Dodo IS est un système mondial qui vous aide à gérer efficacement votre entreprise chez Dodo Pizza. Il résout les problèmes de commande de pizza, aide le franchisé à suivre l'entreprise, améliore l'efficacité des employés et parfois tombe. Le dernier est le pire pour nous. Chaque minute de telles chutes entraîne une perte de profits, une insatisfaction des utilisateurs et des nuits blanches de développeurs.
Mais maintenant, nous dormons mieux. Nous avons appris à reconnaître les scénarios d'apocalypse systémique et à les traiter. Ci-dessous, je vais vous expliquer comment nous assurons la stabilité du système.

Une série d'articles sur l'effondrement du système Dodo IS * :
1. Le jour où Dodo IS s'est arrêté. Script synchrone.
2. Le jour où Dodo IS s'est arrêté. Script asynchrone.
* Les matériaux ont été écrits sur la base de ma performance à DotNext 2018 à Moscou .
Dodo est
Le système est un grand avantage concurrentiel de notre franchise, car les franchisés ont un modèle commercial prêt à l'emploi. Ce sont ERP, HRM et CRM, tout en un.
Le système est apparu quelques mois après l'ouverture de la première pizzeria. Il est utilisé par les gestionnaires, les clients, les caissiers, les cuisiniers, les clients mystères, les employés des centres d'appels - c'est tout. Classiquement, Dodo IS est divisé en deux parties. Le premier est destiné aux clients. Cela comprend un site Web, une application mobile, un centre de contact. Deuxième partenaire franchisé, il permet de gérer les pizzerias. Grâce au système, les factures des fournisseurs, la gestion du personnel, les personnes qui travaillent, la comptabilité de paie automatique, la formation en ligne du personnel, la certification des gestionnaires, un système de contrôle de la qualité et les acheteurs mystères transitent par le système.
Performances du système
Performances du système Dodo IS = fiabilité = tolérance aux pannes / récupération. Arrêtons-nous sur chacun des points.
Fiabilité
Nous n'avons pas de grands calculs mathématiques: nous devons traiter un certain nombre de commandes, il y a certaines zones de livraison. Le nombre de clients ne varie pas particulièrement. Bien sûr, nous serons heureux quand il grandira, mais cela se produit rarement par grandes rafales. Pour nous, les performances se résument au peu de pannes, à la fiabilité du système.
Tolérance aux pannes
Un composant peut dépendre d'un autre composant. Si une erreur se produit dans un système, l'autre sous-système ne doit pas tomber.
La résilience
Des pannes de composants individuels se produisent chaque jour. C'est normal. Il est important de savoir à quelle vitesse nous pouvons nous remettre d'un échec.
Scénario de défaillance du système synchrone
Qu'est ce que c'est
L'instinct d'une grande entreprise est de servir de nombreux clients en même temps. Tout comme il est impossible de travailler pour une pizzeria de cuisine travaillant pour la livraison de la même manière qu'une femme au foyer dans une cuisine à domicile, un code conçu pour une exécution synchrone ne peut pas fonctionner correctement pour un service client de masse sur un serveur.
Il existe une différence fondamentale entre l'exécution d'un algorithme dans une seule instance et l'exécution du même algorithme qu'un serveur dans un service de masse.
Jetez un oeil à l'image ci-dessous. À gauche, nous voyons comment les demandes se produisent entre deux services. Ce sont des appels RPC. La demande suivante se termine après la précédente. De toute évidence, cette approche n'est pas évolutive - des commandes supplémentaires sont alignées.
