais besoin de transférer des données la concernant entre les serveurs.
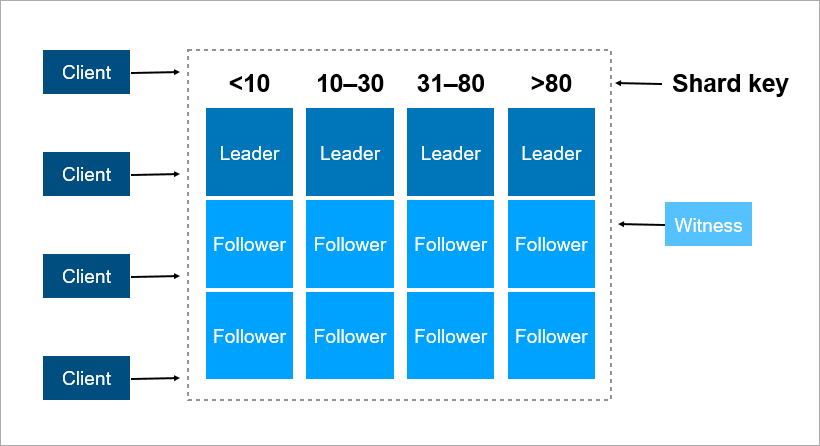
Dans Pyrus, vous pouvez prendre une organisation comme clé de partitionnement. Mais leur taille est très différente: il y a à la fois une énorme Sovcombank (plus de 15 000 utilisateurs) et des milliers de petites entreprises. Lorsque vous attribuez à une organisation un serveur spécifique, vous ne savez pas à l'avance comment il va se développer. Si l'organisation est grande et utilise activement le service, tôt ou tard, ses données cesseront d'être placées sur un seul serveur et vous devrez effectuer un nouveau partage. Et ce n'est pas facile si les données sont en téraoctets. Imaginez: un système chargé, les transactions se déroulent à chaque seconde, et dans ces conditions, vous devez déplacer les données d'un endroit à un autre. Vous ne pouvez pas arrêter le système, un tel volume peut être pompé pendant plusieurs heures et les clients professionnels ne survivront pas à un temps d'arrêt aussi long.
En tant que clé de partage, il est préférable de choisir des données qui changent rarement. Cependant, loin d'être toujours une tâche appliquée, cela est facile à faire.
Consensus dans le cluster
Lorsqu'il y a beaucoup de machines dans le cluster et que certaines perdent le contact avec les autres, alors comment décider qui stocke la dernière version des données? Il ne suffit pas d'affecter un serveur témoin, car il peut également perdre le contact avec l'ensemble du cluster. De plus, dans une situation de cerveau divisé, plusieurs machines peuvent enregistrer différentes versions des mêmes données - et vous devez en quelque sorte déterminer laquelle est la plus pertinente. Pour résoudre ce problème, les gens ont proposé des algorithmes de consensus. Ils permettent à plusieurs machines identiques de parvenir à un résultat unique sur n'importe quelle question en votant. En 1989, le premier algorithme de ce type,
Paxos , a été publié, et en 2014, les gars de Stanford ont proposé un
radeau plus simple à mettre en œuvre. A strictement parler, pour qu'un cluster de serveurs (2N + 1) parvienne à un consensus, il suffit qu'il n'y ait en même temps pas plus de N défaillances. Pour survivre à 2 échecs, le cluster doit avoir au moins 5 serveurs.
Mise à l'échelle relationnelle du SGBD
La plupart des bases de données que les développeurs sont habitués à utiliser prennent en charge l'algèbre relationnelle. Les données sont stockées dans des tables et parfois vous devez joindre les données de différentes tables à l'aide de l'opération JOIN. Prenons un exemple de base de données et une simple requête.
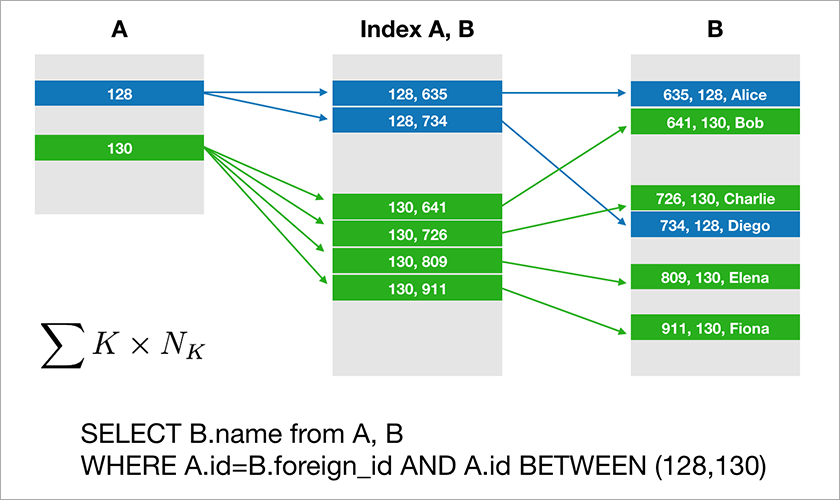
Supposons que A.id est une clé primaire avec un index clusterisé. L'optimiseur créera ensuite un plan qui sélectionnera très probablement les enregistrements nécessaires dans la table A, puis prendra les liens appropriés vers les enregistrements de la table B à partir d'un index approprié (A, B). Le temps d'exécution de cette requête augmente logarithmiquement à partir du nombre d'enregistrements dans les tables.
