Bonjour, Habr! Dans cet article, nous allons écrire une application sur Spring Boot 2 à l'aide d'Apache Kafka sous Linux, de l'installation du JRE à une application de microservice fonctionnelle.
Des collègues du département de développement frontal qui ont vu l'article se plaignent que je n'explique pas ce que sont Apache Kafka et Spring Boot. Je crois que quiconque a besoin de monter un projet fini en utilisant les technologies ci-dessus sait ce que c'est et pourquoi il en a besoin. Si pour le lecteur la question n'est pas vide, voici d'excellents articles sur Habr, ce qu'est
Apache Kafka et
Spring Boot .
Nous pouvons nous passer de longues explications sur ce que sont Kafka, Spring Boot et Linux et, à la place, exécuter le serveur Kafka à partir de zéro sur une machine Linux, écrire deux microservices et faire en sorte que l'un d'eux envoie des messages à l'autre - en général, configurez architecture de microservice complète.

Le poste comprendra deux sections. Dans le premier, nous configurons et exécutons Apache Kafka sur une machine Linux, dans le second, nous écrivons deux microservices en Java.
Dans la startup, dans laquelle j'ai commencé ma carrière professionnelle en tant que programmeur, il y avait des microservices sur Kafka, et l'un de mes microservices a également travaillé avec d'autres via Kafka, mais je ne savais pas comment fonctionnait le serveur lui-même, qu'il soit écrit sous forme d'application ou est-il déjà complètement encadré produit. Quelle a été ma surprise et ma déception quand il s'est avéré que Kafka était encore un produit en boîte, et ma tâche ne serait pas seulement d'écrire un client en Java (ce que j'aime faire), ainsi que de déployer et de configurer l'application finalisée en devOps (que je déteste faire). Cependant, même si je pouvais le faire sur le serveur virtuel Kafka en moins d'une journée, c'est vraiment assez simple de le faire. Alors.
Notre application aura la structure d'interaction suivante:
À la fin du post, comme d'habitude, il y aura des liens vers git avec du code de travail.
Déployer Apache Kafka + Zookeeper sur une machine virtuelle
J'ai essayé d'élever Kafka sur Linux local, sur un coquelicot et sur Linux distant. Dans deux cas (Linux), j'ai réussi assez rapidement. Avec le pavot, il ne s'est rien passé. Par conséquent, nous lèverons Kafka sur Linux. J'ai choisi Ubuntu 18.04.
Pour que Kafka travaille, elle a besoin d'un gardien de zoo. Pour ce faire, vous devez le télécharger et l'exécuter avant de lancer Kafka.
Alors.
0. Installez JRE
Cela se fait par les commandes suivantes:
sudo apt-get update sudo apt-get install default-jre
Si tout s'est bien passé, vous pouvez entrer la commande
java -version
et assurez-vous que Java est installé.
1. Téléchargez Zookeeper
Je n'aime pas les équipes magiques sur Linux, surtout quand elles ne donnent que quelques commandes et que ce qu'elles font n'est pas clair. Par conséquent, je décrirai chaque action - ce qu'elle fait exactement. Nous devons donc télécharger Zookeeper et le décompresser dans un dossier pratique. Il est conseillé que toutes les applications soient stockées dans le dossier / opt, c'est-à-dire, dans notre cas, ce sera / opt / zookeeper.
J'ai utilisé la commande ci-dessous. Si vous connaissez d'autres commandes Linux qui, à votre avis, vous permettront de le faire plus racialement correctement, utilisez-les. Je suis un développeur, pas un devoop, et je communique avec les serveurs au niveau de "la chèvre elle-même". Alors téléchargez l'application:
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"
L'application est téléchargée dans le dossier que vous spécifiez, j'ai créé le dossier / home / xpendence / Downloads pour y télécharger toutes les applications dont j'ai besoin.
2. Déballez Zookeeper
J'ai utilisé la commande:
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gz
Cette commande décompresse l'archive dans le dossier dans lequel vous vous trouvez. Vous devrez peut-être ensuite transférer l'application vers / opt / zookeeper. Et vous pouvez immédiatement y accéder et à partir de là, décompressez déjà l'archive.
