
Je voudrais présenter le concept de
programmation fonctionnelle aux débutants de la manière la plus simple, en soulignant certains de ses avantages parmi les nombreux autres qui rendront vraiment le code plus lisible et expressif. J'ai ramassé pour vous quelques démos intéressantes qui sont sur le
Playground sur
Github .
Programmation fonctionnelle: définition
Tout d'abord, la
programmation fonctionnelle n'est pas un langage ou une syntaxe, mais très probablement un moyen de résoudre des problèmes en divisant des processus complexes en processus plus simples et leur composition ultérieure. Comme son nom l'indique, «
Programmation fonctionnelle », l'unité de composition de cette approche est une
fonction ; et le but d'une telle
fonction est d'éviter de changer d'état ou de valeurs en dehors de sa
scope) .
Dans
Swift World, il y a toutes les conditions pour cela, car les
fonctions sont ici des participants à part entière au processus de programmation comme des
objets, et le problème de la
mutation est résolu au niveau du concept de
value TYPES (
struct structures et
enum énumérations) qui aident à gérer la mutabilité (
mutation ) et communiquer clairement comment et quand cela peut se produire.
Cependant,
Swift pas au sens plein du langage de
programmation fonctionnelle , il ne vous oblige pas à la
programmation fonctionnelle , bien qu'il reconnaisse les avantages des approches
fonctionnelles et trouve des moyens de les intégrer.
Dans cet article, nous allons nous concentrer sur l'utilisation des éléments intégrés de la
programmation fonctionnelle dans
Swift (c'est-à-dire «prêts à l'emploi») et comprendre comment vous pouvez les utiliser confortablement dans votre application.
Approches impératives et fonctionnelles: comparaison
Pour évaluer l'approche
fonctionnelle , comparons les solutions à un problème simple de deux manières différentes. La première solution est «
impérative », dans laquelle le code change l'état à l'intérieur du programme.
Notez que nous manipulons les valeurs à l'intérieur du tableau mutable nommé
numbers , puis l'imprimons sur la console. En regardant ce code, essayez de répondre aux questions suivantes dont nous discuterons dans un proche avenir:
- Qu'essayez-vous de réaliser avec votre code?
- Que se passe-t-il si un autre
thread tente d'accéder au tableau de numbers pendant l'exécution de votre code? - Que se passe-t-il si vous souhaitez avoir accès aux valeurs d'origine dans le tableau des
numbers ? - Dans quelle mesure ce code peut-il être testé?
Examinons maintenant une approche alternative "
fonctionnelle ":
Dans ce morceau de code, nous obtenons le même résultat sur la console, en abordant la solution au problème d'une manière complètement différente. Notez que cette fois notre tableau de
numbers est immuable grâce au mot clé
let . Nous avons déplacé le processus de multiplication des nombres du tableau de
numbers vers la méthode
timesTen() , qui se trouve dans l'extension d'
extension Array . Nous utilisons toujours une boucle
for et modifions une variable appelée
output , mais la
scope cette variable n'est limitée que par cette méthode. De même, notre argument d'entrée
self est passé à la méthode
timesTen() par valeur (
by value ), ayant la même portée que la sortie variable de
output . La méthode
timesTen() est appelée et nous pouvons imprimer sur la console à la fois le tableau de
numbers origine et le résultat du tableau de
result .
Revenons à nos 4 questions.
1. Qu'essayez-vous de réaliser avec votre code?Dans notre exemple, nous effectuons une tâche très simple en multipliant les nombres dans le tableau de
numbers par
10 .
Avec une approche
impérative , pour obtenir une sortie, vous devez penser comme un ordinateur, en suivant les instructions de la boucle
for . Dans ce cas, le code indique
vous obtenez le résultat. Avec l'approche
fonctionnelle , «
» est «
timesTen() » dans la méthode
timesTen() . À condition que cette méthode ait été implémentée ailleurs, vous ne pouvez vraiment voir que l'expression
numbers.timesTen() . Un tel code montre clairement ce qui
réalisé par ce code, et non
la tâche est résolue. C'est ce qu'on appelle la
programmation déclarative , et il est facile de deviner pourquoi une telle approche est intéressante.
L' approche
impérative permet au développeur de comprendre le
code afin de déterminer
qu'il doit faire.
L' approche
fonctionnelle par rapport à l'approche
impérative est beaucoup plus «expressive» et offre au développeur une occasion luxueuse de simplement supposer que la méthode fait ce qu'elle prétend faire! (Évidemment, cette hypothèse ne s'applique qu'au code pré-vérifié).
2. Que se passe-t-il si un autre thread essaie d'accéder au tableau de numbers pendant l'exécution de votre code?Les exemples présentés ci-dessus existent dans un espace complètement isolé, bien que dans un environnement multithread complexe, il est tout à fait possible que deux
threads tentent d'accéder simultanément aux mêmes ressources. Dans le cas de l'approche
impérative , il est facile de voir que lorsqu'un autre
thread a accès au tableau de
numbers en cours d'utilisation, le résultat sera dicté par l'ordre dans lequel les
threads accèdent au tableau de
numbers . Cette situation est appelée
race condition et peut entraîner un comportement imprévisible et même une instabilité et un crash de l'application.
En comparaison, l'approche
fonctionnelle n'a pas «d'effets secondaires». En d'autres termes, la sortie de la méthode de
output ne modifie aucune valeur stockée dans notre système et est déterminée uniquement par l'entrée. Dans ce cas, tout thread (
threads ) ayant accès au tableau de
numbers recevra TOUJOURS les mêmes valeurs et son comportement sera stable et prévisible.
3. Que se passe-t-il si vous souhaitez avoir accès aux valeurs d'origine stockées dans le tableau de
numbers ?
Il s'agit d'une continuation de notre discussion sur les «effets secondaires». De toute évidence, les changements d'état ne sont pas suivis. Par conséquent, avec l'approche
impérative , nous perdons l'état initial de notre tableau de
numbers pendant le processus de conversion. Notre solution, basée sur l'approche
fonctionnelle , enregistre le tableau de
numbers origine et génère un nouveau tableau de
result avec les propriétés souhaitées en sortie. Il laisse le tableau de
numbers origine intact et adapté pour un traitement ultérieur.
4. Dans quelle mesure ce code peut-il être testé?
Puisque l'approche
fonctionnelle détruit tous les «effets secondaires», la fonctionnalité testée est complètement à l'intérieur de la méthode. L'entrée de cette méthode ne sera JAMAIS modifiée, vous pouvez donc la tester plusieurs fois en utilisant la boucle autant de fois que vous le souhaitez, et vous obtiendrez TOUJOURS le même résultat. Dans ce cas, le test est très simple. En comparaison, tester la solution
Imperative en boucle changera le début de l'entrée et vous obtiendrez des résultats complètement différents après chaque itération.
