Les auteurs sont John Hennessey et David Patterson, lauréats du prix Turing 2017 "pour une approche innovante, systématique et mesurable de la conception et du test d'architectures informatiques qui a eu un impact durable sur l'ensemble de l'industrie des microprocesseurs". Article publié dans Communications of the ACM, février 2019, Volume 62, No 2, pp. 48-60, doi: 10.1145 / 3282307 «Ceux qui ne se souviennent pas du passé sont condamnés à le répéter»
«Ceux qui ne se souviennent pas du passé sont condamnés à le répéter» - George Santayana, 1905
Nous avons commencé notre
conférence Turing le 4 juin 2018 avec une revue de l'architecture informatique à partir des années 60. En plus de lui, nous mettons en évidence les problèmes actuels et essayons d'identifier les opportunités futures qui promettent un nouvel âge d'or dans le domaine de l'architecture informatique au cours de la prochaine décennie. La même chose que dans les années 1980, lorsque nous avons mené nos recherches sur l'amélioration du coût, de l'efficacité énergétique, de la sécurité et des performances des processeurs, pour lesquelles nous avons reçu ce prix honorable.
Idées clés
- Le progrès logiciel peut stimuler l'innovation architecturale
- L'augmentation du niveau des interfaces logicielles et matérielles crée des opportunités d'innovation architecturale
- Le marché détermine en fin de compte le gagnant dans le différend d'architecture
Le logiciel "communique" avec l'équipement via un dictionnaire appelé "architecture du jeu d'instructions" (ISA). Au début des années 1960, IBM possédait quatre séries d'ordinateurs incompatibles, chacune avec ses propres ISA, pile logicielle, système d'E / S et niche de marché - orientées respectivement vers les petites entreprises, les grandes entreprises, les applications scientifiques et les systèmes en temps réel. Les ingénieurs d'IBM, dont le lauréat du prix Turing Frederick Brooks Jr., ont décidé de créer un seul ISA qui unit efficacement les quatre.
Ils avaient besoin d'une solution technique sur la façon de fournir un ISA tout aussi rapide pour les ordinateurs équipés de bus 8 bits et 64 bits. Dans un sens, les bus sont les «muscles» des ordinateurs: ils font le travail, mais sont relativement faciles à «compresser» et à «étendre». Autrefois, le plus grand défi pour les concepteurs est le "cerveau" de l'équipement de contrôle du processeur. Inspiré par la programmation, Maurice Wilkes, pionnier de l'informatique et lauréat du prix Turing, a proposé des options pour simplifier ce système. Le contrôle a été présenté comme un tableau bidimensionnel, qu'il a appelé le "magasin de contrôle" (magasin de contrôle).
Chaque colonne de la matrice correspondait à une ligne de contrôle, chaque ligne était une micro-instruction et l'enregistrement des micro-instructions était appelé microprogrammation . La mémoire de contrôle contient un interpréteur ISA écrit par des micro-instructions, donc l'exécution d'une instruction normale prend plusieurs micro-instructions. La mémoire de contrôle est implémentée, en fait, en mémoire, et c'est beaucoup moins cher que les éléments logiques.
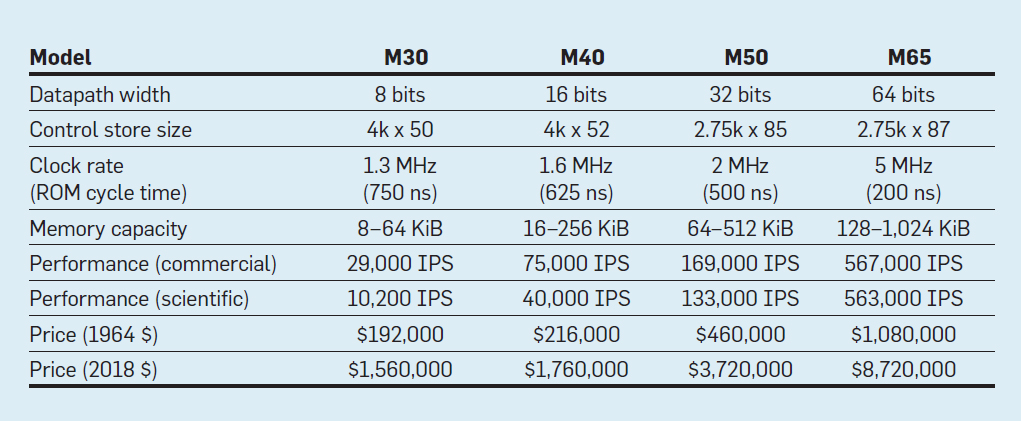 Caractéristiques des quatre modèles de la famille IBM System / 360; IPS signifie opérations par seconde
Caractéristiques des quatre modèles de la famille IBM System / 360; IPS signifie opérations par secondeLe tableau montre quatre modèles de la nouvelle ISA dans System / 360 d'IBM, introduite le 7 avril 1964. Les bus diffèrent de 8 fois, la capacité de mémoire est de 16, la vitesse d'horloge est presque de 4, les performances sont de 50 et le coût est de presque 6. Les ordinateurs les plus chers ont la mémoire de contrôle la plus étendue, car les bus de données plus complexes utilisent plus de lignes de contrôle . Les ordinateurs les moins chers ont moins de mémoire de contrôle en raison d'un matériel plus simple, mais ils avaient besoin de plus de micro-instructions, car ils avaient besoin de plus de cycles d'horloge pour exécuter l'instruction System / 360.
Grâce à la microprogrammation, IBM a parié que la nouvelle ISA va révolutionner l'industrie informatique - et a gagné le pari. IBM a dominé ses marchés et les descendants d'anciens ordinateurs centraux IBM de 55 ans génèrent toujours 10 milliards de dollars de revenus par an.
Comme cela a été noté à plusieurs reprises, bien que le marché soit un arbitre imparfait en tant que technologie, mais étant donné les liens étroits entre l'architecture et les ordinateurs commerciaux, il détermine en fin de compte le succès des innovations architecturales, qui nécessitent souvent d'importants investissements en ingénierie.
Circuits intégrés, CISC, 432, 8086, IBM PC
Lorsque les ordinateurs sont passés aux circuits intégrés, la loi de Moore signifiait que la mémoire de contrôle pouvait devenir beaucoup plus grande. À son tour, cela a permis une ISA beaucoup plus complexe. Par exemple, la mémoire de contrôle VAX-11/780 de Digital Equipment Corp. en 1977, il était de 5120 mots en 96 bits, alors que son prédécesseur n'utilisait que 256 mots en 56 bits.
Certains fabricants ont activé le micrologiciel pour certains clients qui peuvent avoir ajouté des fonctionnalités personnalisées. C'est ce qu'on appelle le magasin de contrôle accessible en écriture (WCS). L'ordinateur WCS le plus célèbre était
Alto , que les lauréats du prix Turing Chuck Tucker et Butler Lampson et ses collègues ont créé pour le Xerox Palo Alto Research Center en 1973. C'était vraiment le premier ordinateur personnel: voici le premier écran avec imagerie élément par élément et le premier réseau Ethernet local. Les contrôleurs de l'affichage innovant et de la carte réseau étaient des microprogrammes qui sont stockés dans le WCS avec une capacité de 4096 mots en 32 bits.
Dans les années 70, les processeurs restaient toujours 8 bits (par exemple, Intel 8080) et étaient programmés principalement en assembleur. Les concurrents ont ajouté de nouvelles instructions pour se surpasser, montrant leurs réalisations avec des exemples d'assembleurs.
Gordon Moore pensait que la prochaine ISA d'Intel durerait pour toujours pour l'entreprise, il a donc embauché beaucoup de médecins intelligents en informatique et les a envoyés dans une nouvelle installation à Portland pour inventer la prochaine grande ISA. Le processeur 8800, comme Intel l'appelait à l'origine, était un projet d'architecture informatique absolument ambitieux pour toutes les époques, et c'était certainement le projet le plus agressif des années 80. Il comprenait un adressage basé sur les capacités 32 bits, une architecture orientée objet, des instructions de longueur variable et son propre système d'exploitation dans le nouveau langage de programmation Ada.
Malheureusement, ce projet ambitieux a nécessité plusieurs années de développement, ce qui a obligé Intel à lancer un projet de sauvegarde d'urgence à Santa Clara afin de sortir rapidement un processeur 16 bits en 1979. Intel a donné à la nouvelle équipe 52 semaines pour développer la nouvelle ISA "8086", concevoir et construire la puce. Compte tenu d'un calendrier serré, la conception d'ISA n'a pris que 10 semaines-personne pendant trois semaines civiles régulières, principalement en raison de l'extension des registres 8 bits et d'un ensemble d'instructions 8080 à 16 bits. L'équipe a achevé 8086 dans les délais, mais ce processeur crash-made a été annoncé sans grande fanfare.
Intel a eu beaucoup de chance qu'IBM développe un ordinateur personnel pour concurrencer l'Apple II et avait besoin d'un microprocesseur 16 bits. IBM envisageait le Motorola 68000 avec un ISA similaire à l'IBM 360, mais il était derrière le calendrier agressif d'IBM. Au lieu de cela, IBM est passé à la version 8 bits du bus 8086. Quand IBM a annoncé le PC le 12 août 1981, il espérait vendre 250 000 ordinateurs d'ici 1986. Au lieu de cela, la société a vendu 100 millions de dollars dans le monde, présentant un avenir très prometteur pour l'ISA d'urgence d'Intel.
Le projet Intel 8800 d'origine a été renommé iAPX-432. Enfin, il a été annoncé en 1981, mais il nécessitait plusieurs puces et avait de sérieux problèmes de performances. Il a été achevé en 1986, un an après qu'Intel ait étendu l'ISA 8086 16 bits à 80386, faisant passer les registres de 16 bits à 32 bits. Ainsi, la prédiction de Moore concernant l'ISA s'est avérée correcte, mais le marché a choisi le 8086 fabriqué en deux, plutôt que l'iAPX-432 oint. Comme les architectes des processeurs Motorola 68000 et iAPX-432 l'ont compris, le marché est rarement capable de faire preuve de patience.
