
Bonjour, Habr! Je m'appelle Stanislav Semenov, je travaille sur des technologies d'extraction de données à partir de documents en R&D ABBYY. Dans cet article, je parlerai des approches de base du traitement des documents semi-structurés (factures, reçus de caisse, etc.) que nous avons utilisés récemment et que nous utilisons actuellement. Et nous parlerons de la façon dont les méthodes d'apprentissage automatique sont applicables pour résoudre ce problème.
Nous considérerons les factures comme des documents, car dans le monde, ils sont très répandus et les plus demandés en termes d'extraction de données. Soit dit en passant, le traitement automatique des factures est l'un des scénarios les plus populaires parmi nos clients étrangers. Par exemple, avec l'aide d'ABBYY FlexiCapture, la technologie d'imagerie américaine PepsiCo a
réduit le temps de traitement des factures et le nombre d'erreurs dues à la saisie manuelle, et le détaillant européen Sportina a
commencé à saisir les données des comptes dans les systèmes comptables
2 fois plus rapidement .
Les factures sont des documents qui sont utilisés dans la pratique commerciale internationale et sont d'une grande importance pour les entreprises. Quelque chose de similaire à une facture en Russie est, par exemple, une lettre de voiture. Les données de ces documents tombent dans divers systèmes comptables, et les erreurs, pour le moins, ne sont pas les bienvenues.
Une facture ordinaire peut être considérée comme assez structurée; elle contient deux classes principales d'objets:
- divers champs de l'en-tête (numéro de document, date, expéditeur, destinataire, total, etc.),
- les données tabulaires sont une liste de biens et services (quantité, prix, description, etc.).
Voici à quoi ça ressemble:
Des millions d'heures de travail sont consacrées chaque année au traitement des factures. Et c'est très cher. Selon diverses estimations, pour une entreprise, le traitement d'une facture papier coûte de 10 $ à 40 $, où une part importante de ces coûts est le travail manuel pour la saisie et le rapprochement des données.
Il existe des entreprises qui traitent des millions de factures par mois. Pour ce faire, ils contiennent tout un personnel de centaines, et parfois de milliers de personnes. Il est facile d'estimer qu'une augmentation de la précision de la reconnaissance ou de l'efficacité d'extraction des données de seulement 1% peut réduire les coûts des grandes entreprises de centaines de milliers, voire de millions de dollars par an.
D'un autre côté, il y a une quantité catastrophique de documents. En 2017, Billentis a
estimé le nombre total de factures / factures générées par an dans le monde à 400 milliards. De ce nombre, seulement 10% environ étaient électroniques et les autres nécessitent une saisie entièrement manuelle ou une participation humaine intensive. Si vous imprimez 400 milliards de documents sur du papier A4 standard, alors ce sont des milliers de camions de papier par jour, ou une pile de papier à hauteur humaine chaque seconde!
Quelques mots sur l'évolution de la technologie

De nombreuses entreprises développent des logiciels spécialisés capables de reconnaître des documents et d'en extraire des données. Mais la qualité du traitement des factures n'est pas encore parfaite. "Quel est le problème?" - demandez-vous.
Il s'agit d'une grande variété de factures. Il n'y a pas de normes pour les factures, et chaque entreprise est libre de créer sa propre version du document: le type, la structure et l'emplacement des champs.
Rechercher des champs par mots clés
Les premières tentatives d'extraction de données se sont résumées à la recherche de mots clés spéciaux parmi tous les mots reconnus, tels que, par exemple, le numéro de facture ou le total, puis, dans un petit voisinage de ces mots, par exemple à droite ou en bas, pour trouver les significations elles-mêmes.
Emplacement du numéro de facture sur différentes factures (cliquable):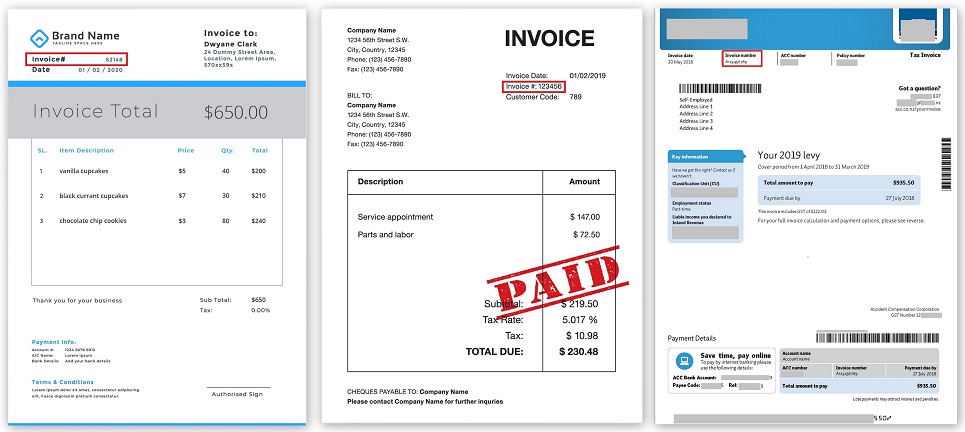
Toute la logique a été programmée, qu'il y a tel ou tel champ, ils sont à tel ou tel endroit du document, autour d'eux il y a d'autres champs à quelques distances. Et cela a fonctionné jusqu'à ce qu'une autre société apparaisse, qui a commencé à envoyer ses documents sous une forme complètement différente. Ou la société précédente a soudainement changé le format et tout a cessé de fonctionner.
