Le matériel et les compilateurs modernes sont prêts à bouleverser notre code, si seulement cela fonctionne plus rapidement. Et leurs fabricants cachent soigneusement leur cuisine intérieure. Et tout va bien tant que le code est exécuté dans un seul thread.
Dans un environnement multi-thread, vous pouvez forcément observer des choses intéressantes. Par exemple, l'exécution des instructions de programme n'est pas dans l'ordre qui est écrit dans le code source. D'accord, il est désagréable de réaliser que l'exécution du code source ligne par ligne n'est que notre imagination.
Mais tout le monde s'est déjà rendu compte, car il faut en quelque sorte vivre avec. Et les programmeurs Java vivent même bien. Parce que Java a un modèle de mémoire - le modèle de mémoire Java (JMM), qui fournit des règles assez simples pour écrire le code multithread correct.
Et ces règles sont suffisantes pour la plupart des programmes. Si vous ne les connaissez pas, mais que vous écrivez ou souhaitez écrire des programmes multithreads en Java, il est préférable de vous familiariser avec
eux dès que possible. Et si vous le savez, mais que vous n'avez pas assez de contexte ou qu'il est intéressant de savoir d'où viennent les jambes de JMM, cet article peut vous aider.
Et chasser l'abstraction
À mon avis, il y a une tarte, ou, mieux, un iceberg. JMM est la pointe de l'iceberg. L'iceberg lui-même est une théorie de la programmation multi-thread sous l'eau. Sous l'iceberg est l'enfer.

Un iceberg est une abstraction; s'il fuit, nous verrons certainement l'enfer. Bien que beaucoup de choses intéressantes se produisent là-bas, dans l'article de revue, nous n'y arriverons pas.
Dans l'article, je m'intéresse plus aux sujets suivants:
- Théorie et terminologie
- Comment la théorie de la programmation multithread se reflète-t-elle dans JMM
- Modèles de programmation compétitifs
La théorie de la programmation multi-thread vous permet de vous éloigner de la complexité des processeurs et compilateurs modernes, elle vous permet de simuler l'exécution de programmes multi-thread et d'étudier leurs propriétés. Roman Elizarov a fait un excellent
rapport , dont le but est de fournir une base théorique pour comprendre JMM. Je recommande le rapport à tous ceux qui s'intéressent à ce sujet.
Pourquoi est-il important de connaître la théorie? À mon avis, j'espère que pour le mien, certains programmeurs ont une opinion que JMM est une complication du langage et des correctifs de certains problèmes de plate-forme avec le multithreading. La théorie montre que Java n'a pas compliqué, mais simplifié et rendu plus prévisible une programmation multithread très complexe.
Concurrence et concurrence
Voyons d'abord la terminologie. Malheureusement, il n'y a pas de consensus dans la terminologie - lorsque vous étudiez différents matériaux, vous pouvez rencontrer différentes définitions de la concurrence et de la concurrence.
Le problème est que même si nous allons au fond de la vérité et trouvons les définitions exactes de ces concepts, cela ne vaut pas la peine d'attendre que tout le monde signifiera la même chose avec ces concepts. Vous ne
trouverez pas
les fins ici.
Roman Elizarov, dans un rapport, la théorie de la programmation parallèle pour les praticiens suggère que parfois ces concepts sont mélangés. La programmation parallèle se distingue parfois comme un concept général divisé en compétitif et distribué.
Il me semble que dans le contexte de JMM, il faut encore séparer compétition et parallélisme, ou plutôt comprendre qu'il existe deux paradigmes différents, quel que soit leur nom.
Souvent cité par Rob Pike, qui distingue les concepts comme suit:
- La concurrence est un moyen de résoudre simultanément de nombreux problèmes
- La concurrence est un moyen d'exécuter différentes parties d'une même tâche.
L'opinion de Rob Pike n'est pas une norme, mais à mon avis, il est commode de s'en inspirer pour approfondir la question. En savoir plus sur les différences
ici .
Très probablement, une meilleure compréhension de la question apparaîtra si nous mettons en évidence les principales caractéristiques d'un programme concurrentiel et parallèle. Il y a beaucoup de signes, considérez les plus importants.
Signes de compétition.
- La présence de plusieurs flux de contrôle (par exemple, Thread en Java, coroutine dans Kotlin), s'il n'y a qu'un seul flux de contrôle, il ne peut y avoir aucune exécution compétitive
- Résultat non déterministe. Le résultat dépend des événements aléatoires, de l'implémentation et de la manière dont la synchronisation a été effectuée. Même si chaque flux est complètement déterministe, le résultat final sera non déterministe
Un programme parallèle aura un ensemble différent de fonctionnalités.
- Facultatif a plusieurs flux de contrôle
- Cela peut conduire à un résultat déterministe, par exemple, le résultat de la multiplication de chaque élément du tableau par un nombre ne changera pas si vous le multipliez en plusieurs parties en parallèle
Curieusement, l'exécution parallèle est possible sur un seul flux de contrôle, et même sur une architecture monocœur. Le fait est que le parallélisme au niveau des tâches (ou des flux de contrôle) auquel nous sommes habitués n'est pas le seul moyen d'effectuer des calculs en parallèle.