Du jeu d'instructions complexe au jeu abrégé
Au début des années 1980, plusieurs études sur les ordinateurs avec un ensemble d'instructions complexes (CISC) ont été menées: ils ont de grands microprogrammes dans une grande mémoire de contrôle. Lorsque Unix a démontré que même le système d'exploitation peut être écrit dans un langage de haut niveau, la question principale était: "Quelles instructions les compilateurs généreront-ils?" au lieu de l'ancien "Quel assembleur les programmeurs utiliseront-ils?" Une augmentation significative du niveau de l'interface matériel-logiciel a créé une opportunité pour l'innovation en architecture.
Le lauréat du prix Turing John Kokk et ses collègues ont développé des ISA et des compilateurs de mini-ordinateurs plus simples. À titre d'expérience, ils ont réorienté leurs compilateurs de recherche vers l'utilisation de l'IBM 360 ISA pour n'utiliser que des opérations simples entre les registres et le chargement avec de la mémoire, en évitant des instructions plus complexes. Ils ont remarqué que les programmes s'exécutent trois fois plus vite s'ils utilisent un simple sous-ensemble. Emer et Clark ont
constaté que 20% des instructions VAX occupent 60% du microcode et ne prennent que 0,2% du temps d'exécution. Un auteur de cet article (Patterson) a passé des vacances créatives au DEC, contribuant à réduire les erreurs dans le microcode VAX. Si les fabricants de microprocesseurs devaient suivre les conceptions ISA avec un ensemble de commandes CISC complexes dans de grands ordinateurs, ils s'attendaient à un grand nombre d'erreurs de microcode et voulaient trouver un moyen de les corriger. Il a écrit
un tel article , mais
le magazine
Computer l' a rejeté. Les examinateurs ont suggéré que la terrible idée de construire des microprocesseurs avec ISA est si complexe qu'ils doivent être réparés sur le terrain. Cet échec a jeté un doute sur la valeur du CISC pour les microprocesseurs. Ironiquement, les microprocesseurs CISC modernes incluent des mécanismes de récupération de microcode, mais le refus de publier l'article a inspiré l'auteur à développer une ISA moins complexe pour les microprocesseurs - des ordinateurs avec un jeu d'instructions réduit (RISC).
Ces commentaires et la transition vers des langues de haut niveau ont permis la transition du CISC au RISC. Tout d'abord, les instructions RISC sont simplifiées, il n'y a donc pas besoin d'un interprète. Les instructions RISC sont généralement simples comme des micro-instructions et peuvent être exécutées directement par le matériel. Deuxièmement, la mémoire rapide qui était auparavant utilisée pour l'interpréteur de microcode CISC a été repensée dans le cache d'instructions RISC (le cache est une petite mémoire rapide qui met en mémoire tampon les instructions récemment exécutées, car ces instructions sont susceptibles d'être réutilisées dans un avenir proche). Troisièmement,
les allocateurs de registres basés sur le schéma de coloration du graphique de Gregory Chaitin ont grandement facilité l'utilisation efficace des registres pour les compilateurs, qui bénéficiaient de ces ISA avec les opérations registre-registre. Enfin, la loi de Moore a conduit au fait que dans les années 1980, il y avait suffisamment de transistors sur une puce pour accueillir un bus 32 bits complet sur une seule puce, ainsi que des caches pour les instructions et les données.
Par exemple, sur la fig. La figure 1 montre les microprocesseurs
RISC-I et
MIPS développés à l'Université de Californie à Berkeley et à l'Université de Stanford en 1982 et 1983, qui ont démontré les avantages du RISC. En conséquence, en 1984, ces processeurs ont été présentés à la principale conférence sur la conception des circuits, la Conférence internationale des circuits à semi-conducteurs de l'IEEE (
1 ,
2 ). Ce fut un moment merveilleux lorsque plusieurs étudiants diplômés de Berkeley et Stanford ont créé des microprocesseurs qui dépassaient les capacités de l'industrie de cette époque.
 Fig. 1. Processeurs RISC-I de l'Université de Californie à Berkeley et MIPS de l'Université de Stanford
Fig. 1. Processeurs RISC-I de l'Université de Californie à Berkeley et MIPS de l'Université de StanfordCes puces académiques ont inspiré de nombreuses entreprises à créer des microprocesseurs RISC, qui ont été les plus rapides au cours des 15 prochaines années. L'explication est liée à la formule de performances de processeur suivante:
Temps / Programme = (Instructions / Programme) × (mesures / instruction) × (temps / mesure)Les ingénieurs de DEC ont
montré plus tard que pour un programme, les CISC plus complexes nécessitent 75% du nombre d'instructions RISC (le premier terme de la formule), mais dans une technologie similaire (troisième terme), chaque instruction CISC prend 5-6 cycles de plus (deuxième terme), ce qui rend les microprocesseurs RISC environ 4 fois plus rapides.
Il n'y avait pas de telles formules dans la littérature informatique des années 80, ce qui nous a fait écrire le livre
Computer Architecture: A Quantitective Approach en 1989. Le sous-titre explique le thème du livre: utiliser des mesures et des repères pour quantifier les compromis, plutôt que de s'appuyer sur l'intuition et l'expérience du concepteur, comme par le passé. Notre approche quantitative a également été inspirée par ce que
le livre du lauréat Turing Donald Knuth a fait pour les algorithmes.
VLIW, EPIC, Itanium
La prochaine ISA innovante devait dépasser le succès du RISC et du CISC. La très longue
architecture d' instructions machine
VLIW et son cousin EPIC (Computing with explicit machine instruction parallelism) d'Intel et Hewlett-Packard utilisaient des instructions longues, chacune composée de plusieurs opérations indépendantes liées entre elles. Les partisans de VLIW et d'EPIC à l'époque croyaient que si une instruction pouvait indiquer, disons, six opérations indépendantes - deux transferts de données, deux opérations entières et deux opérations en virgule flottante - et la technologie du compilateur pourrait affecter efficacement les opérations à six emplacements d'instruction, alors l'équipement peut être simplifié. Semblable à l'approche de RISC, VLIW et EPIC ont transféré le travail du matériel au compilateur.
Ensemble, Intel et Hewlett-Packard ont développé un processeur EPIC 64 bits pour remplacer l'architecture x86 32 bits. De grandes attentes étaient placées sur le premier processeur EPIC appelé Itanium, mais la réalité ne correspondait pas aux premières déclarations des développeurs. Bien que l'approche EPIC ait bien fonctionné pour les programmes à virgule flottante hautement structurés, elle n'a pas pu atteindre de hautes performances pour les programmes entiers avec des branchements et des échecs de cache moins prévisibles. Comme Donald Knuth l'a
noté plus tard: "Itanium était censé être ... génial - jusqu'à ce qu'il s'avère que les compilateurs souhaités étaient fondamentalement impossibles à écrire." Les critiques ont noté des retards dans la libération d'Itanium et l'ont surnommé Itanik en l'honneur du malheureux navire à passagers Titanic. Le marché n'a de nouveau pas fait preuve de patience et a adopté la version 64 bits de x86, et non Itanium, comme successeur.
La bonne nouvelle est que VLIW est toujours adapté à des applications plus spécialisées qui exécutent de petits programmes avec des branches plus simples sans manque de cache, y compris le traitement du signal numérique.
RISC vs CISC à l'ère PC et post-PC
AMD et Intel avaient besoin de 500 équipes de conception et d'une technologie de semi-conducteurs supérieure pour combler l'écart de performances entre x86 et RISC. Encore une fois, par souci de performances grâce au pipeline, un décodeur d'instructions à la volée traduit les instructions x86 complexes en micro-instructions internes de type RISC. AMD et Intel construisent ensuite un pipeline pour leur implémentation. Toutes les idées que les concepteurs de RISC ont utilisées pour améliorer les performances - caches d'instructions et de données séparés, caches de deuxième niveau sur la puce, pipeline profond et réception et exécution simultanées de plusieurs instructions - ont ensuite été incluses dans x86. Au plus fort de l'ère des ordinateurs personnels en 2011, AMD et Intel ont livré environ 350 millions de microprocesseurs x86 par an. Les volumes élevés et les faibles marges de l'industrie signifient également des prix inférieurs à ceux des ordinateurs RISC.
Avec des centaines de millions d'ordinateurs vendus chaque année, les logiciels sont devenus un énorme marché. Alors que les fournisseurs de logiciels Unix devaient publier différentes versions de logiciels pour différentes architectures RISC - Alpha, HP-PA, MIPS, Power et SPARC - les ordinateurs personnels avaient un ISA, les développeurs ont donc publié un logiciel «rétréci» qui n'était compatible binaire qu'avec l'architecture x86. En raison de sa base logicielle beaucoup plus étendue, de performances similaires et de prix plus bas, en 2000, l'architecture x86 dominait les marchés des ordinateurs de bureau et des petits serveurs.
Apple a aidé à inaugurer l'ère post-PC avec l'iPhone en 2007. Au lieu d'acheter des microprocesseurs, les fabricants de smartphones ont créé leurs propres systèmes sur puce (SoC) en utilisant les développements d'autres personnes, y compris les processeurs RISC d'ARM. Ici, les concepteurs sont importants non seulement pour les performances, mais également pour la consommation d'énergie et la surface de la puce, ce qui désavantage l'architecture CISC. En outre, l'Internet des objets a considérablement augmenté à la fois le nombre de processeurs et les compromis nécessaires en termes de taille de puce, de puissance, de coût et de performances. Cette tendance a accru l'importance du temps et du coût de conception, aggravant encore la position des processeurs CISC. Dans l'ère post-PC d'aujourd'hui, les livraisons annuelles de x86 ont chuté de près de 10% depuis le pic de 2011, tandis que les puces RISC sont montées en flèche à 20 milliards.