Patterns
Lutter contre cela, chaque fois reprogrammer quelque chose, était irrationnel. Par conséquent, un nouveau paradigme est venu à la rescousse - l'utilisation de modèles.
Un modèle est un ensemble de champs qui doivent être trouvés dans un document et un ensemble de règles sur la façon de trouver ces champs. Le principal avantage ici est que les modèles sont créés visuellement. Par exemple, nous voulons rechercher le numéro de facture et le total, sélectionner ces champs et configurer les paramètres que tel ou tel champ va immédiatement après tel ou tel mot-clé, il est situé en haut du document et contient des nombres et des signes de ponctuation.
Des outils spécialisés ont été développés, les soi-disant éditeurs de modèles, où des utilisateurs déjà avancés sans l'aide de programmeurs pouvaient rapidement définir manuellement une sorte de logique. Dès qu'un document d'un nouveau formulaire est arrivé, un modèle a été créé pour lui et tout a commencé à fonctionner plus ou moins.
Exemple de modèle (cliquable):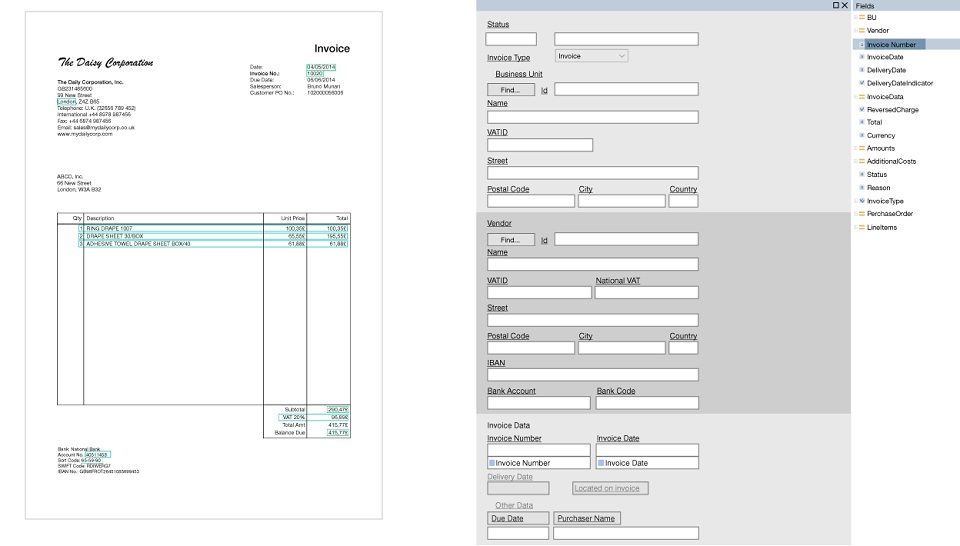
Mais pour faire un modèle ne suffit pas, il faut en faire des centaines voire des milliers. Et donc, mettre en place un produit pour chaque client peut parfois prendre beaucoup de temps. Il est impossible de créer à l'avance des modèles «universels» qui couvriront toute la variété des factures.
À l'aide de modèles, vous pouvez considérablement améliorer la qualité de la récupération des tables. Mais on trouve souvent des structures de tableaux complexes, avec une représentation des données non standard, plusieurs niveaux d'imbrication, et les modèles dans ces cas ne fonctionnent pas toujours bien. Encore une fois, vous devez écrire des scripts contenant de nombreux paramètres, conditions, exceptions, etc. sélectionnés manuellement.
Utilisation de l'apprentissage automatique
Aujourd'hui, la technologie ne s'arrête pas et avec le développement de l'apprentissage automatique, il est devenu possible de transférer la tâche d'extraction des données des documents vers les réseaux de neurones.
