Cet article est une traduction autorisée de l'article d'origine . La traduction a été réalisée avec l'aimable aide des gars de PVS-Studio. Merci les gars!Ce qui m'a encouragé à écrire cet article, c'est une quantité importante de documents sur l'analyse statique, qui est de plus en plus récente. Tout d'abord, il s'agit d'un
blog de PVS-Studio , qui se promeut activement sur Habr en publiant des critiques d'erreurs, trouvées par leur outil dans des projets open source. PVS-Studio a récemment implémenté le
support Java et, bien sûr, les développeurs d'IntelliJ IDEA, dont l'analyseur intégré est probablement le plus avancé pour Java aujourd'hui,
ne pouvaient pas rester à l'écart .
En lisant ces critiques, j'ai l'impression que nous parlons d'un élixir magique: cliquez sur le bouton, et le voici - la liste des défauts juste devant vos yeux. Il semble qu'à mesure que les analyseurs deviennent plus avancés, de plus en plus de bugs seront détectés, et les produits, scannés par ces robots, deviendront de mieux en mieux sans aucun effort de notre part.
Eh bien, mais il n'y a pas d'élixirs magiques. Je voudrais parler de ce qui n'est généralement pas parlé dans des articles comme "voici des choses que notre robot peut trouver": ce que les analyseurs ne sont pas en mesure de faire, quelle est leur véritable partie et place dans le processus de livraison de logiciels, et comment mettre en œuvre l'analyse correctement.
 Ratchet (source: Wikipedia ).
Ratchet (source: Wikipedia ).Ce que les analyseurs statiques ne pourront jamais faire
Quelle est l'analyse du code source du point de vue pratique? Nous prenons les fichiers source et obtenons quelques informations sur la qualité du système en peu de temps (beaucoup plus court qu'une exécution de tests). La limitation principale et mathématiquement insurmontable est que de cette façon, nous ne pouvons répondre qu'à un sous-ensemble très limité de questions sur le système analysé.
L'exemple le plus célèbre d'une tâche, non résoluble en utilisant l'analyse statique est un
problème d'arrêt : c'est un théorème, qui prouve qu'on ne peut pas travailler sur un algorithme général, qui définirait si un programme avec un code source donné bouclé pour toujours ou terminé pour la dernière fois. L'extension de ce théorème est un
théorème de Rice , affirmant que pour toute propriété non triviale de fonctions calculables, la question de déterminer si un programme donné calcule une fonction avec cette propriété est une tâche algorithmiquement insoluble. Par exemple, vous ne pouvez pas écrire un analyseur, qui détermine en fonction du code source si le programme analysé est une implémentation d'un algorithme spécifique, disons, celui qui calcule la mise au carré d'un nombre entier.
Ainsi, la fonctionnalité des analyseurs statiques a des limites insurmontables. L'analyseur statique ne pourra jamais détecter tous les cas, par exemple, de bogue "d'exception de pointeur nul" dans les langues sans la
sécurité void . Ou détectez toutes les occurrences de "attribut introuvable" dans les langues typées dynamiquement. Tout ce que l'analyseur statique le plus parfait peut faire est de détecter des cas particuliers. Le nombre d'entre eux parmi tous les problèmes possibles avec votre code source, sans exagération, est une goutte dans l'océan.
L'analyse statique n'est pas une recherche de bogues
Voici une conclusion qui découle de ce qui précède: l'analyse statique n'est pas le moyen de diminuer le nombre de défauts dans un programme. Je me risquerais à affirmer ce qui suit: étant appliqué pour la première fois à votre projet, il trouvera des endroits "amusants" dans le code, mais ne trouvera probablement aucun défaut affectant la qualité de votre programme.
Les exemples de défauts détectés automatiquement par les analyseurs sont impressionnants, mais il ne faut pas oublier que ces exemples ont été trouvés en scannant un énorme ensemble de bases de code par rapport à un ensemble de règles relativement simples. De la même manière, les pirates, ayant la possibilité d'essayer plusieurs mots de passe simples sur un grand nombre de comptes, finissent par trouver les comptes avec un mot de passe simple.
