De nombreuses organisations, notamment financières, doivent faire face à diverses normes de sécurité - par exemple, PCI DSS. Ces certifications nécessitent un cryptage des données. Cryptage transparent des données sur disque Le cryptage transparent des données est implémenté dans de nombreux SGBD industriels.
Apache Ignite est utilisé dans les banques, par conséquent, il a été décidé d'y implémenter TDE.
Je vais décrire comment nous avons développé TDE à travers la communauté, publiquement, via les processus Apachev.
Voici une version texte du rapport:
J'essaierai de parler de l'architecture, de la complexité du développement, de son aspect réel en open source.
Qu'est-ce qui a été fait et que reste-t-il à faire?
Apache Ignite TDE actuellement implémenté. Phase 1.
Il comprend les fonctionnalités de base de l'utilisation de caches chiffrées:
- Gestion des clés
- Création de caches chiffrées
- Enregistrement de toutes les données de cache sur le disque sous forme cryptée
Dans la phase 2, il est prévu d'activer la possibilité de rotation (changement) de la clé principale.
Dans la phase 3, la possibilité de faire pivoter les clés de cache.
Terminologie
- Chiffrement transparent des données - chiffrement transparent (pour l'utilisateur) des données lors de l'enregistrement sur le disque. Dans le cas d'Ignite, le cryptage du cache, car Ignite concerne les caches.
- Ignite cache - cache de valeurs-clés dans Apache Ignite. Les données du cache peuvent être enregistrées sur le disque
- Pages - pages de données. Dans Ignite, toutes les données sont paginées. Les pages sont écrites sur le disque et doivent être cryptées.
- WAL - écrire le journal à l'avance. Toutes les modifications de données dans Ignite y sont enregistrées, toutes les actions que nous avons effectuées pour tous les caches.
- Keystore - keystore java standard, qui est généré par keytool Javascript. Il fonctionne et est certifié partout, nous l'avons utilisé.
- Clé principale - clé principale. En l'utilisant, les clés des tables sont cryptées, les clés de cryptage du cache. Stocké dans le magasin de clés java.
- Clés de cache - clés avec lesquelles les données sont réellement cryptées. Avec la clé principale, une structure à deux niveaux est obtenue. La clé principale est stockée séparément du cache de clés et des données de base - à des fins de sécurité, de séparation des droits d'accès, etc.
L'architecture
Tout est mis en œuvre selon le schéma suivant:
- Toutes les données du cache sont cryptées à l'aide du nouveau SPI de cryptage.
- Par défaut, AES est utilisé - un algorithme de chiffrement industriel.
- La clé principale est stockée dans un fichier JKS - un fichier java standard pour les clés.
Les banques et autres organisations utilisent leurs propres algorithmes de chiffrement: GOST et autres. Il est clair que nous avons fourni l'opportunité de glisser notre SPI de chiffrement - l'implémentation de chiffrement dont un utilisateur spécifique a besoin.
Schéma de travail
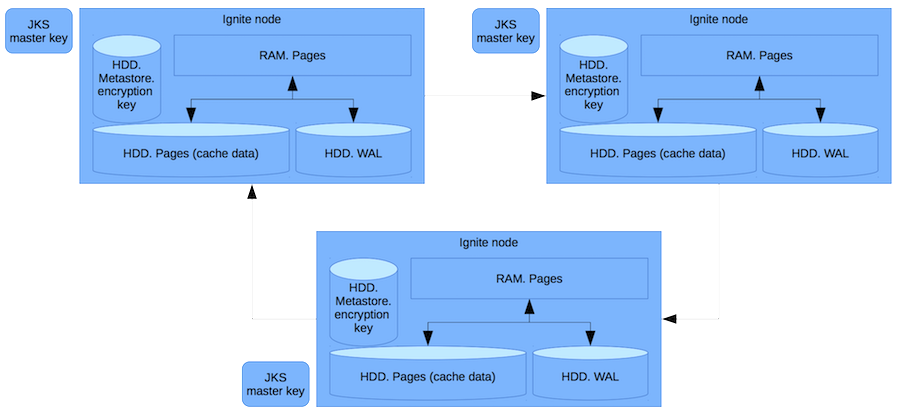
Nous avons donc de la RAM - une mémoire à accès aléatoire avec des pages contenant des données pures. L'utilisation de la RAM implique que nous ne sommes pas protégés contre un pirate qui a obtenu un accès root et a vidé toute la mémoire. Nous nous protégeons de l'administrateur qui prend le disque dur et le vend sur le marché Tushino (ou là où ces données sont actuellement vendues).
En plus des pages avec le cache, les données sont également stockées dans un journal d'écriture anticipée, qui écrit sur le disque le delta des enregistrements modifiés dans la transaction. Le métastore stocke les clés de chiffrement du cache. Et dans un fichier séparé - une clé principale.