Aujourd'hui, plusieurs approches de base sont utilisées dans la pratique:
- La première approche consiste à travailler directement avec l'image d'entrée du document. C'est-à-dire qu'une image (image) ou un fragment est envoyé à l'entrée du réseau, et le réseau apprend à trouver de petites zones où se trouvent les champs nécessaires, puis le texte dans ces zones est reconnu à l'aide des technologies classiques OCR (Optical Character Recognition). Il s'agit d'une solution de bout en bout qui peut être rapidement mise en œuvre. Vous pouvez prendre un réseau prêt à l'emploi pour rechercher des objets dans des images, par exemple, YOLO ou Faster R-CNN et le former à des images annotées de documents.
L'inconvénient de cette approche n'est pas la meilleure qualité des données extraites et la difficulté d'extraire des tableaux. En fait, cette approche est en quelque sorte similaire à la tâche de trouver les bons mots dans l'image (repérage de mots), un problème fondamental du domaine de la vision par ordinateur, seulement ici nous ne recherchons pas les mots, mais les champs nécessaires. - La deuxième approche consiste à traiter le texte extrait du document. Il peut s'agir de texte d'un PDF ou d'un document OCR pleine page. Il utilise la technologie de traitement du langage naturel (NLP) . Des lignes sont collectées à partir de mots individuels, divers fragments de texte, des paragraphes ou des colonnes sont formés à partir de lignes, et le réseau apprend déjà à distinguer différentes entités nommées NER (Named-Entity Recognition).
Différentes manières de former des fragments de texte sont possibles. Vous pouvez combiner les première et deuxième approches, former un réseau pour trouver de gros blocs avec certaines informations dans les images, par exemple, des données sur l'expéditeur ou des données sur le destinataire, qui contiennent immédiatement le nom, l'adresse, les détails, etc., puis transférer le texte de chaque bloc au deuxième réseau NER.
La qualité de cette approche peut s'avérer supérieure à celle de la première approche, mais il est plutôt difficile de construire un modèle efficace. Aujourd'hui, il existe des modèles assez avancés, par exemple, LSTM-CRF pour NER, qui peuvent étiqueter des mots dans le texte et définir des entités. - La troisième approche consiste à construire une représentation sémantique du document sans référence au type de document, c'est-à-dire lorsque nous ne savons pas ce que le document est devant nous, mais nous essayons de le comprendre pendant le traitement. Un ensemble de mots de document avec leurs divers attributs (par exemple, le mot contient-il uniquement des lettres ou est-ce un nombre), la disposition géométrique des mots (coordonnées, retraits) et avec divers délimiteurs et connexions identifiés lors de l'analyse d'image, est alimenté à l'entrée du réseau et la sortie est obtenue pour Chaque mot a ses propres caractéristiques spécifiques. Sur la base des caractéristiques obtenues, divers ensembles d'hypothèses de champs ou de tables possibles sont formés, qui sont ensuite triés et évalués par un classificateur supplémentaire. Ensuite, l'hypothèse la plus fiable de la structure et du contenu du document est sélectionnée.
C'est déjà techniquement la solution la plus difficile, mais vous pouvez résoudre le problème de l'extraction de données à partir de documents de manière générale.
Comment utilisons-nous les réseaux de neurones
Chez ABBYY, nous surveillons non seulement de près les réalisations de la science et de la technologie, mais nous créons également nos propres technologies de pointe et les mettons en œuvre dans divers produits.
La figure ci-dessous montre l'architecture générale de notre solution à l'aide de réseaux de neurones.
Image cliquable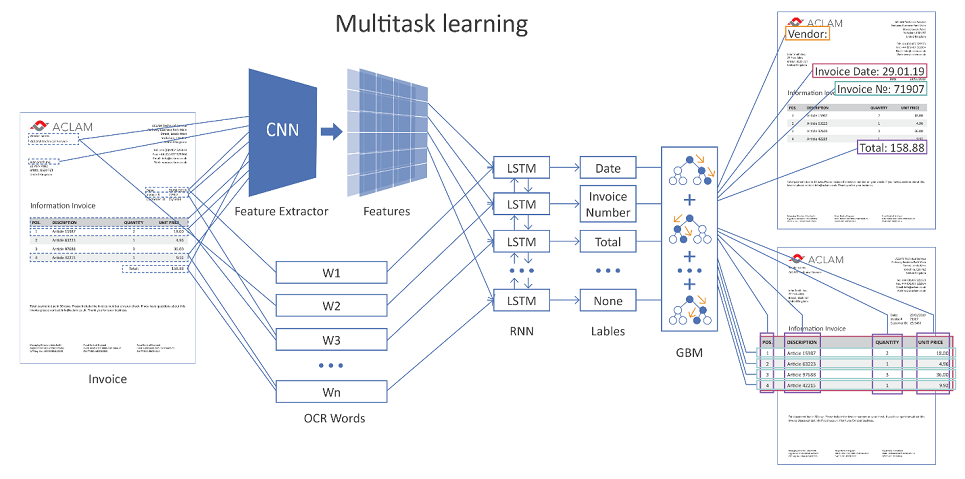
La page de document entière est envoyée à l'entrée réseau. À l'aide de couches convolutives (CNN), diverses caractéristiques géométriques sont formées, par exemple, la position relative des mots les uns par rapport aux autres. De plus, ces signes sont combinés avec la représentation vectorielle de mots reconnus (imbrication de mots) et servis sur des couches récurrentes (LSTM) et entièrement connectées. Il existe plusieurs couches de sortie différentes (apprentissage multi-tâches), chaque sortie résout son propre problème:
- détermination du type de champ auquel le mot peut correspondre,
- hypothèses de limites de table,
- hypothèses de lignes de tableau, limites de colonnes, etc.
