Salut Habr!
De nombreux lecteurs et auteurs réguliers du site ont probablement réfléchi au cycle de vie des articles publiés ici. Et bien que cela soit intuitivement plus ou moins clair (il est évident, par exemple, que l'article de la première page a le maximum de vues), mais combien précisément?
Pour collecter des statistiques, nous utiliserons Python, Pandas, Matplotlib et Raspberry Pi.
Ceux qui sont intéressés par ce qui en est ressorti, sous cat.
Collecte de données
Tout d'abord, décidons des métriques - ce que nous voulons savoir. Tout est simple ici, chaque article a 4 paramètres principaux affichés sur la page - c'est le nombre de vues, de likes, de signets et de commentaires. Nous les analyserons.
Ceux qui veulent voir immédiatement les résultats peuvent passer à la troisième partie, mais pour l'instant il s'agira de programmation.
Plan général: nous analyserons les données nécessaires de la page Web, les enregistrerons avec CSV et verrons ce que nous obtenons pendant plusieurs jours. Tout d'abord, chargez le texte de l'article (gestion des exceptions omise pour plus de clarté):
link = "https://habr.com/ru/post/000001/" f = urllib.urlopen(link) data_str = f.read()
Maintenant, nous devons extraire les données de la ligne data_str (c'est, bien sûr, en HTML). Ouvrez le code source dans le navigateur (éléments sans principes supprimés):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514"> <li class="post-stats__item post-stats__item_voting-wjt"> <span class="voting-wjt__counter voting-wjt__counter_positive js-score" title=" 448: ↑434 ↓14">+420</span> </li> <span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title=" , ">320</span></span> <li class="post-stats__item post-stats__item_views"> <div class="post-stats__views" title=" "> <span class="post-stats__views-count">219k</span> </div> </li> <li class="post-stats__item post-stats__item_comments"> <a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title=" ">577</span> </a> </li> <li class="post-stats__item"> <span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg> </span> </li> </ul>
Il est facile de voir que le texte dont nous avons besoin se trouve dans le bloc '<ul class = "post-stats post-stats_post js-user_>', et les éléments nécessaires sont dans des blocs avec les noms voter-wjt__counter, bookmark__counter, post-stats__views-count et post- stats__comments-count. Par son nom, tout est assez évident.
Nous hériterons de la classe str et y ajouterons la méthode d'extraction de la sous-chaîne située entre les deux balises:
class Str(str): def find_between(self, first, last): try: start = self.index(first) + len(first) end = self.index(last, start) return Str(self[start:end]) except ValueError: return Str("")
Vous pourriez vous passer de l'héritage, mais cela vous permettra d'écrire du code plus concis. Avec lui, toute l'extraction de données tient sur 4 lignes:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<') bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<') views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<') comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
Mais ce n'est pas tout. Comme vous pouvez le voir, le nombre de commentaires ou de vues peut être stocké sous la forme d'une chaîne comme «12,1 k», qui n'est pas directement traduite en int.
Ajoutez une fonction pour convertir une telle chaîne en nombre:
def to_int(self): s = self.lower().replace(",", ".") if s[-1:] == "k":
Il ne reste plus qu'à ajouter un horodatage, et vous pouvez enregistrer les données en csv:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime()) str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
Comme nous souhaitons analyser plusieurs articles, nous ajoutons la possibilité de spécifier un lien via la ligne de commande. Nous générerons également le nom du fichier journal par l'ID d'article:
link = sys.argv[1]
Et la toute dernière étape. Nous retirons le code dans la fonction, dans la boucle nous interrogeons les données et écrivons les résultats dans le journal.
delay_s = 5*60 while True:
Comme vous pouvez le constater, les données ont été mises à jour toutes les 5 minutes afin de ne pas créer de charge sur le serveur. J'ai enregistré le fichier programme sous le nom habr_parse.py, quand il démarre, il enregistre les données jusqu'à la fermeture du programme.