Aujourd'hui, 99% des processeurs 32 et 64 bits dans le monde sont RISC.En conclusion de cette revue historique, on peut dire que le marché a réglé le différend entre RISC et CISC. Bien que le CISC ait remporté les dernières étapes de l'ère PC, RISC gagne maintenant que l'ère post-PC est arrivée. Il n'y a pas de nouvelles normes ISA au CISC depuis des décennies. À notre grande surprise, le consensus général sur les meilleurs principes ISA pour les processeurs à usage général est toujours en faveur du RISC, 35 ans après son invention.Défis modernes pour l'architecture de processeur
« , , , , » —
(ISA), ISA, ISA . 70- - (MOS), n- (nMOS), (CMOS). MOS — — , ISA.
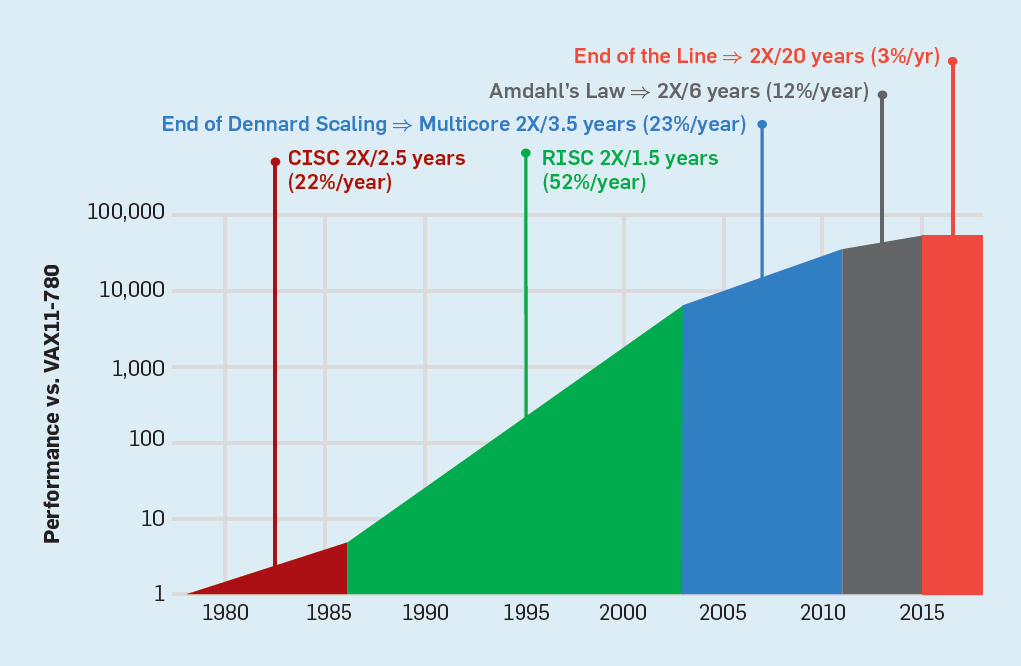
1965 prévoyait un doublement annuel de la densité des transistors; en 1975, il l'a révisé , prévoyant un doublement tous les deux ans. En fin de compte, cette prévision a commencé à s'appeler la loi de Moore. Étant donné que la densité des transistors croît de façon quadratique et que la vitesse croît de façon linéaire, l'utilisation de plus de transistors peut augmenter la productivité.La fin de la loi de Moore et de la loi d'échelle de Dennard
Bien que la loi de Moore soit en vigueur depuis de nombreuses décennies (voir figure 2), vers 2000, elle a commencé à ralentir et, en 2018, l'écart entre les prévisions de Moore et les capacités actuelles s'est agrandi jusqu'à 15 fois. En 2003, Moore a suggéré que c'était inévitable . Il est actuellement prévu que l'écart continuera de s'élargir à mesure que la technologie CMOS approche des limites fondamentales.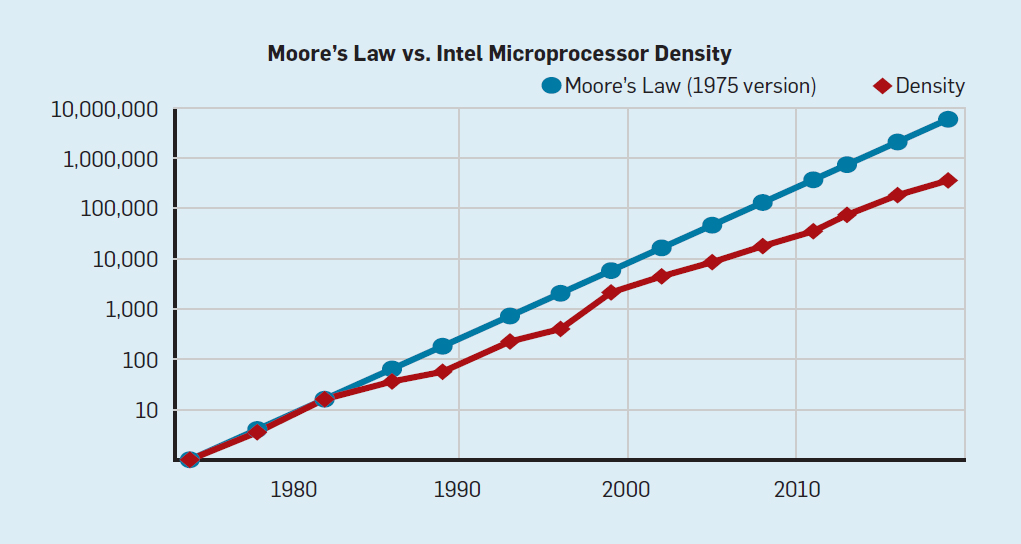 Fig. 2. Le nombre de transistors sur une puce Intel par rapport à laloi de Moore. La loi de Moore était accompagnée d'une projection réalisée par Robert Dennard intitulée "Dennard Scaling"qu'au fur et à mesure que la densité des transistors augmente, la consommation d'énergie du transistor diminue, de sorte que la consommation par mm² de silicium sera presque constante. À mesure que la puissance de calcul d'un millimètre de silicium augmentait à chaque nouvelle génération de technologie, les ordinateurs devenaient plus économes en énergie. La mise à l'échelle de Dennard a commencé à ralentir considérablement en 2007 et, en 2012, elle était pratiquement tombée à néant (voir figure 3).
Fig. 2. Le nombre de transistors sur une puce Intel par rapport à laloi de Moore. La loi de Moore était accompagnée d'une projection réalisée par Robert Dennard intitulée "Dennard Scaling"qu'au fur et à mesure que la densité des transistors augmente, la consommation d'énergie du transistor diminue, de sorte que la consommation par mm² de silicium sera presque constante. À mesure que la puissance de calcul d'un millimètre de silicium augmentait à chaque nouvelle génération de technologie, les ordinateurs devenaient plus économes en énergie. La mise à l'échelle de Dennard a commencé à ralentir considérablement en 2007 et, en 2012, elle était pratiquement tombée à néant (voir figure 3).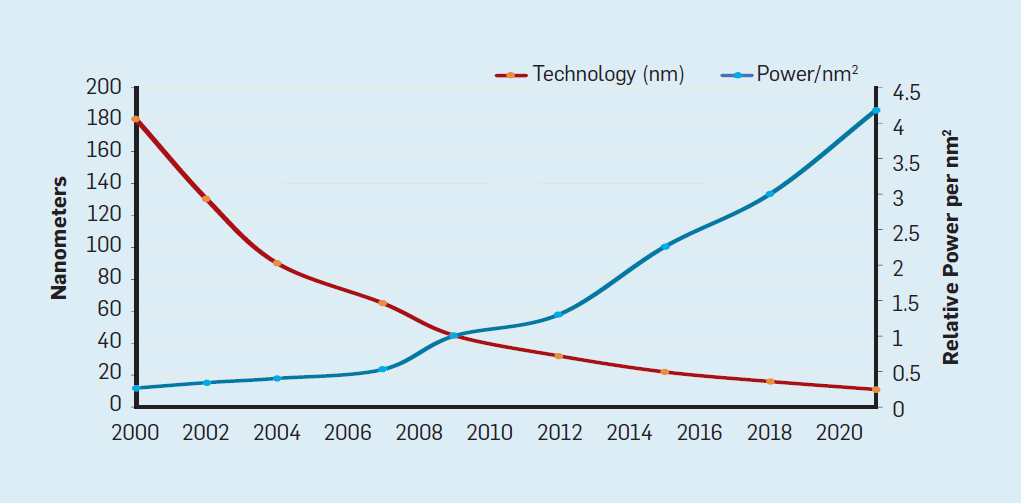 Fig. 3. Le nombre de transistors par puce et la consommation d'énergie par mm²De 1986 à 2002, la concurrence d'accès au niveau d'instruction (ILP) a été la principale méthode architecturale pour augmenter la productivité. Parallèlement à l'augmentation de la vitesse des transistors, cela a donné une augmentation annuelle de la productivité d'environ 50%. La fin de la mise à l'échelle de Dennard signifiait que les architectes devaient trouver de meilleures façons d'utiliser la concurrence.Pour comprendre pourquoi une augmentation de l'efficacité ILP a réduit l'efficacité, considérez le cœur des processeurs ARM, Intel et AMD modernes. Supposons qu'il dispose d'un pipeline à 15 étapes et de quatre instructions par horloge. Ainsi, à tout moment sur le convoyeur il y a jusqu'à 60 instructions, dont une quinzaine de succursales, puisqu'elles représentent environ 25% des instructions exécutées. Pour remplir le pipeline, des branches sont prédites et le code est placé de manière spéculative dans le pipeline pour exécution. La prévision spéculative est à la fois la source des performances et de l'inefficacité de l'ILP. Lorsque la prédiction de branche est idéale, la spéculation améliore les performances et n'augmente que légèrement la consommation d'énergie - et peut même économiser de l'énergie - mais lorsque les branches ne sont pas prédites correctement, le processeur doit jeter les mauvais calculs.et tout le travail et l'énergie gaspillés. L'état interne du processeur devra également être rétabli dans l'état qui existait avant la branche mal comprise, au détriment du temps et de l'énergie supplémentaires.Pour comprendre la complexité d'une telle conception, imaginez la difficulté de prédire correctement les résultats de 15 branches. Si le concepteur du processeur fixe une limite de 10% de perte, le processeur doit prédire correctement chaque branche avec une précision de 99,3%. Il n'y a pas beaucoup de programmes de branche à usage général qui peuvent être prédits avec autant de précision.Pour évaluer en quoi consiste ce travail gaspillé, considérez les données de la Fig. 4, montrant la proportion d'instructions qui sont exécutées efficacement mais qui sont gaspillées car le processeur a incorrectement prédit la ramification. Dans les tests SPEC sur Intel Core i7, en moyenne 19% des instructions sont perdues. Cependant, la quantité d'énergie dépensée est plus grande, car le processeur doit utiliser de l'énergie supplémentaire pour restaurer l'état lorsqu'il est incorrectement prédit.
