Il y a quelques mois, nos collègues de Google ont
organisé un concours à Kaggle pour créer un classificateur pour les images reçues dans le
jeu acclamé "Quick, Draw!". L'équipe, à laquelle Roman Vlasov, développeur Yandex a participé, a pris la quatrième place du concours. Lors de la session de formation en machine-learning de janvier, Roman a partagé les idées de son équipe, la mise en œuvre finale du classificateur et les pratiques intéressantes de ses rivaux.
- Bonjour à tous! Je m'appelle Roma Vlasov, aujourd'hui je vais vous parler de Quick, Draw! Défi de reconnaissance de Doodle.

Il y avait cinq personnes dans notre équipe. Je l'ai rejointe juste avant la date limite de fusion. Nous n'avons pas eu de chance, nous étions un peu secoués, mais nous étions à l'abri de l'argent, et ils étaient de la position d'or. Et nous avons pris une honorable quatrième place.
(Pendant le concours, les équipes se sont observées dans la notation, qui a été formée en fonction des résultats indiqués sur une partie de l'ensemble de données proposé. La notation finale, à son tour, a été formée sur l'autre partie de l'ensemble de données. Ceci est fait pour que les participants au concours n'adaptent pas leurs algorithmes à des données spécifiques. Par conséquent, lors des finales, lors du basculement entre les classements, les positions sont un peu "sheikap" (de l'anglais shake up - à shuffle): sur d'autres données et le résultat peut être différent. L'équipe de Roman était première dans le top trois. AU Troika - est de l'argent, zone de classement de l'argent, puisque seuls les trois premiers emplacements invoquaient prix Après que l'équipe « secousse apa » était déjà à la quatrième place de la même manière l'autre équipe a perdu la victoire, la position de l'or -... Ed) ..
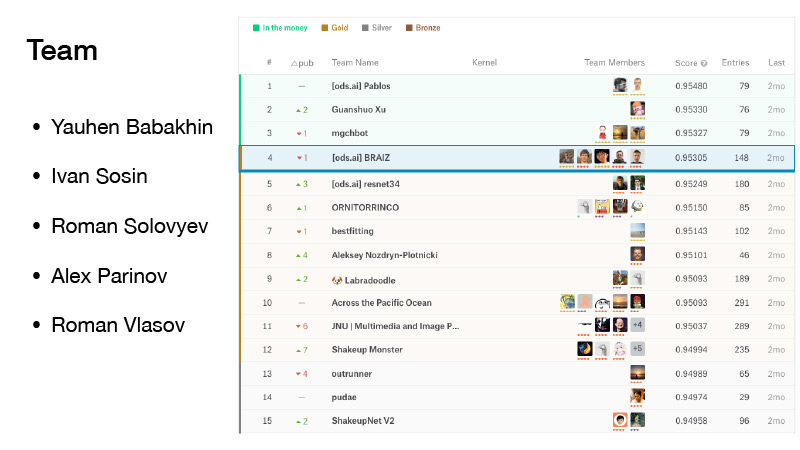
La compétition était également importante car Yevgeny Babakhnin a reçu pour lui des grands-maîtres, Ivan Sosin - des maîtres, Roman Solovyov est resté un grand maître, Alex Parinov a reçu un maître, je suis devenu un expert, et maintenant je suis déjà un maître.
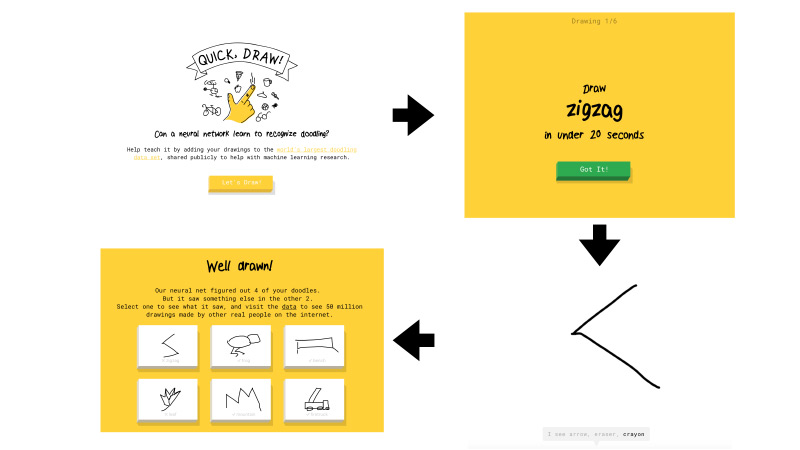
Qu'est-ce que c'est Quick, Draw? Il s'agit d'un service de Google. Google visait à vulgariser l'IA et, avec ce service, voulait montrer comment fonctionnent les réseaux de neurones. Vous allez là-bas, cliquez sur Dessiner, et une nouvelle page apparaît où l'on vous dit: dessinez un zigzag, vous avez 20 secondes pour le faire. Vous essayez de dessiner un zigzag en 20 secondes, comme ici, par exemple. Si tout fonctionne pour vous, le réseau dit que c'est un zigzag et vous continuez. Il n'y a que six images de ce type.