Est-ce à dire qu'il n'est pas nécessaire d'appliquer une analyse statique? Bien sûr que non! Il doit être appliqué pour la même raison que vous souhaiterez peut-être vérifier chaque nouveau mot de passe dans la liste d'arrêt des mots de passe non sécurisés.
L'analyse statique est plus que la recherche de bogues
En fait, les tâches qui peuvent être résolues par l'analyse dans la pratique sont beaucoup plus larges. Parce que d'une manière générale, l'analyse statique représente toute vérification du code source, effectuée avant de l'exécuter. Voici certaines choses que vous pouvez faire:
- Une vérification du style de codage au sens large de ce mot. Il comprend à la fois une vérification de la mise en forme et une recherche d'utilisation des parenthèses vides / inutiles, la définition de valeurs de seuil pour les métriques telles qu'un certain nombre de lignes / la complexité cyclomatique d'une méthode, etc. - tout cela complique la lisibilité et la maintenabilité du code. En Java, Checkstyle représente un outil avec une telle fonctionnalité, en Python -
flake8 . Ces programmes sont généralement appelés "linters". - Non seulement le code exécutable peut être analysé. La validité des ressources telles que les fichiers JSON, YAML, XML et
.properties peut (et doit!) Être vérifiée automatiquement. La raison en est qu'il est préférable de découvrir que, disons, la structure JSON est rompue en raison des citations non appariées au début de la vérification automatisée d'une demande d'extraction plutôt que pendant l'exécution des tests ou au moment de l'exécution, n'est pas ça? Il existe des outils pertinents, par exemple, YAMLlint , JSONLint et xmllint . - La compilation (ou l'analyse pour les langages de programmation dynamiques) est également une sorte d'analyse statique. Habituellement, les compilateurs peuvent émettre des avertissements qui signalent des problèmes de qualité du code source, et ils ne doivent pas être ignorés.
- Parfois, la compilation est appliquée non seulement au code exécutable. Par exemple, si vous avez de la documentation au format AsciiDoctor , puis en train de la compiler en HTML / PDF, AsciiDoctor ( plugin Maven ) peut émettre des avertissements, par exemple, sur des liens internes rompus. Il s'agit d'une raison importante de ne pas accepter une demande d'extraction avec des modifications de la documentation.
- La vérification orthographique est également une sorte d'analyse statique. L'utilitaire aspell est capable de vérifier l'orthographe non seulement dans la documentation, mais aussi dans le code source des programmes (commentaires et littéraux) dans divers langages de programmation, notamment C / C ++, Java et Python. Une faute d'orthographe dans l'interface utilisateur ou la documentation est également un défaut!
- Les tests de configuration représentent en fait une forme d'analyse statique, car ils n'exécutent pas le code source pendant le processus de leur exécution, même si les tests de configuration sont exécutés comme des
pytest unitaires pytest .
Comme nous pouvons le voir, la recherche de bogues a le rôle le moins important dans cette liste et tout le reste est disponible lors de l'utilisation d'outils open source gratuits.
Lequel de ces types d'analyse statique doit être utilisé dans votre projet? Bien sûr, plus c'est mieux! Ce qui est important ici, c'est une bonne mise en œuvre, qui sera discutée plus loin.
Un pipeline de livraison comme filtre à plusieurs étages et l'analyse statique comme sa première étape
Un pipeline avec un flux de changements (depuis les changements du code source jusqu'à la livraison en production) est une métaphore classique de l'intégration continue. La séquence standard des étapes de ce pipeline se présente comme suit:
- analyse statique
- compilation
- tests unitaires
- tests d'intégration
- Tests d'interface utilisateur
- vérification manuelle
Les modifications rejetées à la N-ème étape du pipeline ne sont pas transmises à l'étape N + 1.
Pourquoi et non autrement? Dans la partie du pipeline, qui traite des tests, les testeurs reconnaissent la pyramide des tests bien connue:
 Pyramide de test. Source: l'article de Martin Fowler.