Résumé des avantages
Comme nous l'avons vu à partir d'un exemple très simple, l'approche
fonctionnelle est une bonne chose si vous avez affaire à un modèle de données car:
- C'est déclaratif
- Il corrige les problèmes liés aux threads comme les
race condition concurrence et les blocages - Il laisse l'état inchangé, qui peut être utilisé pour des transformations ultérieures.
- C'est facile à tester.
Allons un peu plus loin dans l'apprentissage de la programmation
fonctionnelle dans
Swift . Il suppose que les principaux «acteurs» sont des fonctions, et ils devraient être principalement des
objets de première classe .
Fonctions de première classe et fonctions d'ordre supérieur
Pour qu'une fonction soit de première classe, elle doit pouvoir être déclarée comme variable. Cela vous permet de gérer la fonction comme un TYPE normal de données et de l'exécuter en même temps. Heureusement, dans
Swift fonctions sont des objets de première classe, c'est-à-dire qu'elles sont prises en charge en les passant comme arguments à d'autres fonctions, en les renvoyant à la suite d'autres fonctions, en les affectant à des variables ou en les stockant dans des structures de données.
Pour cette raison, nous avons d'autres fonctions dans
Swift - des fonctions d'ordre supérieur qui sont définies comme des fonctions qui prennent une autre fonction en argument ou retournent une fonction. Il y en a beaucoup:
map ,
filter ,
reduce ,
forEach ,
flatMap ,
compactMap ,
sorted , etc. Les exemples les plus courants de fonctions d'ordre supérieur sont
map ,
filter et
reduce . Ils ne sont pas globaux, ils sont tous «attachés» à certains TYPES. Ils fonctionnent sur tous les TYPES de
Sequence , y compris la
Collection , qui est représentée par des structures de données
Swift telles qu'un
Array , un
Dictionary et un
Set . Dans
Swift 5 , les fonctions d'ordre supérieur fonctionnent également avec un tout nouveau TYPE -
Result .
map(_:)
Dans
Swift map(_:) prend une fonction comme paramètre et convertit les valeurs d'un certain
fonction de cette fonction. Par exemple, en appliquant
map(_:) à un tableau de valeurs de
Array , nous appliquons une fonction de paramètre à chaque élément du tableau d'origine et nous obtenons un tableau de
Array , mais également les valeurs converties.
Dans le code ci-dessus, nous avons créé la fonction
timesTen (_:Int) , qui prend une valeur entière
Int et renvoie la valeur entière
Int multipliée par
10 , et l'avons utilisée comme paramètre d'entrée de notre fonction de
map(_:) ordre supérieur
map(_:) , en l'appliquant à notre tableau
numbers . Nous avons obtenu le résultat dont nous avons besoin dans le tableau de
result .
Le nom de la fonction de paramètre
timesTen pour les fonctions d'ordre supérieur comme
map(_:) n'a pas d'importance, le
paramètre d'entrée et la valeur de retour sont importants, c'est-à-dire la signature
(Int) -> Int paramètre d'entrée de fonction. Par conséquent, nous pouvons utiliser des fonctions anonymes dans
map(_:) - fermetures - sous n'importe quelle forme, y compris celles avec des noms d'arguments raccourcis
$0 ,
$1 , etc.
Si nous regardons la fonction
map(_ :) pour un
Array , cela pourrait ressembler à ceci:
func map<T>(_ transform: (Element) -> T) -> [T] { var returnValue = [T]() for item in self { returnValue.append(transform(item)) } return returnValue }
C'est un code impératif qui nous est familier, mais ce n'est plus un problème de développeur, c'est un problème
Apple , un problème
Swift . L'implémentation de la fonction
map(_:) supérieur est optimisée par
Apple en termes de performances, et nous, les développeurs, avons la garantie de la fonctionnalité
map(_:) , de sorte que nous ne pouvons exprimer correctement avec l'argument de la fonction de
transform nous voulons sans nous soucier de
il sera mis en œuvre. En conséquence, nous obtenons du code parfaitement lisible sous la forme d'une seule ligne, qui fonctionnera mieux et plus rapidement.
Le
renvoyé par la fonction de paramètre peut ne pas coïncider avec le
éléments de la collection d'origine.
Dans le code ci-dessus, nous avons des entiers
possibleNumbers , représentés sous forme de chaînes, et nous voulons les convertir en entiers de
Int , en utilisant l'initialiseur disponible
Int(_ :String) représenté par la fermeture
{ str in Int(str) } . Nous faisons cela en utilisant
map(_:) et obtenons un tableau
mapped de
Optional comme sortie:

Nous n'avons
convertir
éléments de notre tableau
possibleNumbers en nombres entiers.En conséquence, une partie a reçu la valeur
nil , indiquant l'impossibilité de convertir la
String en un entier
Int , et l'autre partie transformée en
Optionals , qui ont des valeurs:
print (mapped)
compactMap(_ :)
Si la fonction de paramètre transmise à la fonction d'ordre supérieur a une valeur
Optional à la sortie, il peut être plus utile d'utiliser une autre fonction d'un ordre supérieur, de signification similaire -
compactMap(_ :) , qui fait la même chose que
map(_:) , mais «étend» en outre les valeurs reçues à la sortie
Optional et supprime les valeurs
nil de la collection.

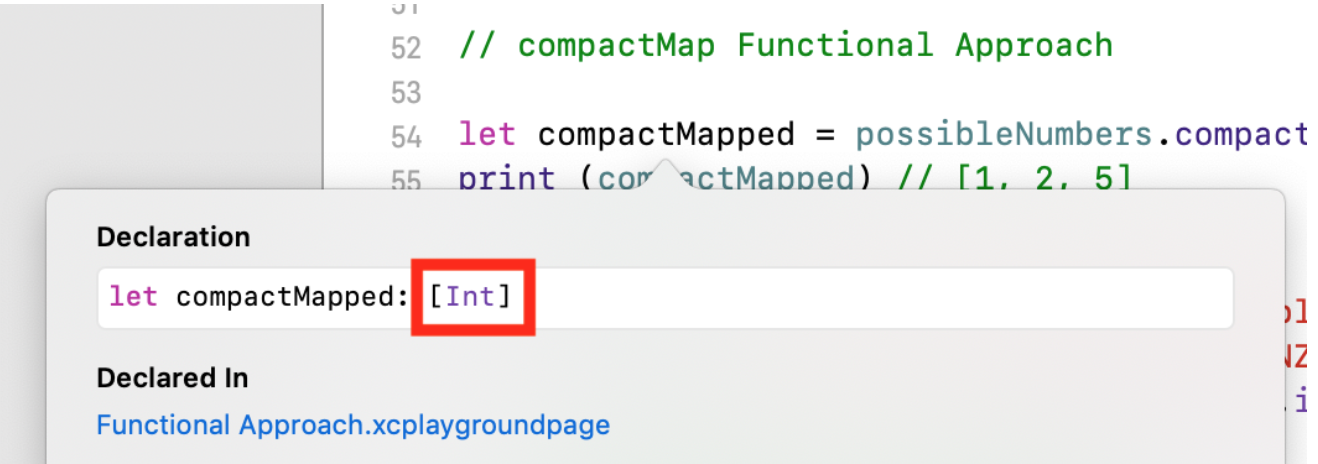
Dans ce cas, nous obtenons un tableau de TYPE
compactMapped [Int] , mais peut-être plus petit:
let possibleNumbers = ["1", "2", "three", "///4///", "5"] let compactMapped = possibleNumbers.compactMap(Int.init) print (compactMapped)
Chaque fois que vous utilisez l'
init?() Comme fonction de transformation, vous devrez utiliser
compactMap(_ :) :
Je dois dire qu'il y a plus qu'assez de raisons d'utiliser la fonction
compactMap(_ :) ordre
compactMap(_ :) .
