Bonjour, Habr! Je vous présente la traduction de l'article
«Tout ce que vous devez savoir sur les diagrammes de dispersion pour la visualisation des données» de George Seif.
Si vous êtes engagé dans l'analyse et la visualisation de données, vous devrez probablement traiter avec des diagrammes de dispersion. Malgré leur simplicité, les diagrammes de dispersion sont un outil puissant pour visualiser les données. En manipulant les couleurs, les tailles et les formes, la flexibilité et la représentativité des diagrammes de dispersion peuvent être assurées.
Dans cet article, vous apprendrez presque tout ce que vous devez savoir sur la visualisation des données à l'aide de diagrammes de dispersion. Nous allons essayer d'analyser tous les paramètres nécessaires dans leur utilisation en code python. Vous pouvez également trouver des astuces pratiques.
Bâtiment de régression
Même l'utilisation la plus primitive d'un diagramme de dispersion donne déjà un bon aperçu de nos données. Dans la figure 1, nous pouvons déjà voir des îlots de données combinées et identifier rapidement les valeurs aberrantes.
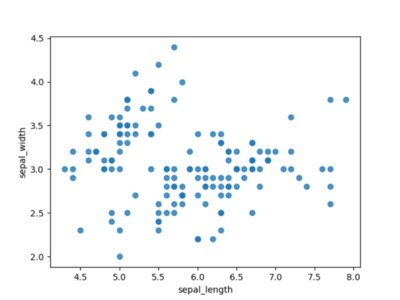 Figure 1
Figure 1
Des lignes de régression appropriées simplifient visuellement la tâche d'identification des points proches du milieu. Dans la figure 2, nous avons tracé un graphique linéaire. Il est assez facile de voir que dans ce cas la fonction linéaire n'est pas représentative, car de nombreux points sont assez éloignés de la ligne.
 Figure 2
Figure 2
La figure 3 utilise un polynôme d'ordre 4 et semble beaucoup plus prometteuse. Il semble que pour modéliser cet ensemble de données, nous avons certainement besoin d'un polynôme d'ordre 4.
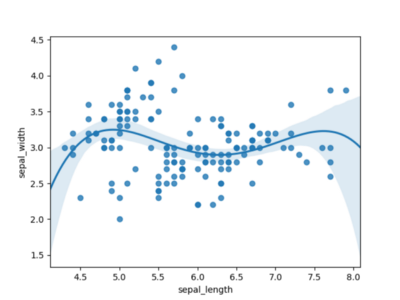 Figure 3
Figure 3
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Couleur et forme des points
La couleur et la forme peuvent être utilisées pour visualiser les différentes catégories de votre jeu de données. La couleur et la forme sont visuellement très claires. Lorsque vous regardez un graphique où des groupes de points ont des couleurs différentes de nos formes, il devient immédiatement évident que les points appartiennent à différents groupes.
La figure 4 montre les classes regroupées par couleur. La figure 5 montre les classes, séparées par la couleur et la forme. Dans les deux cas, il est beaucoup plus facile de voir le regroupement. Maintenant, nous savons qu'il sera facile de séparer la classe
setosa et sur quoi nous devrions nous concentrer. Il est également clair qu'un graphique à une seule ligne ne pourra pas séparer les points verts et orange. Par conséquent, nous devons ajouter quelque chose pour afficher plus de dimensions.
Le choix entre la couleur et la forme devient une question de préférence. Personnellement, je trouve la couleur un peu plus claire et plus intuitive, mais le choix vous appartient toujours.
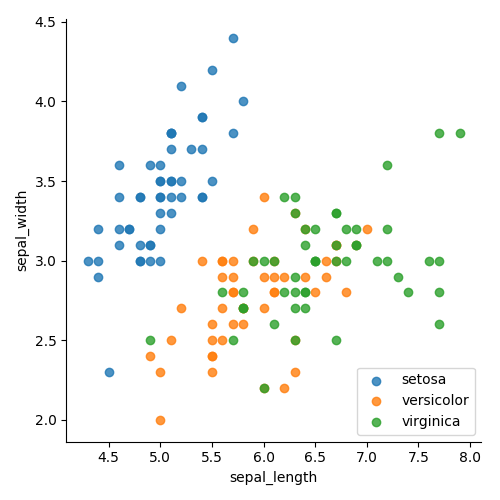 Figure 4
Figure 4
 Figure 5
Figure 5
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Histogramme marginal
Un exemple de graphique avec des histogrammes marginaux est illustré à la figure 6. Des histogrammes marginaux sont superposés en haut et sur le côté, représentant la distribution des points des objets le long de l'abscisse et des ordonnées. Ce petit ajout est idéal pour repérer la distribution des points et les valeurs aberrantes.