Pour servir de nombreuses commandes, nous avons besoin de la bonne option:
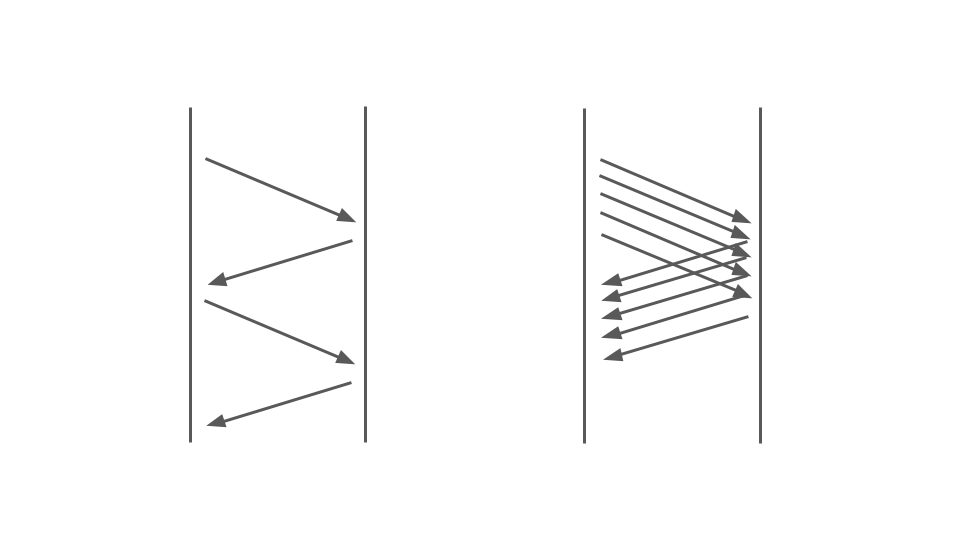
Le fonctionnement du blocage de code dans une application synchrone est fortement affecté par le modèle de multithreading utilisé, à savoir le multitâche préemptif. Elle seule peut conduire à des échecs.
Le multitâche simplifié et préemptif pourrait être illustré comme suit:

Les blocs de couleur sont le vrai travail que fait le CPU, et nous voyons que le travail utile indiqué par le vert dans le diagramme est assez petit dans le contexte général. Nous devons éveiller le flux, l'endormir, et cela est au-dessus. Un tel sommeil / réveil se produit pendant la synchronisation sur toutes les primitives de synchronisation.
De toute évidence, les performances du processeur diminueront si vous diluez le travail utile avec un grand nombre de synchronisations. Dans quelle mesure le multitâche préemptif peut-il affecter les performances?
Considérez les résultats d'un test synthétique:
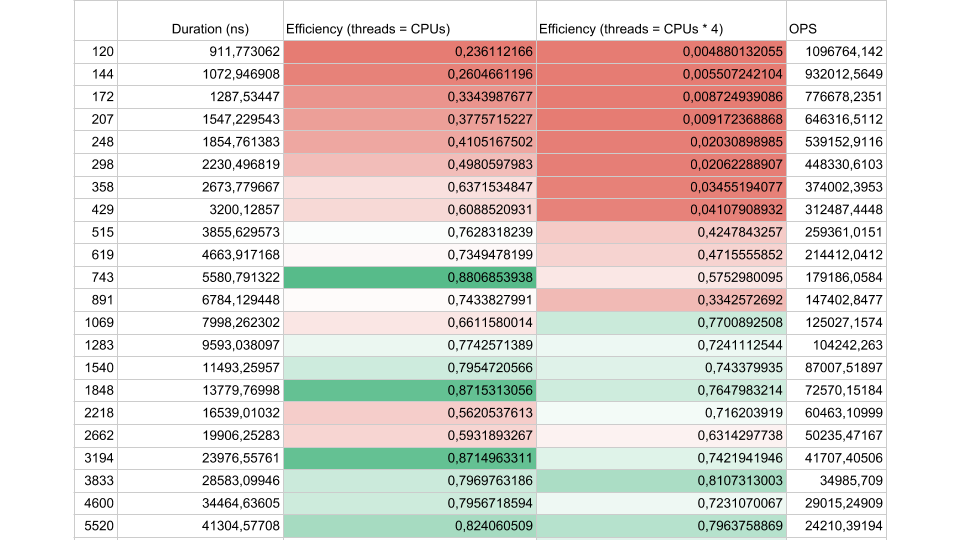
Si l'intervalle de flux entre les synchronisations est d'environ 1 000 nanosecondes, l'efficacité est assez faible, même si le nombre de threads est égal au nombre de cœurs. Dans ce cas, l'efficacité est d'environ 25%. Si le nombre de threads est 4 fois supérieur, l'efficacité chute considérablement, à 0,5%.