3. Modifier les paramètres
Dans le dossier / zookeeper / conf / il y a un fichier zoo-sample.cfg, je propose de le renommer zoo.conf, c'est ce fichier que la JVM recherchera au démarrage. Les éléments suivants doivent être ajoutés à ce fichier à la fin:
tickTime=2000 dataDir=/var/zookeeper clientPort=2181
Créez également le répertoire / var / zookeeper.
4. Lancez Zookeeper
Accédez au dossier / opt / zookeeper et démarrez le serveur avec la commande:
bin/zkServer.sh start
«COMMENCÉ» devrait apparaître.
Après quoi, je propose de vérifier que le serveur fonctionne. Nous écrivons:
telnet localhost 2181
Un message doit apparaître indiquant que la connexion a réussi. Si vous avez un serveur faible et que le message n'apparaît pas, essayez à nouveau - même lorsque STARTED apparaît, l'application commence à écouter le port beaucoup plus tard. Quand j'ai essayé tout cela sur un serveur faible, cela m'est arrivé à chaque fois. Si tout est connecté, entrez la commande
ruok
Qu'est-ce que cela signifie: "Êtes-vous d'accord?" Le serveur doit répondre:
imok ( !)
et déconnectez-vous. Donc, tout est conforme au plan. Nous procédons au lancement d'Apache Kafka.
5. Créez un utilisateur sous Kafka
Pour travailler avec Kafka, nous avons besoin d'un utilisateur distinct.
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka
6. Téléchargez Apache Kafka
Il existe deux distributions - binaire et sources. Nous avons besoin d'un binaire. En apparence, l'archive avec le binaire est de taille différente. Le binaire pèse 59 Mo et 6,5 Mo pèsent.
Téléchargez le binaire dans le répertoire, en utilisant le lien ci-dessous:
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"
7. Déballez Apache Kafka
La procédure de déballage n'est pas différente de la même pour Zookeeper. Nous décompressons également l'archive dans le répertoire / opt et la renommons en kafka afin que le chemin vers le dossier / bin soit / opt / kafka / bin
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz
8. Modifier les paramètres
Les paramètres se trouvent dans /opt/kafka/config/server.properties. Ajoutez une ligne:
delete.topic.enable = true
Ce paramètre semble être facultatif, il fonctionne sans lui. Ce paramètre vous permet de supprimer des sujets. Sinon, vous ne pouvez tout simplement pas supprimer des sujets via la ligne de commande.
9. Nous donnons accès aux répertoires utilisateur kafka Kafka
chown -R kafka:nogroup /opt/kafka chown -R kafka:nogroup /var/lib/kafka
10. Le lancement tant attendu d'Apache Kafka
Nous entrons dans la commande, après quoi Kafka devrait commencer:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
Si les actions habituelles (Kafka est écrit en Java et Scala) n'ont pas débordé dans le journal, alors tout a fonctionné et vous pouvez tester notre service.
10.1. Problèmes de serveur faibles
Pour des expériences sur Apache Kafka, j'ai pris un serveur faible avec un cœur et 512 Mo de RAM (pour seulement 99 roubles), ce qui s'est avéré être plusieurs problèmes pour moi.
Pas de mémoire. Bien sûr, vous ne pouvez pas overclocker avec 512 Mo et le serveur n'a pas pu déployer Kafka en raison d'un manque de mémoire. Le fait est que par défaut, Kafka consomme 1 Go de mémoire. Pas étonnant qu'il ait disparu :)
Nous allons à kafka-server-start.sh, zookeeper-server-start.sh. Il existe déjà une ligne qui régule la mémoire:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
Changez-le en:
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
Cela réduira l'appétit de Kafka et vous permettra de démarrer le serveur.
Le deuxième problème avec un ordinateur faible est le manque de temps pour se connecter à Zookeeper. Par défaut, cela donne 6 secondes. Si le fer est faible, ce n'est bien sûr pas suffisant. Dans server.properties nous augmentons le temps de connexion au zukipper:
zookeeper.connection.timeout.ms=30000
J'ai mis une demi-minute.