Par exemple, dans la figure 6, nous voyons évidemment une forte concentration de points autour du balisage 3.0. Et grâce à cet histogramme, vous pouvez déterminer le niveau de concentration. Sur le côté droit, vous pouvez voir que autour du balisage 3.0, il y a au moins trois fois plus de points que pour toute autre plage discrète. En outre, en utilisant l'histogramme de droite, on peut clairement reconnaître que les valeurs aberrantes évidentes sont au-dessus de la marque de 3,75. Le diagramme supérieur montre que la distribution des points le long de l'axe X est plus uniforme, à l'exception des valeurs aberrantes dans le coin le plus à droite.
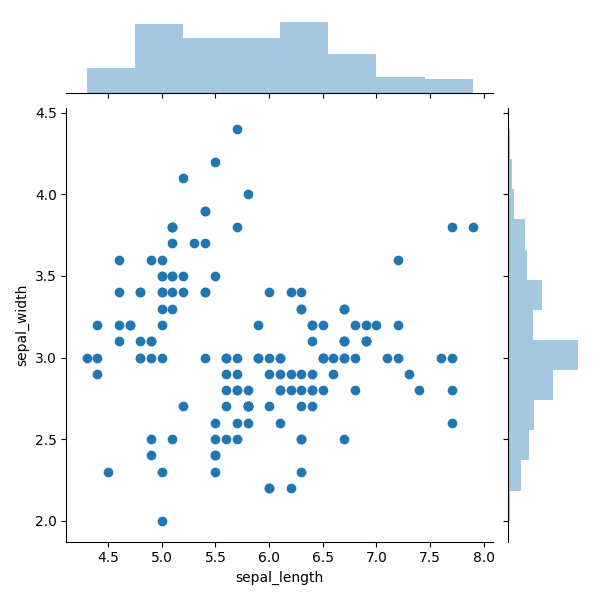 Figure 6
Figure 6
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='scatter') plt.show()
Graphiques à bulles
À l'aide de graphiques à bulles, nous devons utiliser plusieurs variables pour coder les informations. Le nouveau paramètre inhérent à ce type de visualisation est la taille. Dans la figure 7, nous montrons la quantité de frites consommée par la taille et le poids des personnes qui ont mangé. Veuillez noter qu'un diagramme de dispersion n'est qu'un outil de visualisation à deux dimensions, mais lorsque vous utilisez des graphiques à bulles, nous pouvons afficher habilement des informations en trois dimensions.
Ici, nous utilisons la
couleur, la position et la taille , où la position des bulles détermine la taille et le poids de la personne, la couleur détermine le sexe et la taille est déterminée par la quantité de frites mangées. Le graphique à bulles nous permet facilement de combiner facilement tous les attributs en un seul graphique afin que nous puissions voir des informations de grande taille sous une forme bidimensionnelle.
 Figure 7
Figure 7
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches x = np.array([100, 105, 110, 124, 136, 155, 166, 177, 182, 196, 208, 230, 260, 294, 312]) y = np.array([54, 56, 60, 60, 60, 72, 62, 64, 66, 80, 82, 72, 67, 84, 74]) z = (x*y) / 60 for index, val in enumerate(z): if index < 10: color = 'g' else: color = 'r' plt.scatter(x[index], y[index], s=z[index]*5, alpha=0.5, c=color) red_patch = mpatches.Patch(color='red', label='Male') green_patch = mpatches.Patch(color='green', label='Female') plt.legend(handles=[green_patch, red_patch]) plt.title("French fries eaten vs height and weight") plt.xlabel("Weight (pounds)") plt.ylabel("Height (inches)") plt.show()