Pensez-y, dans le cloud, vous avez commandé une machine virtuelle avec 72 cœurs. Cela coûte de l'argent et vous utilisez moins de la moitié d'un cœur. C'est exactement ce qui peut arriver dans une application multi-thread.
S'il y a moins de tâches, mais que leur durée est plus longue, l'efficacité augmente. Nous voyons qu'à 5000 opérations par seconde, dans les deux cas, l'efficacité est de 80 à 90%. Pour un système multiprocesseur, c'est très bien.
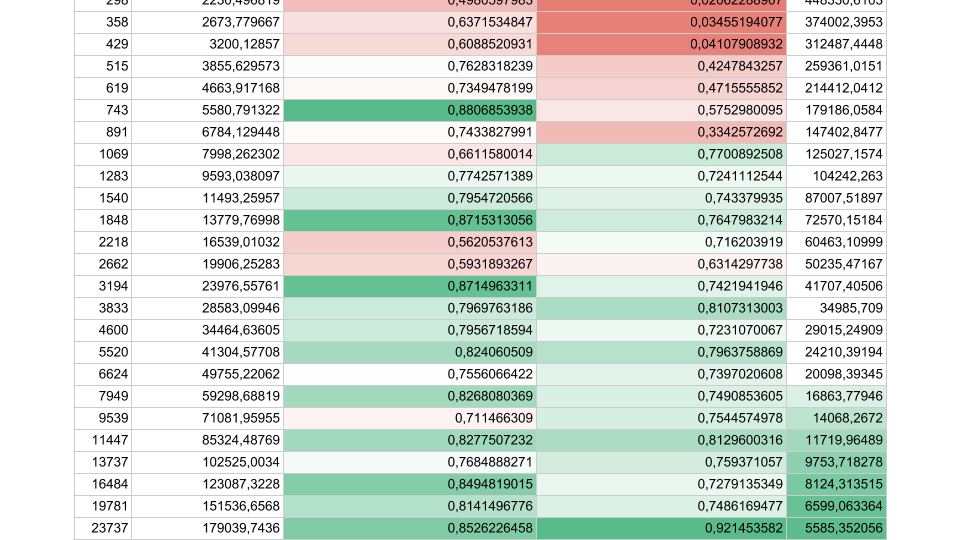
Dans nos applications réelles, la durée d'une opération entre les synchronisations se situe quelque part entre les deux, donc le problème est urgent.
Que se passe-t-il?
Faites attention au résultat des tests de résistance. Dans ce cas, il s'agissait des «tests d'extrusion».