Fig. 3. Le nombre de transistors par puce et la consommation d'énergie par mm²De 1986 à 2002, la concurrence d'accès au niveau d'instruction (ILP) a été la principale méthode architecturale pour augmenter la productivité. Parallèlement à l'augmentation de la vitesse des transistors, cela a donné une augmentation annuelle de la productivité d'environ 50%. La fin de la mise à l'échelle de Dennard signifiait que les architectes devaient trouver de meilleures façons d'utiliser la concurrence.Pour comprendre pourquoi une augmentation de l'efficacité ILP a réduit l'efficacité, considérez le cœur des processeurs ARM, Intel et AMD modernes. Supposons qu'il dispose d'un pipeline à 15 étapes et de quatre instructions par horloge. Ainsi, à tout moment sur le convoyeur il y a jusqu'à 60 instructions, dont une quinzaine de succursales, puisqu'elles représentent environ 25% des instructions exécutées. Pour remplir le pipeline, des branches sont prédites et le code est placé de manière spéculative dans le pipeline pour exécution. La prévision spéculative est à la fois la source des performances et de l'inefficacité de l'ILP. Lorsque la prédiction de branche est idéale, la spéculation améliore les performances et n'augmente que légèrement la consommation d'énergie - et peut même économiser de l'énergie - mais lorsque les branches ne sont pas prédites correctement, le processeur doit jeter les mauvais calculs.et tout le travail et l'énergie gaspillés. L'état interne du processeur devra également être rétabli dans l'état qui existait avant la branche mal comprise, au détriment du temps et de l'énergie supplémentaires.Pour comprendre la complexité d'une telle conception, imaginez la difficulté de prédire correctement les résultats de 15 branches. Si le concepteur du processeur fixe une limite de 10% de perte, le processeur doit prédire correctement chaque branche avec une précision de 99,3%. Il n'y a pas beaucoup de programmes de branche à usage général qui peuvent être prédits avec autant de précision.Pour évaluer en quoi consiste ce travail gaspillé, considérez les données de la Fig. 4, montrant la proportion d'instructions qui sont exécutées efficacement mais qui sont gaspillées car le processeur a incorrectement prédit la ramification. Dans les tests SPEC sur Intel Core i7, en moyenne 19% des instructions sont perdues. Cependant, la quantité d'énergie dépensée est plus grande, car le processeur doit utiliser de l'énergie supplémentaire pour restaurer l'état lorsqu'il est incorrectement prédit.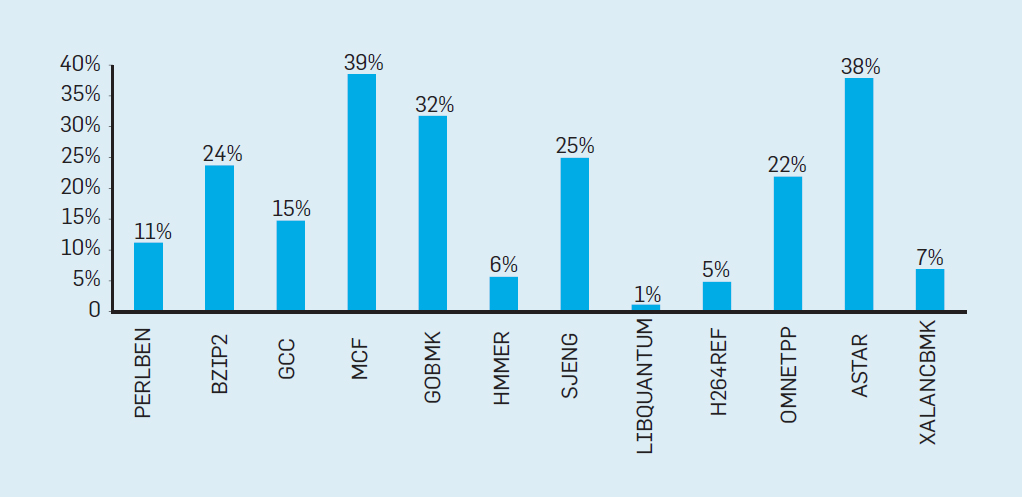 Fig.4. Gaspillage d'instructions en pourcentage de toutes les instructions exécutées sur Intel Core i7 pour divers tests SPEC entiers.De telles mesures ont conduit beaucoup à conclure qu'une approche différente devrait être recherchée pour obtenir de meilleures performances. L'ère du multicœur est donc née.Dans ce concept, la responsabilité d'identifier la concurrence et de décider comment l'utiliser est transférée au programmeur et au système de langage. Le multicœur ne résout pas le problème de l'informatique écoénergétique, aggravé par la fin de la mise à l'échelle de Dennard. Chaque cœur actif consomme de l'énergie, qu'il soit impliqué dans des calculs efficaces. L'obstacle principal est une vieille observation appelée loi d'Amdahl. Il indique que les avantages du calcul parallèle sont limités par la fraction du calcul séquentiel. Pour évaluer l'importance de cette observation, considérons la figure 5. Elle montre à quelle vitesse l'application fonctionne avec 64 cœurs par rapport à un cœur, en supposant une proportion différente de calculs séquentiels lorsqu'un seul processeur est actif. Par exemplesi 1% du temps le calcul est effectué séquentiellement, l'avantage de la configuration à 64 processeurs n'est que de 35%. Malheureusement, la consommation d'énergie est proportionnelle à 64 processeurs, donc environ 45% de l'énergie est gaspillée.
Fig.4. Gaspillage d'instructions en pourcentage de toutes les instructions exécutées sur Intel Core i7 pour divers tests SPEC entiers.De telles mesures ont conduit beaucoup à conclure qu'une approche différente devrait être recherchée pour obtenir de meilleures performances. L'ère du multicœur est donc née.Dans ce concept, la responsabilité d'identifier la concurrence et de décider comment l'utiliser est transférée au programmeur et au système de langage. Le multicœur ne résout pas le problème de l'informatique écoénergétique, aggravé par la fin de la mise à l'échelle de Dennard. Chaque cœur actif consomme de l'énergie, qu'il soit impliqué dans des calculs efficaces. L'obstacle principal est une vieille observation appelée loi d'Amdahl. Il indique que les avantages du calcul parallèle sont limités par la fraction du calcul séquentiel. Pour évaluer l'importance de cette observation, considérons la figure 5. Elle montre à quelle vitesse l'application fonctionne avec 64 cœurs par rapport à un cœur, en supposant une proportion différente de calculs séquentiels lorsqu'un seul processeur est actif. Par exemplesi 1% du temps le calcul est effectué séquentiellement, l'avantage de la configuration à 64 processeurs n'est que de 35%. Malheureusement, la consommation d'énergie est proportionnelle à 64 processeurs, donc environ 45% de l'énergie est gaspillée.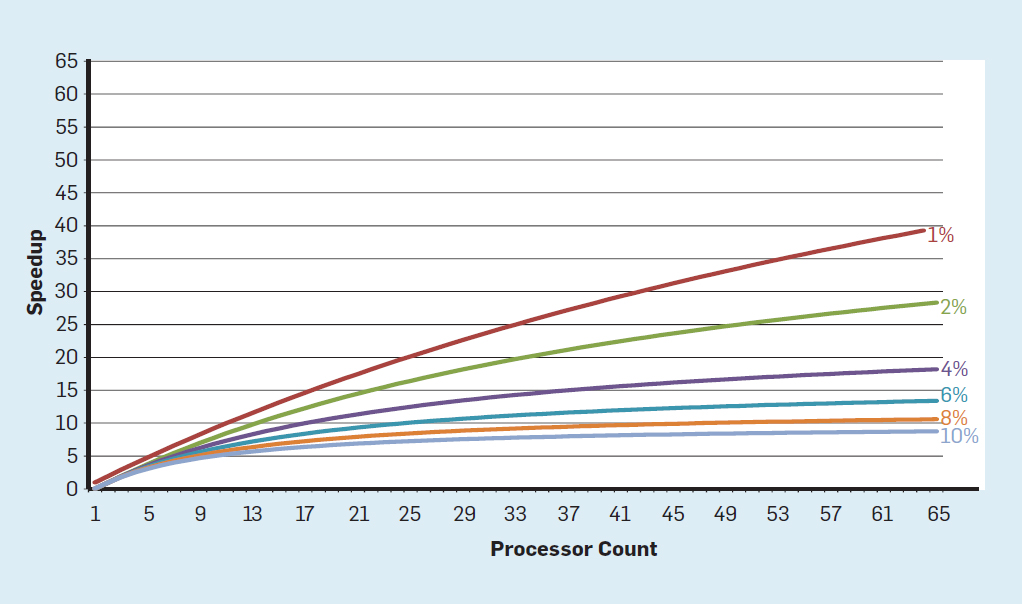 Fig. 5. L'effet de la loi d'Amdahl sur l'augmentation de la vitesse, en tenant compte de la proportion de mesures en mode séquentiel.Bien entendu, les programmes réels ont une structure plus complexe. Il existe des fragments qui vous permettent d'utiliser à tout moment un nombre différent de processeurs. Cependant, la nécessité d'interagir périodiquement et de les synchroniser signifie que la plupart des applications ont certaines parties qui ne peuvent utiliser efficacement qu'une partie des processeurs. Bien que la loi d'Amdahl ait plus de 50 ans, elle reste un obstacle difficile.Avec la fin de la mise à l'échelle de Dennard, une augmentation du nombre de cœurs sur la puce signifiait que la puissance augmentait également presque au même rythme. Malheureusement, la tension fournie au processeur doit alors être supprimée sous forme de chaleur. Ainsi, les processeurs multicœurs sont limités par la puissance de sortie thermique (TDP) ou la quantité moyenne d'énergie que le châssis et le système de refroidissement peuvent supprimer. Bien que certains centres de données haut de gamme utilisent des technologies de refroidissement plus avancées, aucun utilisateur ne voudra mettre un petit échangeur de chaleur sur la table ou transporter un radiateur sur le dos pour refroidir le téléphone mobile. La limite TDP a conduit à l'ère du silicium noir, lorsque les processeurs ralentissent la vitesse d'horloge et désactivent les cœurs inactifs pour éviter la surchauffe. Une autre façon de considérer cette approche est deque certains microcircuits peuvent redistribuer leur précieux pouvoir des noyaux inactifs aux noyaux actifs.