Pyramide de test. Source: l'article de Martin Fowler.Au bas de cette pyramide, il y a des tests plus faciles à écrire, qui sont exécutés plus rapidement et n'ont pas tendance à produire de faux positifs. Par conséquent, il devrait y en avoir plus, ils devraient couvrir la majeure partie du code et devraient être exécutés en premier. Au sommet de la pyramide, la situation est tout à fait opposée, de sorte que le nombre de tests d'intégration et d'interface utilisateur devrait être réduit au minimum nécessaire. Les membres de cette chaîne sont la ressource la plus chère, la plus lente et la moins fiable, ils sont donc situés à la fin et ne font le travail que si les étapes précédentes n'ont détecté aucun défaut. Dans les parties non liées aux tests, le pipeline est construit selon les mêmes principes!
Je voudrais suggérer l'analogie sous la forme d'un système de filtration de l'eau à plusieurs niveaux. L'eau sale (change avec des défauts) est fournie dans l'entrée, et en tant que sortie, nous devons obtenir de l'eau propre, qui ne contiendra pas toutes les contaminations indésirables.
 Filtre à plusieurs étages. Source: Wikimedia Commons
Filtre à plusieurs étages. Source: Wikimedia CommonsComme vous le savez peut-être, les filtres de purification sont conçus pour que chaque étape suivante soit capable d'éliminer les particules contaminantes de plus petite taille. Les étapes d'entrée de purification grossière ont un débit plus élevé et un coût inférieur. Dans notre analogie, cela signifie que les portes de qualité d'entrée ont de meilleures performances, nécessitent moins d'efforts pour être lancées et ont moins de coûts d'exploitation. Le rôle de l'analyse statique, qui (comme nous le comprenons maintenant) ne peut éliminer que les défauts les plus graves est le rôle du filtre de puisard en tant que premier étage des purificateurs à plusieurs étages.
L'analyse statique n'améliore pas la qualité du produit final par elle-même, tout comme le «puisard» ne rend pas l'eau potable. Pourtant, en conjonction avec d'autres éléments du pipeline, son importance est évidente. Même si dans un filtre à plusieurs étages, les étages de sortie peuvent potentiellement supprimer tout ce que les entrées peuvent faire - nous sommes conscients des conséquences qui suivront lorsque vous tenterez de vous en sortir uniquement avec des étapes de purification fine, sans étapes d'entrée.
Le «puisard» a pour but de décharger les étapes suivantes de la capture des défauts très grossiers. Par exemple, une personne effectuant une révision de code ne doit pas être distraite par du code mal formaté et une violation des normes de code (comme des parenthèses redondantes ou des branchements imbriqués trop profondément). Les bogues comme NPE devraient être détectés par les tests unitaires, mais si auparavant, l'analyseur indique qu'un bogue doit apparaître inévitablement - cela accélérera considérablement sa correction.
Je suppose qu'il est maintenant clair pourquoi l'analyse statique n'améliore pas la qualité du produit lorsqu'elle est appliquée occasionnellement, et doit être appliquée en continu pour filtrer les modifications présentant de graves défauts. La question de savoir si l'application d'un analyseur statique améliore la qualité de votre produit est à peu près équivalente à la question "si nous prenons de l'eau d'étangs sales, sa qualité de boisson sera-t-elle améliorée lorsque nous la passerons dans une passoire?"
Introduction dans un projet hérité
Un enjeu pratique important: comment mettre en œuvre l'analyse statique dans le processus d'intégration continue, en tant que «porte qualité»? En cas de tests automatisés, tout est clair: il existe un ensemble de tests, l'échec de l'un d'entre eux est une raison suffisante pour croire qu'une build n'a pas passé une porte de qualité. Une tentative de définir la porte de la même manière par les résultats de l'analyse statique échoue: il y a trop d'avertissements d'analyse sur le code hérité, vous ne voulez pas tous les ignorer, d'autre part, il est impossible d'arrêter la livraison du produit simplement parce que il contient des avertissements de l'analyseur.