La concurrence est possible au niveau de:
- bits (par exemple, sur les machines 32 bits, l'addition a lieu en une seule action, en traitant les 4 octets d'un nombre 32 bits en parallèle)
- instructions (sur un cœur, dans un thread, le processeur peut exécuter des instructions en parallèle, malgré le fait que le code soit séquentiel)
- données (il existe des architectures avec traitement parallèle des données (Single Instruction Multiple Data) qui peuvent exécuter une instruction sur un grand ensemble de données)
- tâches (implique la présence de plusieurs processeurs ou cœurs)
La concurrence au niveau de l'instruction est un exemple d'optimisations qui se produisent avec l'exécution de code qui sont cachées au programmeur.
Il est garanti que le code optimisé sera équivalent à l'original dans le cadre d'un thread, car il est impossible d'écrire du code adéquat et prévisible s'il ne fait pas ce que le programmeur avait prévu.
Tout ce qui fonctionne en parallèle n'a pas d'importance pour JMM. L'exécution simultanée au niveau de l'instruction dans un seul thread n'est pas prise en compte dans JMM.
La terminologie est très fragile, avec une présentation de Roman Elizarov intitulée «Théorie de la programmation
parallèle pour les praticiens», bien qu'il y ait plus sur la programmation compétitive, si vous vous en tenez à ce qui précède.
Dans le contexte de JMM, dans l'article, je m'en tiendrai au terme de concurrence, car la concurrence concerne souvent l'état général. Mais ici, vous devez faire attention à ne pas vous accrocher aux termes, mais à comprendre qu'il existe différents paradigmes.
Modèles avec un état commun: «rotation des opérations» et «arrivé avant»
Dans son
article, Maurice Herlichi (auteur de la programmation The Art Of Multiprocessor) écrit qu'un système concurrentiel contient une collection de processus séquentiels (dans les travaux théoriques, cela signifie la même chose qu'un fil) qui communiquent via la mémoire partagée.
Le modèle d'état général comprend des calculs avec messagerie, où l'état partagé est une file d'attente de messages et des calculs avec mémoire partagée, où l'état commun sont des structures en mémoire.
Chacun des calculs peut être simulé.
Le modèle est basé sur une machine à états finis. Le modèle se concentre exclusivement sur l'état partagé et les données locales de chacun des flux sont complètement ignorées. Chaque action de flux sur un état partagé est fonction de la transition vers un nouvel état.
Ainsi, par exemple, si 4 threads écrivent des données dans une variable partagée, alors il y aura 4 fonctions pour la transition vers un nouvel état. Laquelle de ces fonctions sera appliquée dépend de la chronologie des événements dans le système.
Les calculs de passage de messages sont modélisés de manière similaire, seules les fonctions d'état et de transition dépendent de l'envoi ou de la réception de messages.
Si le modèle vous a semblé compliqué, alors dans l'exemple, nous le corrigerons. C'est vraiment très simple et intuitif. À tel point que sans connaître l'existence de ce modèle, la plupart des gens continueront d'analyser le programme comme le suggère le modèle.
Un tel modèle est appelé modèle de
performance par l'alternance des opérations (le nom a été entendu dans un rapport de Roman Elizarov).
Dans l'intuitivité et le naturel, vous pouvez écrire en toute sécurité les avantages du modèle. Vous pouvez entrer dans la nature avec les mots-clés
cohérence séquentielle et le
travail de Leslie Lamport.
Cependant, il existe une clarification importante sur ce modèle. Le modèle a la limitation que toutes les actions sur un état partagé doivent être instantanées et en même temps, les actions ne peuvent pas se produire simultanément. Ils disent qu'un tel système a un
ordre linéaire - toutes les actions du système sont ordonnées.
En pratique, cela ne se produit pas. L'opération ne se produit pas instantanément, mais est effectuée dans un intervalle; sur les systèmes multicœurs, ces intervalles peuvent se croiser. Bien sûr, cela ne signifie pas que le modèle est inutile dans la pratique, il vous suffit de créer certaines conditions pour son utilisation.
En attendant, considérons un autre
modèle - «arrivé avant», qui ne se concentre pas sur l'état, mais sur l'ensemble des cellules de mémoire en lecture et en écriture pendant l'exécution (historique) et leurs relations.
Le modèle dit que les événements dans différents flux ne sont pas instantanés et atomiques, mais en parallèle, et il n'est pas possible de créer de l'ordre entre eux. Les événements (écriture et lecture de données partagées) dans des flux sur une architecture multiprocesseur ou multicœur se produisent vraiment en parallèle. Il n'y a pas de notion d'heure globale dans le système, nous ne pouvons pas comprendre quand une opération s'est terminée et une autre a commencé.
En pratique, cela signifie que nous pouvons écrire une valeur dans une variable dans un thread et le faire, disons le matin, et lire la valeur de cette variable dans un autre thread le soir, et nous ne pouvons pas dire que nous lirons la valeur écrite le matin avec certitude. En théorie, ces opérations se déroulent en parallèle et on ne sait pas quand l'une se terminera et une autre commencera.
Il est difficile d'imaginer comment il s'avère que de simples opérations de lecture et d'écriture effectuées à différents moments de la journée se déroulent simultanément. Mais si vous y réfléchissez, cela n'a pas vraiment d'importance pour nous lorsque les événements d'écriture et de lecture se produisent, si nous ne pouvons garantir que nous verrons le résultat de l'enregistrement.