Fig. 5. L'effet de la loi d'Amdahl sur l'augmentation de la vitesse, en tenant compte de la proportion de mesures en mode séquentiel.Bien entendu, les programmes réels ont une structure plus complexe. Il existe des fragments qui vous permettent d'utiliser à tout moment un nombre différent de processeurs. Cependant, la nécessité d'interagir périodiquement et de les synchroniser signifie que la plupart des applications ont certaines parties qui ne peuvent utiliser efficacement qu'une partie des processeurs. Bien que la loi d'Amdahl ait plus de 50 ans, elle reste un obstacle difficile.Avec la fin de la mise à l'échelle de Dennard, une augmentation du nombre de cœurs sur la puce signifiait que la puissance augmentait également presque au même rythme. Malheureusement, la tension fournie au processeur doit alors être supprimée sous forme de chaleur. Ainsi, les processeurs multicœurs sont limités par la puissance de sortie thermique (TDP) ou la quantité moyenne d'énergie que le châssis et le système de refroidissement peuvent supprimer. Bien que certains centres de données haut de gamme utilisent des technologies de refroidissement plus avancées, aucun utilisateur ne voudra mettre un petit échangeur de chaleur sur la table ou transporter un radiateur sur le dos pour refroidir le téléphone mobile. La limite TDP a conduit à l'ère du silicium noir, lorsque les processeurs ralentissent la vitesse d'horloge et désactivent les cœurs inactifs pour éviter la surchauffe. Une autre façon de considérer cette approche est deque certains microcircuits peuvent redistribuer leur précieux pouvoir des noyaux inactifs aux noyaux actifs., , , (. . 6).
 . 6. (SPECintCPU)
. 6. (SPECintCPU)— 80- 90- — , . , — .
Dans les années 70, les développeurs de processeurs ont diligemment assuré la sécurité informatique à l'aide de divers concepts, allant des anneaux de protection aux fonctions spéciales. Ils comprenaient bien que la plupart des bogues se trouveraient dans le logiciel, mais pensaient que le support architectural pouvait aider. Ces fonctionnalités n'étaient généralement pas utilisées par les systèmes d'exploitation qui fonctionnaient dans des environnements supposés sûrs (comme les ordinateurs personnels). Par conséquent, les fonctions associées à une surcharge importante ont été supprimées. Dans la communauté des logiciels, beaucoup pensaient que des tests formels et des méthodes comme l'utilisation d'un micro-noyau fourniraient des mécanismes efficaces pour créer des logiciels hautement sécurisés. Malheureusement, l'ampleur de nos systèmes logiciels communs et la recherche de performances signifiaient que de telles méthodes ne pouvaient pas suivre les performances. En conséquence, les grands systèmes logiciels présentent encore de nombreuses failles de sécurité, et l'effet est amplifié en raison de la quantité énorme et croissante d'informations personnelles sur Internet et de l'utilisation du cloud computing, où les utilisateurs partagent le même équipement physique avec un attaquant potentiel.
Bien que les concepteurs de processeurs et d'autres n'aient peut-être pas tout de suite compris l'importance croissante de la sécurité, ils ont commencé à inclure la prise en charge matérielle des machines virtuelles et le chiffrement. Malheureusement, la prédiction de branche a introduit une faille de sécurité inconnue mais significative dans de nombreux processeurs. En particulier, les
vulnérabilités Meltdown et Spectre exploitent les fonctionnalités de microarchitecture, permettant la fuite d'informations protégées . Ils utilisent tous deux les soi-disant attaques sur des canaux tiers lorsque des informations fuient en fonction de la différence de temps passé sur la tâche. En 2018, les chercheurs ont montré
comment utiliser l'une des options Spectre pour extraire des informations sur le réseau sans télécharger de code vers le processeur cible . Bien que cette attaque, appelée NetSpectre, transfère lentement les informations, le fait qu'elle vous permette d'attaquer n'importe quelle machine sur le même réseau local (ou dans le même cluster dans le cloud) crée de nombreux nouveaux vecteurs d'attaque. Par la suite, deux autres vulnérabilités dans l'architecture des machines virtuelles ont été signalées (
1 ,
2 ). L'un d'eux, appelé Foreshadow, vous permet de pénétrer les mécanismes de sécurité Intel SGX conçus pour protéger les données les plus précieuses (telles que les clés de chiffrement). De nouvelles vulnérabilités sont trouvées chaque mois.
Les attaques sur les canaux tiers ne sont pas nouvelles, mais dans la plupart des cas, les bogues logiciels étaient la faute plus tôt. Dans Meltdown, Spectre et d'autres attaques, il s'agit d'une faille dans l'implémentation matérielle. Il y a une difficulté fondamentale dans la façon dont les architectes de processeurs déterminent quelle est la bonne implémentation d'ISA car la définition standard ne dit rien sur les effets de performance de l'exécution d'une séquence d'instructions, seulement l'état architectural visible d'exécution de l'ISA. Les architectes devraient repenser leur définition de la bonne mise en œuvre d'ISA pour éviter de telles failles de sécurité. Dans le même temps, ils doivent repenser l'attention qu'ils accordent à la sécurité informatique et la façon dont les architectes peuvent travailler avec les développeurs de logiciels pour mettre en œuvre des systèmes plus sécurisés. Les architectes (et tout le monde) ne devraient pas prendre la sécurité autrement que comme un besoin principal.
Opportunités futures en architecture informatique
«Nous avons d'incroyables opportunités déguisées en problèmes insolubles.» - John Gardner, 1965
L'inefficacité inhérente des processeurs à usage général, qu'il s'agisse de la technologie ILP ou des processeurs multicœurs, combinée à l'achèvement de la mise à l'échelle de Dennard et à la loi de Moore, il est peu probable que les architectes et les développeurs de processeurs soient en mesure de maintenir un rythme significatif dans l'amélioration des performances des processeurs à usage général. Étant donné l'importance d'améliorer la productivité des logiciels, nous devons nous poser la question suivante: quelles sont les autres approches prometteuses?
Il y a deux possibilités évidentes, ainsi qu'une troisième créée en combinant les deux. Premièrement, les méthodes de développement de logiciels existantes utilisent largement des langages de haut niveau avec une frappe dynamique. Malheureusement, ces langues sont généralement interprétées et exécutées de manière extrêmement inefficace. Pour illustrer cette inefficacité, Leiserson et ses collègues ont
donné un petit exemple: la multiplication matricielle .
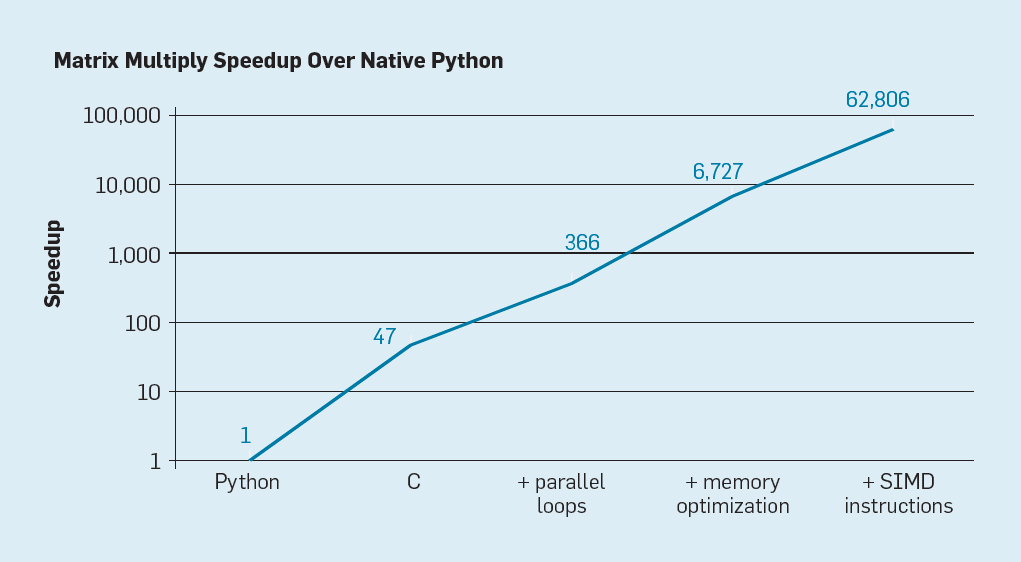 Fig. 7. Accélération potentielle de la multiplication des matrices Python après quatre optimisations
Fig. 7. Accélération potentielle de la multiplication des matrices Python après quatre optimisationsComme le montre la fig. 7, la simple réécriture du code de Python vers C améliore les performances de 47 fois. L'utilisation de boucles parallèles sur de nombreux cœurs donne un facteur supplémentaire d'environ 7. L'optimisation de la structure de la mémoire pour l'utilisation des caches donne un facteur de 20, et le dernier facteur de 9 provient de l'utilisation d'extensions matérielles pour effectuer des opérations SIMD parallèles, qui sont capables d'exécuter 16 instructions 32 bits. Après cela, la version finale hautement optimisée s'exécute sur le processeur multicœur d'Intel 62 806 fois plus rapidement que la version Python d'origine. Ceci, bien sûr, est un petit exemple. On peut supposer que les programmeurs utiliseront une bibliothèque optimisée. Bien que l'écart de performances soit exagéré, il existe probablement de nombreux programmes qui peuvent être optimisés 100 à 1000 fois.
