L'infographie, comme vous le savez, est à la base de l'industrie du jeu. Dans le processus de création de contenu graphique, nous rencontrons inévitablement des difficultés liées à la différence de sa présentation dans l'environnement de création et dans l'application. A ces difficultés s'ajoutent les risques de simple négligence humaine. Compte tenu de l'ampleur du développement du jeu, de tels problèmes surviennent fréquemment ou en grand nombre.
Lutter contre de telles difficultés nous a conduit à penser à l'automatisation et à écrire des articles sur ce sujet. La plupart du matériel traitera de l'utilisation de
Unity 3D , car il s'agit du principal outil de développement de Plarium Krasnodar. Ci-après, les modèles et textures 3D seront considérés comme du contenu graphique.
Dans cet article, nous parlerons des fonctionnalités d'accès aux données représentant des objets 3D dans
Unity . Le matériel sera utile principalement aux débutants, ainsi qu'aux développeurs qui interagissent rarement avec la représentation interne de ces modèles.

À propos des modèles 3D dans Unity - pour les plus petits
Dans l'approche standard,
Unity utilise les composants
MeshFilter et
MeshRenderer pour rendre le modèle. MeshFilter fait référence à l'actif
Mesh qui représente le modèle. Pour la plupart des shaders, les informations de géométrie sont un composant minimum obligatoire pour le rendu d'un modèle à l'écran. Les données de scan de texture et les os d'animation peuvent ne pas être disponibles s'ils ne sont pas impliqués. Comment cette classe est implémentée à l'intérieur et comment tout est stocké, il y a un mystère pour la
nième somme d'argent dans sept sceaux.
À l'extérieur, le maillage en tant qu'objet donne accès aux jeux de données suivants:
- sommets - un ensemble de positions de sommets géométriques dans un espace tridimensionnel avec sa propre origine;
- normales, tangentes - ensembles de vecteurs normaux et tangents aux sommets qui sont couramment utilisés pour calculer l'éclairage;
- uv, uv2, uv3, uv4, uv5, uv6, uv7, uv8 - jeux de coordonnées pour le balayage de texture;
- couleurs, couleurs32 - ensembles de valeurs de couleur des sommets, dont un exemple classique consiste à mélanger la texture par masque;
- bindposes - ensembles de matrices pour positionner les sommets par rapport aux os;
- boneWeights - coefficients d'influence des os sur les sommets;
- triangles - un ensemble d'indices de sommets traités 3 à la fois; chacun de ces triples représente un polygone (dans ce cas, un triangle) du modèle.
L'accès aux informations sur les sommets et les polygones est implémenté via les propriétés correspondantes, chacune renvoyant un tableau de structures. Pour une personne qui
ne lit pas la documentation travaille rarement avec des maillages dans
Unity , il peut ne pas être évident que chaque fois que les données de sommet sont accédées, une copie de l'ensemble correspondant est créée en mémoire sous la forme d'un tableau d'une longueur égale au nombre de sommets. Cette nuance est considérée dans un petit
bloc de documentation . Les commentaires sur les propriétés de la classe
Mesh mentionnés ci-dessus le mettent également en garde. La raison de ce comportement est la fonctionnalité architecturale
Unity dans le contexte du runtime
Mono . Schématiquement, cela peut être représenté comme suit:
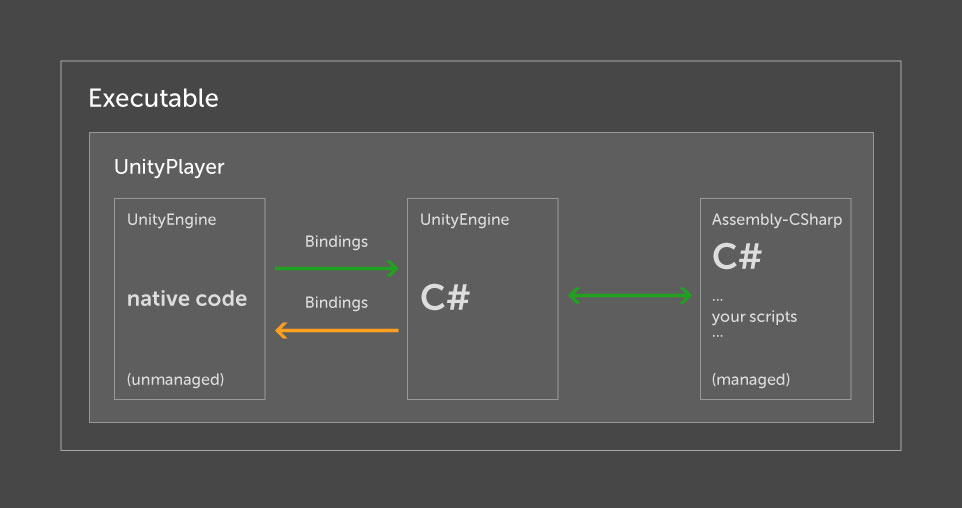
Le cœur du moteur (UnityEngine (natif)) est isolé des scripts de développement et l'accès à ses fonctionnalités est implémenté via la bibliothèque UnityEngine (C #). En fait, c'est un adaptateur, car la plupart des méthodes servent de couche pour recevoir des données du noyau. Dans ce cas, le noyau et le reste, y compris vos scripts, tournent sous différents processus et la partie script ne connaît que la liste des commandes. Ainsi, il n'y a pas d'accès direct à la mémoire utilisée par le noyau depuis le script.