Pour tout projet, l'analyseur émet un grand nombre d'avertissements appliqués la première fois. La majorité des avertissements n'ont rien à voir avec le bon fonctionnement du produit. Il sera impossible de les réparer tous et beaucoup d'entre eux n'ont pas du tout besoin d'être réparés. Au final, nous savons que notre produit fonctionne réellement avant même l'introduction de l'analyse statique!
En conséquence, de nombreux développeurs se cantonnent à une utilisation occasionnelle de l'analyse statique ou ne l'utilisent qu'en mode informatif, ce qui implique d'obtenir un rapport d'analyseur lors de la construction d'un projet. Cela équivaut à l'absence d'analyse, car si nous avons déjà de nombreux avertissements, l'émergence d'un autre (même grave) reste inaperçu lors du changement de code.
Voici les moyens connus d'introduction de portes de qualité:
- Définition de la limite du nombre total d'avertissements ou du nombre d'avertissements, divisé par le nombre de lignes de code. Cela fonctionne mal, car une telle porte laisse passer les changements avec de nouveaux défauts jusqu'à ce que leur limite soit dépassée.
- Marquage de tous les anciens avertissements du code comme ignorés à un certain moment et échec de la génération lorsque de nouveaux avertissements apparaissent. Une telle fonctionnalité peut être fournie par PVS-Studio et certains autres outils, par exemple, Codacy. Je n'ai pas eu l'occasion de travailler avec PVS-Studio. Quant à mon expérience avec Codacy, leur principal problème est que la distinction entre une ancienne et une nouvelle erreur est un algorithme compliqué et pas toujours fonctionnel, surtout si les fichiers changent de manière significative ou sont renommés. À ma connaissance, Codacy pourrait ignorer de nouveaux avertissements dans une demande d'extraction et en même temps entraver une demande d'extraction en raison d'avertissements, non liés à des modifications du code de ce PR.
- À mon avis, la solution la plus efficace est la méthode du «cliquet» décrite dans le livre « Continuous Delivery ». L'idée de base est que le nombre d'avertissements d'analyse statique est une propriété de chaque version et seules ces modifications sont autorisées, ce qui n'augmente pas le nombre total d'avertissements.
Cliquet
Cela fonctionne de la manière suivante:
- Dans la phase initiale, une entrée sur un certain nombre d'avertissements trouvés par les analyseurs de code est ajoutée dans les métadonnées de publication. Ainsi, lors de la construction de la branche principale, non seulement la «version 7.0.2» est écrite dans votre gestionnaire de référentiel, mais la «version 7.0.2, contenant 100500 Checkstyle-warnings». Si vous utilisez un gestionnaire de référentiels avancé (comme Artifactory), il est facile de conserver ces métadonnées sur votre version.
- Lors de la création, chaque demande d'extraction compare le nombre d'avertissements résultants avec leur nombre dans une version actuelle. Si un PR conduit à une croissance de ce nombre, le code ne passe pas la porte de qualité sur l'analyse statique. Si le nombre d'avertissements est réduit ou ne change pas - alors il passe.
- Lors de la prochaine version, le numéro recalculé sera à nouveau écrit dans les métadonnées.
Ainsi lentement mais sûrement, le nombre d'avertissements convergera vers zéro. Bien sûr, le système peut être trompé en introduisant un nouvel avertissement et en corrigeant celui de quelqu'un d'autre. C'est normal, car à long terme, cela donne le résultat: les avertissements sont résolus, généralement pas un par un, mais par des groupes d'un certain type, et tous les avertissements facilement résolus sont résolus assez rapidement.
Ce graphique montre le nombre total d'avertissements Checkstyle pendant six mois d'un tel "cliquet" sur l'
un de nos projets OpenSource . Le nombre d'avertissements a été considérablement réduit, et cela s'est produit naturellement, en parallèle avec le développement du produit!