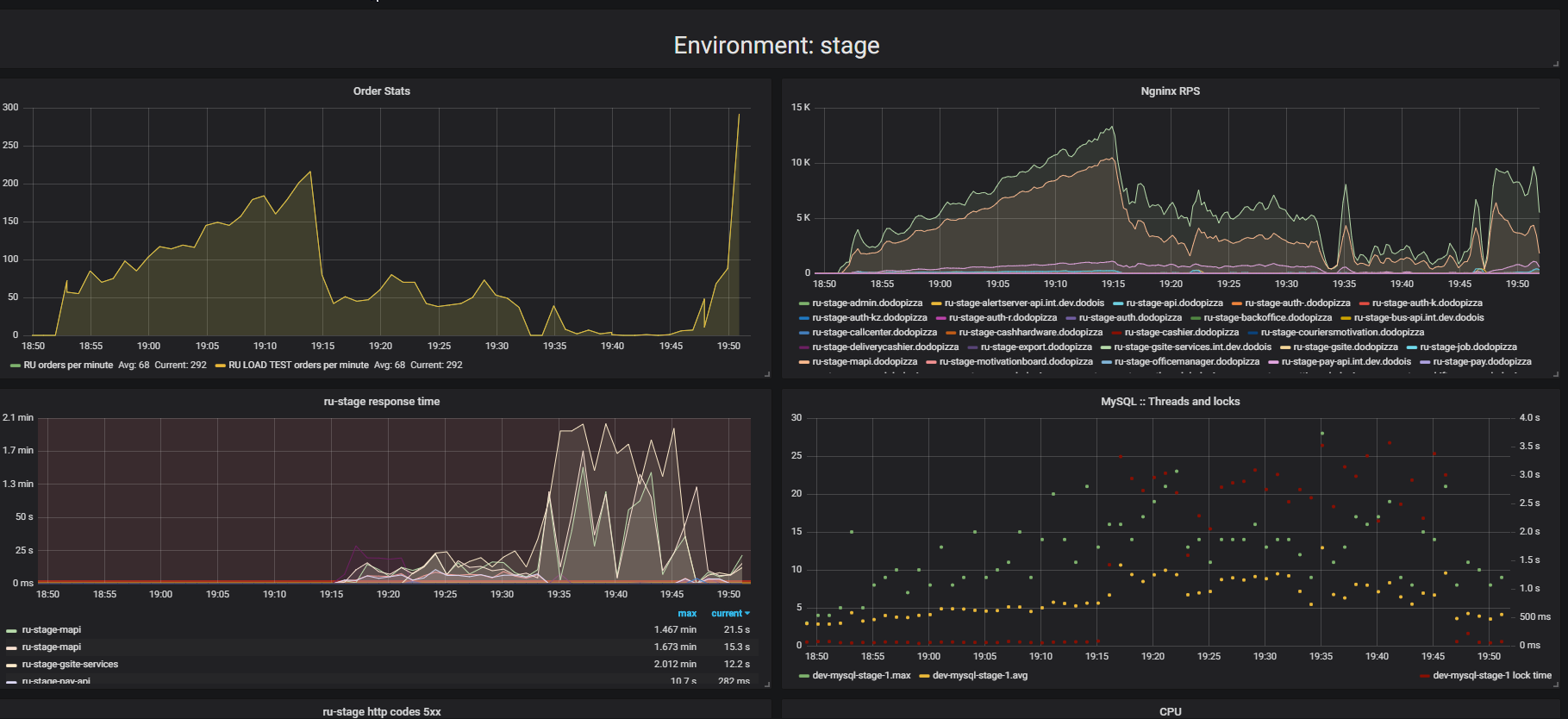
L'essence du test est qu'en utilisant un support de charge, nous soumettons de plus en plus de demandes artificielles au système, essayons de passer autant de commandes que possible par minute. Nous essayons de trouver la limite après laquelle l'application refusera de répondre aux demandes au-delà de ses capacités. Intuitivement, nous nous attendons à ce que le système fonctionne à la limite, rejetant les demandes supplémentaires. C'est exactement ce qui se passerait dans la vraie vie, par exemple - lorsque vous servez dans un restaurant bondé de clients. Mais il se passe autre chose. Les clients ont passé plus de commandes et le système a commencé à servir moins. Le système a commencé à servir si peu de commandes qu'il peut être considéré comme une panne complète, une panne. Cela se produit avec de nombreuses applications, mais devrait-il en être ainsi?
Dans le deuxième graphique, le temps de traitement d'une demande augmente, pendant cet intervalle, moins de demandes sont traitées. Les demandes arrivées plus tôt sont traitées bien plus tard.