De plus, il est conseillé de sauvegarder les données, au moins pendant quelques jours. Parce que Nous sommes réticents à garder l'ordinateur allumé pendant plusieurs jours, nous prenons le Raspberry Pi - il est assez puissant pour une telle tâche, et contrairement à un PC, le Raspberry Pi ne fait pas de bruit et ne consomme presque pas d'électricité. Nous allons sur SSH et exécutons notre script:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
La commande nohup laisse le script en arrière-plan après la fermeture de la console.
En prime, vous pouvez exécuter un serveur http en arrière-plan en entrant la commande "nuhup python -m SimpleHTTPServer 8000 &". Cela vous permettra de visualiser les résultats directement dans le navigateur à tout moment, en ouvrant un lien du formulaire
http://192.168.1.101:8000 (l'adresse, bien sûr, peut être différente).
Vous pouvez maintenant laisser le Raspberry Pi allumé et revenir au projet dans quelques jours.
Analyse des données
Si tout a été fait correctement, la sortie devrait ressembler à ce journal:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1; 2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1; 2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1; 2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1; 2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1; 2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1; 2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1; 2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2; 2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3; 2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4; ... 2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20; 2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
Voyons comment cela peut être traité. Pour commencer, chargez csv dans une trame de données pandas:
import pandas as pd import numpy as np import datetime log_path = "habr_data.txt" df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
Ajoutez des fonctions de conversion et de moyenne et extrayez les données nécessaires:
def to_float(s):
La moyenne est nécessaire car le nombre de vues sur le site est affiché par incréments de 100, ce qui conduit à un planning «déchiré». En principe, cela n'est pas nécessaire, mais avec une moyenne, cela semble mieux. Le fuseau horaire de Moscou est également ajouté dans le code (l'heure sur le Raspberry Pi s'est avérée être GMT).
Enfin, vous pouvez afficher les graphiques et voir ce qui s'est passé.
import matplotlib.pyplot as plt
Résultats
Au début de chaque graphique, il y a un espace vide, qui est expliqué simplement - lorsque le script a été lancé, les articles étaient déjà publiés, donc les données n'ont pas été collectées à partir de zéro. Le point «zéro» a été ajouté manuellement à partir de la description de l'heure de publication de l'article.
Tous les graphiques présentés sont générés par matplotlib et le code ci-dessus.
Selon les résultats, j'ai divisé les articles étudiés en 3 groupes. La division est conditionnelle, bien qu'elle ait encore un certain sens.
Article chaud
Cet article concerne un sujet populaire et pertinent, avec un titre comme «Comment MTS déduit de l'argent» ou «Roskomnadzor a bloqué le hub de git
porn ».
De tels articles ont un grand nombre de vues et de commentaires, mais le "battage médiatique" dure plusieurs jours au maximum. Vous pouvez également voir une légère différence dans la croissance du nombre de vues pendant le jour et la nuit (mais pas aussi importante que prévu - apparemment, Habr est lu dans presque tous les fuseaux horaires).