Chaque fois qu'une clé pour le cache est créée, avant d'écrire ou de transférer sur le réseau, nous chiffrons cette clé à l'aide d'une clé principale. Pour que personne ne puisse obtenir la clé de cache après avoir reçu les données Ignite. Ce n'est qu'en volant à la fois la clé principale et les données que vous pouvez y accéder. Cela est peu probable, car l'accès à ces fichiers nécessite divers droits.
L'algorithme d'actions est le suivant:
- Au début du nœud, soustrayez la clé principale de jks.
- Au début des nœuds, lisez le méta-magasin et déchiffrez les clés de cache.
- Lorsque vous joignez des nœuds dans un cluster:
- vérifier les hachages de la clé principale.
- Vérifiez les clés pour les caches partagées.
- enregistrer les clés pour les nouveaux caches.
- Lors de la création dynamique d'un cache, nous générons une clé et l'enregistrons dans le méta-magasin.
- Lors de la lecture / écriture d'une page, nous la décryptons / cryptons.
- Chaque entrée WAL pour le cache chiffré est également chiffrée.
Maintenant plus en détail:
Au début du nœud, nous avons un rappel qui lance notre EncryptionSPI. Selon les paramètres, nous soustrayons la clé principale du fichier jks.
Ensuite, lorsque le métastore est prêt, nous obtenons les clés de chiffrement stockées. Dans ce cas, nous avons déjà une clé principale, afin de pouvoir décrypter les clés et accéder aux données du cache.
Séparément, il existe un processus très intéressant - comment joindre un nouveau nœud à un cluster. Nous avons déjà un système distribué composé de plusieurs nœuds. Comment s'assurer que le nouveau nœud est correctement configuré, qu'il ne s'agit pas d'un attaquant?
Nous effectuons ces actions:
- Lorsqu'un nouveau nœud arrive, il envoie un hachage à partir de la clé principale. Nous pensons qu'il correspond à celui existant.
- Ensuite, nous vérifions les clés des caches partagés. Du nœud provient l'identifiant de cache et la clé de cache cryptée. Nous les vérifions pour nous assurer que toutes les données sur tous les nœuds sont cryptées avec la même clé. Si ce n'est pas le cas, nous n'avons tout simplement pas le droit de laisser le nœud dans le cluster, sinon, il se déplacera par clés et données.
- S'il y a de nouvelles clés et caches sur le nouveau nœud, enregistrez-les pour une utilisation future.
- Lors de la création dynamique d'un cache, une fonction de génération de clés est fournie. Nous le générons, l'enregistrons dans le méta-magasin et pouvons continuer à effectuer les opérations décrites.
La deuxième partie est une superstructure sur les opérations d'E / S. Les pages sont écrites dans le fichier de partition. Notre complément examine quelle page cache, les chiffre en conséquence et les enregistre.
Il en va de même pour WAL. Il existe un sérialiseur qui sérialise les objets d'enregistrement WAL. Et si l'enregistrement concerne des caches chiffrés, nous devons le chiffrer et ensuite seulement l'enregistrer sur le disque.
Difficultés de développement
Difficultés communes à tous les projets open source plus ou moins complexes:
- Vous devez d'abord comprendre complètement le dispositif Ignite. Pourquoi, quoi et comment cela a été fait là-bas, comment et dans quels endroits attacher vos gestionnaires.
- Il est nécessaire de fournir une compatibilité descendante. Cela peut être assez difficile, pas évident. Lors du développement d'un produit que d'autres utilisent, vous devez considérer que les utilisateurs souhaitent être mis à jour sans problème. La rétrocompatibilité est bonne et bonne. Lorsque vous apportez une amélioration aussi importante que TDE, vous changez les règles d'enregistrement sur le disque, vous cryptez quelque chose. Et la compatibilité descendante doit être travaillée.
- Un autre point non évident est lié à la distribution de notre système. Lorsque différents clients essaient de créer le même cache, vous devez vous mettre d'accord sur la clé de chiffrement, car par défaut, deux différents seront générés. Nous avons résolu ce problème. Je n'insisterai pas plus en détail - la solution mérite un article séparé. Maintenant, nous sommes garantis d'utiliser une seule clé.
- La prochaine chose importante a conduit à de grandes améliorations, quand il semblait que tout était prêt (une histoire familière?) :). Le chiffrement a des frais généraux. Nous avons un vecteur init - zéro données aléatoires qui est utilisé dans l'algorithme AES. Ils sont stockés sous forme ouverte, et avec leur aide, nous augmentons l'entropie: les mêmes données seront cryptées différemment dans différentes sessions de cryptage. En gros, même si nous avons deux Ivan Petrov avec le même nom de famille, chaque fois que nous chiffrons, nous recevons des données chiffrées différentes. Cela réduit les risques de piratage.