11. Testez le serveur Kafka
Pour ce faire, nous ouvrirons deux terminaux, l'un lancera le producteur, l'autre le consommateur.
Dans la première console, entrez une ligne:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Cette icône devrait apparaître, indiquant que le producteur est prêt à envoyer des spams:
>
Dans la deuxième console, entrez la commande:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
Maintenant, en tapant dans la console du producteur, lorsque vous appuyez sur Entrée, il apparaîtra dans la console du consommateur.
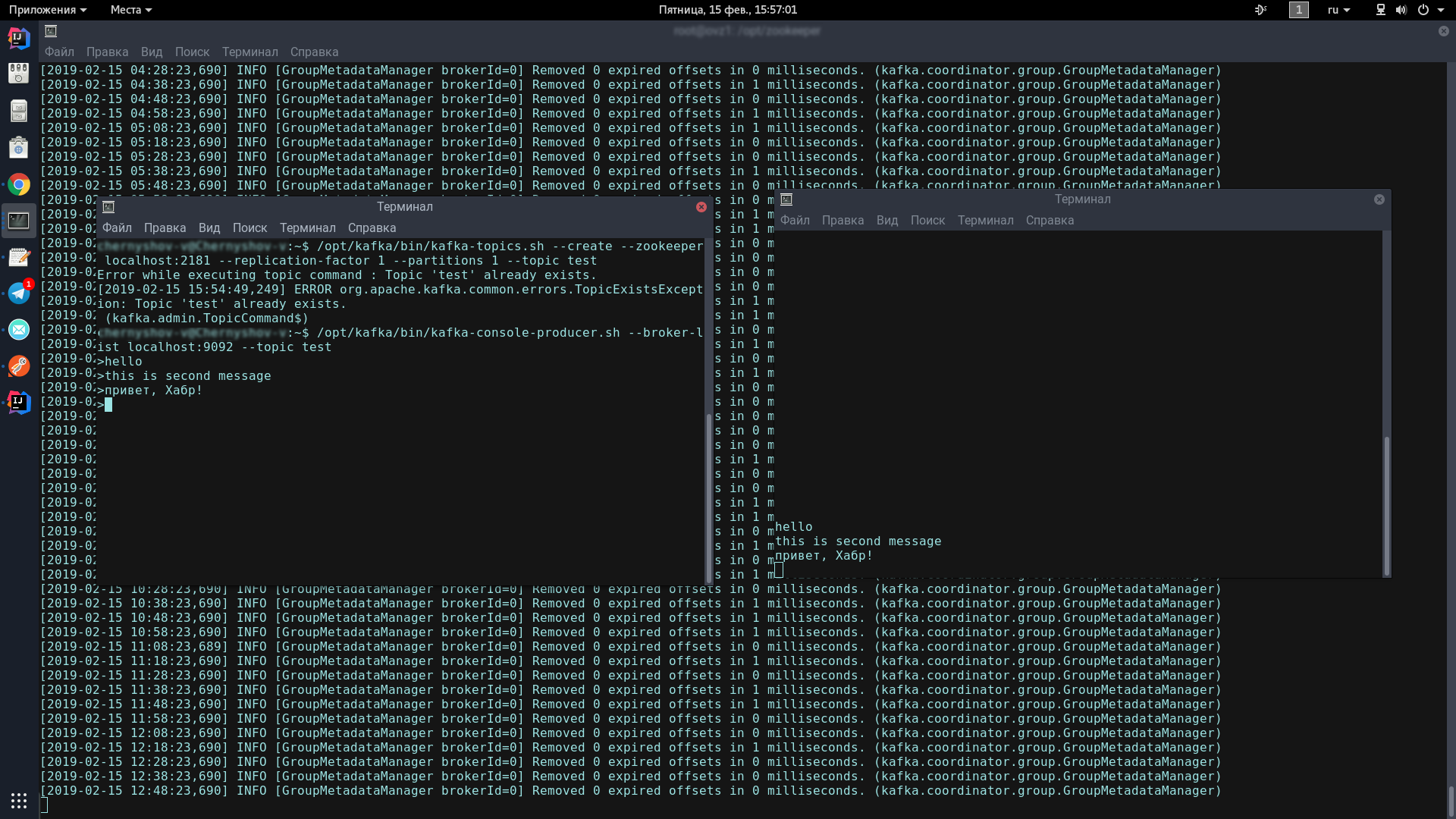
Si vous voyez à l'écran à peu près la même chose que moi - félicitations, le pire est passé!