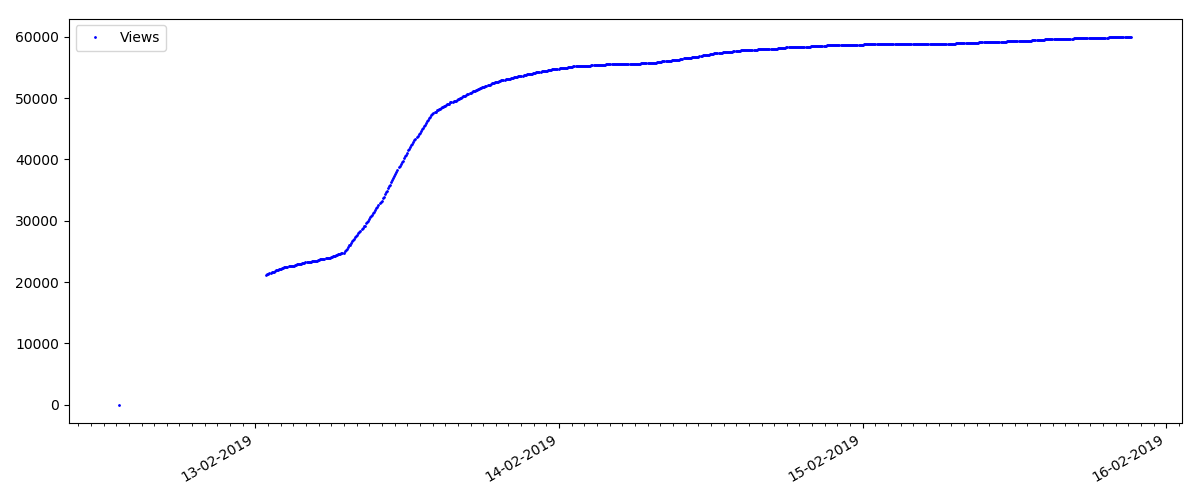
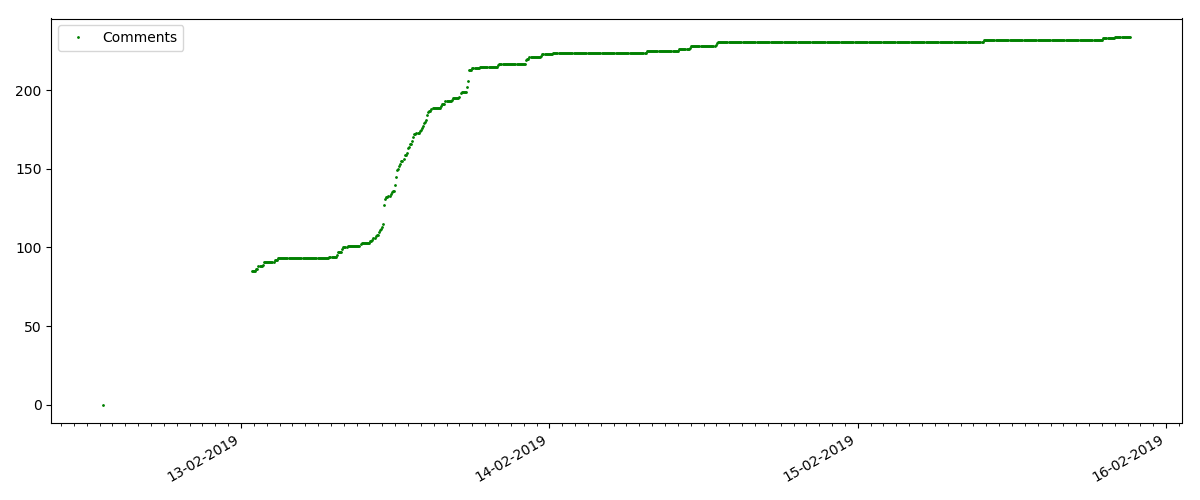
Le nombre de «likes» augmente de manière assez significative, tandis que le nombre de signets augmente sensiblement plus lentement. C'est logique, car Quelqu'un peut aimer l'article, mais la spécificité du texte est telle qu'il n'est tout simplement pas nécessaire de le mettre en signet.