Swift «loves» Valeurs
Optional , elles peuvent être obtenues non seulement en utilisant l'
failable «
failable »
init?() , Mais aussi en utilisant le
as? "Casting":
let views = [innerView,shadowView,logoView] let imageViews = views.compactMap{$0 as? UIImageView}
... et l'
try? lors du traitement des erreurs lancées par certaines méthodes. Je dois dire
Apple craint que l'utilisation d'
try? conduit très souvent au double
Optional et dans
Swift 5 ne laisse plus qu'un seul niveau
Optional après avoir appliqué l'
try? .
Il existe une autre fonction similaire au nom du
flatMap(_ :) ordre
flatMap(_ :) , dont un peu plus bas.
Parfois, pour utiliser la
map(_:) fonction d'ordre supérieur
map(_:) , il est utile d'utiliser la méthode
zip (_:, _:) pour créer une séquence de paires à partir de deux séquences différentes.
Supposons que nous ayons une
view sur laquelle plusieurs points sont représentés, reliés entre eux et formant une ligne brisée:
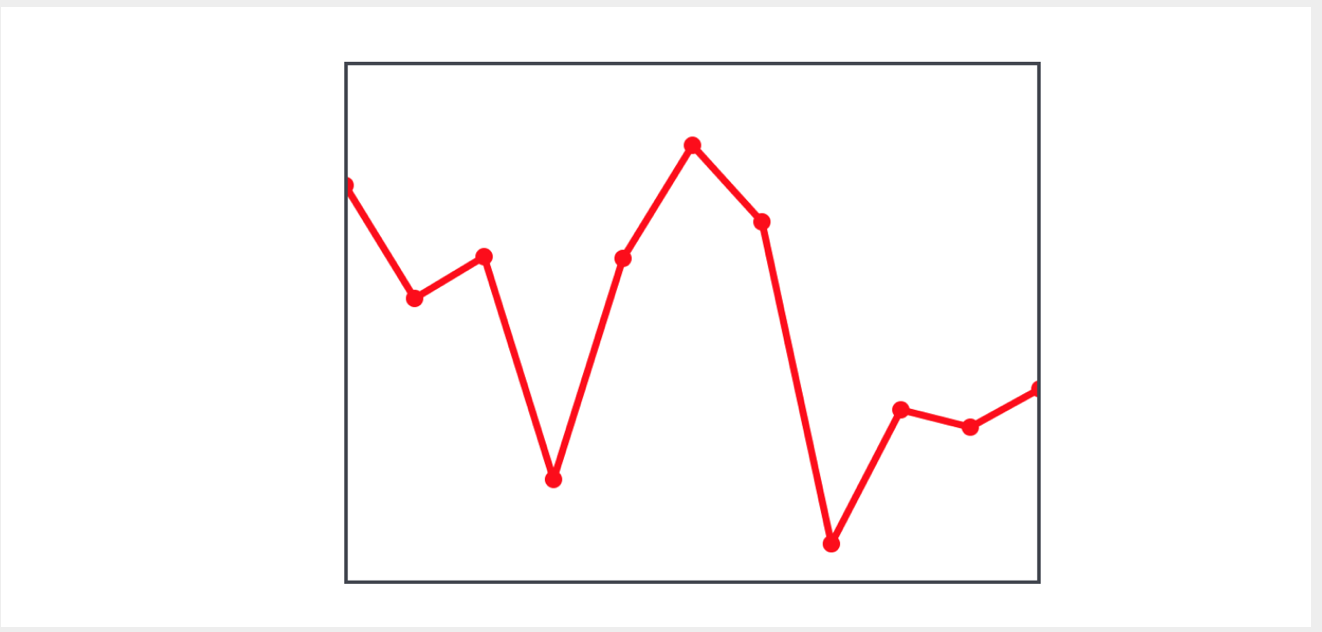
Nous devons construire une autre ligne brisée reliant les points médians des segments de la ligne brisée d'origine:

Pour calculer le milieu d'un segment, nous devons avoir les coordonnées de deux points: le courant et le suivant. Pour ce faire, nous pouvons créer une séquence composée de paires de points - le courant et le suivant - en utilisant la méthode
zip (_:, _:) points.dropFirst() zip (_:, _:) , dans laquelle nous utiliserons le tableau de points de départ et le tableau des
points suivants.dropFirst
points.dropFirst() :
let pairs = zip (points,points.dropFirst()) let averagePoints = pairs.map { CGPoint(x: ($0.x + $1.x) / 2, y: ($0.y + $1.y) / 2 )}
Avec une telle séquence, nous calculons très facilement les points médians à l'aide de la
map(_:) fonction d'ordre supérieur
map(_:) et les affichons sur le graphique.
filter (_:)
Dans
Swift , le
filter (_:) fonction d'ordre supérieur
filter (_:) est disponible pour la plupart des
lesquels la fonction
map(_:) est disponible. Vous pouvez filtrer toutes les
Sequence séquences avec un
filter (_:) , c'est évident! La méthode
filter (_:) prend une autre fonction comme paramètre, qui est une condition pour chaque élément de la séquence, et si la condition est remplie, alors l'élément est inclus dans le résultat et sinon, il n'est pas inclus. Cette "autre fonction" prend une seule valeur - un élément de la séquence
Sequence - et renvoie un
Bool , le soi-disant prédicat.
Par exemple, pour les tableaux matriciels, le
filter (_:) fonction d'ordre supérieur
filter (_:) applique la fonction de prédicat et renvoie un autre tableau composé uniquement des éléments du tableau d'origine pour lesquels la fonction de prédicat d'entrée renvoie
true .