Il ne nous reste plus qu'à écrire quelques clients sur Spring Boot qui communiqueront entre eux via Apache Kafka.
Écrire une application sur Spring Boot
Nous écrirons deux applications qui échangeront des messages via Apache Kafka. Le premier message sera appelé kafka-server et contiendra à la fois le producteur et le consommateur. Le second sera appelé kafka-tester, il est conçu de manière à disposer d'une architecture de microservice.
kafka-server
Pour nos projets créés via Spring Initializr, nous avons besoin du module Kafka. J'ai ajouté Lombok et Web, mais c'est une question de goût.
Le client Kafka se compose de deux composants - le producteur (il envoie des messages au serveur Kafka) et le consommateur (il écoute le serveur Kafka et en prend de nouveaux messages sur les sujets auxquels il est abonné). Notre tâche est d'écrire les deux composants et de les faire fonctionner.
Consommateur:
@Configuration public class KafkaConsumerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.group.id}") private String kafkaGroupId; @Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; } @Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); } }
Nous avons besoin de 2 champs initialisés avec des données statiques de kafka.properties.
kafka.server=localhost:9092 kafka.group.id=server.broadcast
kafka.server est l'adresse à laquelle notre serveur se bloque, dans ce cas, local. Par défaut, Kafka écoute sur le port 9092.
kafka.group.id est un groupe de consommateurs, au sein duquel une instance du message est remise. Par exemple, vous avez trois courriers dans un groupe et ils écoutent tous le même sujet. Dès qu'un nouveau message apparaît sur le serveur avec cette rubrique, il est remis à un membre du groupe. Les deux autres consommateurs ne reçoivent pas le message.
Ensuite, nous créons une usine pour les consommateurs - ConsumerFactory.
@Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); }
Initialisé avec les propriétés dont nous avons besoin, il servira à l'avenir d'usine standard aux consommateurs.
@Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; }
consumerConfigs ne sont que des configurations de carte. Nous fournissons l'adresse du serveur, le groupe et les désérialiseurs.
En outre, l'un des points les plus importants pour un consommateur. Le consommateur peut recevoir à la fois des objets uniques et des collections - par exemple, StarshipDto et List. Et si nous obtenons StarshipDto en JSON, alors nous obtenons List en gros, en tant que tableau JSON. Par conséquent, nous avons au moins deux fabriques de messages - pour les messages simples et pour les tableaux.
@Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; }
Nous instancions ConcurrentKafkaListenerContainerFactory, tapons Long (clé de message) et AbstractDto (valeur de message abstraite), et initialisons ses champs avec des propriétés. Bien sûr, nous initialisons l'usine avec notre usine standard (qui contient déjà des configurations de carte), puis nous marquons que nous n'écoutons pas les paquets (les mêmes tableaux) et spécifions un convertisseur JSON simple comme convertisseur.
Lorsque nous créons une usine pour les packages / tableaux (batch), la principale différence (en dehors du fait que nous marquons que nous écoutons les packages) est que nous spécifions comme convertisseur un convertisseur de package spécial qui convertira les packages composés de à partir de chaînes JSON.
@Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); }
Et encore une chose. Lors de l'initialisation des beans Spring, le bac sous le nom kafkaListenerContainerFactory peut ne pas être compté et l'application sera ruinée. Il y a sûrement des options plus élégantes pour résoudre le problème, écrivez à leur sujet dans les commentaires, pour l'instant je viens de créer un bac déchargé avec des fonctionnalités du même nom:
@Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); }
Le consommateur est installé. Nous passons au producteur.