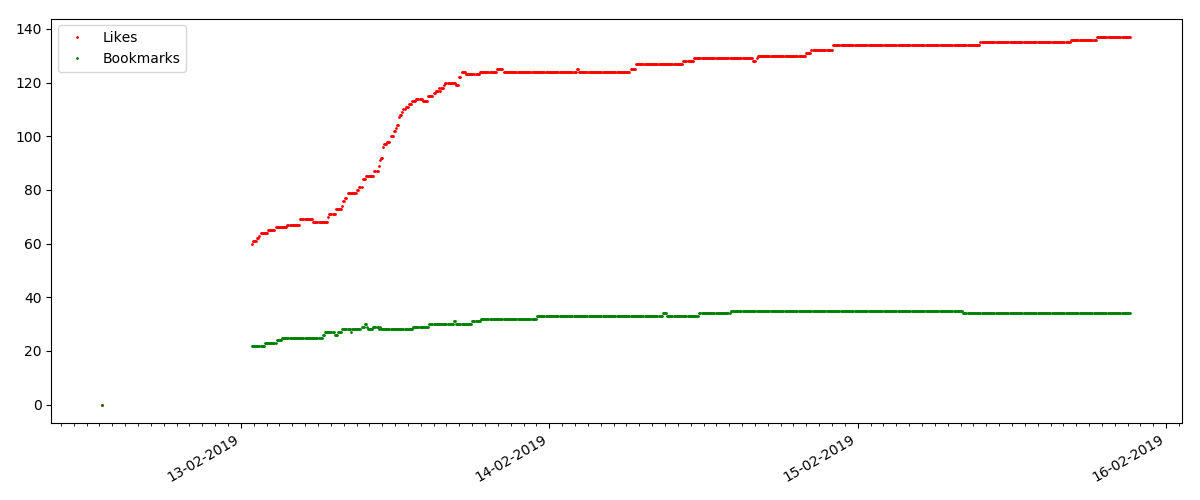
Le ratio de vues et de likes reste à peu près le même et est d'environ 400: 1:
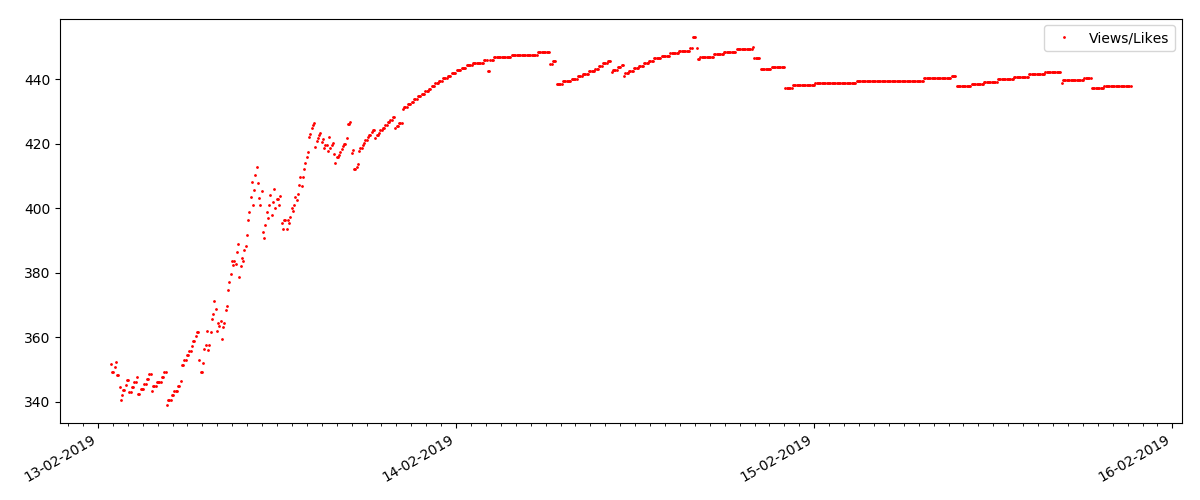
Article "technique"
Il s'agit d'un article plus spécialisé, tel que «Configuration de scripts pour Node JS». Un tel article, bien entendu, gagne beaucoup moins de vues que le «chaud», le nombre de commentaires est également sensiblement plus petit (dans ce cas, il n'y en avait que 4).