Ici, le
filter (_:) fonction d'ordre supérieur
filter (_:) prend chaque élément du tableau de
numbers (représenté par
$0 ) et vérifie si cet élément est un nombre pair. S'il s'agit d'un nombre pair, les éléments du tableau de
numbers tombent dans le nouveau tableau
filted , sinon non. Dans une forme déclarative, nous avons informé le programme
nous voulons obtenir au lieu de nous soucier de
nous devons le faire.
Je vais donner un autre exemple d'utilisation du
filter (_:) fonction d'ordre supérieur
filter (_:) pour obtenir uniquement les
20 premiers nombres de Fibonacci pairs avec des valeurs
< 4000 :
let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
Nous obtenons une séquence de tuples composée de deux éléments de la séquence de Fibonacci: le n-ème et (n + 1) -th:
(0, 1), (1, 1), (1, 2), (2, 3), (3, 5) …
Pour un traitement ultérieur, nous limitons le nombre d'éléments aux vingt et unièmes éléments en utilisant le
prefix (20) et prenons le
0 élément du tuple généré en utilisant la
map {$0.0 } , qui correspondra à la séquence de Fibonacci commençant par
0 :
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Nous pourrions prendre le
1 élément du tuple formé en utilisant la
map {$0.1 } , ce qui correspondrait à la séquence de Fibonacci commençant par
1 :
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Nous obtenons les éléments dont nous avons besoin en utilisant le
filter {$0 % 2 == 0 && $0 < 4000} fonction d'ordre supérieur
filter {$0 % 2 == 0 && $0 < 4000} , qui retourne un tableau d'éléments de séquence qui satisfont le prédicat donné. Dans notre cas, ce sera un tableau d'entiers
[Int] :
[0, 2, 8, 34, 144, 610, 2584]
Il existe un autre exemple utile d'utilisation du
filter (_:) pour une
Collection .
J'étais confronté
à un vrai problème , lorsque vous avez un tableau d'
images qui s'affiche à l'aide de
CollectionView , et en utilisant la technologie
Drag & Drop , vous pouvez collecter un tas d'images et les déplacer partout, y compris en les déposant dans " poubelle. "

Dans ce cas, le tableau d'index
removedIndexes déversées dans la «poubelle» est fixe, et vous devez créer un nouveau tableau d'images, à l'exclusion de ceux dont les index sont dans le tableau
removedIndexes . Supposons que nous ayons un tableau d'
images entiers qui imite les images, et un tableau d'indices de ces entiers
removedIndexes qui doivent être supprimés. Nous utiliserons le
filter (_:) pour résoudre notre problème:
var images = [6, 22, 8, 14, 16, 0, 7, 9] var removedIndexes = [2,5,0,6] var images1 = images .enumerated() .filter { !removedIndexes.contains($0.offset) } .map { $0.element } print (images1)
La méthode
enumerated() renvoie une séquence de tuples composée d'index de
offset et de valeurs d'
element d'un tableau.
Ensuite, nous appliquons un filtre filterà la séquence résultante de tuples, ne laissant que ceux dont l'index n'est $0.offsetpas contenu dans le tableau removedIndexes. L'étape suivante, nous sélectionnons la valeur dans le tuple $0.elementet obtenons le tableau dont nous avons besoin images1.reduce (_:, _:)
La méthode est reduce (_:, _:)également disponible pour la plupart des map(_:)et des méthodes disponibles filter (_:). La méthode reduce (_:, _:)«réduit» la séquence Sequenceà une seule valeur cumulée et a deux paramètres. Le premier paramètre est la valeur d'accumulation de départ et le deuxième paramètre est une fonction qui combine la valeur d'accumulation avec l'élément de séquence Sequencepour obtenir une nouvelle valeur d'accumulation.La fonction de paramètre d'entrée est appliquée à chaque élément de la séquence Sequence, l'un après l'autre, jusqu'à ce qu'il atteigne la fin et crée la valeur cumulée finale. let sum = Array (1...100).reduce(0, +)
Ceci est un exemple trivial classique d'utilisation d'une fonction d'ordre supérieur reduce (_:, _:)- compter la somme des éléments d'un tableau Array. 1 0 1 0 +1 = 1 2 1 2 2 + 1 = 3 3 3 3 3 + 3 = 6 4 6 4 4 + 6 = 10 . . . . . . . . . . . . . . . . . . . 100 4950 100 4950 + 100 = 5050
En utilisant la fonction, reduce (_:, _:)nous pouvons très simplement calculer la somme des nombres de Fibonacci qui satisfont une certaine condition: let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
Mais il existe des applications plus intéressantes d'une fonction d'ordre supérieur reduce (_:, _:).Par exemple, nous pouvons déterminer très simplement et de manière concise un paramètre très important pour UIScrollView- la taille de la zone "scrollable" contentSize- en fonction de sa taille subviews: let scrollView = UIScrollView() scrollView.addSubview(UIView(frame: CGRect(x: 300.0, y: 0.0, width: 200, height: 300))) scrollView.addSubview(UIView(frame: CGRect(x: 100.0, y: 0.0, width: 300, height: 600))) scrollView.contentSize = scrollView.subviews .reduce(CGRect.zero,{$0.union($1.frame)}) .size
Dans cette démo, la valeur accumulée est GCRect, et l'opération d'accumulation est l'opération de combinaison des unionrectangles qui sont les framenôtres subviews.Malgré le fait qu'une fonction d'ordre supérieur reduce (_:, _:)assume un caractère cumulatif, elle peut être utilisée dans une perspective complètement différente. Par exemple, pour diviser un tuple en parties dans un tableau de tuples:
Swift a 4.2introduit un nouveau type de fonction d'ordre supérieur reduce (into:, _:). La méthode reduce (into:, _:)est préférable en termes d'efficacité par rapport à la méthode reduce (:, :)si COW (copy-on-write) Arrayou est utilisée comme structure résultante Dictionary.Il peut être utilisé efficacement pour supprimer les valeurs correspondantes dans un tableau d'entiers:
... ou lors du comptage du nombre d'éléments différents dans un tableau:
flatMap (_:)
Avant de passer à cette fonction d'ordre supérieur, regardons une démonstration très simple. let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
Si nous exécutons ce code pour l'exécuter Playground, alors tout semble bon, et le nôtre firstNumberest égal 42: mais, si vous ne le savez pas, il
mais, si vous ne le savez pas, il Playgroundcache souvent le vrai firstNumber. En fait, la constante firstNumbera Optional: en effet,
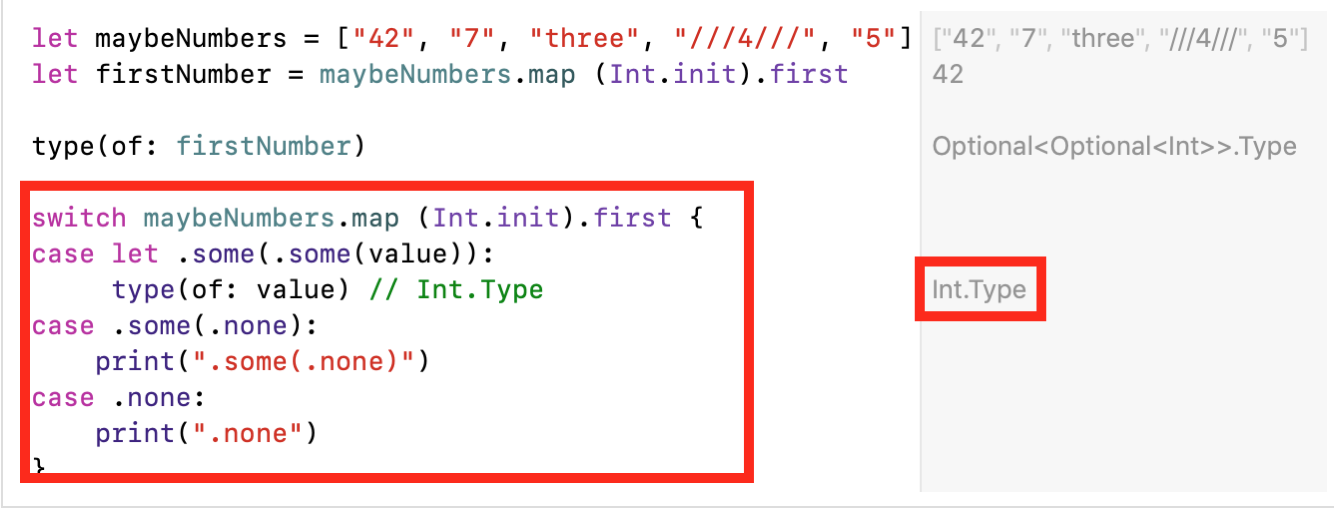
effet, map (Int.init)à la sortie, elle forme un tableau Optionalde valeurs TYPE [Int?], car toutes les lignes Stringne peuvent pas être converties Intet l'initialiseur Int.int«tombe» ( failable). Ensuite, nous prenons le premier élément du tableau formé en utilisant la fonction firstdu tableau Array, qui forme également la sortieOptional, car le tableau peut être vide et nous ne pourrons pas obtenir le premier élément du tableau. En conséquence, nous avons un double Optional, c'est-à-direInt?? .
Nous avons une structure imbriquée Optionaldans Optionallaquelle il est vraiment plus difficile de travailler et que nous ne voulons naturellement pas avoir. Afin de tirer le meilleur parti de cette structure imbriquée, nous devons «plonger» dans deux niveaux. De plus, toute transformation supplémentaire peut approfondir le niveau Optionalencore plus bas.Obtenir la valeur du double imbriqué est Optionalvraiment pénible.Nous avons 3 options et toutes nécessitent une connaissance approfondie de la langue Swift.if let , ; «» «» Optional , — «» Optional :

if case let ( pattern match ) :

?? :

- ,
switch :
Pire encore, de tels problèmes d'imbrication genericconteneurs generalized ( ) pour lesquels une opération est définie map. Par exemple, pour les tableaux Array.Prenons un autre exemple de code. Supposons que nous ayons un texte sur plusieurs lignes multilineStringque nous voulons diviser en mots écrits en minuscules: let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .map{$0.split(separator: " ")}
Afin d'obtenir un tableau de mots words, nous faisons d'abord des lettres majuscules (grandes) en minuscules (petites) en utilisant la méthode lowercased(), puis nous divisons le texte en split(separatot: "\n")lignes en utilisant la méthode et obtenons un tableau de chaînes, puis nous l'utilisons map {$0.split(separator: " ")}pour séparer chaque ligne en mots distincts.En conséquence, nous obtenons des tableaux imbriqués: [["", ",", "", ","], ["", "", ";", "", "", "", "", ",", "—"], ["", ",", "", "", ":"], ["", "—", "", "", ",", "", "", "."], ["", "", ",", "", "", ","], ["", "", ".", "", ""], ["", ".", "", ",", ""], ["", "", "", ""], ["", "", ",", "", "«", "»"], ["", ".", "", ","], ["", ",", "", "", "!"]]
... et cela wordsa Array: nous avons à nouveau obtenu une structure de données "imbriquée", mais cette fois, nous ne l'avons pas fait
nous avons à nouveau obtenu une structure de données "imbriquée", mais cette fois, nous ne l'avons pas fait Optional, mais Array. Si nous voulons continuer à traiter les mots reçus words, par exemple, pour trouver le spectre des lettres de ce texte à plusieurs lignes, nous devrons d'abord «redresser» le tableau du double Arrayet le transformer en un seul tableau Array. Ceci est similaire à ce que nous avons fait avec double Optionalpour une démo au début de cette section sur flatMap: let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
Heureusement, Swiftnous n'avons pas à recourir à des constructions syntaxiques complexes. Swiftnous fournit une solution toute faite pour les baies Arrayet Optional. Il s'agit d'une fonction d'ordre supérieur flatMap! Il est très similaire à map, mais il possède des fonctionnalités supplémentaires associées au "redressement" ultérieur des "pièces jointes" qui apparaissent lors de l'exécution map. Et c'est pourquoi on l'appelle flatMap, ça «redresse» ( flattens) le résultat map.Essayons d'appliquer flatMapà firstNumber: Nous avons vraiment obtenu la sortie avec un seul niveau
Nous avons vraiment obtenu la sortie avec un seul niveau Optional. Fonctionneencore plus intéressant flatMappour un tableau Array. Dans notre expression pour, wordsnous remplaçons simplement mapparflatMap: ... et nous obtenons juste un tableau de mots
... et nous obtenons juste un tableau de mots wordssans "imbrication": ["", ",", "", ",", "", "", ";", "", "", "", "", ",", "—", "", ",", "", "", ":", "", "—", "", "", ",", "", "", ".", "", "", ",", "", "", ",", "", "", ".", "", "", "", ".", "", ",", "", "", "", "", "", "", "", ",", "", "«", "»", "", ".", "", ",", "", ",", "", "", "!"]
Nous pouvons maintenant continuer le traitement dont nous avons besoin du tableau de mots résultant words, mais soyez prudent. Si nous l'appliquons à nouveau flatMapà chaque élément du tableau words, nous obtiendrons, peut-être, un résultat inattendu, mais tout à fait compréhensible. Nous obtenons un tableau unique et non «imbriqué» de lettres et de symboles
Nous obtenons un tableau unique et non «imbriqué» de lettres et de symboles [Character]contenu dans notre phrase à plusieurs lignes: ["", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ";", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ...]