Un domaine de recherche intéressant est la question de savoir s'il est possible de combler certains écarts de performances avec la nouvelle technologie de compilateur, éventuellement avec des améliorations architecturales. Bien qu'il soit difficile de traduire et de compiler efficacement des langages de script de haut niveau tels que Python, le gain potentiel est énorme. Même une petite optimisation peut conduire au fait que les programmes Python s'exécuteront des dizaines à des centaines de fois plus rapidement. Cet exemple simple montre l'ampleur de l'écart entre les langages modernes axés sur les performances des programmeurs et les approches traditionnelles qui mettent l'accent sur les performances.
Architectures spécialisées
Une approche plus orientée matériel est la conception d'architectures adaptées à un domaine spécifique, où elles démontrent une efficacité significative. Il s'agit d'architectures spécifiques au domaine (architectures spécifiques au domaine, DSA). Ce sont généralement des processeurs programmables et complets, mais prenant en compte une classe spécifique de tâches. En ce sens, ils diffèrent des circuits intégrés spécifiques à l'application (ASIC), qui sont souvent utilisés pour la même fonction que le code qui change rarement. Les DSA sont souvent appelés accélérateurs, car ils accélèrent certaines applications par rapport à l'exécution de l'application entière sur un CPU à usage général. De plus, les DSA peuvent offrir de meilleures performances car ils sont plus précisément adaptés aux besoins de l'application. Les exemples de DSA incluent les processeurs graphiques (GPU), les processeurs de réseau neuronal utilisés pour l'apprentissage en profondeur et les processeurs pour les réseaux définis par logiciel (SDN). Les DSA atteignent des performances et une efficacité énergétique supérieures pour quatre raisons principales.
Premièrement, les DSA utilisent une forme de concurrence plus efficace pour un domaine spécifique. Par exemple, SIMD (flux d'instructions unique, flux de données multiples) est
plus efficace que MIMD (flux d'instructions multiples, flux de données multiples). Bien que SIMD soit moins flexible, il est bien adapté à de nombreux DSA. Les processeurs spécialisés peuvent également utiliser les approches ILP de VLIW au lieu de mécanismes peu spéculatifs. Comme mentionné précédemment,
les processeurs VLIW sont mal adaptés au code à usage général , mais pour les zones étroites, ils sont beaucoup plus efficaces car les mécanismes de contrôle sont plus simples. En particulier, les processeurs polyvalents les plus haut de gamme sont excessivement multi-pipelined, ce qui nécessite une logique de contrôle complexe pour démarrer et terminer les instructions. En revanche, VLIW effectue l'analyse et la planification nécessaires au moment de la compilation, ce qui peut bien fonctionner pour un programme clairement parallèle.
Deuxièmement, les services DSA utilisent mieux la hiérarchie de la mémoire. L'accès à la mémoire est devenu beaucoup plus cher que les calculs arithmétiques,
comme l'a noté Horowitz . Par exemple, l'accès à un bloc dans un cache de 32 Ko nécessite environ 200 fois plus d'énergie que l'ajout d'entiers 32 bits. Une telle différence énorme rend l'optimisation de l'accès à la mémoire critique pour atteindre une efficacité énergétique élevée. Les processeurs à usage général exécutent du code dans lequel les accès à la mémoire présentent généralement une localité spatiale et temporelle, mais sont par ailleurs peu prévisibles au moment de la compilation. Par conséquent, pour augmenter le débit, les processeurs utilisent des caches à plusieurs niveaux et masquent le retard dans les DRAM relativement lentes en dehors de la puce. Ces caches à plusieurs niveaux consomment souvent environ la moitié de l'énergie du processeur, mais ils empêchent presque tous les appels à la DRAM, ce qui prend environ 10 fois plus d'énergie que l'accès au cache de dernier niveau.
Les caches ont deux défauts notables.
Lorsque les ensembles de données sont très volumineux . Les caches ne fonctionnent tout simplement pas bien lorsque les ensembles de données sont très volumineux, ont une faible localisation temporelle ou spatiale.
Quand les caches fonctionnent bien . Lorsque les caches fonctionnent bien, la localité est très élevée, c'est-à-dire que, par définition, la majeure partie du cache est inactive la plupart du temps.
Dans les applications où les modèles d'accès à la mémoire sont bien définis et compréhensibles au moment de la compilation, ce qui est vrai pour les langages spécifiques à un domaine (DSL), les programmeurs et les compilateurs peuvent optimiser l'utilisation de la mémoire mieux que les caches alloués dynamiquement. Ainsi, les DSA utilisent généralement une hiérarchie de mémoire mobile qui est explicitement contrôlée par le logiciel, semblable au fonctionnement des processeurs vectoriels. Dans les applications correspondantes, le contrôle de mémoire utilisateur «manuel» vous permet de dépenser beaucoup moins d'énergie que le cache standard.
Troisièmement, DSA peut réduire la précision des calculs si une précision élevée n'est pas nécessaire. Les processeurs à usage général prennent généralement en charge les calculs d'entiers 32 bits et 64 bits, ainsi que les données à virgule flottante (FP). Pour de nombreuses applications d'apprentissage automatique et de graphisme, il s'agit d'une précision redondante. Par exemple, dans les réseaux de neurones profonds, le calcul utilise souvent des nombres de 4, 8 ou 16 bits, améliorant à la fois le débit de données et la puissance de traitement. De même, les calculs en virgule flottante sont utiles pour la formation des réseaux de neurones, mais 32 bits, et souvent 16 bits, suffisent.
Enfin, les DSA bénéficient de programmes écrits dans des langages spécifiques au domaine qui permettent plus de simultanéité, améliorent la structure, la présentation de l'accès à la mémoire et simplifient la superposition d'application efficace sur un processeur dédié.
Langues orientées sujet
Les DSA nécessitent que les opérations de niveau supérieur soient adaptées à l'architecture du processeur, mais il est très difficile de le faire dans un langage général tel que Python, Java, C ou Fortran. Les langages spécifiques au domaine (DSL) aident à cela et vous permettent de programmer efficacement les DSA. Par exemple, les DSL peuvent rendre explicites les opérations vectorielles explicites, à matrice dense et à matrice clairsemée, permettant au compilateur DSL de mapper efficacement les opérations au processeur. Parmi les langages spécifiques au domaine, on trouve Matlab, un langage pour travailler avec des matrices, TensorFlow pour programmer des réseaux de neurones, P4 pour programmer des réseaux définis par logiciel et Halide pour traiter des images avec des transformations de haut niveau.
Le problème du DSL est de savoir comment maintenir une indépendance architecturale suffisante pour que le logiciel puisse être porté sur diverses architectures, tout en atteignant une grande efficacité lors de la comparaison de logiciels avec un DSA de base. Par exemple,
un système XLA traduit le code
Tensorflow en systèmes hétérogènes avec des GPU Nvidia ou des processeurs tenseurs (TPU). Équilibrer la portabilité entre les DSA tout en maintenant l'efficacité est une tâche de recherche intéressante pour les développeurs de langage, les compilateurs et les DSA eux-mêmes.
Exemple de DSA: TPU v1
À titre d'exemple de DSA, considérons Google TPU v1, qui est conçu pour accélérer le fonctionnement d'un réseau de neurones (
1 ,
2 ). Ce TPU a été produit depuis 2015, et de nombreuses applications ont été exécutées dessus: des requêtes de recherche à la traduction de texte et à la reconnaissance d'images dans AlphaGo et AlphaZero, des programmes DeepMind pour jouer au go et aux échecs. L'objectif était d'augmenter de 10 fois la productivité et l'efficacité énergétique des réseaux de neurones profonds.