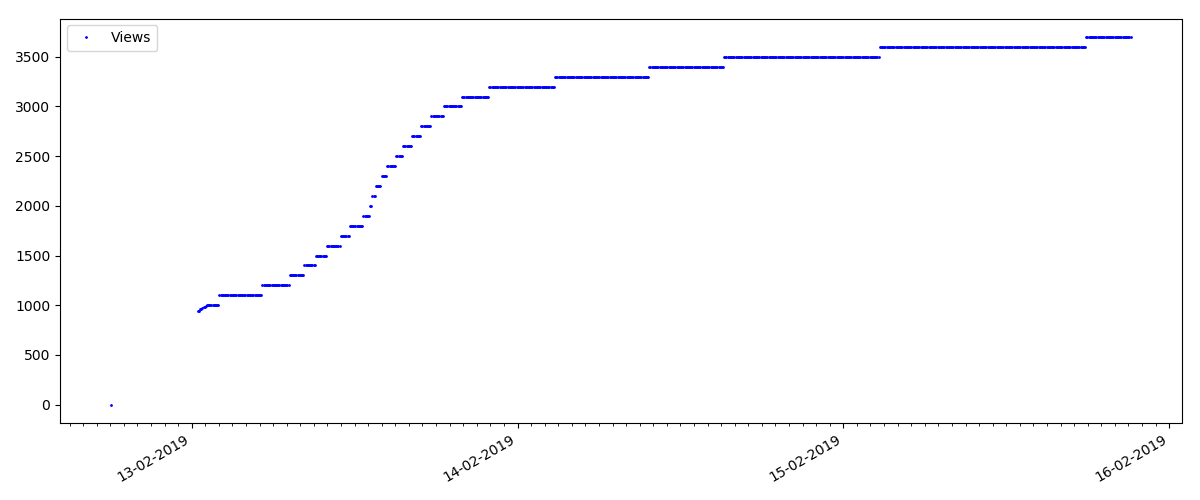
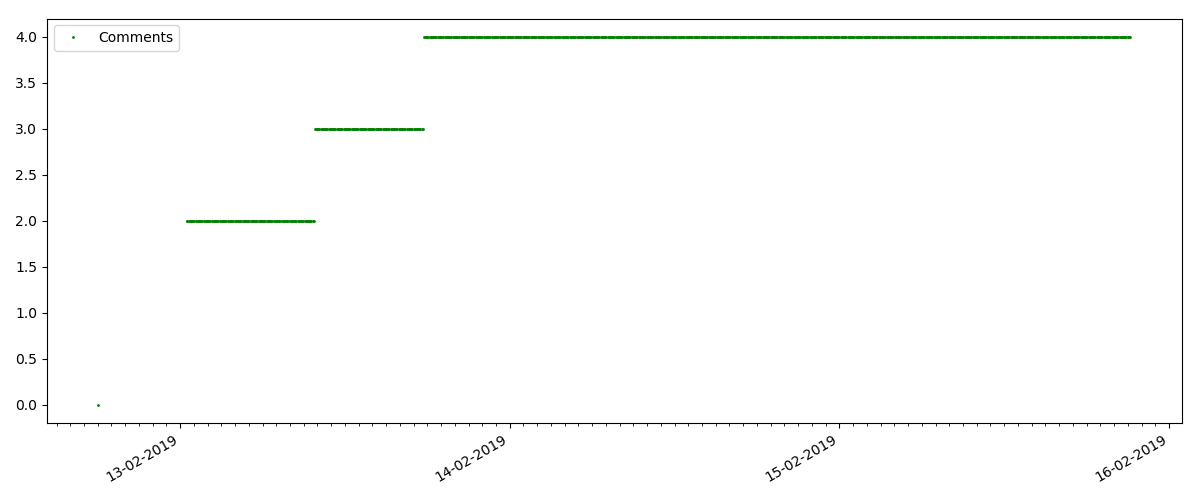
Mais le point suivant est plus intéressant: le nombre de «likes» pour de tels articles augmente sensiblement plus lentement que le nombre de «signets». Ici, c'est l'inverse par rapport à la version précédente - beaucoup trouvent l'article utile à enregistrer pour l'avenir, mais le lecteur n'a pas du tout à cliquer sur "J'aime".
