Salut, habrozhiteli!
Nous avons décidé de partager la traduction du chapitre «Systèmes basés sur des files d'attente de tâches» de la nouveauté à venir «Systèmes distribués. Design patterns »(déjà dans l'imprimerie).
La forme la plus simple de traitement par lots est la file d'attente des tâches. Dans un système avec une file d'attente de tâches, il existe un ensemble de tâches qui doivent être terminées. Chaque tâche est complètement indépendante des autres et peut être traitée sans aucune interaction avec elles. Dans le cas général, l'objectif d'un système avec une file d'attente de tâches est de s'assurer que chaque étape du travail est terminée dans un laps de temps donné. Le nombre de workflows augmente ou diminue en fonction de l'évolution de la charge. Le schéma de la file d'attente de tâches généralisée est présenté à la Fig. 10.1.
Un système basé sur une file d'attente de tâches généralisée
La ligne de tâches est un exemple idéal qui montre toute la puissance des modèles de conception de systèmes distribués. La plupart de la logique de la file d'attente des tâches ne dépend pas du type de travail effectué. Dans de nombreux cas, il en va de même pour l'exécution des tâches elles-mêmes.
Illustrons cette déclaration à l'aide de la file d'attente des tâches illustrée à la Fig. 10.1. Après l'avoir réexaminé, déterminez quelles fonctions peuvent être fournies par un ensemble partagé de conteneurs. Il devient évident que la plupart de l'implémentation d'une file d'attente de tâches conteneurisée peut être utilisée par un large éventail d'utilisateurs.
La mise en file d'attente des tâches basée sur des conteneurs nécessite des interfaces correspondantes entre les conteneurs de bibliothèque et les conteneurs avec une logique utilisateur. Dans la file d'attente des tâches conteneurisées, deux interfaces sont distinguées: l'interface du conteneur source, qui fournit un flux de tâches nécessitant un traitement, et l'interface du conteneur d'exécution, qui sait comment les gérer.
Interface du conteneur source
Toute file d'attente de tâches fonctionne sur la base d'un ensemble de tâches qui nécessitent un traitement. Selon l'application spécifique implémentée sur la base de la file d'attente des tâches, il existe de nombreuses sources de tâches qui y entrent. Mais après avoir reçu un ensemble de tâches, le schéma d'opération de file d'attente est assez simple. Par conséquent, nous pouvons séparer la logique spécifique à l'application de la source de tâche du schéma généralisé de traitement de la file d'attente de tâches. En rappelant les modèles de groupes de conteneurs discutés précédemment, vous pouvez voir ici la mise en œuvre du modèle Ambassador. Le conteneur de file d'attente de tâches généralisé est le conteneur d'application principal et le conteneur source spécifique à l'application est un ambassadeur diffusant les demandes du conteneur du gestionnaire de files d'attente aux exécuteurs de tâches spécifiques. Ce groupe de conteneurs est illustré à la Fig. 10.2.

Soit dit en passant, bien que l'ambassadeur de conteneur soit spécifique à l'application (ce qui est évident), il existe également un certain nombre d'implémentations généralisées de l'API de source de tâches. Par exemple, la source peut être une liste de photos situées dans un stockage cloud, un ensemble de fichiers sur un lecteur réseau, ou même une file d'attente dans des systèmes fonctionnant sur le principe de "publication / abonnement", tels que Kafka ou Redis. Bien que les utilisateurs puissent choisir les ambassadeurs de conteneurs les mieux adaptés à leur tâche, ils doivent utiliser une implémentation de «bibliothèque» généralisée du conteneur lui-même. Cela minimisera la quantité de travail et maximisera la réutilisation du code.
API de file d'attente des tâches Étant donné le mécanisme d'interaction entre la file d'attente des tâches et le conteneur dépendant de l'application, nous devons formuler une définition formelle de l'interface entre les deux conteneurs. Il existe de nombreux protocoles différents, mais les API HTTP RESTful sont faciles à implémenter et constituent la norme de facto pour de telles interfaces. La file d'attente des tâches s'attend à ce que les URL suivantes soient implémentées dans le conteneur après:
Pourquoi ajouter la v1 à votre définition d'API, demandez-vous? Y aura-t-il jamais une deuxième version de l'interface? Cela semble illogique, mais le coût de versioning de l'API lorsqu'il est initialement défini est minime. La réalisation du refactoring approprié plus tard sera extrêmement coûteuse. Faites-en une règle pour ajouter des versions à toutes les API, même si vous n'êtes pas sûr qu'elles changeront jamais. Dieu sauve le coffre-fort.