Et nous ne pouvons vraiment pas voir le résultat de l'enregistrement, c'est-à-dire dans une variable dont la valeur est
0 dans le flux
P, nous écrivons
1 , et dans le flux
Q nous lisons cette variable. Peu importe combien de temps physique passe après l'enregistrement, nous pouvons toujours lire
0 .
C'est ainsi que les ordinateurs fonctionnent et le modèle le reflète.Le modèle est complètement abstrait et nécessite une visualisation pratique pour un travail pratique. Pour la visualisation et uniquement pour cela, un modèle avec le temps global est utilisé, avec des réserves que pour prouver les propriétés des programmes, le temps global n'est pas utilisé. En visualisation, chaque événement est représenté comme un intervalle avec un début et une fin.
Les événements se déroulent en parallèle, comme nous l'avons découvert. Mais quand même, le système a un
ordre partiel , car il y a des paires spéciales d'événements qui ont un ordre, auquel cas ils disent que ces événements ont une relation «arrivé avant». Si vous entendez d'abord parler de la relation «qui s'est produite avant», sachant probablement que cette relation organise en quelque sorte des événements ne vous sera pas d'une grande utilité.
Essayer d'analyser un programme Java
Nous avons considéré un minimum théorique, essayons d'avancer et considérons un programme multi-thread dans un langage spécifique - Java, à partir de deux threads avec un état mutable commun.
Un exemple classique.
private static int x = 0, y = 0; private static int a = 0, b = 0; synchronized (this) { a = 0; b = 0; x = 0; y = 0; } Thread p = new Thread(() -> { a = 1; x = b; }); Thread q = new Thread(() -> { b = 1; y = a; }); p.start(); q.start(); p.join(); q.join(); System.out.println("x=" + x + ", y=" + y);
Nous devons simuler l'exécution de ce programme et obtenir tous les résultats possibles - les valeurs des variables x et y. Il y aura plusieurs résultats, comme nous le rappelons de la théorie, un tel programme n'est pas déterministe.
Comment allons-nous modéliser? Je veux immédiatement utiliser le modèle d'opérations entrelacées. Mais le modèle «arrivé avant» nous dit que les événements d'un thread sont parallèles aux événements d'un autre thread. Par conséquent, le modèle d'opérations alternées ici n'est pas approprié s'il n'y a pas de relation «antérieure à» entre les opérations.
Le résultat de l'exécution de chaque thread est toujours déterminé, puisque les événements dans un thread sont toujours ordonnés, considérez qu'ils reçoivent gratuitement une relation «arrivé avant». Mais comment les événements dans différents flux peuvent obtenir la relation «qui s'est produite avant» n'est pas entièrement évident. Bien sûr, cette relation est formalisée dans le modèle, l'ensemble du modèle est écrit en langage mathématique. Mais que faire de cela dans la pratique, dans une langue particulière, n'est pas immédiatement compris.
Quelles sont les options?
Ignorez les contraintes et simulez l'entrelacement. Vous pouvez l'essayer, peut-être qu'il ne se passera rien de mal.
Pour comprendre quel type de résultats peut être obtenu, nous énumérons simplement toutes les variantes possibles d'exécution.
Toutes les exécutions de programme possibles peuvent être représentées comme une machine à états finis.
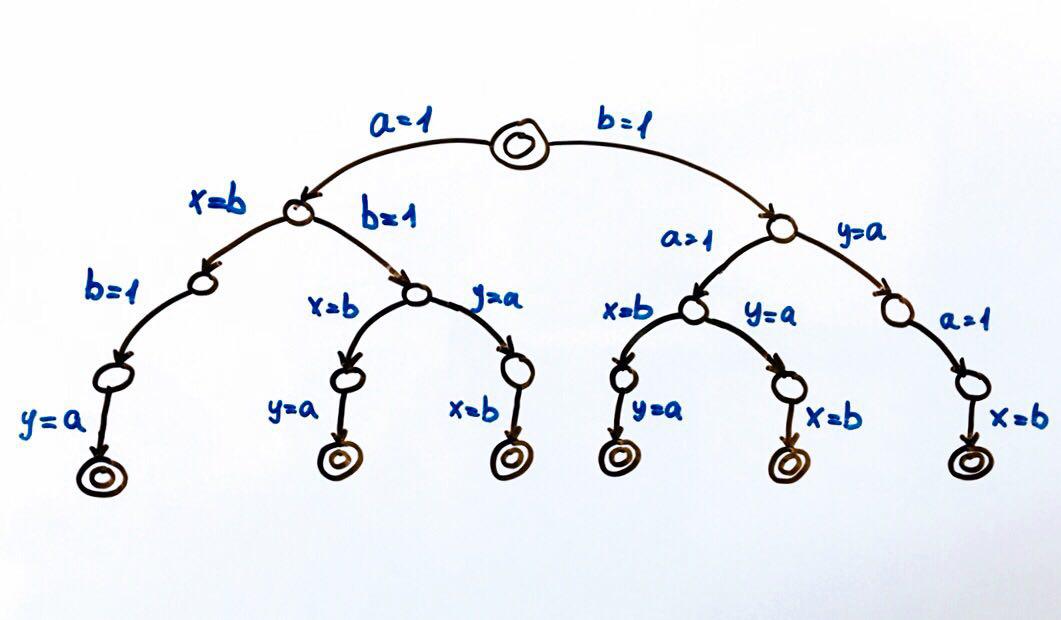
Chaque cercle est un état du système, dans notre cas les variables
a, b, x, y . Une fonction de transition est une action sur un état qui met le système dans un nouvel état. Étant donné que deux flux peuvent effectuer des actions sur l'état général, il y aura deux transitions à partir de chaque état. Les cercles doubles sont les états final et initial du système.