À propos de l'accès aux données internes ou de la gravité des problèmes
Pour montrer à quel point les choses peuvent être mauvaises, analysons la quantité de mémoire effacée par Garbage Collector à l'aide d'un exemple de la documentation. Pour simplifier le profilage, encapsulez le même code dans la méthode Update.
public class MemoryTest : MonoBehaviour { public Mesh Mesh; private void Update() { for (int i = 0; i < Mesh.vertexCount; i++) { float x = Mesh.vertices[i].x; float y = Mesh.vertices[i].y; float z = Mesh.vertices[i].z; DoSomething(x, y, z); } } private void DoSomething(float x, float y, float z) {
Nous avons exécuté ce script avec une primitive standard - une sphère (515 sommets). À l'aide de l'outil
Profileur , dans l'onglet
Mémoire , vous pouvez voir la quantité de mémoire qui a été marquée pour le nettoyage de la mémoire dans chaque cadre. Sur notre machine de travail, cette valeur était de ~ 9,2 Mo.
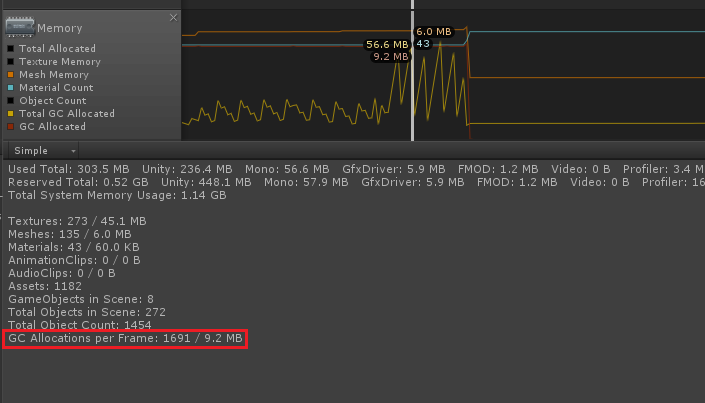
C'est beaucoup, même pour une application chargée, et ici nous avons lancé une scène avec un objet sur lequel le script le plus simple est monté.
Il est important de mentionner les fonctionnalités du compilateur
.Net et l'optimisation du code. En parcourant la chaîne d'appels, vous constaterez que l'appel à
Mesh.vertices implique d'appeler la méthode
externe du moteur. Cela empêche le compilateur d'optimiser le code à l'intérieur de notre méthode
Update () , malgré le fait que
DoSomething () est vide et les variables
x, y, z ne sont pas utilisées pour cette raison.
Maintenant, nous mettons en cache le tableau de positions au début.
public class MemoryTest : MonoBehaviour { public Mesh Mesh; private Vector3[] _vertices; private void Start() { _vertices = Mesh.vertices; } private void Update() { for (int i = 0; i < _vertices.Length; i++) { float x = _vertices[i].x; float y = _vertices[i].y; float z = _vertices[i].z; DoSomething(x, y, z); } } private void DoSomething(float x, float y, float z) {
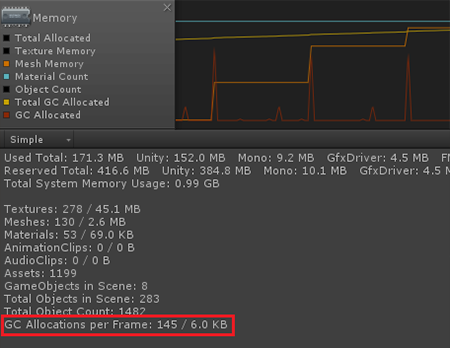
En moyenne 6 Ko. Une autre chose!