Le fait est que la chaîne Stringest une collection de Collectioncaractères [Character]et, en appliquant flatMapà chaque mot individuel, nous abaissons une fois de plus le niveau de "nidification" et arrivons à un tableau de caractères flattenCharacters.Peut-être que c'est exactement ce que vous voulez, ou peut-être pas. Faites attention à cela.Mettre tout cela ensemble: résoudre certains problèmes
TÂCHE 1
Nous pouvons continuer le traitement du tableau de mots obtenu dans la section précédente dont nous avons besoin wordset calculer la fréquence d'apparition des lettres dans notre phrase multiligne. Pour commencer, «collons» tous les mots du tableau wordssur une seule grande ligne et en excluons tous les signes de ponctuation, c'est-à-dire ne laissons que les lettres: let wordsString = words.reduce ("",+).filter { "" .contains($0)}
Nous avons donc obtenu toutes les lettres dont nous avons besoin. Maintenant, faisons-en un dictionnaire, où la clé keyest la lettre et la valeur valueest la fréquence de son occurrence dans le texte.Nous pouvons le faire de deux manières.La première méthode est associée à l'utilisation d'une nouvelle Swift 4.2variété d'une fonction d'ordre supérieur qui est apparue dans reduce (into:, _:). Cette méthode nous convient tout à fait pour organiser un dictionnaire letterCountavec la fréquence d'apparition des lettres dans notre phrase multiligne: let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} print (letterCount)
En conséquence, nous obtiendrons un dictionnaire letterCount [Character : Int]dans lequel les clés keysont les caractères trouvés dans la phrase à l'étude, et comme la valeur valueest le nombre de ces caractères.La deuxième méthode consiste à initialiser le dictionnaire à l'aide du regroupement, ce qui donne le même résultat: let letterCountDictionary = Dictionary(grouping: wordsString ){ $0}.mapValues {$0.count} letterCount == letterCountDictionary
Nous souhaitons trier le dictionnaire letterCountpar ordre alphabétique: let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
Mais nous ne pouvons pas trier directement le dictionnaire Dictionary, car ce n'est fondamentalement pas une structure de données ordonnée. Si nous appliquons la fonction sorted (by:)au dictionnaire Dictionary, elle nous renverra les éléments de la séquence triés avec le prédicat donné sous la forme d'un tableau de tuples nommés, que mapnous transformerons en un tableau de chaînes [":17", ":5", ":18", ...]reflétant la fréquence d'occurrence de la lettre correspondante.Nous voyons que cette fois, sorted (by:)juste l'opérateur " <" est passé comme prédicat à une fonction d' ordre supérieur . La fonction sorted (by:)attend une «fonction de comparaison» comme seul argument à l'entrée. Il est utilisé pour comparer deux valeurs adjacentes et décider si elles sont correctement ordonnées (dans ce cas, renvoietrue) ou non (retourne false). On peut donner à cette "fonction de comparaison" des fonctions sorted (by:)sous forme de fermeture anonyme: sorted(by: {$0.key < $1.key}
Et nous pouvons simplement lui donner l'opérateur " <", qui a la signature dont nous avons besoin, comme cela a été fait ci-dessus. Il s'agit également d'une fonction et le tri par clé est en cours key.Si nous voulons trier le dictionnaire par valeurs valueet savoir quelles lettres se trouvent le plus souvent dans cette phrase, nous devrons utiliser la fermeture de la fonction sorted (by:): let countsStat = letterCountDictionary .sorted(by: {$0.value > $1.value}) .map{"\($0.0):\($0.1)"} print (countsStat )
Si nous examinons la solution au problème de la détermination du spectre des lettres d'une phrase multiligne dans son ensemble ... let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .flatMap{$0.split(separator: " ")} let wordsString = words.reduce ("",+).filter { "" .contains($0)} let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
… , (
var ,
let) () , , :
split - ,
map —
flatMap - ( ),
filter - ,
sorted - ,
reduce -
, . «» ,
map , ,
flatMap, si nous voulons sélectionner uniquement certaines données, nous les utilisons filter, etc. Toutes ces fonctions de «l'ordre le plus élevé» sont conçues et testées Appleen tenant compte de l'optimisation des performances. Donc, ce morceau de code est très fiable et concis - nous n'avions pas besoin de plus de 5 phrases pour résoudre notre problème. Ceci est un exemple de programmation fonctionnelle.Le seul inconvénient de l'application de l'approche fonctionnelle dans cette démo est que, pour des raisons d'immuabilité, de testabilité et de lisibilité, nous poursuivons notre texte à plusieurs reprises à travers diverses fonctions d'ordre supérieur. Dans le cas d'un grand nombre d'articles de collection, les Collectionperformances peuvent chuter. Par exemple, si nous utilisons d'abord filter(_:)et, puis - first.DansSwift 4 De nouvelles options de fonctionnalités ont été ajoutées pour améliorer les performances, et voici quelques conseils pour écrire du code plus rapidement.1. Utilisez contains, PASfirst( where: ) != nil
La vérification de la présence d'un objet dans une collection Collectionpeut être effectuée de plusieurs manières. La meilleure performance est fournie par la fonction contains.CODE CORRECT let numbers = [0, 1, 2, 3] numbers.contains(1)
CODE INCORRECT let numbers = [0, 1, 2, 3] numbers.filter { number in number == 1 }.isEmpty == false numbers.first(where: { number in number == 1 }) != nil
2. Utilisez la validation isEmpty, PAS une comparaison countavec zéro
Étant donné que pour certaines collections, l'accès à la propriété counts'effectue en itérant sur tous les éléments de la collection.CODE CORRECT let numbers = [] numbers.isEmpty
CODE INCORRECT let numbers = [] numbers.count == 0
3. Vérifiez la chaîne vide StringavecisEmpty
String Stringin Swiftest une collection de caractères [Character]. Cela signifie que pour les chaînes, il est Stringégalement préférable d'utiliser isEmpty.CODE CORRECT myString.isEmpty
CODE INCORRECT myString == "" myString.count == 0
4. Obtention du premier élément qui remplit certaines conditions
L'itération sur l'ensemble de la collection afin d'obtenir le premier objet qui remplit certaines conditions peut être effectuée à l'aide d'une méthode filtersuivie d'une méthode first, mais la méthode est la meilleure en termes de vitesse first (where:). Cette méthode cesse d'itérer sur la collection dès qu'elle remplit la condition nécessaire. La méthode filtercontinuera d'itérer sur l'ensemble de la collection, qu'elle rencontre ou non les éléments nécessaires.Évidemment, il en va de même pour la méthode last (where:).CODE CORRECT let numbers = [3, 7, 4, -2, 9, -6, 10, 1] let firstNegative = numbers.first(where: { $0 < 0 })
CODE INCORRECT let numbers = [0, 2, 4, 6] let allEven = numbers.filter { $0 % 2 != 0 }.isEmpty
Parfois, lorsque la collection Collectionest très importante et que les performances sont essentielles pour vous, il vaut la peine de revenir à comparer les approches impératives et fonctionnelles et à choisir celle qui vous convient.TÂCHE 2
Il y a un autre excellent exemple d'une utilisation très concise d'une fonction d'ordre supérieur reduce (_:, _:)que j'ai rencontré. Ceci est un jeu SET .Voici ses règles de base. Le nom du jeu SETvient du mot anglais "set" - "set". Le jeu SETcomprend 81 cartes, chacune avec une image unique: Chaque carte a 4 attributs, énumérés ci-dessous:Quantité : chaque carte a un, deux ou trois caractères.Type de personnages : ovales, losanges ou vagues.Couleur : les symboles peuvent être rouges, verts ou violets.Remplissage : les caractères peuvent être vides, ombrés ou ombrés.But du jeu
Chaque carte a 4 attributs, énumérés ci-dessous:Quantité : chaque carte a un, deux ou trois caractères.Type de personnages : ovales, losanges ou vagues.Couleur : les symboles peuvent être rouges, verts ou violets.Remplissage : les caractères peuvent être vides, ombrés ou ombrés.But du jeuSET: Parmi les 12 cartes présentées sur la table, vous devez trouver SET(un ensemble) composé de 3 cartes, dans lesquelles chacun des signes coïncide complètement ou diffère complètement sur les 3 cartes. Tous les panneaux doivent respecter pleinement cette règle.Par exemple, le nombre de caractères sur les 3 cartes doit être identique ou différent, la couleur sur les 3 cartes doit être identique ou différente, et ainsi de suite ...Dans cet exemple, nous ne nous intéresserons qu'au modèle de carte SET struct SetCardet à l'algorithme pour déterminer SETpar 3e cartes isSet( cards:[SetCard]): struct SetCard: Equatable { let number: Variant
—
number ,
shape ,
color fill —
Variant , 3 :
var1 ,
var2 var3 , 3-
rawValue —
1,2,3 .