Si le document est de plusieurs pages, le réseau fait sa prédiction pour chaque page individuelle, puis les résultats sont combinés.
Ensuite, des hypothèses sont formées sur la disposition possible des champs et des tables, à l'aide d'une fonction de régression formée séparément, elles sont évaluées et l'hypothèse la plus confiante l'emporte.
Afin d'augmenter la précision de l'extraction des données, en plus de séparer les documents par type (chèque, facture, contrat, etc.), un regroupement supplémentaire se produit à l'intérieur de son type en fonction de caractéristiques supplémentaires.
Par exemple, pour les factures, il peut s'agir d'un fournisseur ou simplement d'une apparence (selon le degré de similitude de l'emplacement des champs). Et puis, en fonction d'un groupe particulier (cluster), des paramètres d'algorithme spécifiques sont appliqués. Techniquement, ayant des exemples de factures correctement marquées pour différents groupes, il est possible du côté de l'utilisateur de recycler les mécanismes d'évaluation et de choix des bonnes hypothèses.
Pour configurer toutes sortes de paramètres de nos algorithmes et réseaux de neurones, nous utilisons la méthode d'évolution différentielle, qui a fait ses preuves en pratique.
Nos résultats d'apprentissage automatique

- La méthode développée pour extraire des données de documents structurés en utilisant l'apprentissage automatique montre dans de nombreux cas de meilleurs résultats que les solutions programmées basées sur l'heuristique. Le gain de qualité dans diverses mesures varie de plusieurs unités à des dizaines de pour cent sur diverses entités extractibles.
- Il y a un avantage indéniable par rapport à l'approche classique - la possibilité de recycler le réseau sur de nouvelles données. Dans le cas de diverses formes de documents, ce n'est plus un problème, mais plutôt un besoin. Plus ils sont nombreux, mieux c'est; plus la capacité du réseau à généraliser est forte et plus la qualité est élevée.
- Il était possible de sortir la soi-disant solution «prête à l'emploi», lorsque l'utilisateur installe simplement le produit (en fait, un réseau formé), et que tout commence immédiatement à fonctionner avec un résultat acceptable. Il n'est pas nécessaire de programmer quoi que ce soit, de personnaliser longuement et péniblement les modèles, de sélectionner toutes sortes de paramètres.
Un détail important que je voudrais également mentionner concerne les données. Aucun apprentissage automatique ne peut se produire sans données de qualité. L'apprentissage automatique donne de meilleurs résultats que l'ingénierie des connaissances, uniquement s'il existe une quantité suffisante de données balisées. Dans le cas des factures, ce sont des dizaines de milliers de documents étiquetés manuellement, et ce chiffre est en constante augmentation.
En outre, nous utilisons des mécanismes avancés d'augmentation des données, modifions les noms des organisations, les adresses, les listes de biens et les types de services dans des tableaux, des dates, diverses caractéristiques quantitatives, telles que le prix, la quantité, le coût, etc. Nous modifions également la séquence des différentes entités dans les documents, ce qui nous permet de générer à terme des millions de documents complètement différents pour la formation.
Au lieu d'une conclusion
En conclusion, on peut dire que la programmation n'a bien sûr pas disparu, mais change progressivement de rôle. À chaque nouvelle journée, l'apprentissage automatique commence à mieux faire face aux tâches qui lui sont assignées dans une variété d'industries, évincant les approches classiques. L'avantage indéniable de l'apprentissage automatique en termes d'efficacité: des dizaines d'années-homme de travail intellectuel coûtent désormais des dizaines d'heures-machine d'apprentissage. Par conséquent, dans un avenir proche, nous voyons un développement et une applicabilité encore plus grands des réseaux dans tous nos développements. Et si vous êtes intéressé, nous sommes toujours ouverts aux suggestions et à la
coopération .