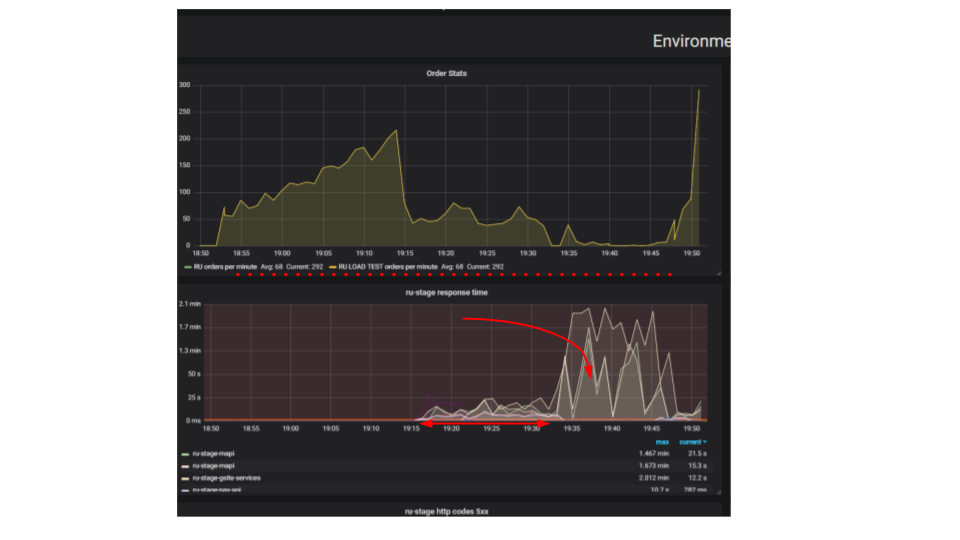
Pourquoi l'application s'arrête-t-elle? Il y avait un algorithme, ça a marché. On le démarre depuis notre machine locale, ça marche très vite. Nous pensons que si nous prenons une machine cent fois plus puissante et exécutons cent requêtes identiques, elles doivent être exécutées en même temps. Il s'avère que les demandes de différents clients entrent en collision. Entre eux, des conflits surviennent et il s'agit d'un problème fondamental dans les applications distribuées. Des demandes séparées se battent pour des ressources.
Comment trouver un problème
Si le serveur ne fonctionne pas, nous essaierons tout d'abord de trouver et de résoudre les problèmes triviaux des verrous à l'intérieur de l'application, dans la base de données et lors des E / S sur les fichiers. Il y a encore toute une classe de problèmes dans le réseautage, mais jusqu'à présent, nous nous limiterons à ces trois, cela suffit pour apprendre à reconnaître des problèmes similaires, et nous nous intéressons principalement aux problèmes qui causent la Contention - la lutte pour les ressources.
Verrous en cours
Voici une demande typique dans une application de blocage.
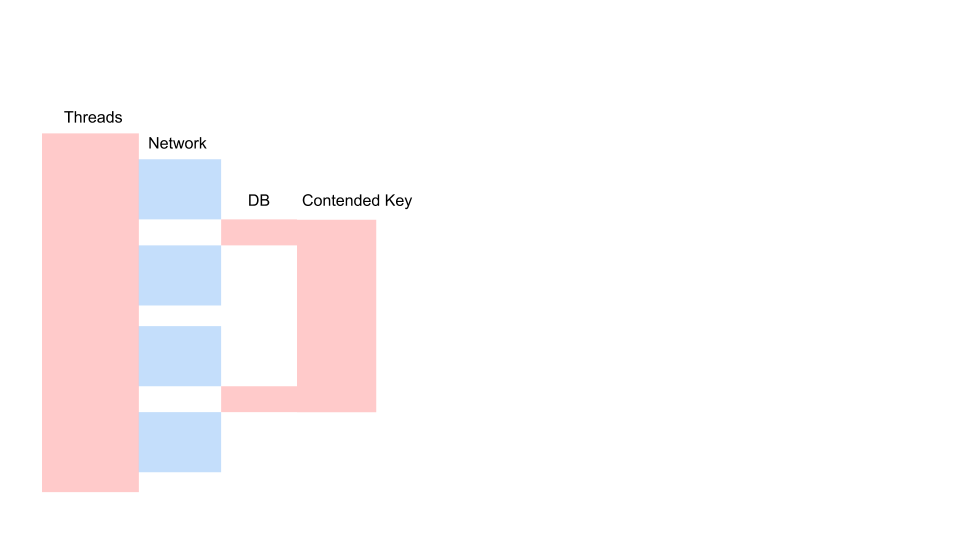
Il s'agit d'une variante du diagramme de séquence qui décrit l'algorithme d'interaction du code d'application et de la base de données à la suite d'une opération conditionnelle. Nous voyons qu'un appel réseau est en cours, puis quelque chose se passe dans la base de données - la base de données est légèrement utilisée. Ensuite, une autre demande est faite. Pour toute la période, une transaction dans la base de données et une clé commune à toutes les requêtes sont utilisées. Il peut s'agir de deux clients différents ou de deux commandes différentes, mais d'un même objet de menu de restaurant, stocké dans la même base de données que les commandes clients. Nous travaillons en utilisant une transaction pour la cohérence; deux requêtes ont Contention sur la clé de l'objet commun.