Au total, 6 exécutions différentes sont possibles, ce qui donne des paires de valeurs x, y:
(1, 1), (1, 0), (0, 1)
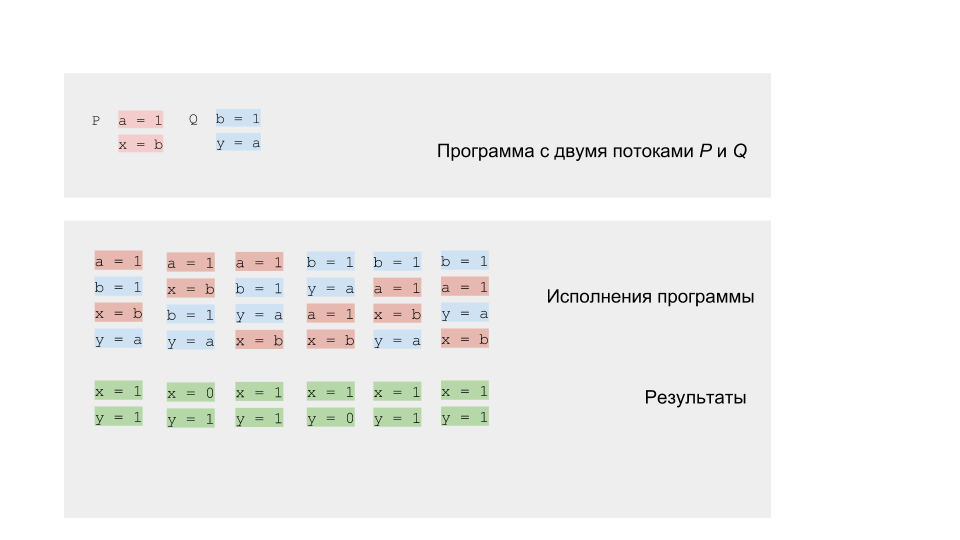
Nous pouvons exécuter le programme et vérifier les résultats. Comme il sied à un programme compétitif, il aura un résultat non déterministe.
Pour tester des programmes compétitifs, il est préférable d'utiliser des outils spéciaux (
outil ,
rapport ).
Mais vous pouvez essayer d'exécuter le programme plusieurs millions de fois, ou mieux encore, écrire un cycle qui le fera pour nous.
Si nous exécutons le code sur une architecture à cœur unique ou à processeur unique, nous devrions obtenir le résultat de l'ensemble que nous attendons. Le modèle de rotation fonctionnera très bien. Sur une architecture multicœur, par exemple x86, nous pouvons être surpris par le résultat - nous pouvons obtenir le résultat (0,0), qui ne peut pas être conforme à notre modélisation.
L'explication peut être trouvée sur Internet par le mot-clé -
réorganisation . Maintenant, il est important de comprendre que la
modélisation d'entrelacement n'est vraiment pas appropriée dans une situation où nous ne pouvons pas déterminer l'ordre d'accès à l'état partagé .
Théorie de la programmation compétitive et JMM
Il est temps de regarder de plus près la relation «qui s'est produite avant» et comment elle se lie d'amitié avec JMM. La définition originale de la relation «arrivé avant» se trouve dans Time, Clocks et Ordering of Events in a Distributed System.
Le modèle de mémoire de langage aide à écrire du code compétitif, car il détermine quelles opérations sont liées à «déjà eu lieu». Une liste de ces opérations est présentée dans la
spécification dans la section Ordre des commandes antérieures. En fait, cette section répond à la question - dans quelles conditions verrons-nous le résultat de l'enregistrement dans un autre flux.
Il existe différentes commandes dans JMM. Alexei Shipilev parle très vigoureusement des règles dans l'un de ses
rapports .
Dans le modèle de temps global, toutes les opérations dans le même thread sont en ordre. Par exemple, les événements d'écriture et de lecture d'une variable peuvent être représentés comme deux intervalles, puis le modèle garantit que ces intervalles ne se recouperont jamais dans le cadre d'un seul flux. Dans JMM, cette commande est appelée commande de programme (
PO ).
PO lie les actions dans un seul thread et ne dit rien sur l'ordre d'exécution, il ne parle que de l'ordre dans le code source. C'est tout à fait suffisant pour garantir le
déterminisme pour chaque flux séparément .
Les bons de commande peuvent être considérés comme des données brutes.
PO est toujours facile à organiser dans un programme - toutes les opérations (ordre linéaire) dans le code source dans un seul flux auront
PO .