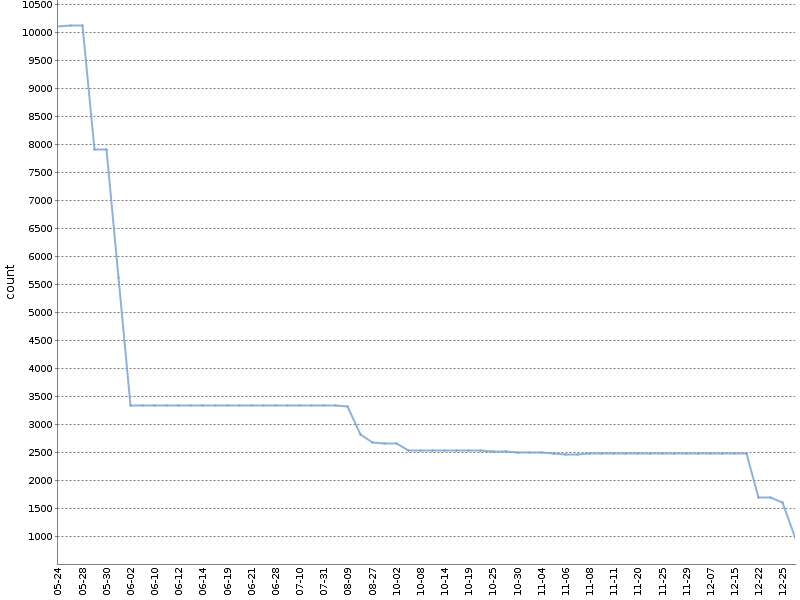
J'applique la version modifiée de cette méthode. Je compte les avertissements séparément pour différents modules de projet et outils d'analyse. Le fichier YAML avec des métadonnées sur la construction, qui est formé en procédant ainsi, se présente comme suit:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
Dans tout système CI avancé, un "cliquet" peut être implémenté pour tous les outils d'analyse statique, sans s'appuyer sur des plugins et des outils tiers. Chacun des analyseurs publie son rapport dans un format texte ou XML simple, qui sera facilement analysé. La seule chose à faire après, est d'écrire la logique nécessaire dans un script CI. Vous pouvez jeter un œil et voir
ici ou
ici comment il est implémenté dans nos projets sources basés sur Jenkins et Artifactory. Les deux exemples dépendent de la bibliothèque
ratchetlib : la méthode
countWarnings() de la manière habituelle compte les balises xml dans les fichiers générés par Checkstyle et Spotbugs, et
compareWarningMaps() implémente ce même cliquet, lançant une erreur dans le cas, si le nombre d'avertissements dans l'un des les catégories augmentent.
Une manière intéressante d'implémentation "à cliquet" est possible pour analyser l'orthographe des commentaires, des littéraux de texte et de la documentation en utilisant aspell. Comme vous le savez peut-être, lors de la vérification de l'orthographe, tous les mots inconnus du dictionnaire standard ne sont pas incorrects, ils peuvent être ajoutés au dictionnaire personnalisé. Si vous intégrez un dictionnaire personnalisé au projet de code source, le portail de qualité pour l'orthographe peut être formulé comme suit: l'exécution d'aspell avec un dictionnaire standard et personnalisé
ne doit pas trouver d'erreurs d'orthographe.
L'importance de corriger la version de l'analyseur
En conclusion, il est nécessaire de noter ce qui suit: quelle que soit la façon dont vous choisissez d'introduire l'analyse dans votre pipeline de livraison, la version de l'analyseur doit être fixe. Si vous laissez l'analyseur se mettre à jour spontanément, lors de la génération d'une autre demande d'extraction, de nouveaux défauts peuvent apparaître, qui ne sont pas liés au code modifié, mais au fait que le nouvel analyseur est simplement capable de détecter plus de défauts. Cela interrompra votre processus de vérification de la demande d'extraction. La mise à niveau de l'analyseur doit être une action consciente. Quoi qu'il en soit, la fixation rigide de la version de chaque composant de construction est une exigence générale et un sujet pour un autre sujet.
Conclusions
- L'analyse statique ne trouvera pas de bogues et n'améliorera pas la qualité de votre produit à la suite d'une seule exécution. Seul son fonctionnement continu dans le processus de livraison produira un effet positif.