URL / éléments / renvoie une liste de toutes les tâches:
{ kind: ItemList, apiVersion: v1, items: [ "item-1", "item-2", …. ] }
L'URL / items / <item-name> fournit des informations détaillées sur une tâche spécifique:
{ kind: Item, apiVersion: v1, data: { "some": "json", "object": "here", } }
Veuillez noter que l'API ne fournit aucun mécanisme pour corriger le fait de la tâche. On pourrait développer une API plus complexe et transférer la plupart de l'implémentation à un ambassadeur de conteneurs. N'oubliez pas, cependant, que notre objectif est de concentrer le plus possible l'implémentation globale dans le gestionnaire de files d'attente de tâches. À cet égard, le gestionnaire de files d'attente de tâches doit lui-même surveiller les tâches qui ont déjà été traitées et celles qui doivent encore l'être.
De cette API, nous obtenons des informations sur une tâche spécifique, puis passons la valeur du champ item.data de l'interface conteneur de l'exécuteur.
Exécution de l'interface de conteneur
Dès que le gestionnaire de files d'attente a reçu la tâche suivante, il doit la confier à un exécuteur. Il s'agit de la deuxième interface de la file d'attente de tâches généralisée. Le conteneur lui-même et son interface sont légèrement différents de l'interface du conteneur source pour plusieurs raisons. Tout d'abord, il s'agit d'une API unique. Le travail de l'exécuteur testamentaire commence par un seul appel, et pendant le cycle de vie du conteneur, plus aucun appel n'est effectué. Deuxièmement, le conteneur en cours d'exécution et le gestionnaire de files d'attente de tâches se trouvent dans des groupes de conteneurs différents. L'exécuteur de conteneur est lancé via l'API d'orchestrateur de conteneur dans son propre groupe. Cela signifie que le gestionnaire de files d'attente de tâches doit effectuer un appel distant pour lancer le conteneur d'exécution. Cela signifie également que vous devez faire plus attention aux problèmes de sécurité, car un utilisateur malveillant du cluster peut le charger avec un travail inutile.
Dans le conteneur source, nous avons utilisé un simple appel HTTP pour envoyer la liste des tâches au gestionnaire de tâches. Cela a été fait en supposant que cet appel d'API devait être effectué plusieurs fois, et les problèmes de sécurité n'étaient pas pris en compte, car tout fonctionnait dans le cadre de l'hôte local. L'API de conteneur ne doit être appelée qu'une seule fois et il est important de s'assurer que les autres utilisateurs du système ne peuvent pas ajouter de travail aux exécuteurs, même par accident ou par intention malveillante. Par conséquent, pour le conteneur en cours d'exécution, nous utiliserons l'API de fichier. Lors de la création, nous transmettrons au conteneur une variable d'environnement appelée WORK_ITEM_FILE, dont la valeur fait référence à un fichier dans le système de fichiers interne du conteneur. Ce fichier contient des données sur la tâche à effectuer. Ce type d'API, comme illustré ci-dessous, peut être implémenté par l'objet ConfigMap Kubernetes. Il peut être monté dans un groupe de conteneurs sous forme de fichier (Fig. 10.3).
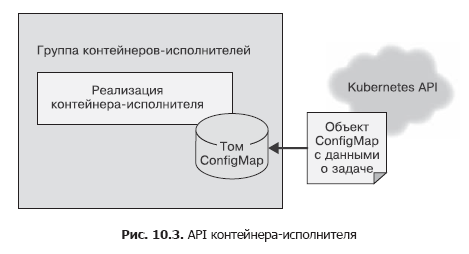
Un tel mécanisme d'API de fichier est plus facile à implémenter à l'aide d'un conteneur. Un exécuteur dans une file d'attente de tâches est souvent un simple script shell qui accède à plusieurs outils. Il n'est pas pratique d'élever un serveur Web entier pour la gestion des tâches - cela entraîne une complication de l'architecture. Comme dans le cas des sources de tâches, la plupart des exécuteurs de conteneurs seront des conteneurs spécialisés pour certaines tâches, mais il existe également des exécuteurs généralisés applicables pour résoudre plusieurs tâches différentes.