Dans notre exemple, nous obtenons quelque chose comme ceci:
P: a = 1 PO x = b - écrire dans a et lire b a un ordre PO
Q: b = 1 PO y = a - écrire dans b et lire un ordre a PO
J'ai espionné cette forme d'écriture
w (a, 1) PO r (b): 0. J'espère vraiment que personne ne l'a breveté pour les rapports. Cependant, la spécification a une forme similaire.
Mais chaque thread individuellement n'est pas particulièrement intéressant pour nous, puisque les threads ont un état commun, nous sommes plus intéressés par l'interaction des flux. Tout ce que nous voulons, c'est être sûr que nous verrons un enregistrement des variables dans d'autres threads.
Permettez-moi de vous rappeler que cela n'a pas fonctionné pour nous, car les opérations d'écriture et de lecture de variables dans différents flux ne sont pas instantanées (ce sont des segments qui se croisent), respectivement, il est impossible d'analyser où se trouvent le début et la fin des opérations.
L'idée est simple - au moment où nous lisons la variable a dans le flux
Q , l'enregistrement de cette même variable dans le flux
P n'est peut-être pas encore terminé. Et peu importe le temps physique que ces événements partagent - une nanoseconde ou quelques heures.
Pour commander des événements, nous avons besoin de la relation «arrivé avant». JMM définit cette relation. La spécification fixe l'ordre dans un thread:
Si l'opération x et y sont dans le même thread et dans PO x se produit d'abord, puis y, alors x s'est produit avant y.
Pour l'avenir, nous pouvons dire que nous pouvons remplacer tous les
bons de commande par Happens-before (
HB ):
P: w(a, 1) HB r(b) Q: w(b, 1) HB r(a)
Mais encore une fois, nous revenons dans le cadre d'un flux.
HB est possible entre des opérations se produisant dans différents threads, pour traiter ces cas, nous nous familiariserons avec d'autres commandes.
Ordre de synchronisation (
SO ) - relie les actions de synchronisation (
SA ), une liste complète des
SA est donnée dans la spécification, à la section 17.4.2. Actions En voici quelques uns:
- Lecture d'une variable volatile
- Écriture d'une variable volatile
- Verrouillage du moniteur
- Déverrouiller le moniteur
SO est intéressant pour nous, car il a la propriété que toutes les lectures dans l'ordre
SO voient les dernières entrées dans
SO . Et je vous rappelle que nous ne faisons que cela.
À cet endroit, je répéterai ce que nous recherchons. Nous avons un programme multithread, nous voulons simuler toutes les exécutions possibles et obtenir tous les résultats qu'il peut donner. Il existe des modèles qui permettent de le faire tout simplement. Mais ils exigent que toutes les actions sur l'état partagé soient ordonnées.
Selon la propriété
SO - si toutes les actions du programme sont
SA, nous atteindrons notre objectif. C'est-à-dire nous pouvons définir un
modificateur volatile pour toutes les variables et nous pouvons utiliser un modèle d'alternance. Si l'intuition vous dit que cela n'en vaut pas la peine, alors vous avez absolument raison. Avec ces actions, nous interdisons simplement les optimisations sur le code, bien sûr, parfois c'est une bonne option, mais ce n'est certainement pas un cas général.
Considérons une autre commande Synchronizes-With Order (
SW ) - SO pour des paires spécifiques de déverrouillage / verrouillage, d'écriture / lecture volatiles. Peu importe le flux de ces actions, l'essentiel est qu'elles soient sur le même moniteur, variable volatile.
SW fournit un pont entre les threads.
Et maintenant, nous arrivons à l'ordre le plus intéressant - Happens-before (
HB ).
HB est une fermeture transitive de l'union de
SW et
PO .
PO donne un ordre linéaire dans le flux, et
SW fournit un pont entre les flux.
HB est transitif, c'est-à-dire si
x HB y y HB z, x HB z
La spécification a une liste de relations
HB , vous pouvez vous familiariser avec elle plus en détail, voici une partie de la liste:
Dans un seul thread, toute opération se produit avant par toute opération qui la suit dans le code source.
La sortie d'un bloc / d'une méthode synchronisée se produit avant d'entrer un bloc / une méthode synchronisée sur le même moniteur.
L'écriture d'un champ
volatile se produit avant de lire le même champ
volatile .
Revenons à notre exemple:
P: a = 1 PO x = b Q: b = 1 PO y = a
Revenons à notre exemple et essayons d'analyser le programme en tenant compte des commandes.
L'analyse du programme à l'aide de JMM est basée sur la proposition d'hypothèses et leur confirmation ou réfutation.