Si le réseau de Google ne pouvait pas reconnaître ce que vous avez dessiné, une croix a été placée sur la tâche. Plus tard, je vous dirai ce que cela signifiera à l'avenir, que le dessin soit reconnu par le réseau ou non.
Ce service a rassemblé un nombre assez important d'utilisateurs, et toutes les photos que les utilisateurs ont dessinées ont été enregistrées.

Il a été possible de collecter près de 50 millions de photos. À partir de cela, la date du train et des tests pour notre compétition a été formée. Soit dit en passant, la quantité de données dans le test et le nombre de classes ne sont pas en vain en gras. J'en parlerai un peu plus tard.
Le format des données était le suivant. Ce ne sont pas seulement des images RVB, mais, en gros, le journal de tout ce que l'utilisateur a fait. Word est notre cible, countrycode est d'où vient le doodle, l'horodatage est le temps. L'étiquette reconnue indique simplement si le réseau de Google a reconnu l'image ou non. Et le dessin lui-même est une séquence, une approximation de la courbe que l'utilisateur dessine avec des points. Et les horaires. Il s'agit du temps écoulé depuis le début du dessin de l'image.
Les données ont été présentées sous deux formats. Il s'agit du premier format et le second est simplifié. Ils ont scié les horaires à partir de là et ont rapproché cet ensemble de points avec un plus petit ensemble de points. Pour ce faire, ils ont utilisé
l'algorithme Douglas-Pecker . Vous disposez d'un large ensemble de points qui se rapproche simplement d'une ligne droite, mais vous pouvez réellement approximer cette ligne avec seulement deux points. C'est l'idée de l'algorithme.
Les données ont été réparties comme suit. Tout est uniforme, mais il y a des valeurs aberrantes. Lorsque nous avons résolu le problème, nous ne l'avons pas examiné. L'essentiel est qu'il n'y avait pas de classes vraiment peu nombreuses, nous n'avions pas à faire d'échantillonneurs pondérés et de suréchantillonnage des données.

À quoi ressemblaient les photos? Il s'agit de la classe d'aéronef et des exemples d'elle sont étiquetés reconnus et non reconnus. Leur rapport était de 1 à 9. Comme vous pouvez le voir, les données sont assez bruyantes. Je dirais que c'est un avion. Si vous regardez non reconnu, dans la plupart des cas, c'est juste du bruit. Quelqu'un a même essayé d'écrire «avion», mais apparemment en français.
La plupart des participants ont simplement pris des grilles, rendu les données de cette séquence de lignes sous forme d'images RVB et les ont jetées dans le réseau. J'ai peint à peu près de la même manière: j'ai pris une palette de couleurs, j'ai peint la première ligne avec une couleur, qui était au début de cette palette, la dernière, avec une autre, qui était à la fin de la palette, et entre elles partout interpolées sur cette palette. Soit dit en passant, cela a donné un meilleur résultat que si vous dessiniez comme sur la toute première diapositive - juste en noir.
D'autres membres de l'équipe, comme Ivan Sosin, ont essayé des approches légèrement différentes du dessin. Avec un canal, il a simplement dessiné une image grise, avec un autre canal, il a dessiné chaque trait avec un dégradé du début à la fin, de 32 à 255, et le troisième canal a dessiné un dégradé dans tous les traits de 32 à 255.
Une autre chose intéressante est qu'Alex Parinov a jeté des informations dans le réseau via countrycode.