Prenons l'exemple d'un conteneur en cours d'exécution qui télécharge un fichier à partir du stockage cloud, exécute un script shell dessus, puis copie le résultat vers le stockage cloud. Un tel conteneur peut être pour la plupart général, mais un scénario spécifique peut lui être transmis en tant que paramètre. Ainsi, la plupart du code de gestion de fichiers peut être réutilisé par de nombreux utilisateurs / files d'attente de tâches. L'utilisateur final n'a qu'à fournir un script contenant les spécificités du traitement des fichiers.
Infrastructure de file d'attente de tâches commune
Que reste-t-il à implémenter dans une implémentation de file d'attente réutilisable si vous avez déjà des implémentations des deux interfaces de conteneur décrites précédemment? L'algorithme de base de la file d'attente des tâches est assez simple.
- Téléchargez les tâches actuellement disponibles à partir du conteneur source.
- Clarifiez le statut de la file d'attente des tâches pour quelles tâches ont déjà été terminées ou sont encore en cours d'exécution.
- Pour chacune des tâches non résolues, créez des conteneurs de conteneurs avec une interface appropriée.
- Une fois le conteneur exécuté avec succès, notez que la tâche est terminée.
Cet algorithme est simple en mots, mais en réalité il n'est pas si facile à mettre en œuvre. Heureusement, l'orchestre Kubernetes possède plusieurs fonctionnalités qui simplifient considérablement sa mise en œuvre. À savoir: Kubernetes possède un objet Job qui garantit un fonctionnement fiable de la file d'attente des tâches. Vous pouvez configurer l'objet Job pour qu'il démarre le conteneur d'exécution correspondant soit une fois, soit jusqu'à ce que la tâche soit terminée avec succès. Si vous configurez le conteneur en cours d'exécution de sorte qu'il s'exécute avant la fin de la tâche, même lorsque la machine du cluster échoue, la tâche sera finalement terminée avec succès.
Ainsi, la mise en file d'attente des tâches est grandement simplifiée, car l'orchestre assume la responsabilité de l'exécution fiable des tâches.
De plus, Kubernetes vous permet d'annoter des tâches, ce qui nous permet de marquer chaque objet de tâche avec le nom de l'élément de file d'attente de tâches traité. Il devient de plus en plus facile de distinguer les tâches qui sont traitées et terminées avec succès et avec une erreur.
Cela signifie que nous pouvons implémenter la file d'attente des tâches au-dessus de l'orchestrateur Kubernetes sans utiliser notre propre référentiel. Tout cela simplifie considérablement la tâche de construction de l'infrastructure de la file d'attente des tâches.
Par conséquent, un algorithme détaillé pour le fonctionnement du conteneur, le gestionnaire de files d'attente de tâches, est le suivant.
Répétez sans cesse.
- Obtenez la liste des tâches via l'interface du conteneur - la source des tâches.
- Obtenez une liste des tâches desservant cette file d'attente de tâches.
- Sur la base de ces listes, sélectionnez une liste de tâches non traitées.
- Pour chaque tâche non traitée, créez un objet Job qui génère le conteneur d'exécution correspondant.
Voici un script Python qui implémente cette file d'attente:
import requests import json from kubernetes import client, config import time namespace = "default" def make_container(item, obj): container = client.V1Container() container.image = "my/worker-image" container.name = "worker" return container def make_job(item): response = requests.get("http://localhost:8000/items/{}".format(item)) obj = json.loads(response.text) job = client.V1Job() job.metadata = client.V1ObjectMeta() job.metadata.name = item job.spec = client.V1JobSpec() job.spec.template = client.V1PodTemplate() job.spec.template.spec = client.V1PodTemplateSpec() job.spec.template.spec.restart_policy = "Never" job.spec.template.spec.containers = [ make_container(item, obj) ] return job def update_queue(batch): response = requests.get("http://localhost:8000/items") obj = json.loads(response.text) items = obj['items'] ret = batch.list_namespaced_job(namespace, watch=False) for item in items: found = False for i in ret.items: if i.metadata.name == item: found = True if not found: # Job, # job = make_job(item) batch.create_namespaced_job(namespace, job) config.load_kube_config() batch = client.BatchV1Api() while True: update_queue(batch) time.sleep(10)
Atelier Implémentation d'un générateur de vignettes pour les fichiers vidéo
Comme exemple d'utilisation de la file d'attente des tâches, considérez la tâche de génération de vignettes de fichiers vidéo. Sur la base de ces miniatures, les utilisateurs décident quelles vidéos ils souhaitent regarder.