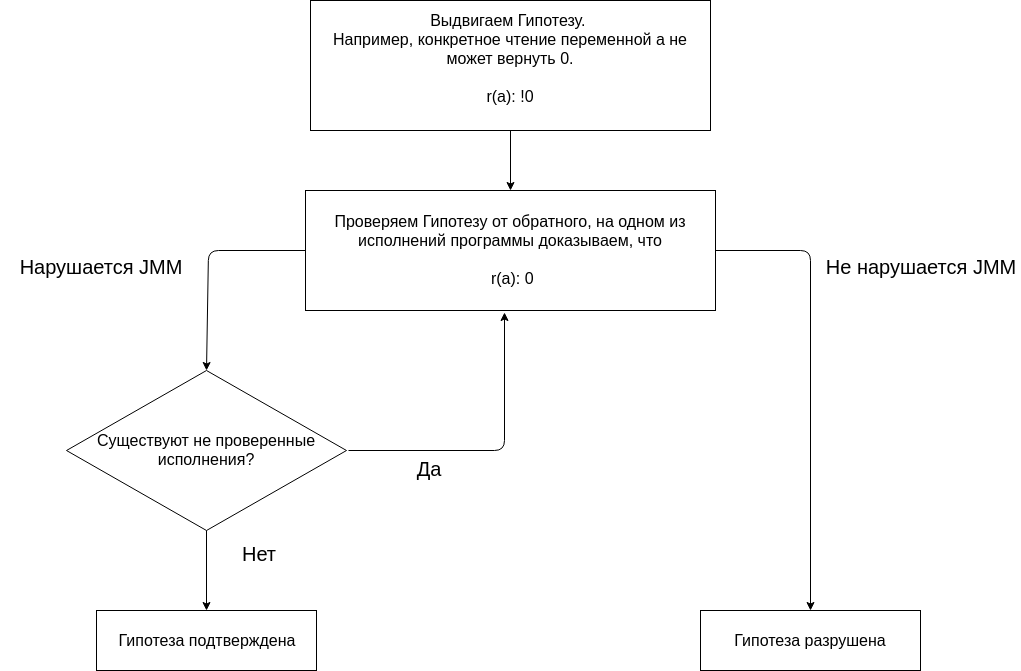
Nous commençons notre analyse avec l'hypothèse que pas une seule exécution de programme ne donne le résultat (0, 0). L'absence de résultat (0, 0) sur toutes les exécutions est une propriété supposée du programme.
Nous testons l'hypothèse en construisant différentes exécutions.
J'ai repéré la nomenclature
ici (parfois il apparaît au lieu de
… mot
race avec une flèche, Alexey lui-même utilise la flèche et le mot race dans ses rapports, mais avertit que cet ordre n'existe pas dans JMM et utilise cette notation pour plus de clarté).
Nous faisons une petite réservation.
Puisque toutes les actions sur des variables communes sont importantes pour nous, et dans l'exemple, les variables communes sont
a, b, x, y . Ensuite, par exemple, l'opération x = b doit être considérée comme r (b) et w (x, b), et
r(b) HB w(x,b) (basé sur
PO ). Mais comme la variable x n'est lue nulle part dans les threads (la lecture imprimée à la fin du code n'est pas intéressante, car après l'opération de jointure sur le thread nous verrons la valeur x), nous ne pouvons pas considérer l'action w (x, b).
Vérifiez la première représentation.
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0
Dans le flux
Q, on lit la variable a, on écrit sur cette variable dans le flux
P. Il n'y a pas d'ordre entre l'écriture et la lecture
(PO, SW, HB) .
Si la variable est écrite dans un thread et que la lecture est dans un autre thread et qu'il n'y a pas de relation
HB entre les opérations, alors ils disent que la variable est lue sous la race. Et selon la course selon JMM, nous pouvons lire soit la dernière valeur enregistrée dans
HB , soit toute autre valeur.
Une telle performance est possible. L'exécution
ne viole pas JMM . Lors de la lecture de la variable a, vous pouvez voir n'importe quelle valeur, car la lecture a lieu sous la course et il n'y a aucune garantie que nous verrons l'action w (a, 1). Cela ne signifie pas que le programme fonctionne correctement, cela signifie simplement qu'un tel résultat est attendu.
Cela n'a aucun sens de considérer le reste de l'exécution, car l'
hypothèse est déjà détruite .
JMM dit que si le programme n'a pas de race de données, toutes les exécutions peuvent être considérées comme séquentielles. Débarrassons-nous de la course, pour cela, nous devons rationaliser les opérations de lecture et d'écriture dans différents threads. Il est important de comprendre qu'un programme multithread, contrairement à un programme séquentiel, a plusieurs exécutions. Et pour dire qu'un programme a une propriété, il est nécessaire de prouver que le programme a cette propriété non pas sur l'une des exécutions, mais sur toutes les exécutions.
Pour prouver que le programme n'est pas une course, vous devez le faire pour toutes les performances. Essayons de créer
SA et marquons la variable a avec un
modificateur volatile .
Les variables
volatiles seront préfixées par v.
Nous proposons
une nouvelle hypothèse . Si la variable a est rendue
volatile , alors aucune exécution du programme ne donnera le résultat (0, 0).
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0
L'exécution
ne viole pas JMM . La lecture va se passe sous la course. Toute race détruit la transitivité de HB.
Nous proposons
une autre hypothèse . Si la variable b est rendue
volatile , aucune exécution du programme ne donnera le résultat (0, 0).
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0
L'exécution ne viole pas JMM. La lecture d'un a lieu sous la course.
Testons
l'hypothèse que si les variables a et b sont
volatiles , alors aucune exécution de programme ne donnera le résultat (0, 0).
Vérifiez la première représentation.
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0
Puisque toutes les actions du programme
SA (en particulier la lecture ou l'écriture d'une variable
volatile ), nous obtenons l'ordre
SO complet entre toutes les actions. Cela signifie que r (va) devrait voir w (va, 1). Cette
exécution viole JMM .