rawValue . - , ,
color ,
rawValue colors 3- , ,
colors 3- ,
3 ,
6 9 , ,
6 . 3-
rawValue colorsles 3 cartes. Nous savons que c'est une condition préalable à la composition de 3 cartes SET. Pour que 3 cartes deviennent vraiment SETnécessaires, pour tous les signes SetCard- Quantité number, Type de symbole shape, Couleur coloret Remplissage fill- leur somme doit rawValueêtre un multiple de la 3e. Parconséquent, dans la staticméthode, isSet( cards:[SetCard])nous avons d' abord calculer le tableau sumsdes sommes rawValuepour les 3 cartes pour toutes les carte 4 performances en utilisant la fonction d'ordre supérieur reduceavec une valeur initiale égale à 0, et l' accumulation de fonctions {$0 + $1.number.rawValue}, {$0 + $1.color.rawValue}, {$0 + $1.shape.rawValue}, { {$0 + $1.fill.rawValue}. Chaque élément du tableau sumsdoit être un multiple de 3e, et encore une fois, nous utilisons la fonctionreduce, mais cette fois avec une valeur initiale égale trueet cumulant la fonction logique " AND" {$0 && ($1 % 3) == 0}. Dans Swift 5, pour tester la multiplicité d'un nombre pour un autre, une fonction est introduite à la isMultiply(of:)place de l'opérateur %restant. Il permettra également d' améliorer la lisibilité du code: { $0 && ($1.isMultiply(of:3) }.Ce code incroyablement court pour savoir si les 3 SetCardcartes sont les SETi est obtenu grâce à l' approche " fonctionnelle ", et nous pouvons nous assurer qu'il fonctionne sur Playground: Comment
Comment SETconstruire l'interface utilisateur ( UI) sur ce modèle de jeu ici , ici et ici .Fonctionnalités pures et effets secondaires
Une fonction pure remplit deux conditions. Il renvoie toujours le même résultat avec les mêmes paramètres d'entrée. Et le calcul du résultat ne provoque pas d'effets secondaires associés à la sortie de données à l'extérieur (par exemple, sur disque) ou à l'emprunt de données source à l'extérieur (par exemple, le temps). Cela vous permet d'optimiser considérablement le code.Ce sujet est Swiftparfaitement exposé sur point.free dans les tout premiers épisodes de " Fonctions " et " Effets secondaires " , qui sont traduits en russe et présentés comme " Fonctions " et "Effets secondaires" .Composition des fonctions
Dans un sens mathématique, cela signifie appliquer une fonction au résultat d'une autre fonction. Dans une Swiftfonction, ils peuvent renvoyer une valeur que vous pouvez utiliser comme entrée pour une autre fonction. Il s'agit d'une pratique de programmation courante.Imaginez que nous avons un tableau d'entiers et que nous voulons obtenir un tableau de carrés de nombres pairs uniques à la sortie. Habituellement, nous le réimplémentons comme suit: var integerArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] func unique(_ array: [Int]) -> [Int] { return array.reduce(into: [], { (results, element) in if !results.contains(element) { results.append(element) } }) } func even(_ array: [Int]) -> [Int] { return array.filter{ $0%2 == 0} } func square(_ array: [Int]) -> [Int] { return array.map{ $0*$0 } } var array = square(even(unique(integerArray)))
Ce code nous donne le résultat correct, mais vous voyez que la lisibilité de la dernière ligne de code n'est pas si facile. La séquence de fonctions (de droite à gauche) est l'opposé de celle à laquelle nous sommes habitués (de gauche à droite) et que nous aimerions voir ici. Nous devons d'abord diriger notre logique vers la partie la plus interne de multiples plongements - vers le tableau inegerArray, puis vers la fonction externe à ce tableau unique, puis nous montons d'un autre niveau - la fonction even, et enfin, la fonction dans la conclusion square.Et ici la «composition» des fonctions >>>et des opérateurs vient à notre aide |>, ce qui nous permet d'écrire le code d'une manière très pratique, représentant le traitement du tableau d'origine integerArraycomme un «convoyeur» de fonctions: var array1 = integerArray |> unique >>> even >>> square
Presque toutes les langues spécialisées telles que la programmation fonctionnelle F#, Elixiret Elmutiliser ces opérateurs pour les fonctions « de composition ».Il Swiftn'y a pas d'opérateurs intégrés de la «composition» des fonctions >>>et |>, mais nous pouvons très facilement les obtenir à l'aide de Genericsclosures ( closure) et de l' infixopérateur: precedencegroup ForwardComposition{ associativity: left higherThan: ForwardApplication } infix operator >>> : ForwardComposition func >>> <A, B, C>(left: @escaping (A) -> B, right: @escaping (B) -> C) -> (A) -> C { return { right(left($0)) } } precedencegroup ForwardApplication { associativity: left } infix operator |> : ForwardApplication func |> <A, B>(a: A, f: (A) -> B) -> B { return f(a) }
Malgré les coûts supplémentaires, cela peut dans certains cas augmenter considérablement les performances, la lisibilité et la testabilité de votre code. Par exemple, à l'intérieur, mapvous placez toute une chaîne de fonctions en utilisant l'opérateur «composition» >>>au lieu de courir après un tableau à travers de nombreux map: var integerArray1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] let b = integerArray1.map( { $0 + 1 } >>> { $0 * 3 } >>> String.init) print (b)
Mais pas toujours une approche fonctionnelle donne un effet positif.Au début, quand il est apparu Swiften 2014, tout le monde s'est précipité pour écrire des bibliothèques avec des opérateurs pour la «composition» des fonctions et pour résoudre une tâche difficile à l'époque comme l'analyse syntaxique à l' JSONaide d'opérateurs de programmation fonctionnelle au lieu d'utiliser des constructions infiniment imbriquées if let. J'ai moi-même traduit l' article sur l'analyse fonctionnelle JSON qui m'a ravi de sa solution élégante et était un fan de la bibliothèque Argo .Mais les développeurs sont Swiftallés d'une manière complètement différente et ont proposé, sur la base d'une technologie orientée protocole, une manière beaucoup plus concise d'écrire du code. Afin de «livrer» les JSONdonnées directement àCodable, qui met automatiquement en œuvre ce protocole, si votre modèle est constitué des connus Swiftstructures de données: String, Int, URL, Array, Dictionary, etc. struct Blog: Codable { let id: Int let name: String let url: URL }