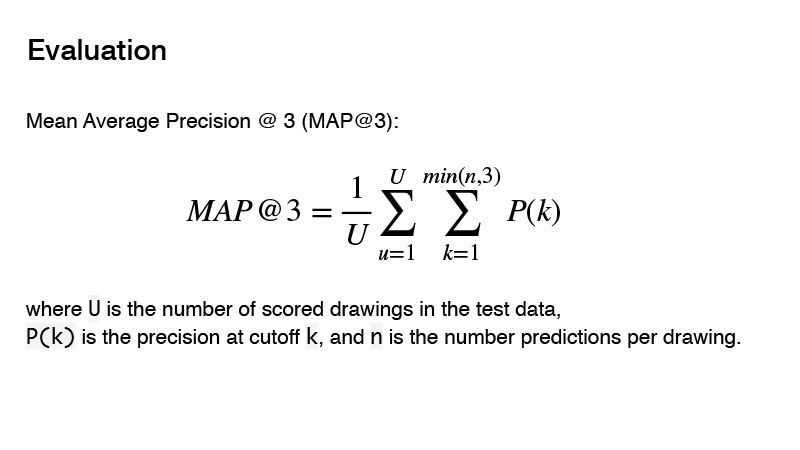
La métrique utilisée dans la compétition est la précision moyenne moyenne. Quelle est l'essence de cette métrique pour la compétition? Vous pouvez donner trois prédicteurs, et si ces trois prédicteurs ne sont pas corrects, alors vous obtenez 0. S'il y en a un correct, alors son ordre est pris en compte. Et le résultat pour la cible sera considéré comme 1, divisé par l'ordre de votre prédiction. Par exemple, vous avez fait trois prédictions, et la première est la bonne, alors vous divisez 1 par 1 et obtenez 1. Si le prédicteur est correct et son ordre est 2, puis 1 divisez par 2, vous obtenez 0,5. Eh bien, etc.

Avec le prétraitement des données - comment dessiner des images, etc. - nous avons décidé un peu. Quelles architectures avons-nous utilisées? Nous avons essayé d'utiliser des architectures audacieuses telles que PNASNet, SENet, et des architectures déjà classiques comme SE-Res-NeXt, elles entrent de plus en plus dans de nouvelles compétitions. Il y avait aussi ResNet et DenseNet.



Comment avons-nous enseigné cela? Tous les modèles que nous avons pris, nous nous sommes pré-formés sur imagenet. Bien qu'il y ait beaucoup de données, 50 millions d'images, mais quand même, si vous prenez un réseau pré-formé sur imagenet, cela a donné un meilleur résultat que si vous le formiez à partir de zéro.
Quelles techniques de formation avons-nous utilisées? Il s'agit d'un recuit de coût avec des redémarrages à chaud, j'en parlerai un peu plus tard. C'est une technique que j'utilise dans la quasi-totalité de mes dernières compétitions, et avec elles ça se passe plutôt bien pour entraîner les filets, pour atteindre un bon minimum.

Ensuite, réduisez le taux d'apprentissage sur le Plateau. Vous commencez à former le réseau, définissez un taux d'apprentissage spécifique, puis apprenez-le, puis votre perte converge progressivement vers une valeur spécifique. Vous vérifiez cela, par exemple, sur dix époques, la perte n'a pas changé. Vous réduisez votre taux d'apprentissage d'une certaine valeur et continuez à apprendre. Il baisse encore un peu, converge à un certain minimum, et encore une fois vous réduisez le taux d'apprentissage, et ainsi de suite, jusqu'à ce que votre réseau converge enfin.
Autre technique intéressante: ne pas diminuer le taux d'apprentissage, augmenter la taille du lot. Il existe un article du même nom. Lorsque vous formez le réseau, vous n'avez pas à diminuer le taux d'apprentissage, vous pouvez simplement augmenter la taille du lot.
Cette technique a d'ailleurs été utilisée par Alex Parinov. Il a commencé avec un lot égal à 408, et lorsque le réseau est arrivé à un plateau, il a simplement doublé la taille du lot, etc.