Il est nécessaire de procéder à la prochaine exécution afin de confirmer l'hypothèse. Mais comme il y aura
SO pour toute exécution, vous pouvez dévier du formalisme - il est évident que le résultat (0, 0) viole le JMM pour toute exécution.
Pour utiliser le modèle de rotation, vous devez ajouter
volatile pour les variables a et b. Un tel programme donnera les résultats (1,1), (1,0) ou (0,1).
Au final, on peut dire que des programmes très simples sont assez simples à analyser.
Mais les programmes complexes avec un grand nombre d'exécutions et de données partagées sont difficiles à analyser, car vous devez vérifier toutes les exécutions.
Autres modèles d'exécution compétitifs
Pourquoi envisager d'autres modèles de programmation compétitifs?
L'utilisation de threads et de primitives de synchronisation peut résoudre tous les problèmes. Tout cela est vrai, mais le problème est que nous avons examiné un exemple d'une douzaine de lignes de code, où 4 lignes de code font un travail utile.
Et là, nous avons rencontré un tas de questions, au point que sans la spécification, nous ne pourrions même pas calculer correctement tous les résultats possibles. Les threads et les primitives de synchronisation sont une chose très difficile, dont l'utilisation est certainement justifiée dans certains cas. Fondamentalement, ces cas sont liés aux performances.
Désolé, je me réfère beaucoup à Elizarov, mais que puis-je faire si une personne a vraiment de l'expérience dans ce domaine. Donc, il a un autre
rapport merveilleux
, "Des millions de citations par seconde en Java pur", dans lequel il dit qu'un état immuable est bon, mais je ne copierai pas mes millions de citations dans chaque flux, désolé. Mais tous n'ont pas des millions de citations, beaucoup ont bien sûr des tâches plus modestes. Existe-t-il des modèles de programmation compétitifs qui vous permettent d'oublier JMM tout en écrivant du code sûr et compétitif?
Si vous êtes vraiment intéressé par cette question, je recommande fortement le livre de Paul Butcher, «Seven Models of Competition in Seven Weeks. Nous dévoilons les secrets des flux. ” Malheureusement, il n'a pas été possible de trouver suffisamment d'informations sur l'auteur, mais le livre devrait vous ouvrir les yeux sur de nouveaux paradigmes. Malheureusement, je n'ai pas d'expérience avec de nombreux autres modèles de compétition, j'ai donc reçu la critique de ce livre.
Répondre à la question ci-dessus. À ma connaissance, il existe des modèles de programmation compétitifs qui peuvent au moins réduire considérablement le besoin de connaître les nuances de JMM. Cependant, s'il y a un état et des flux mutables, ne visser aucune abstraction dessus, il y aura toujours un endroit où ces flux devraient synchroniser l'accès à l'état. Une autre question est que vous n'avez probablement pas à synchroniser l'accès vous-même, par exemple, un framework peut répondre à cela. Mais comme nous l'avons dit, tôt ou tard, l'abstraction peut se produire.
Vous pouvez exclure tout état mutable. Dans le monde de la programmation fonctionnelle, c'est une pratique normale. S'il n'y a pas de structures mutables, alors il n'y aura probablement pas de problèmes avec la mémoire partagée par définition. Il existe des représentants de langages fonctionnels sur la machine virtuelle Java, tels que Clojure. Clojure est un langage fonctionnel hybride, car il vous permet toujours de modifier les structures de données, mais fournit des outils plus efficaces et plus sûrs pour cela.
Les langages fonctionnels sont un excellent outil pour travailler avec du code concurrentiel. Personnellement, je ne l'utilise pas, car mon domaine d'activité est le développement mobile, et là, il n'est tout simplement pas courant. Bien que certaines approches puissent être adoptées.
Une autre façon de travailler avec des données mutables est d'empêcher le partage de données. Les acteurs sont un tel modèle de programmation. Les acteurs simplifient la programmation en ne permettant pas l'accès simultané aux données. Ceci est réalisé par le fait qu'une fonction qui effectue un travail à un moment donné peut fonctionner dans un seul thread.
Cependant, un acteur peut changer l'état interne. Étant donné qu'à l'instant suivant, le même acteur peut être exécuté sur un autre thread, cela peut être un problème. Le problème peut être résolu de différentes manières, dans des langages de programmation tels que Erlang ou Elixir, où le modèle d'acteur fait partie intégrante du langage, vous pouvez utiliser la récursivité pour appeler un acteur avec un nouvel état.
À Java, les récursions peuvent être trop chères. Cependant, en Java, il existe des cadres pour un travail pratique avec ce modèle, probablement le plus populaire est Akka. Les développeurs d'Akka se sont occupés de tout, vous pouvez aller à la section de documentation d'
Akka et du modèle de mémoire Java et lire deux cas où l'accès à un état partagé peut se produire à partir de différents threads. Mais plus important encore, la documentation indique quels événements sont liés à «ce qui s'est passé avant». C'est-à-dire cela signifie que nous pouvons changer l'état de l'acteur autant que nous le souhaitons, mais lorsque nous recevons le message suivant et le traitons éventuellement dans un autre thread, nous sommes garantis de voir toutes les modifications apportées dans un autre thread.
Pourquoi le modèle de filetage est-il si populaire?
Nous avons examiné deux modèles de programmation compétitive, en fait il y en a encore plus qui rendent la programmation compétitive plus facile et plus sûre.