Pour implémenter les vignettes, vous avez besoin de deux conteneurs. Le premier concerne la source des tâches. Il sera plus facile de placer des tâches sur un lecteur réseau partagé connecté, par exemple via NFS (Network File System, système de fichiers réseau). La source de la tâche reçoit une liste de fichiers dans ce répertoire et les transmet à l'appelant.
Je vais donner un programme simple sur NodeJS:
const http = require('http'); const fs = require('fs'); const port = 8080; const path = process.env.MEDIA_PATH; const requestHandler = (request, response) => { console.log(request.url); fs.readdir(path + '/*.mp4', (err, items) => { var msg = { 'kind': 'ItemList', 'apiVersion': 'v1', 'items': [] }; if (!items) { return msg; } for (var i = 0; i < items.length; i++) { msg.items.push(items[i]); } response.end(JSON.stringify(msg)); }); } const server = http.createServer(requestHandler); server.listen(port, (err) => { if (err) { return console.log(' ', err); } console.log(` ${port}`) });
Cette source définit la liste des films à traiter. L'utilitaire ffmpeg est utilisé pour extraire les vignettes.
Vous pouvez créer un conteneur qui exécute la commande suivante:
ffmpeg -i ${INPUT_FILE} -frames:v 100 thumb.png
La commande extrait une trame sur 100 (paramètre -frames: v 100) et l'enregistre au format PNG (par exemple, thumb1.png, thumb2.png, etc.).
Ce type de traitement peut être implémenté sur la base de l'image Docker ffmpeg existante. L'
image de jrottenberg / ffmpeg est populaire.
En définissant un conteneur source simple et un conteneur d'exécution encore plus simple, il est facile de voir les avantages d'un système de gestion de file d'attente générique et orienté conteneur. Il réduit considérablement le temps entre la conception et la mise en œuvre de la file d'attente des tâches.
Mise à l'échelle dynamique des artistes
La file d'attente des tâches considérée précédemment est bien adaptée au traitement des tâches au fur et à mesure qu'elles deviennent disponibles, mais peut entraîner une charge brutale sur les ressources de l'orchestrateur de cluster de conteneurs. Cela est utile lorsque vous avez de nombreux types de tâches différents qui créent des pics de charge à des moments différents et répartissent ainsi la charge sur le cluster de manière uniforme dans le temps.
Mais si vous n'avez pas assez de types de charge, l'approche «puis épaisse, puis vide» pour faire évoluer la file d'attente des tâches peut nécessiter la réservation de ressources supplémentaires pour prendre en charge les rafales de charge. Le reste du temps, les ressources seront inactives, vidant inutilement votre portefeuille.
Pour résoudre ce problème, vous pouvez limiter le nombre total d'objets Job générés par la file d'attente des tâches. Cela limitera naturellement le nombre de travaux traités en parallèle et, par conséquent, réduira l'utilisation des ressources lors des pics de charge. En revanche, la durée de chaque tâche individuelle augmentera avec une charge élevée sur le cluster.
Si la charge est spasmodique, ce n'est pas effrayant, car les intervalles de temps d'arrêt peuvent être utilisés pour terminer les tâches accumulées. Cependant, si la charge constante est trop élevée, la file d'attente des tâches n'aura pas le temps de traiter les tâches entrantes et de plus en plus de temps sera consacré à leur mise en œuvre.
Dans une telle situation, vous devrez ajuster dynamiquement le nombre maximal de tâches parallèles et, par conséquent, les ressources informatiques disponibles pour maintenir le niveau de performances requis. Heureusement, il existe des formules mathématiques qui vous permettent de déterminer quand il est nécessaire de mettre à l'échelle la file d'attente des tâches pour traiter plus de demandes.
Imaginez une file d'attente de tâches dans laquelle une nouvelle tâche apparaît en moyenne une fois par minute et son achèvement prend en moyenne 30 secondes. Une telle file d'attente est capable de faire face au flux de tâches qui y pénètrent. Même si un grand ensemble de tâches arrive à la fois, créant un embouteillage, alors l'embouteillage sera éliminé au fil du temps, car la file d'attente parvient à traiter deux tâches en moyenne avant l'arrivée de la tâche suivante.