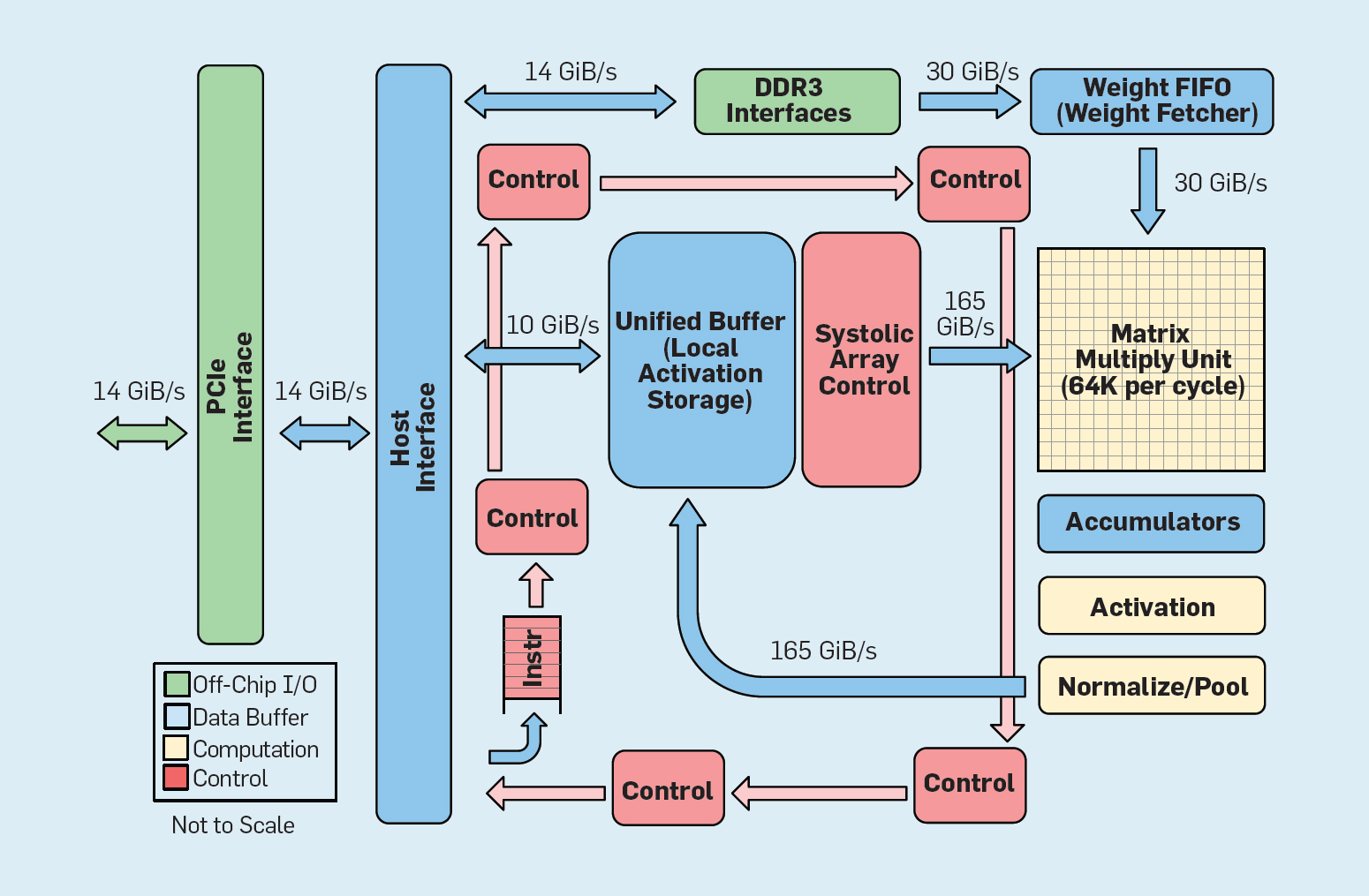 Fig. 8. Organisation fonctionnelle Google Tensor Processing Unit (TPU v1)
Fig. 8. Organisation fonctionnelle Google Tensor Processing Unit (TPU v1)Comme le montre la figure 8, l'organisation d'un TPU est radicalement différente d'un processeur à usage général. L'unité de calcul principale est l'unité matricielle, la
structure des réseaux systoliques , qui chaque cycle produit 256 × 256 multiplier-accumuler. La combinaison d'une précision de 8 bits, d'une structure systolique très efficace, d'un contrôle SIMD et de l'allocation d'une partie importante de la puce pour cette fonction aide à effectuer environ 100 fois plus d'opérations de multiplication d'accumulation par cycle qu'un cœur de processeur à usage général. Au lieu des caches, TPU utilise 24 Mo de mémoire locale, ce qui représente environ le double des caches CPU à usage général de 2015 avec le même TDP. Enfin, la mémoire d'activation des neurones et la mémoire d'équilibre du réseau neuronal (y compris la structure FIFO qui stocke les poids) sont connectées via des canaux à grande vitesse contrôlés par l'utilisateur. Les performances TPU moyennes pondérées pour six problèmes typiques de sortie logique des réseaux de neurones dans les centres de données Google sont 29 fois supérieures à celles des processeurs à usage général. Étant donné que les TPU nécessitent moins de la moitié de la puissance, son efficacité énergétique pour cette charge de travail est plus de 80 fois supérieure à celle des processeurs universels.
Résumé
Nous avons examiné deux approches différentes pour améliorer les performances du programme en augmentant l'efficacité de l'utilisation des technologies matérielles. Premièrement, en augmentant la productivité des langues modernes de haut niveau qui sont généralement interprétées. Deuxièmement, en créant des architectures pour des domaines spécifiques, qui améliorent considérablement les performances et l'efficacité par rapport aux processeurs à usage général. Les langages spécifiques au domaine sont un autre exemple de la façon d'améliorer l'interface matériel-logiciel qui permet des innovations architecturales telles que DSA. Pour obtenir un succès significatif en utilisant de telles approches, une équipe de projet intégrée verticalement sera nécessaire qui est versée dans les applications, les langages thématiques et les technologies de compilation connexes, l'architecture informatique, ainsi que la technologie de mise en œuvre de base. Le besoin d'intégration verticale et de prise de décisions de conception à différents niveaux d'abstraction était typique de la plupart des premiers travaux dans le domaine de la technologie informatique avant que l'industrie ne soit structurée horizontalement. Dans cette nouvelle ère, l'intégration verticale est devenue plus importante. Des avantages seront accordés aux équipes capables de trouver et d'accepter des compromis et des optimisations complexes.
Cette opportunité a déjà conduit à une vague d'innovation architecturale, attirant de nombreuses philosophies architecturales concurrentes:
GPU Les GPU Nvidia
utilisent plusieurs cœurs, chacun avec des fichiers de registre volumineux, plusieurs flux matériels et des caches.
TPU Les
TPU de Google
reposent sur de grandes matrices systoliques bidimensionnelles et une mémoire programmable sur puce.
FPGA Microsoft Corporation dans ses centres de données
implémente des matrices de portes programmables par l'utilisateur (FPGA), qui sont utilisées dans les applications de réseau neuronal.
CPU Intel propose des processeurs avec de nombreux cœurs, un grand cache à plusieurs niveaux et des instructions SIMD unidimensionnelles, d'une certaine manière comme le FPGA de Microsoft, et le
nouveau neuroprocesseur est plus proche du TPU que du CPU .
En plus de ces acteurs majeurs, des
dizaines de startups mettent en œuvre leurs propres idées . Pour répondre à la demande croissante, les concepteurs combinent des centaines et des milliers de puces pour créer des superordinateurs de réseau neuronal.
Cette avalanche d'architectures de réseaux de neurones indique qu'un moment intéressant est venu dans l'histoire de l'architecture informatique. En 2019, il est difficile de prédire lequel de ces nombreux domaines gagnera (si quelqu'un gagne du tout), mais le marché déterminera certainement le résultat, tout comme il a réglé le débat architectural du passé.
Architecture ouverte
Suivant l'exemple d'un logiciel open source réussi, l'open ISA représente une opportunité alternative en architecture informatique. Ils sont nécessaires pour créer une sorte de «Linux pour les processeurs», afin que la communauté puisse créer des noyaux open source en plus des entreprises individuelles qui possèdent des noyaux propriétaires. Si de nombreuses organisations conçoivent des processeurs utilisant la même ISA, une concurrence accrue peut conduire à une innovation encore plus rapide. L'objectif est de fournir une architecture pour les processeurs coûtant de quelques centimes à 100 $.
Le premier exemple est RISC-V (RISC Five), la
cinquième architecture RISC développée à l'Université de Californie à Berkeley . Elle est soutenue par une communauté dirigée par
la Fondation RISC-V .
L'ouverture de l'architecture permet de faire évoluer l'ISA aux yeux du public, avec la participation d'experts jusqu'à la prise de décision finale. Un avantage supplémentaire d'un fonds ouvert est qu'il est peu probable que l'ISA se développe principalement pour des raisons de marketing, car c'est parfois la seule explication de l'expansion de leurs propres ensembles d'instructions.RISC-V est un jeu d'instructions modulaire. Une petite base d'instructions lance une pile logicielle open source complète, suivie d'extensions standard supplémentaires que les concepteurs peuvent activer ou désactiver en fonction de leurs besoins. Cette base de données contient des versions 32 et 64 bits des adresses. RISC-V ne peut se développer que grâce à des extensions facultatives; la pile logicielle fonctionnera toujours bien, même si les architectes n'acceptent pas les nouvelles extensions. Les architectures propriétaires nécessitent généralement une compatibilité ascendante au niveau binaire: cela signifie que si la société de traitement ajoute une nouvelle fonctionnalité, tous les futurs processeurs devraient également l'inclure. RISC-V ne le fait pas, ici toutes les améliorations sont facultatives et peuvent être supprimées si l'application n'en a pas besoin.Voici les extensions standard pour le moment, avec les premières lettres du nom complet:- M. Multiplication / division d'un entier.
- A. Opérations de mémoire atomique.
- F / d. Opérations en virgule flottante simple / double précision.
- C. Instructions compressées.
La troisième caractéristique de RISC-V est la simplicité de l'ISA. Bien que cet indicateur ne soit pas quantifiable, voici deux comparaisons avec l'architecture ARMv8, qui a été développée en parallèle par ARM:- Moins d'instructions . RISC-V contient beaucoup moins d'instructions. Il y en a 50 dans la base de données, et ils sont étonnamment similaires en nombre et en caractère au RISC-I d'origine . Le reste des extensions standard (M, A, F et D) ajoute 53 instructions, plus C en ajoute 34 de plus, donc le nombre total est de 137. Pour comparaison, ARMv8 a plus de 500 instructions.
- . RISC-V : , ARMv8 14.