Cette fonctionnalité est devenue l'une des raisons pour lesquelles nous avons dû implémenter notre propre structure de stockage et de traitement des données de maillage.
Comment on fait
Lors des travaux sur de grands projets, l'idée est née de créer un outil d'analyse et d'édition de contenu graphique importé. Nous discuterons des méthodes d'analyse et de transformation dans les articles suivants. Examinons maintenant la structure de données que nous avons décidé d'écrire pour la commodité d'implémenter des algorithmes, en tenant compte des caractéristiques d'accès aux informations sur le maillage.
Initialement, cette structure ressemblait à ceci:
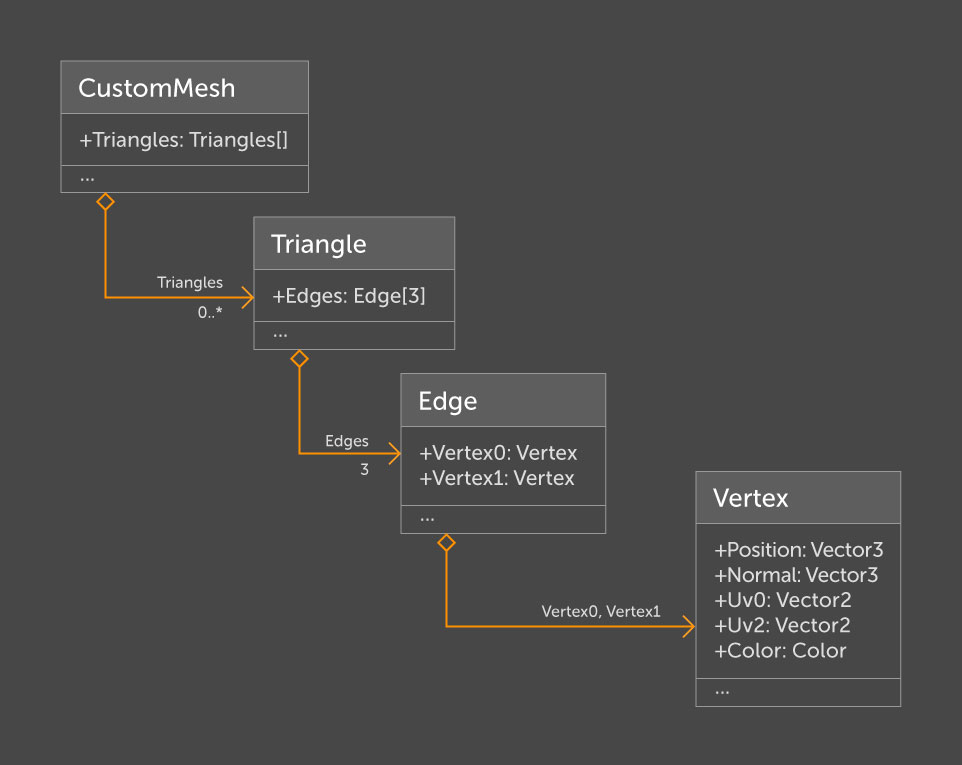
Ici, la classe
CustomMesh représente le maillage lui-même. Séparément, sous la forme d'
utilitaire, nous avons implémenté la conversion à partir d'
UntiyEngine.Mesh et vice versa. Un maillage est défini par son tableau de triangles. Chaque triangle contient exactement trois arêtes, qui à leur tour sont définies par deux sommets. Nous avons décidé d'ajouter aux sommets uniquement les informations dont nous avons besoin pour l'analyse, à savoir: la position, la normale, deux canaux de balayage de texture (
uv0 pour la texture principale,
uv2 pour l'éclairage) et la couleur.
Après un certain temps, le besoin s'est fait sentir de remonter dans la hiérarchie. Par exemple, pour savoir à partir d'un triangle à quel maillage il appartient. De plus, la
rétrogradation de
CustomMesh vers
Vertex semblait prétentieuse, et la quantité déraisonnable et significative de valeurs en double me
faisait peur . Pour ces raisons, la structure a dû être repensée.