- La chasse aux insectes n'est pas du tout l'objectif principal de l'analyse. La grande majorité des fonctionnalités utiles sont disponibles dans les outils open source.
- Introduire des portes de qualité par les résultats de l'analyse statique sur la première étape du pipeline de livraison, en utilisant le «cliquet» pour le code hérité.
Les références
- Livraison continue
- Alexey Kudryavtsev: Analyse de programme: êtes-vous un bon développeur? Rapport sur différentes méthodes d'analyse de code, pas seulement statique!
Extraits de la discussion de l'article original
Evgeniy RyzhkovIvan, merci pour l'article et pour nous avoir aidés à faire notre travail, qui est de vulgariser la technologie de l'analyse de code statique. Vous avez tout à fait raison de dire que les articles du blog PVS-Studio, au cas où les esprits seraient immatures, pourraient les affecter et conduire à des conclusions telles que "Je vais vérifier le code une seule fois, corriger les erreurs et cela suffira." C'est ma douleur personnelle, que je ne sais pas surmonter depuis déjà plusieurs années. Le fait est que les articles sur les contrôles de projets:
- Provoque un effet wow chez les gens. Les gens aiment lire comment les développeurs de sociétés telles que Google, Epic Games, Microsoft et d'autres sociétés échouent parfois. Les gens aiment penser que n'importe qui peut se tromper, même les leaders de l'industrie font des erreurs. Les gens aiment lire ces articles.
- De plus, les auteurs peuvent écrire des articles sur le flux, sans avoir à réfléchir sérieusement. Bien sûr, je ne veux pas offenser nos gars qui écrivent ces articles. Mais trouver un nouvel article à chaque fois est beaucoup plus difficile que d'écrire un article sur une vérification de projet (une douzaine de bugs, quelques blagues, mélangez-le avec des images de licornes).
Vous avez écrit un très bon article. J'ai également quelques articles sur ce sujet. Les autres collègues aussi. De plus, je visite différentes entreprises avec un rapport sur le thème "Philosophie de l'analyse de code statique", dans lequel je parle du processus lui-même, mais pas de bugs spécifiques.
Mais il n'est pas possible d'écrire 10 articles sur le processus. Eh bien, pour promouvoir notre produit, nous devons écrire régulièrement. Je voudrais commenter quelques points supplémentaires de l'article avec un commentaire séparé pour amener la discussion plus facilement.
Ce court
article traite de la «Philosophie de l'analyse de code statique», qui est mon sujet lorsque je visite différentes entreprises.
Ivan PonomarevEvgeniy, merci beaucoup pour la revue informative de l'article! Oui, vous avez eu ma préoccupation dans le post sur l'impact sur les "esprits immatures" tout à fait correctement!
Il n'y a personne à blâmer ici, car les auteurs des articles / rapports sur les
analyseurs ne visent pas à faire des articles / rapports sur l'
analyse . Mais après quelques articles récents d'
Andrey2008 et de
lany , j'ai décidé que je ne pouvais plus me taire.
Evgeniy RyzhkovIvan, comme écrit ci-dessus, je commenterai trois points de l'article. Cela signifie que je suis d'accord avec ceux-là, que je ne commente pas.
1.
La séquence standard des étapes de ce pipeline se présente comme suit ...Je ne suis pas d'accord pour dire que la première étape est l'analyse statique et que la deuxième est la compilation. Je pense qu'en moyenne, la vérification de la compilation est plus rapide et plus logique qu'une exécution immédiate d'une analyse statique "plus lourde". Nous pouvons discuter si vous pensez le contraire.
2.