@Configuration public class KafkaProducerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.producer.id}") private String kafkaProducerId; @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); props.put(ProducerConfig.CLIENT_ID_CONFIG, kafkaProducerId); return props; } @Bean public ProducerFactory<Long, StarshipDto> producerStarshipFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public KafkaTemplate<Long, StarshipDto> kafkaTemplate() { KafkaTemplate<Long, StarshipDto> template = new KafkaTemplate<>(producerStarshipFactory()); template.setMessageConverter(new StringJsonMessageConverter()); return template; } }
Parmi les variables statiques, nous avons besoin de l'adresse du serveur kafka et de l'ID du producteur. Il peut être n'importe quoi.
Dans les configs, comme on le voit, il n'y a rien de spécial. Presque la même chose. Mais en ce qui concerne les usines, il y a une différence significative. Nous devons enregistrer un modèle pour chaque classe, dont nous enverrons les objets au serveur, ainsi qu'une usine pour celui-ci. Nous en avons une, mais il peut y en avoir des dizaines.
Dans le modèle, nous marquons que nous allons sérialiser des objets en JSON, et cela suffit peut-être.
Nous avons un consommateur et un producteur, il reste à écrire un service qui va envoyer et recevoir des messages.
@Service @Slf4j public class StarshipServiceImpl implements StarshipService { private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate; private final ObjectMapper objectMapper; @Autowired public StarshipServiceImpl(KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate, ObjectMapper objectMapper) { this.kafkaStarshipTemplate = kafkaStarshipTemplate; this.objectMapper = objectMapper; } @Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); } @Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); } private String writeValueAsString(StarshipDto dto) { try { return objectMapper.writeValueAsString(dto); } catch (JsonProcessingException e) { e.printStackTrace(); throw new RuntimeException("Writing value to JSON failed: " + dto.toString()); } } }
Il n'y a que deux méthodes dans notre service, elles nous suffisent pour expliquer le travail du client. Nous câblons automatiquement les modèles dont nous avons besoin:
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;
Méthode du producteur:
@Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); }
Pour envoyer un message au serveur, il suffit d'appeler la méthode d'envoi sur le modèle et d'y transférer le sujet (sujet) et notre objet. L'objet sera sérialisé en JSON et volera vers le serveur sous la rubrique spécifiée.
La méthode d'écoute ressemble à ceci:
@Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); }
Nous marquons cette méthode avec l'annotation @KafkaListener, où nous indiquons tout ID que nous aimons, les sujets écoutés et une usine qui convertira le message reçu en ce dont nous avons besoin. Dans ce cas, puisque nous acceptons un objet, nous avons besoin d'une seule usine. Pour Liste <?>, Spécifiez batchFactory. En conséquence, nous envoyons l'objet au serveur kafka en utilisant la méthode send et l'obtenons en utilisant la méthode consume.
Vous pouvez écrire un test en 5 minutes qui montrera toute la force de Kafka, mais nous irons plus loin - passez 10 minutes et écrivez une autre application qui enverra des messages au serveur que notre première application écoutera.
testeur de kafka
Ayant l'expérience d'écrire la première application, nous pouvons facilement écrire la seconde, surtout si nous copions la pâte et le package dto, enregistrons uniquement le producteur (nous n'enverrons que des messages) et ajouterons la seule méthode d'envoi au service. En utilisant le lien ci-dessous, vous pouvez facilement télécharger le code du projet et vous assurer qu'il n'y a rien de compliqué.
@Scheduled(initialDelay = 10000, fixedDelay = 5000) @Override public void produce() { StarshipDto dto = createDto(); log.info("<= sending {}", writeValueAsString(dto)); kafkaStarshipTemplate.send("server.starship", dto); } private StarshipDto createDto() { return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000)); }
Après les 10 premières secondes, le testeur de kafka commence à envoyer des messages avec les noms des vaisseaux spatiaux au serveur Kafka toutes les 5 secondes (l'image est cliquable).