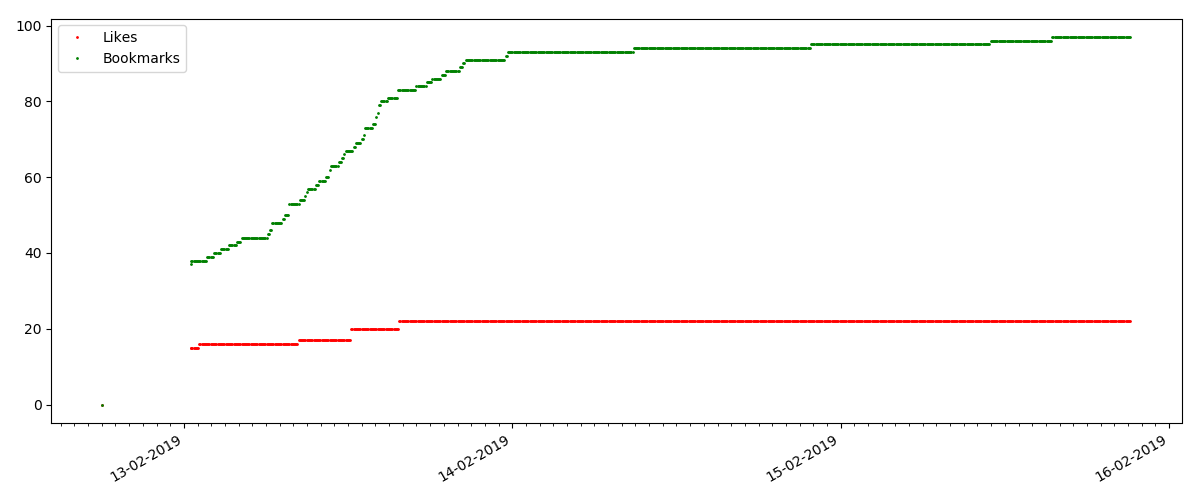
Soit dit en passant, à ce stade, je voudrais attirer l'attention des administrateurs du site - lors du calcul des notes d'articles, vous devez compter les signets en parallèle avec les likes (par exemple, combiner des ensembles par OR). Sinon, cela conduit à un biais dans la note, lorsqu'un article bien connu contient de nombreux signets (c'est-à-dire que les lecteurs l'ont certainement aimé), mais ces personnes ont oublié ou étaient trop paresseuses pour cliquer sur «J'aime».
Et enfin, le ratio de vues et de likes: vous pouvez voir qu'il est sensiblement plus élevé que dans le premier mode de réalisation et qu'il est à peu près 150: 1, c'est-à-dire la qualité du contenu peut également être indirectement considérée comme supérieure.
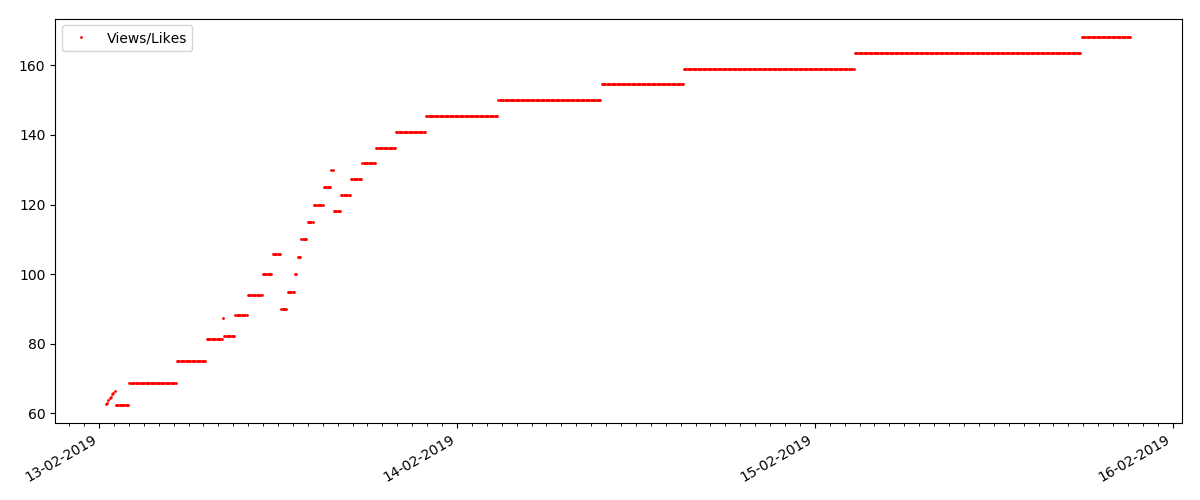
Article "suspect" (mais ce n'est pas exact)
Pour le prochain article examiné, le nombre de «j'aime» a augmenté d'un tiers dans un intervalle de 5 minutes (immédiatement de 10 avec un total de 30 marqués pour tous les jours).