Imaginez maintenant que les données sont réparties sur quatre serveurs du cluster et que vous devez exécuter la même requête:
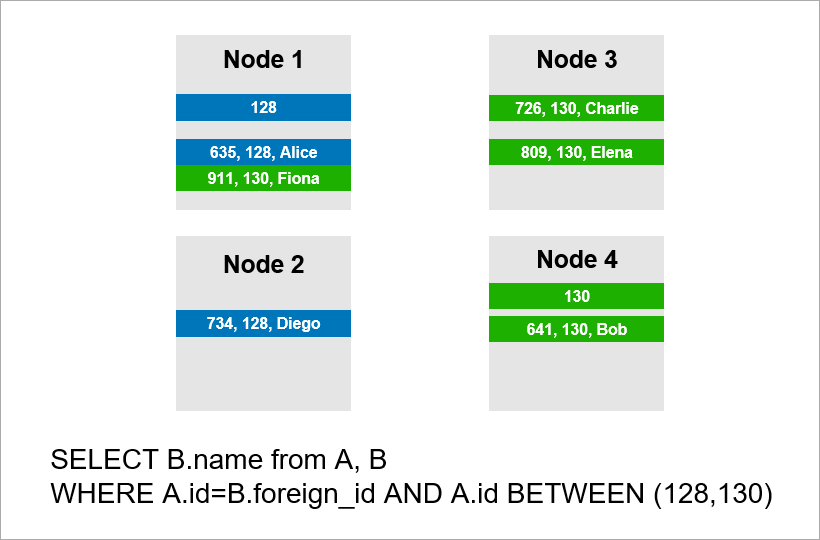
Si le SGBD ne souhaite pas afficher tous les enregistrements de l'ensemble du cluster, il essaiera probablement de rechercher des enregistrements avec A.id égal à 128, 129 ou 130 et de trouver les enregistrements appropriés pour eux dans la table B.Mais si A.id n'est pas une clé de partition, le SGBD à l'avance Je ne peux pas savoir sur quel serveur se trouvent les données du tableau A. Je vais quand même devoir contacter tous les serveurs pour savoir s'il existe des enregistrements A.id adaptés à notre état. Ensuite, chaque serveur peut créer un JOIN en lui-même, mais cela ne suffit pas. Vous voyez, nous avons besoin de l'enregistrement sur le nœud 2 dans l'échantillon, mais il n'y a pas d'enregistrement avec A.id = 128? Si les nœuds 1 et 2 se joignent indépendamment, le résultat de la requête sera incomplet - nous ne recevrons pas une partie des données.
Par conséquent, pour répondre à cette demande, chaque serveur doit se tourner vers tout le monde. Le runtime croît de façon quadratique avec le nombre de serveurs. (Vous avez de la chance si vous pouvez partager toutes les tables avec la même clé, alors vous n'avez pas besoin d'analyser tous les serveurs. Cependant, dans la pratique, cela est irréaliste - il y aura toujours des requêtes où la récupération n'est pas basée sur la clé de partition.)
Ainsi, les opérations JOIN échouent fondamentalement mal et c'est un problème fondamental de l'approche relationnelle.
Approche NoSQL
Les difficultés de mise à l'échelle des SGBD classiques ont conduit les gens à proposer des bases de données NoSQL qui ne comportent pas d'opérations JOIN. Pas de jointures - pas de problème. Mais il n'y a pas de propriétés ACID, mais ils ne l'ont pas mentionné dans les documents marketing. Des
artisans rapidement
trouvés qui testent la force de divers systèmes distribués et
publient les résultats publiquement . Il s'est avéré qu'il existe des scénarios où le
cluster Redis perd 45% des données stockées, le cluster RabbitMQ - 35% des messages ,
MongoDB - 9% des enregistrements ,
Cassandra - jusqu'à 5% . Et nous parlons
de la perte après que le cluster a informé le client de la sauvegarde réussie. Vous attendez généralement un niveau de fiabilité plus élevé de la technologie choisie.
Google a développé la base de données
Spanner , qui opère dans le monde entier dans le monde. Spanner garantit les propriétés ACID, la sérialisation et plus encore. Ils ont des horloges atomiques dans les centres de données qui fournissent l'heure exacte, ce qui vous permet de créer un ordre global de transactions sans avoir à transférer des paquets réseau entre les continents. L'idée de Spanner est qu'il est préférable pour les programmeurs de traiter les problèmes de performances qui surviennent avec un grand nombre de transactions que de béquilles autour du manque de transactions. Cependant, Spanner est une technologie fermée, elle ne vous convient pas si, pour une raison quelconque, vous ne voulez pas dépendre d'un seul fournisseur.
Les autochtones de Google ont développé un analogue open source de Spanner et l'ont nommé CockroachDB («cockroach» en anglais «cockroach», qui devrait symboliser la capacité de survie de la base de données). Sur Habré a
déjà écrit sur l'indisponibilité du produit pour la production, car le cluster perdait des données. Nous avons décidé de vérifier la nouvelle version 2.0 et sommes arrivés à une conclusion similaire. Nous n'avons pas perdu les données, mais certaines des requêtes les plus simples ont été exécutées de manière déraisonnablement longue.
En conséquence, il existe aujourd'hui des bases de données relationnelles qui évoluent bien uniquement verticalement, ce qui est coûteux. Et il existe des solutions NoSQL sans transactions et sans garanties ACID (si vous voulez ACID, écrivez des béquilles).
Comment créer des applications stratégiques dans lesquelles les données ne tiennent pas sur un seul serveur? De nouvelles solutions apparaissent sur le marché, et à propos de l'une d'entre elles -
FoundationDB - nous vous en dirons plus dans le prochain article.