La simplicité simplifie à la fois la conception de la conception des processeurs et la vérification de leur exactitude. Parce que RISC-V se concentre sur tout, des centres de données aux appareils IoT, la validation de la conception peut représenter une part importante des coûts de développement.Quatrièmement, RISC-V est une conception vierge après 25 ans, où les architectes apprennent des erreurs de leurs prédécesseurs. Contrairement à l'architecture RISC de première génération, elle évite la microarchitecture ou les fonctions qui dépendent de la technologie (telles que les branches différées et les téléchargements différés) ou des innovations (telles que les fenêtres de registre), qui ont été supplantées par les avancées du compilateur.Enfin, RISC-V prend en charge DSA, réservant un espace opcode étendu pour les accélérateurs personnalisés.En plus de RISC-V, Nvidia a également annoncé (en 2017)Une architecture libre et ouverte , elle l'appelle Nvidia Deep Learning Accelerator (NVDLA). Il s'agit d'un DSA évolutif et personnalisable pour l'inférence dans l'apprentissage automatique. Les paramètres de configuration incluent le type de données (int8, int16 ou fp16) et la taille de la matrice de multiplication bidimensionnelle. L'échelle du substrat de silicium varie de 0,5 mm² à 3 mm², et la consommation d'énergie est de 20 mW à 300 mW. ISA, la pile logicielle et l'implémentation sont ouvertes.Des architectures ouvertes et simples vont bien avec la sécurité. Premièrement, les experts en sécurité ne croient pas à la sécurité par l'obscurité, les implémentations open source sont donc attrayantes et les implémentations open source nécessitent une architecture ouverte. Tout aussi importante est l'augmentation du nombre de personnes et d'organisations qui peuvent innover dans le domaine des architectures sécurisées. Les architectures propriétaires limitent la participation des employés, mais les architectures ouvertes permettent aux meilleurs cerveaux du monde universitaire et de l'industrie d'aider à la sécurité. Enfin, la simplicité de RISC-V simplifie la vérification de ses implémentations. De plus, les architectures ouvertes, les implémentations et les piles de logiciels, ainsi que la flexibilité des FPGA, permettent aux architectes de déployer et d'évaluer de nouvelles solutions en ligne avec des cycles de publication hebdomadaires plutôt qu'annuels. Bien que les FPGA soient 10 fois plus lents que les puces personnalisées,mais leurs performances sont suffisantes pour travailler en ligne et présenter des innovations de sécurité devant de vrais attaquants pour vérification. Nous nous attendons à ce que les architectures ouvertes soient des exemples de conception collaborative de matériel et de logiciels par des architectes et des experts en sécurité.Développement matériel flexible
The Flexible Software Development Manifesto (2001) Beck et al.Révolutionné le développement de logiciels en éliminant les problèmes d'un système de cascade traditionnel basé sur la planification et la documentation. De petites équipes de programmeurs créent rapidement des prototypes fonctionnels mais incomplets et reçoivent les commentaires des clients avant de commencer la prochaine itération. La version Scrum d'Agile rassemble des équipes de cinq à dix programmeurs qui sprint pendant deux à quatre semaines par itération.Après avoir repris l'idée du développement logiciel, il est possible d'organiser un développement matériel flexible. La bonne nouvelle est que les outils modernes de conception assistée par ordinateur (ECAD) ont augmenté le niveau d'abstraction, permettant un développement flexible. Ce niveau d'abstraction plus élevé augmente également le niveau de réutilisation du travail entre différentes conceptions.Les sprints de quatre semaines semblent peu plausibles pour les processeurs, étant donné les mois entre la création du design et la production de puces. Dans la fig. La figure 9 montre comment une méthode flexible peut fonctionner en modifiant un prototype à un niveau approprié .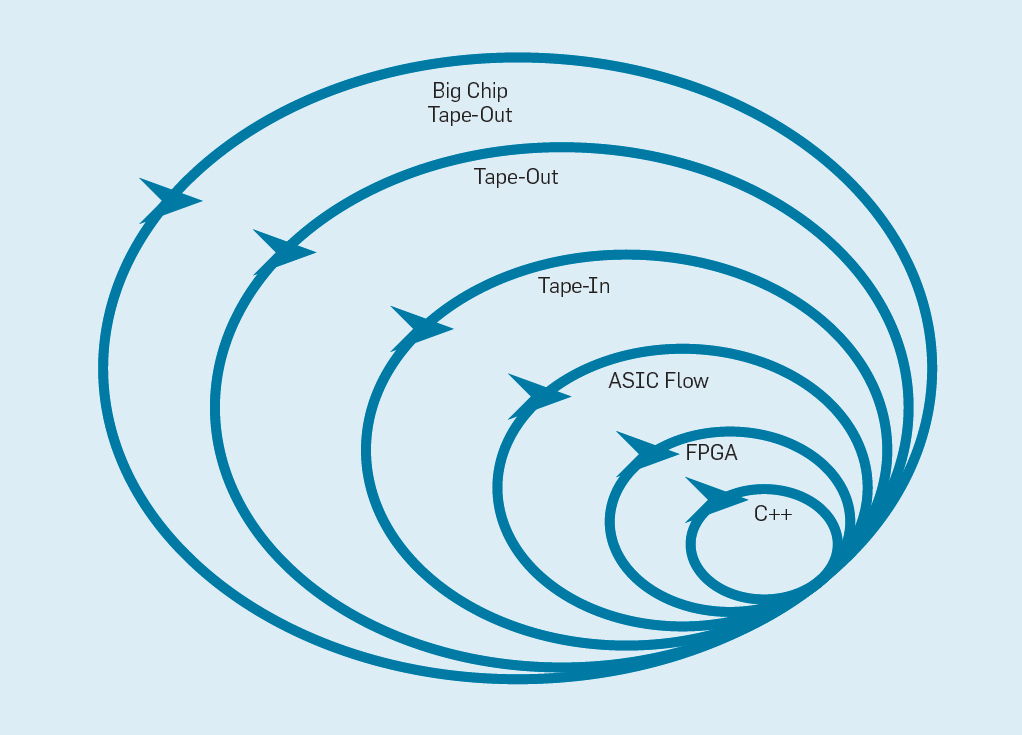 Fig. 9. Méthodologie flexible de développement de l'équipementLe niveau le plus intérieur est un simulateur de logiciel, l'endroit le plus simple et le plus rapide pour effectuer des changements. Le niveau suivant est celui des puces FPGA, qui peuvent fonctionner des centaines de fois plus rapidement qu'un simulateur logiciel détaillé. Les FPGA peuvent fonctionner avec des systèmes d'exploitation et des références complètes, telles que la Standard Performance Evaluation Corporation (SPEC), qui permet une évaluation beaucoup plus précise des prototypes. Amazon Web Services propose des FPGA dans le cloud, afin que les architectes puissent utiliser des FPGA sans avoir à acheter d’équipement ni à installer un laboratoire. Le niveau suivant utilise des outils ECAD pour générer un circuit à puce, pour documenter la taille et la consommation d'énergie. Même après le travail des outils, il est nécessaire de suivre certaines étapes manuelles pour affiner les résultats avant d'envoyer le nouveau processeur en production.Les développeurs de processeurs appellent ce niveau supérieur.bande . Ces quatre premiers niveaux prennent en charge les sprints de quatre semaines.À des fins de recherche, nous pourrions nous arrêter au niveau quatre, car les estimations de la superficie, de l'énergie et des performances sont très précises. Mais c’est comme si un coureur a couru un marathon et s’est arrêté 5 mètres avant l’arrivée, car son temps d’arrivée est déjà clair. Malgré la préparation difficile du marathon, il manquera le frisson et le plaisir de franchir la ligne d'arrivée. L'un des avantages des ingénieurs en matériel par rapport aux ingénieurs en logiciel est qu'ils créent des choses physiques. Obtenir des puces de l'usine: mesurer, exécuter de vrais programmes, les montrer à des amis et à la famille est une grande joie pour le concepteur.De nombreux chercheurs pensent qu'ils devraient arrêter parce que la fabrication de puces est trop abordable. Mais si le design est petit, il est étonnamment bon marché. Les ingénieurs peuvent commander 100 micropuces de 1 mm² pour seulement 14 000 $. À 28 nm, une puce de 1 mm² contient des millions de transistors: cela suffit pour le processeur RISC-V et l'accélérateur NVLDA. Le niveau le plus externe est cher si le concepteur a l'intention de créer une grande puce, mais de nombreuses nouvelles idées peuvent être démontrées sur de petites puces.
Fig. 9. Méthodologie flexible de développement de l'équipementLe niveau le plus intérieur est un simulateur de logiciel, l'endroit le plus simple et le plus rapide pour effectuer des changements. Le niveau suivant est celui des puces FPGA, qui peuvent fonctionner des centaines de fois plus rapidement qu'un simulateur logiciel détaillé. Les FPGA peuvent fonctionner avec des systèmes d'exploitation et des références complètes, telles que la Standard Performance Evaluation Corporation (SPEC), qui permet une évaluation beaucoup plus précise des prototypes. Amazon Web Services propose des FPGA dans le cloud, afin que les architectes puissent utiliser des FPGA sans avoir à acheter d’équipement ni à installer un laboratoire. Le niveau suivant utilise des outils ECAD pour générer un circuit à puce, pour documenter la taille et la consommation d'énergie. Même après le travail des outils, il est nécessaire de suivre certaines étapes manuelles pour affiner les résultats avant d'envoyer le nouveau processeur en production.Les développeurs de processeurs appellent ce niveau supérieur.bande . Ces quatre premiers niveaux prennent en charge les sprints de quatre semaines.À des fins de recherche, nous pourrions nous arrêter au niveau quatre, car les estimations de la superficie, de l'énergie et des performances sont très précises. Mais c’est comme si un coureur a couru un marathon et s’est arrêté 5 mètres avant l’arrivée, car son temps d’arrivée est déjà clair. Malgré la préparation difficile du marathon, il manquera le frisson et le plaisir de franchir la ligne d'arrivée. L'un des avantages des ingénieurs en matériel par rapport aux ingénieurs en logiciel est qu'ils créent des choses physiques. Obtenir des puces de l'usine: mesurer, exécuter de vrais programmes, les montrer à des amis et à la famille est une grande joie pour le concepteur.De nombreux chercheurs pensent qu'ils devraient arrêter parce que la fabrication de puces est trop abordable. Mais si le design est petit, il est étonnamment bon marché. Les ingénieurs peuvent commander 100 micropuces de 1 mm² pour seulement 14 000 $. À 28 nm, une puce de 1 mm² contient des millions de transistors: cela suffit pour le processeur RISC-V et l'accélérateur NVLDA. Le niveau le plus externe est cher si le concepteur a l'intention de créer une grande puce, mais de nombreuses nouvelles idées peuvent être démontrées sur de petites puces.Conclusion
« — » — , 1650
, , , / . iAPX-432 Itanium , , S/360, 8086 ARM , .
L'achèvement de la loi de Moore et la mise à l'échelle de Dennard, ainsi que le ralentissement des performances des microprocesseurs standard, ne sont pas des problèmes qui devraient être résolus, mais un fait qui, comme vous le savez, offre des opportunités intéressantes. Les langages et architectures de haut niveau axés sur les matières, libérés des chaînes de jeux d'instructions propriétaires, ainsi que la demande du public pour une sécurité accrue, ouvriront un nouvel âge d'or pour l'architecture informatique. Dans les écosystèmes open source, les puces conçues artificiellement démontreront de manière convaincante les réalisations et accéléreront ainsi la mise en œuvre commerciale. La philosophie du processeur à usage général dans ces puces est probablement RISC, qui a résisté à l'épreuve du temps. Attendez-vous à la même innovation rapide que vous avez fait au cours du dernier âge d'or,mais cette fois en termes de coût, d'énergie et de sécurité, pas seulement de performances., .