Voyons comment ça évolue.
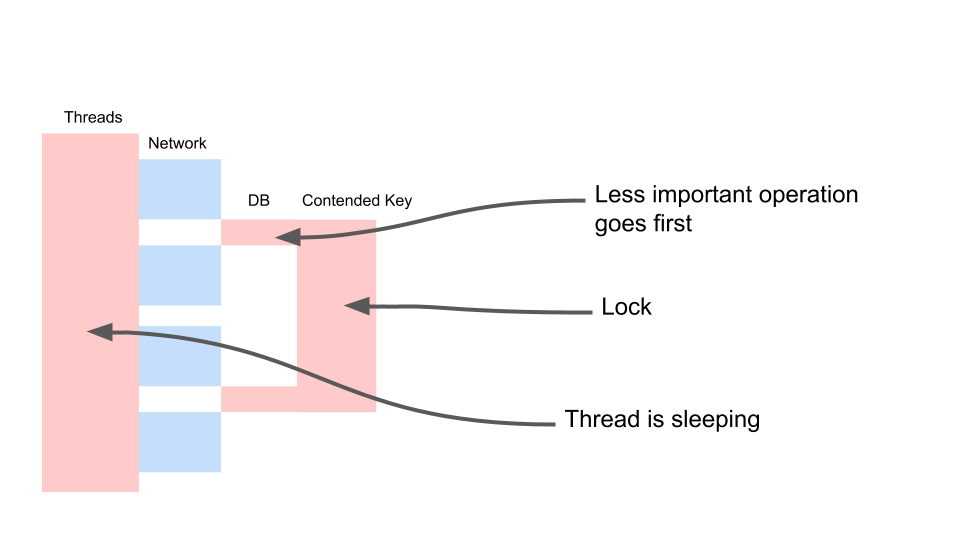
Le fil dort la plupart du temps. En fait, il ne fait rien. Nous avons un verrou qui interfère avec d'autres processus. Le plus ennuyeux est que l'opération la moins utile dans une transaction qui a verrouillé une clé se produit au tout début. Il allonge les transactions de portée dans le temps.
Nous allons nous battre de cette façon.
var fallback = FallbackPolicy<OptionalData> .Handle<OperationCancelledException>() .FallbackAsync<OptionalData>(OptionalData.Default); var optionalDataTask = fallback .ExecuteAsync(async () => await CalculateOptionalDataAsync());
C'est la cohérence éventuelle. Nous supposons que certaines de nos données peuvent être moins récentes. Pour ce faire, nous devons travailler différemment avec le code. Nous devons accepter que les données sont d'une qualité différente. Nous ne regarderons pas ce qui s'est passé auparavant - le gestionnaire a changé quelque chose dans le menu ou le client a cliqué sur le bouton «Commander». Pour nous, peu importe qui a appuyé sur le bouton deux secondes plus tôt. Et pour les affaires, il n'y a pas de différence.