Avoir des JSONdonnées de ce célèbre article ... [ { "id" : 73, "name" : "Bloxus test", "url" : "http://remote.bloxus.com/" }, { "id" : 74, "name" : "Manila Test", "url" : "http://flickrtest1.userland.com/" } ]
... pour le moment, vous n'avez besoin que d'une ligne de code pour obtenir un éventail de blogs blogs: let blogs = Bundle.main.path(forResource: "blogs", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Blog].self, from: $0) } print ("\(blogs!)")
Tout le monde a oublié en toute sécurité d'utiliser les opérateurs de «composition» des fonctions pour l'analyse JSON, s'il existe un autre moyen plus compréhensible et plus simple de le faire en utilisant des protocoles.Si tout est si simple, alors nous pouvons «télécharger» des JSONdonnées vers des modèles plus complexes. Supposons que nous ayons un fichier de JSONdonnées qui porte un nom user.jsonet se trouve dans notre répertoire Resources.. Il contient des données sur un certain utilisateur: { "email": "blob@pointfree.co", "id": 42, "name": "Blob" }
Et nous avons un Codable Useravec un initialiseur à partir des données json: struct User: Codable { let email: String let id: Int let name: String init?(json: Data) { if let newValue = try? JSONDecoder().decode(User.self, from: json) { self = newValue } else { return nil } } }
Nous pouvons très facilement obtenir un nouvel utilisateur newUseravec un code fonctionnel encore plus simple: let newUser = Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }
De toute évidence, le TYPE newUsersera Optional, c'est-à-direUser? :
 Supposons que nous
Supposons que nous Resourcesayons un autre fichier avec un nom dans l'annuaire invoices.jsonet qui contienne des informations sur les factures de cet utilisateur. [ { "amountPaid": 1000, "amountDue": 0, "closed": true, "id": 1 }, { "amountPaid": 500, "amountDue": 500, "closed": false, "id": 2 } ]
Nous pouvons charger ces données exactement comme nous l'avons fait avec User. Définissons la structure comme un modèle de facture struct Invoice... struct Invoice: Codable { let amountDue: Int let amountPaid: Int let closed: Bool let id: Int }
... et décodez le JSONtableau de factures présenté ci invoices- dessus , en ne modifiant que le chemin d'accès au fichier et la logique de décodage decode: let invoices = Bundle.main.path(forResource: "invoices", ofType: "json") .map( URL.init(fileURLWithPath:) ) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) }
invoices sera [Invoice]? :
 Maintenant, nous souhaitons connecter l'utilisateur
Maintenant, nous souhaitons connecter l'utilisateur userà ses factures invoices, si elles ne sont pas égales nil, et enregistrer, par exemple, dans la structure de l'enveloppe UserEnvelopequi est envoyée à l'utilisateur avec ses factures: struct UserEnvelope { let user: User let invoices: [Invoice] }
Au lieu de jouer deux fois if let... if let newUser = newUser, let invoices = invoices { }
... écrivons un analogue fonctionnel du double if letcomme Genericfonction auxiliaire zipqui convertit deux Optionalvaleurs en un Optionaltuple: func zip<A, B>(_ a: A?, _ b: B?) -> (A, B)? { if let a = a, let b = b { return (a, b) } return nil }
Maintenant, nous n'avons aucune raison d'assigner quelque chose aux variables newUseret invoices, nous construisons tout simplement dans notre nouvelle fonction zip, utilisons l'initialiseur UserEnvelope.initet tout fonctionnera! let userEnv = zip( Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }, Bundle.main.path(forResource: "invoices", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) } ).flatMap (UserEnvelope.init) print ("\(userEnv!)")
Dans une seule expression, un algorithme complet pour fournir des JSONdonnées à une forme complexe struct UserEnvelope.zip , , . user , JSON , invoices , JSON . .map , , «» .flatMap , , , .
Opérations zip, mapet flatMapreprésentent une sorte de langage spécifique au domaine (DSL) pour la conversion des données.Nous pouvons développer cette démonstration pour représenter la lecture asynchrone du contenu d'un fichier comme une fonction spéciale que vous pouvez voir sur pointfree.co .Je ne suis pas un fanatique de la programmation fonctionnelle partout et en tout, mais une utilisation modérée me semble souhaitable.Conclusion
J'ai donné des exemples de divers programmes fonctionnels caractéristiques Swft «hors de la boîte », basée sur l'utilisation des fonctions d'ordre supérieur map, flatMap, reduce, filteret l'autre pour les séquences Sequence, Optionalet Result. Ils peuvent être les «chevaux de bataille» de la création de code, ,surtout si des structet des énumérations y sont impliquées enum. Un développeur d' iOSapplication doit posséder cet outil.Toutes les démos compilées Playgroundpeuvent être trouvées sur Github . Si vous avez des problèmes avec le lancement Playground, vous pouvez voir cet article:Comment se débarrasser des erreurs de «gel» de Xcode Playground avec les messages «Launching Simulator» et «Running Playground».Références:
Functional Programming in Swift: An Introduction.An Introduction to Functional Programming in Swift.The Many Faces of Flat-Map: Part 3Inside the Standard Library: Sequence.map()Practical functional programming in Swift