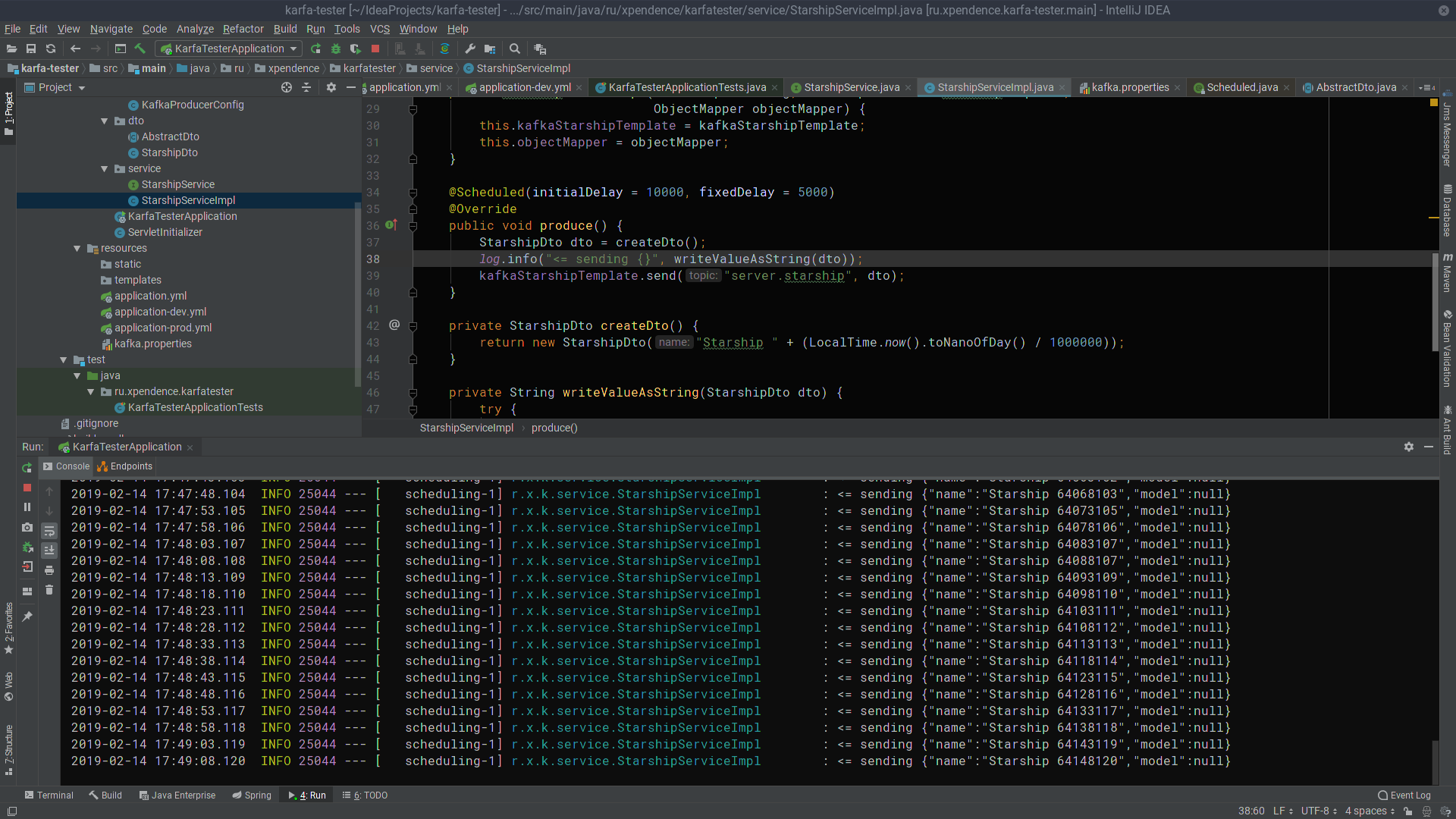
Là, ils sont écoutés et reçus par kafka-server (l'image est également cliquable).

J'espère que ceux qui rêvent de commencer à écrire des microservices chez Kafka réussiront aussi facilement que moi. Et voici les liens vers les projets:
→
serveur kafka→
testeur de kafka