Il n'y a aucune différence, nous pouvons faire une telle chose. Appelez-le conditionnellement facultatifData. Autrement dit, une valeur dont nous pouvons nous passer. Nous avons un repli - la valeur que nous prenons du cache ou passons une valeur par défaut. Et pour l'opération la plus importante (la variable requise) nous attendrons. Nous l'attendrons fermement, et alors seulement nous attendrons une réponse aux demandes de données facultatives. Cela nous permettra d'accélérer le travail. Il y a un autre point important - cette opération peut ne pas être effectuée du tout pour une raison quelconque. Supposons que le code de cette opération ne soit pas optimal et qu'il existe actuellement un bogue. Si l'opération a échoué, faites un repli. Et puis nous travaillons avec cela comme avec le sens habituel.
Serrures DB
Nous obtenons approximativement la même disposition lorsque nous avons réécrit sur async et changé le modèle de cohérence.
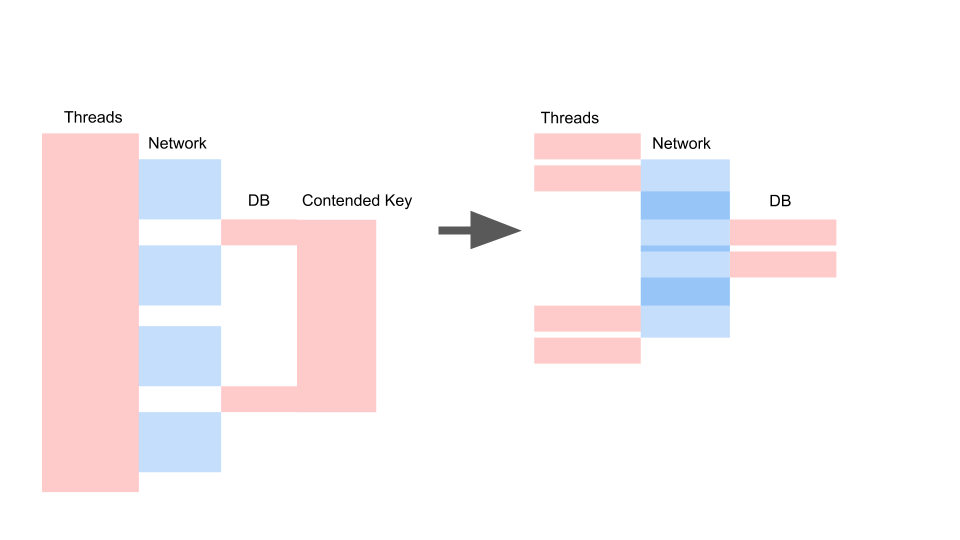
Ce qui importe ici, ce n'est pas que la demande soit devenue plus rapide dans le temps. L'important, c'est que nous n'avons pas de Contention. Si nous ajoutons des demandes, alors seul le côté gauche de l'image est saturé de nous.
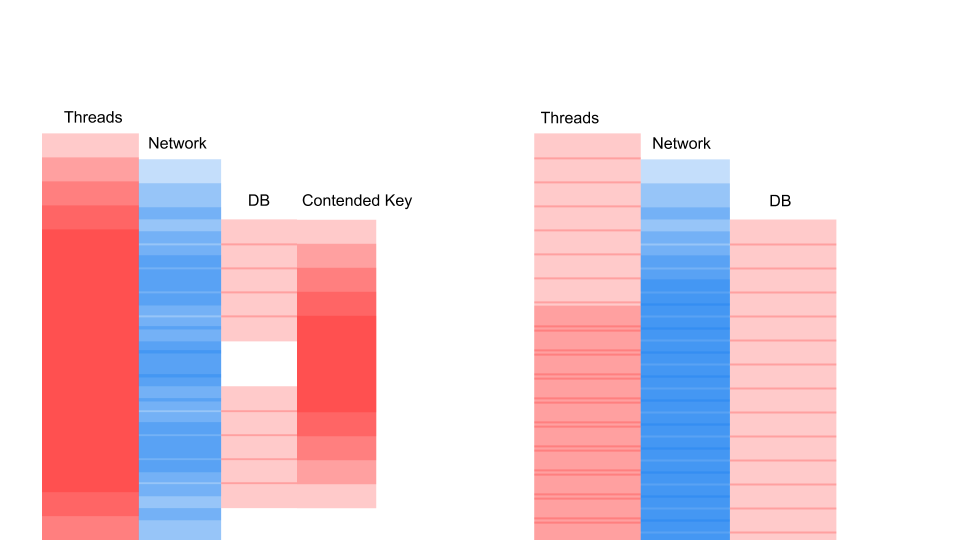
Il s'agit d'une demande de blocage. Ici, les threads se chevauchent et les clés sur lesquelles se produit la contention. À droite, nous n'avons aucune transaction dans la base de données et elles sont exécutées tranquillement. Le bon cas peut fonctionner indéfiniment dans ce mode. Gauche entraînera le crash du serveur.