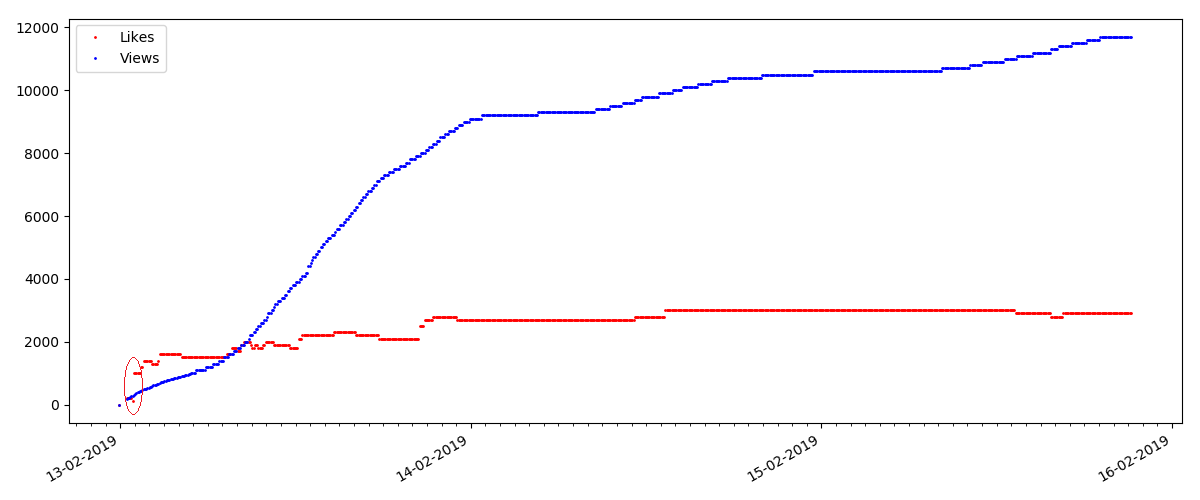
On pourrait soupçonner une triche, mais la "théorie de la file d'attente" permet en principe de telles surtensions. Ou peut-être que l'auteur vient d'envoyer le lien à ses 10 amis, ce qui, bien sûr, n'est pas interdit par les règles.
Conclusions
La principale conclusion est que tout est délabrement et maya. Même le matériel le plus populaire, gagnant des milliers de vues, ira "dans le passé" en seulement 3-4 jours. Telles sont, hélas, les spécificités de l'Internet moderne, et probablement l'ensemble de l'industrie des médias modernes dans son ensemble. Et je suis sûr que les chiffres indiqués sont spécifiques non seulement pour Habr, mais aussi pour toute ressource Internet similaire.
Sinon, cette analyse est plus susceptible d'être de nature «vendredi» et, bien sûr, ne prétend pas être une étude sérieuse. J'espère aussi que quelqu'un a trouvé quelque chose de nouveau en utilisant Pandas et Matplotlib.
Merci de votre attention.