En fait, je ne me souviens pas de la valeur atteinte par la taille du lot, mais il est intéressant de noter que des équipes de Kaggle ont utilisé la même technique, leur taille de lot était d'environ 10 000. Soit dit en passant, les cadres modernes d'apprentissage en profondeur, tels que PyTorch, par exemple, vous permet de le faire très simplement. Vous générez votre lot et le soumettez au réseau non tel quel, dans son intégralité, mais vous le divisez en morceaux afin qu'il tienne dans votre carte vidéo, comptez les dégradés et après avoir calculé le gradient pour l'ensemble du lot, vous mettez à jour les échelles.
Soit dit en passant, de grandes tailles de lot sont encore arrivées dans ce concours, car les données étaient assez bruyantes, et une grande taille de lot vous a aidé à approximer plus précisément le gradient.
Le pseudo-tamponnage a également été utilisé; pour la plupart, il a été utilisé par Roman Soloviev. Il a échantillonné quelque part dans la moitié des données du test, et sur de tels lots, il a formé la grille.
La taille des images a joué un rôle, mais le fait est que vous avez beaucoup de données, vous devez vous entraîner longtemps et si votre taille d'image est assez grande, vous vous entraînerez très longtemps. Mais cela n'a pas apporté beaucoup dans la qualité de votre classificateur final, donc cela valait la peine d'utiliser un compromis. Et ils n'ont essayé que des photos de très petite taille.
Comment tout cela a-t-il appris? Au début, des photos de petite taille ont été prises, plusieurs époques ont été exécutées dessus, cela a rapidement pris du temps. Ensuite, de grandes images ont été données, le réseau a appris, puis encore plus, encore plus pour ne pas l'entraîner à partir de zéro et ne pas passer beaucoup de temps.
À propos des optimiseurs. Nous avons utilisé SGD et Adam. De cette façon, il était possible d'obtenir un seul modèle, ce qui donnait une vitesse de 0,941-0,946 sur un classement public, ce qui est plutôt bien.
Si vous assemblez des modèles d'une manière ou d'une autre, vous obtenez quelque part 0,951. Si vous appliquez une autre technique, vous obtiendrez la vitesse finale sur le plateau public 0.954, comme nous l'avons reçu. Mais plus à ce sujet plus tard. Ensuite, je vais vous dire comment nous avons assemblé les modèles et comment une telle vitesse finale a été atteinte.
Ensuite, je voudrais parler du recuit de Cosing avec redémarrage à chaud ou de la descente de gradient stochastique avec redémarrage à chaud. En gros, en principe, vous pouvez coller n'importe quel optimiseur, mais le résultat est le suivant: si vous ne formez qu'un seul réseau et qu'il converge progressivement vers un minimum, alors tout va bien, vous obtiendrez un réseau, il fait certaines erreurs, mais vous pouvez lui apprendre un peu différemment. Vous définissez un taux d'apprentissage initial et le réduisez progressivement en fonction de cette formule. Vous le sous-estimez, votre réseau atteint un certain minimum, puis vous économisez des poids, et définissez à nouveau le taux d'apprentissage, qui était au début de la formation, de ce minimum, montez quelque part, et sous-estimez à nouveau votre taux d'apprentissage.
Ainsi, vous pouvez visiter plusieurs creux à la fois, dans lesquels vous aurez la perte plus ou moins la même chose. Mais le fait est que les réseaux avec ces poids donneront des erreurs différentes sur votre date. En les faisant la moyenne, vous obtiendrez une certaine approximation, et votre vitesse sera plus élevée.
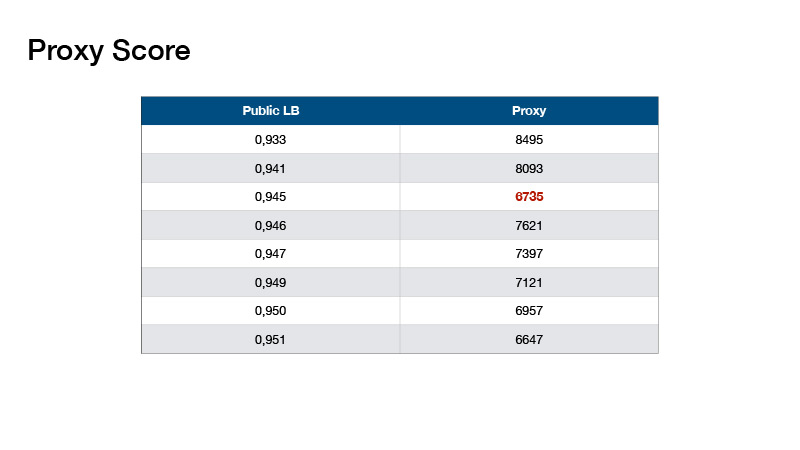
À propos de la façon dont nous avons assemblé nos modèles. Au début de la présentation, j'ai dit de faire attention à la quantité de données dans le test et au nombre de classes. Si vous ajoutez 1 au nombre de cibles dans l'ensemble de test et divisez par le nombre de classes, vous obtenez le nombre 330, et il a été écrit à ce sujet dans le forum - que les classes dans le test sont équilibrées. Cela pourrait être utilisé.