Sync io
Parfois, nous avons besoin de journaux de fichiers. Étonnamment, le système d'enregistrement peut donner lieu à de telles défaillances désagréables. Latence sur le disque dans Azure - 5 millisecondes. Si nous écrivons un fichier dans une rangée, ce n'est que 200 requêtes par seconde. Ça y est, l'application s'est arrêtée.

C'est juste que vos cheveux se terminent lorsque vous voyez cela - plus de 2000 threads ont été créés dans l'application. 78% de tous les threads sont la même pile d'appels. Ils se sont arrêtés au même endroit et tentent d'entrer dans le moniteur. Ce moniteur délimite l'accès au fichier où nous nous connectons tous. Bien sûr, cela doit être coupé.

Voici ce que vous devez faire dans NLog pour le configurer. Nous créons une cible asynchrone et y écrivons. Et la cible asynchrone écrit dans le vrai fichier. Bien sûr, nous pouvons perdre une certaine quantité de messages dans le journal, mais qu'est-ce qui est plus important pour les entreprises? Lorsque le système est tombé pendant 10 minutes, nous avons perdu un million de roubles. Il est probablement préférable de perdre plusieurs messages dans le journal de service, qui ont échoué et redémarré.
Tout va très mal
La contention est un gros problème dans les applications multithread, qui ne vous permet pas simplement de mettre à l'échelle une application monothread. Les sources de conflits doivent être en mesure d'identifier et d'éliminer. Un grand nombre de threads sont désastreux pour les applications et les appels bloquants doivent être réécrits en async.
J'ai dû réécrire beaucoup d'héritage en bloquant les appels sur async, j'ai moi-même souvent initié une telle mise à niveau. Très souvent, quelqu'un arrive et demande: «Écoutez, nous réécrivons depuis deux semaines maintenant, presque tous en mode asynchrone. Et combien cela fonctionnera plus vite? " Les gars, je vais vous bouleverser - ça ne marchera pas plus vite. Cela deviendra encore plus lent. Après tout, le TPL est un modèle compétitif au-dessus d'un autre - le multitâche coopératif plutôt que le multitâche préemptif, et c'est une surcharge. Dans l'un de nos projets - environ + 5% d'utilisation du CPU et de charge sur GC.
Il y a une autre mauvaise nouvelle: l'application peut fonctionner bien pire après une simple réécriture sur async, sans se rendre compte des fonctionnalités du modèle concurrentiel. Je parlerai de ces fonctionnalités en détail dans le prochain article.
Cela soulève la question - est-il nécessaire de réécrire?
Le code synchrone est réécrit sur async afin de débloquer le modèle de concurrence et de se débarrasser du modèle multitâche préemptif. Nous avons vu que le nombre de threads peut nuire aux performances, vous devez donc vous libérer de la nécessité d'augmenter le nombre de threads pour augmenter la concurrence. Même si nous avons Legacy, et nous ne voulons pas réécrire ce code - c'est la principale raison de le réécrire.
La bonne nouvelle à la fin est que nous savons maintenant quelque chose sur la façon de se débarrasser des problèmes triviaux de Contention de blocage de code. Si vous rencontrez de tels problèmes dans votre application de blocage, il est temps de vous en débarrasser avant de réécrire sur async, car ils ne disparaîtront pas d'eux-mêmes.