Je n'ai pas travaillé avec PVS-Studio. Quant à mon expérience avec Codacy, leur principal problème est que la distinction entre une ancienne et une nouvelle erreur est un algorithme compliqué et pas toujours fonctionnel, surtout si les fichiers changent de manière significative ou sont renommés.Dans PVS-Studio, cela est extrêmement pratique. C'est l'une des principales caractéristiques du produit, qui, malheureusement, est difficile à décrire dans les articles, c'est pourquoi les gens ne le connaissent pas très bien. Nous recueillons des informations sur les erreurs existantes dans une base. Et pas seulement «le nom du fichier et la ligne», mais aussi des informations supplémentaires (marque de hachage de trois lignes - actuelle, précédente, suivante), de sorte qu'en cas de décalage du fragment de code, nous pourrions toujours le trouver. Par conséquent, lorsque des modifications mineures sont apportées, nous comprenons toujours qu'il s'agit d'une ancienne erreur. Et l'analyseur ne s'en plaint pas. Maintenant, quelqu'un peut dire: "Eh bien, si le code a beaucoup changé, cela ne fonctionnerait pas, et vous vous en plaignez comme s'il était le nouveau?" Oui Nous nous plaignons. Mais en fait, c'est un nouveau code. Si le code a beaucoup changé, c'est maintenant un nouveau code, plutôt que l'ancien.
Grâce à cette fonctionnalité, nous avons personnellement participé à la mise en œuvre du projet avec 10 millions de lignes de code C ++, qui est chaque jour «touché» par un tas de développeurs. Tout s'est déroulé sans aucun problème. Nous recommandons donc d'utiliser cette fonctionnalité de PVS-Studio à toute personne qui introduit l'analyse statique dans son processus. L'option de fixation du nombre d'avertissements en fonction d'une version me semble moins sympathique.
3.
Quelle que soit la façon dont vous choisissez d'introduire votre analyse du pipeline de livraison, la version de l'analyseur doit être fixeJe ne suis pas d'accord avec ça. Un adversaire certain d'une telle approche. Je recommande de mettre à jour l'analyseur en mode automatique. Au fur et à mesure que nous ajoutons de nouveaux diagnostics et améliorons les anciens. Pourquoi? Tout d'abord, vous recevrez des avertissements pour de nouvelles erreurs réelles. Deuxièmement, certains vieux faux positifs pourraient disparaître si nous les surmontions.
Ne pas mettre à jour l'analyseur revient à ne pas mettre à jour les bases de données antivirus («et si elles commencent à notifier les virus»). Nous ne discuterons pas ici de la véritable utilité du logiciel antivirus dans son ensemble.
Si, après la mise à niveau de la version de l'analyseur, vous avez de nombreux nouveaux avertissements, supprimez-les, comme je l'ai écrit ci-dessus, via cette fonction. Mais pas pour mettre à jour la version ... En règle générale, de tels clients (bien sûr, il y en a) ne mettent pas à jour la version de l'analyseur pendant des années. Pas le temps pour ça. Ils PAYENT pour le renouvellement de la licence, mais n'utilisent pas les nouvelles versions. Pourquoi? Parce qu'une fois, ils ont décidé de fixer une version. Le produit aujourd'hui et il y a trois ans est jour et nuit. Il s'avère que «je vais acheter le billet, mais ne viendra pas».
Ivan Ponomarev1. Ici, vous avez raison. Je suis prêt à être d'accord avec un compilateur / analyseur au début et cela devrait même être changé dans l'article! Par exemple, les fameux
spotbugs ne peuvent pas du tout agir différemment, car ils analysent le bytecode compilé. Il y a des cas exotiques, par exemple, dans le pipeline des playbooks Ansible, il est préférable de définir l'analyse statique avant l'analyse car elle est plus légère. Mais c'est l'exotique lui-même)
2.
L'option de fixation du nombre d'avertissements en fonction d'une release me semble moins sympathique ... - ben oui, c'est moins sympathique, moins technique mais très pratique :-) L'essentiel c'est que c'est un méthode générale, par laquelle je peux implémenter efficacement l'analyse statique n'importe où, même dans le projet le plus effrayant, ayant n'importe quelle base de code et n'importe quel analyseur (pas nécessairement le vôtre), en utilisant des scripts Groovy ou bash sur CI. Soit dit en passant, nous comptons maintenant les avertissements séparément pour différents modules et outils de projet, mais si nous les divisons de manière plus granuleuse (pour les fichiers), cela sera beaucoup plus proche de la méthode de comparaison des nouveaux / anciens. Mais nous avons ressenti cela et j'ai aimé ce cliquet car il stimule les développeurs à surveiller le nombre total d'avertissements et à diminuer lentement ce nombre. Si nous avions la méthode des anciens / nouveaux, cela motiverait-il les développeurs à surveiller la courbe du nombre d'avertissements? - probablement, oui, peut-être, non.