Si une nouvelle tâche arrive toutes les minutes et qu'il faut en moyenne 1 minute pour traiter une tâche, alors un tel système est parfaitement équilibré, mais en même temps réagit mal aux changements de la charge. Elle est capable de faire face à des éclats de charge, mais cela lui prendra beaucoup de temps. Le système ne sera pas inactif, mais il n'y aura pas de réserve de temps informatique pour compenser l'augmentation à long terme de la vitesse de réception des nouvelles tâches. Pour maintenir la stabilité du système, il est nécessaire d'avoir une réserve en cas de croissance de charge à long terme ou de retards imprévus dans les tâches de traitement.
Enfin, considérons un système dans lequel une tâche par minute arrive et le traitement des tâches prend deux minutes. Un tel système perdra constamment ses performances. La longueur de la file d'attente des tâches augmentera avec le délai entre la réception et le traitement des tâches (et le degré de gêne des utilisateurs).
Les valeurs de ces deux indicateurs doivent être surveillées en permanence. En faisant la moyenne du temps entre la réception des tâches pendant une longue période de temps, par exemple, sur la base du nombre de tâches par jour, nous obtenons une estimation de l'intervalle entre les tâches. Il est également nécessaire de surveiller le temps de traitement moyen de la tâche (hors temps passé dans la file d'attente). Dans une file d'attente de tâches stable, le temps de traitement moyen des tâches doit être inférieur à l'intervalle entre les tâches. Pour garantir que cette condition est remplie, il est nécessaire d'ajuster dynamiquement le nombre de files d'attente disponibles de ressources informatiques. Si les travaux sont traités en parallèle, le temps de traitement doit être divisé par le nombre de travaux traités en parallèle. Par exemple, si une tâche est traitée par minute, mais que quatre tâches sont traitées en parallèle, le temps de traitement effectif d'une tâche est de 15 secondes, ce qui signifie que l'intervalle entre les tâches doit être d'au moins 16 secondes.
Cette approche vous permet de créer facilement un module pour faire évoluer la file d'attente des tâches vers le haut. La réduction d'échelle est un peu plus problématique. Néanmoins, il est possible d'utiliser les mêmes calculs que précédemment, en posant en plus la réserve de ressources informatiques déterminée par la voie heuristique. Par exemple, vous pouvez réduire le nombre de tâches parallèles jusqu'à ce que le temps de traitement pour une tâche soit de 90% de l'intervalle entre les tâches.
Modèle multi-travailleurs
L'un des principaux sujets de ce livre est l'utilisation de conteneurs pour encapsuler et réutiliser le code. Il est également pertinent pour les modèles de mise en file d'attente des tâches décrits dans ce chapitre. En plus des conteneurs qui gèrent la file d'attente elle-même, vous pouvez réutiliser des groupes de conteneurs qui composent l'implémentation des acteurs. Supposons que vous ayez besoin de traiter chaque tâche d'une file d'attente de trois manières différentes. Par exemple, pour détecter des visages sur une photo, associez-les à des personnes spécifiques, puis brouillez les parties correspondantes de l'image. Vous pouvez placer tous les traitements dans un seul conteneur d'exécution, mais il s'agit d'une solution unique qui ne peut pas être réutilisée. Pour couvrir autre chose, comme des voitures, sur la photo, vous devrez créer un artiste conteneur à partir de zéro.
La possibilité de ce type de réutilisation peut être obtenue en appliquant le modèle Multi-Worker, qui est en fait un cas spécial du modèle Adapter décrit au début du livre. Le modèle Multi-Worker convertit un ensemble de conteneurs en un conteneur commun avec l'interface logicielle du conteneur en cours d'exécution. Ce conteneur partagé délègue le traitement à plusieurs conteneurs réutilisables distincts. Ce processus est schématisé sur la Fig. 10.4.
En réutilisant le code en combinant des conteneurs d'exécution, le travail des personnes qui conçoivent des systèmes de traitement par lots distribués est réduit.
»Plus d'informations sur le livre sont disponibles sur
le site Web de l'éditeur»
Contenu»
ExtraitPour habrozhitelami 20% de réduction sur le coupon -
Systèmes distribués .