Mais pourquoi alors les fils et les serrures sont-ils toujours aussi populaires?
Je pense que la raison est la simplicité de l'approche, bien sûr, d'une part, il est facile de faire de nombreuses erreurs non évidentes avec les ruisseaux, de se tirer une balle dans le pied, etc. Mais d'un autre côté
, il n'y a rien de compliqué dans les flux, surtout si l'on ne pense pas aux conséquences .
À un moment donné, le noyau peut exécuter une instruction (en fait non, la concurrence existe au niveau de l'instruction, mais maintenant cela n'a plus d'importance), mais en raison du multitâche, même sur des machines monocœur, plusieurs programmes peuvent être exécutés simultanément (bien sûr pseudo simultanément).
Pour que le multitâche fonctionne, vous avez besoin de concurrence. Comme nous l'avons déjà compris, la concurrence est impossible sans plusieurs flux de gestion.
Combien de threads pensez-vous qu'un programme qui s'exécute sur un processeur de téléphone portable quadricœur doit être aussi rapide et réactif que possible?
Il peut y en avoir plusieurs dizaines. Maintenant, la question est, pourquoi avons-nous besoin d'autant de threads pour un programme qui s'exécute sur du matériel qui vous permet d'exécuter seulement 2 à 4 threads à la fois?
Pour essayer de répondre à cette question, supposons que seul notre programme fonctionne sur l'appareil et rien d'autre. Comment gérerions-nous les ressources qui nous sont fournies?
Vous pouvez donner un noyau pour l'interface utilisateur, le reste du noyau pour toute autre tâche.
Si l'un des threads est bloqué, par exemple, le thread peut aller au contrôleur de mémoire et attendre une réponse, alors nous obtiendrons un noyau bloqué.Quelles technologies sont là pour résoudre le problème?Il existe des threads en Java, nous pouvons créer de nombreux threads, puis d'autres threads pourront effectuer des opérations pendant que certains threads sont bloqués. Avec un outil comme les fils, nous pouvons simplifier nos vies.L'approche avec les threads n'est pas gratuite, la création de threads prend généralement du temps (c'est décidé par les pools de threads), de la mémoire leur est allouée, la commutation entre les threads est une opération coûteuse. Mais il est relativement facile de programmer avec eux, c'est donc une technologie massive qui est si largement utilisée dans les langages généraux, comme Java.Java aime généralement les threads, il n'est pas nécessaire de créer pour chaque action un thread, il existe des éléments de niveau supérieur, tels que les exécuteurs, qui vous permettent de travailler avec des pools et d'écrire du code plus évolutif et flexible. Les flux sont vraiment pratiques, vous pouvez faire une demande de blocage au réseau et écrire le traitement des résultats sur la ligne suivante. Même si nous attendons quelques secondes le résultat, nous pouvons encore effectuer d'autres tâches, car le système d'exploitation se chargera de la répartition du temps processeur entre les threads.Les flux sont populaires non seulement dans le développement backend, dans le développement mobile, il est considéré comme tout à fait normal de créer des dizaines de flux afin que vous puissiez bloquer un flux pendant quelques secondes, en attendant que les données soient téléchargées sur le réseau ou les données du socket.Des langues comme Erlang ou Clojure sont encore des niches, et donc les modèles de programmation compétitifs qu'ils utilisent ne sont pas si populaires. Cependant, leurs prévisions sont les plus optimistes.Conclusions
Si vous développez sur la plateforme JVM, vous devez accepter les règles du jeu indiquées par la plateforme. C'est le seul moyen d'écrire du code multithread normal. Il est très souhaitable de comprendre le contexte de tout ce qui se passe, il sera donc plus facile d'accepter les règles du jeu. C’est encore mieux de regarder autour de vous et de vous familiariser avec d’autres paradigmes, bien que vous ne puissiez pas vous éloigner du sous-marin, mais vous pouvez découvrir de nouvelles approches et de nouveaux outils.Matériel supplémentaire
J'ai essayé de placer dans le texte de l'article des liens vers des sources dont j'ai obtenu des informations.En général, le matériel JMM est facile à trouver sur Internet. Ici, je publierai des liens vers du matériel supplémentaire associé à JMM et peut ne pas attirer immédiatement mon attention.La lecture- Le blog d'Alexey Shipilev - Je sais ce qui est évident, mais c'est juste un péché sans parler
- Le blog de Cheremin Ruslan - il n'a pas écrit activement ces derniers temps, vous devez rechercher ses anciennes entrées dans le blog, croyez-moi, ça vaut le coup - il y a une source
- Habr Gleb Smirnov - il existe d'excellents articles sur le multithreading et le modèle de mémoire
- Le blog de Roman Elizarov est abandonné, mais des fouilles archéologiques doivent être effectuées. En général, Roman a fait beaucoup pour éduquer les gens à la théorie de la programmation multithread, recherchez-la dans les médias.
PodcastsProblèmes que j'ai trouvés particulièrement intéressants. Ils ne concernent pas JMM, ils concernent l'enfer, ce qui se passe dans la glande. Mais après les avoir écoutés, je veux embrasser les créateurs de JMM, qui nous ont protégés de tout cela.VidéoEn plus des discours des personnes susmentionnées, faites attention à la vidéo académique.