Quant au point 3, voici un vrai exemple de mon expérience. Regardez
ce commit . D'où cela vient-il? Nous plaçons des linters dans le script TravisCI. Ils y travaillaient comme des portes de qualité. Mais tout à coup, lorsqu'une nouvelle version d'Ansible-lint qui trouvait plus d'avertissements, certaines versions de demandes de tir ont commencé à échouer en raison d'avertissements dans le code, qu'ils n'avaient pas modifiés !!! Au final, le processus a été interrompu et les demandes de retrait urgentes ont été fusionnées sans passer par des barrières de qualité.
Personne ne dit qu'il n'est pas nécessaire de mettre à jour les analyseurs. Bien sûr que ça l'est! Comme tous les autres composants de build. Mais ce doit être un processus conscient, reflété dans le code source. Et chaque fois que les actions dépendront des circonstances (que nous réparions les avertissements détectés à nouveau ou que nous réinitialisions simplement le "cliquet")
Evgeniy RyzhkovQuand on me demande: «Y a-t-il une possibilité de vérifier chaque commit dans PVS-Studio?», Je réponds que oui, il y en a. Et puis ajoutez: "Juste pour l'amour de Dieu, ne manquez pas la construction si PVS-Studio trouve quelque chose!" Parce que sinon, tôt ou tard, PVS-Studio sera perçu comme une chose perturbatrice. Et il y a des situations où IL EST NÉCESSAIRE de s'engager rapidement, plutôt que de se battre avec les outils, qui ne laissent pas passer le commit.
Mon avis qu'il est mauvais d'échouer la construction dans ce cas. Il est bon d'envoyer des messages aux auteurs du code problématique.
Ivan PonomarevÀ mon avis, il n'existe pas de «nous devons nous engager rapidement». Tout cela n'est qu'un mauvais processus. Un bon processus génère de la vitesse non pas parce que nous cassons un processus / des portes de qualité, quand nous devons «le faire rapidement».
Cela ne contredit pas le fait que nous pouvons faire sans manquer une construction sur certaines classes de résultats d'analyse statique. Cela signifie simplement que la porte est configurée de manière à ignorer certains types de résultats et pour d'autres résultats, nous avons une tolérance zéro.
Mon commitstrip préféré sur le sujet "rapidement".Evgeniy RyzhkovJe suis un adversaire certain de l'approche consistant à utiliser l'ancienne version de l'analyseur. Et si un utilisateur découvrait un bogue dans cette version? Il écrit à un développeur d'outils et un développeur d'outils le corrigera même. Mais dans la nouvelle version. Personne ne prendra en charge l'ancienne version pour certains clients. Si nous ne parlons pas de contrats valant des millions de dollars.
Ivan PonomarevEvidemment, nous n'en parlons pas du tout. Personne ne dit que nous devons les garder vieux. Il s'agit de corriger les versions des dépendances des composants de construction pour leur mise à jour contrôlée - c'est une discipline courante, elle s'applique à tout, y compris les bibliothèques et les outils.
Evgeniy RyzhkovJe comprends comment "cela devrait être fait en théorie". Mais je ne vois que deux choix faits par les clients. Soit s'en tenir à la nouvelle ou à l'ancienne. Nous n'avons donc PRESQUE PAS de telles situations quand «nous avons de la discipline et nous sommes en retard par rapport à la version actuelle sur deux versions». Ce n'est pas important pour moi de dire maintenant que c'est bon ou mauvais. Je dis juste ce que je vois.
Ivan PonomarevJ'ai compris. Quoi qu'il en soit, tout dépend fortement des outils / processus dont disposent vos clients et de la façon dont ils les utilisent. Par exemple, je ne sais pas comment tout cela fonctionne dans le monde C ++.