Sur cette base, Roman Solovyov a inventé la métrique, nous l'avons appelée le score proxy, qui correspondait assez bien au classement. L'essentiel est: vous faites une prédiction, prenez le top 1 de vos prédictions et comptez le nombre d'objets pour chaque classe. Soustrayez 330 de chaque valeur et ajoutez les valeurs absolues résultantes.
De telles valeurs se sont avérées. Cela nous a aidés à ne pas faire un classement des tests, mais à valider localement et sélectionner des coefficients pour nos ensembles.
Avec l'ensemble, vous pourriez obtenir une telle vitesse. Que faire d'autre? Supposons que vous ayez utilisé les informations selon lesquelles les classes de votre test sont équilibrées.
L'équilibrage était différent.
Un exemple de l'un d'eux est l'équilibre entre les gars qui ont remporté la première place.
Qu'avons-nous fait? Notre équilibrage était assez simple, il a été proposé par Evgeny Babakhnin. Nous avons d'abord trié nos prédictions par top-1 et sélectionné des candidats - afin que le nombre de classes ne dépasse pas 330. Mais pour certaines classes, il s'avère qu'il y a moins de prédictions que 330. D'accord, trions par top-2 et top 3, et aussi choisir des candidats.
En quoi notre équilibrage différait-il de l'équilibre en premier lieu? Ils ont utilisé une approche itérative, pris la classe la plus populaire et réduit les probabilités pour cette classe d'un petit nombre - jusqu'à ce que cette classe ne devienne pas la plus populaire. Ils ont suivi le cours suivant le plus populaire. Donc plus loin et plus bas jusqu'à ce que le nombre de toutes les classes devienne égal.
Tout le monde a utilisé une approche plus ou moins une pour former les réseaux, mais tout le monde n'a pas utilisé l'équilibrage. En utilisant l'équilibrage, vous pourriez aller dans l'or, et si vous étiez chanceux, puis dans mani.
Comment prétraiter une date? Tout le monde a prétraité la date plus-moins de la même manière - a fait des fonctionnalités artisanales, a essayé d'encoder des timings avec des traits de couleur différents, etc. C'est exactement ce qu'a dit Alexey Nozdrin-Plotnitsky, qui a pris la 8ème place.

Il a fait différemment. Il a dit que toutes ces fonctionnalités artisanales ne fonctionnent pas, vous n'avez pas besoin de le faire, votre réseau doit apprendre tout cela vous-même. Et à la place, il est venu avec des modules d'apprentissage qui ont fait le prétraitement de vos données. Il y a jeté les données source sans prétraitement - les coordonnées des points et des timings.
De plus, il a pris la différence dans les coordonnées et l'a moyennée sur les timings. Et il a obtenu une matrice assez longue. Il a utilisé la convolution 1D plusieurs fois pour obtenir une matrice 64xn, où n est le nombre total de points, et 64 est fait afin d'alimenter la matrice résultante en une couche d'un réseau convolutionnel qui accepte 64 canaux. il s'est avéré être une matrice 64xn, puis il a fallu composer un tenseur d'une certaine taille pour que le nombre de canaux soit de 64. Il a normalisé tous les points X, Y dans la plage de 0 à 32 pour faire un tenseur de taille 32x32. Je ne sais pas pourquoi il voulait du 32x32, c'est arrivé. Et dans cette coordonnée, il a mis un fragment de cette matrice de taille 64xn. Ainsi, il a simplement reçu le tenseur 32x32x64, qui pourrait être mis plus loin dans votre réseau neuronal convolutionnel. J'ai tout.