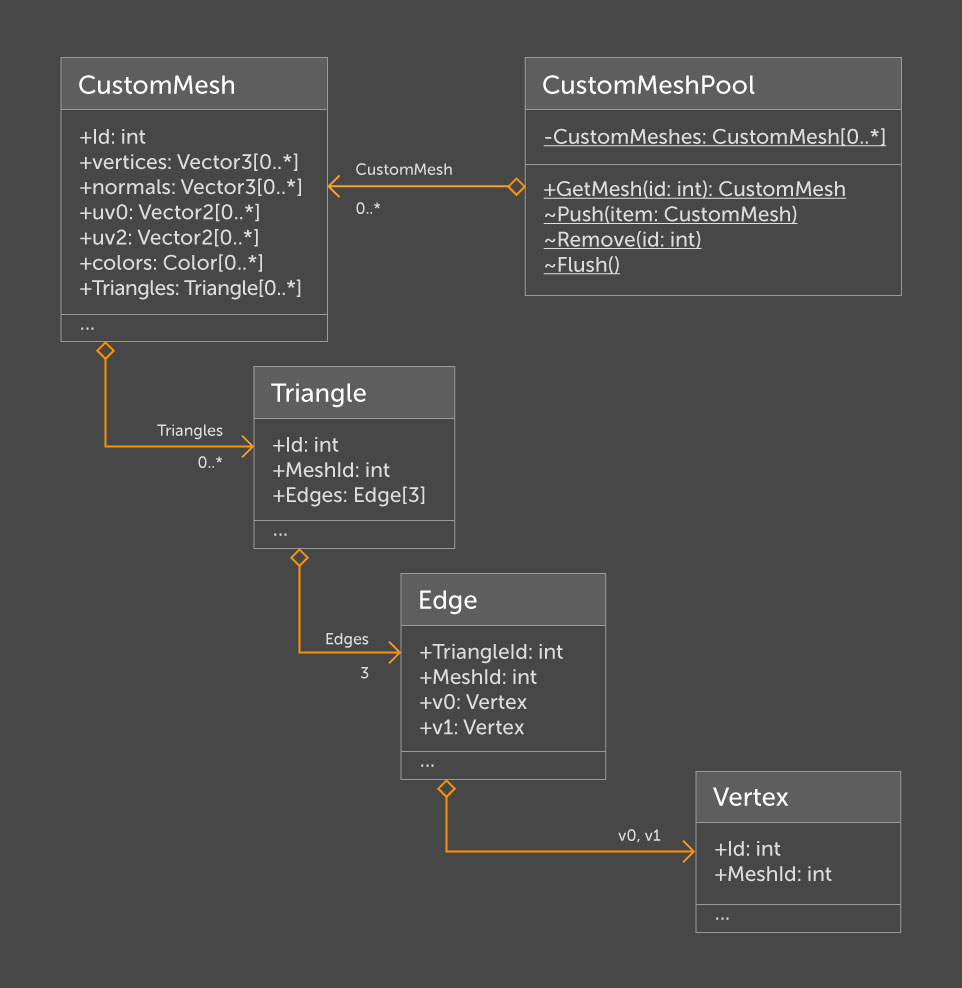 CustomMeshPool
CustomMeshPool implémente des méthodes pour une gestion et un accès pratiques à tous les
CustomMesh traités. En raison du champ
MeshId , chaque entité a accès aux informations du maillage entier. Cette structure de données répond aux exigences des tâches initiales. Il est facile d'étendre en ajoutant l'ensemble de données approprié à
CustomMesh et les méthodes nécessaires à
Vertex .
Il convient de noter que cette approche n'est pas optimale en termes de performances. Dans le même temps, la plupart des algorithmes que nous avons mis en œuvre sont axés sur l'analyse de contenu dans l'éditeur
Unity , c'est pourquoi vous n'avez pas à penser souvent à la quantité de mémoire utilisée. Pour cette raison, nous mettons littéralement en cache tout ce qui est possible. Nous testons d'abord l'algorithme implémenté, puis refactorisons ses méthodes et, dans certains cas, simplifions les structures de données pour optimiser l'exécution.
C'est tout pour l'instant. Dans le prochain article, nous parlerons de la façon de modifier les modèles 3D déjà ajoutés au projet, et nous utiliserons la structure de données considérée.