Le chiffrement a lieu par blocs de 16 octets, et si les données ne sont pas alignées sur 16 octets, nous ajoutons des informations de remplissage - la quantité de données que nous avons réellement chiffrées. Sur un disque, vous devez écrire une page qui est un multiple de 2 Ko. Ce sont les exigences de performance: nous devons utiliser le tampon de disque. Si nous n'écrivons pas 2 Ko (pas 4 ou pas 8, selon la mémoire tampon du disque), nous obtenons immédiatement une grosse baisse de performances.
Comment avons-nous résolu le problème? J'ai dû ramper dans PageIO, dans la RAM et couper 16 octets de chaque page, qui seront cryptés lors de l'écriture sur le disque. Dans ces 16 octets, nous écrivons le vecteur init.
- Une autre difficulté est de ne rien casser. C'est une chose courante lorsque vous venez apporter des modifications. En réalité, ce n'est pas aussi simple qu'il y paraît.
- Dans MVP, il s'est avéré 6 000 lignes. C’est difficile à examiner, et peu de gens veulent le faire - en particulier de la part d’experts qui n’ont pas encore le temps. Nous avons différentes parties - API publique, partie principale, gestionnaires SPI, magasin persistant de pages, gestionnaires WAL. Les changements dans divers sous-systèmes nécessitent qu'ils soient examinés par différentes personnes. Et cela impose également des difficultés supplémentaires. Surtout lorsque vous travaillez dans une communauté où tout le monde est occupé par ses tâches. Néanmoins, tout a fonctionné pour nous.
Que se passera-t-il dans TDE.Phase 2 et 3
La phase 1 est maintenant implémentée. En tant que développeur, vous pouvez aider à la phase 2. Les défis à venir sont intéressants. PCI DSS, comme d'autres normes, nécessite des fonctionnalités supplémentaires du système de cryptage. Notre système devrait pouvoir changer la clé principale. Par exemple, s'il a été compromis ou que le temps vient de se conformer à la politique de sécurité. Maintenant Ignite ne sait pas comment. Mais dans les prochaines versions, nous apprendrons à TDE à modifier la clé principale.
La même chose avec la possibilité de changer la clé de cache sans arrêter le cluster et travailler avec des données. Si le cache est de longue durée et stocke en même temps certaines données - financières, médicales - Ignite devrait être en mesure de modifier la clé de cryptage du cache et de rechiffrer tout à la volée. Nous allons résoudre ce problème dans la troisième phase.
Total: Comment implémenter une grosse fonctionnalité dans un projet open source?
Pour résumer. Ils seront pertinents pour toute source ouverte. J'ai participé à Kafka et à d'autres projets - partout l'histoire est la même.
- Commencez par de petites tâches. N'essayez jamais de résoudre un problème très important tout de suite. Il est nécessaire de comprendre ce qui se passe, comment cela se produit, comment cela se réalise. Qui vous aidera. Et en général - de quel côté aborder ce projet.
- Comprenez le projet. Habituellement, tous les développeurs - du moins moi - viennent et disent: tout doit être réécrit. Tout était mauvais avant moi, et maintenant je vais le réécrire - et tout ira bien. Il est conseillé de reporter ces déclarations, de déterminer ce qui est exactement mauvais et s'il faut le changer.
- Discutez si des améliorations sont nécessaires. J'ai eu des cas quand je suis arrivé dans les différentes communautés avec de l'expérience, par exemple à Spark. Il me l'a dit, mais la communauté n'était pas intéressée pour une raison quelconque. En tout cas ça arrive. Vous avez besoin de cette révision, mais la communauté dit: non, nous ne sommes pas intéressés, nous ne fusionnerons pas et ne vous aiderons pas.
- Faites un dessin. Il existe des projets open source dans lesquels cela est obligatoire. Vous ne pouvez pas commencer à coder sans une conception convenue par le comité et des personnes expérimentées. Dans Ignite, ce n'est pas formellement vrai, mais en général, c'est une partie importante du développement. Il est nécessaire de faire une description en anglais ou en russe compétent, selon le projet. Pour que le texte puisse être lu et qu'il soit clair ce que vous allez faire exactement.
- Discutez de l'API publique. L'argument principal: s'il existe une API publique belle et compréhensible, facile à utiliser, la conception est correcte. Ces choses sont généralement adjacentes les unes aux autres.
D'autres conseils plus évidents qui ne sont pas si faciles à suivre:
- Implémentez la fonctionnalité sans rien casser. Faites les tests.
- Demandez et attendez (c'est le plus difficile) une critique des bons gars, des bons membres de la communauté.
- Faites des repères, découvrez si vous avez une baisse de performance. Ceci est particulièrement important lors de la finalisation de certains sous-systèmes critiques.
- Attendez la fusion, faites quelques exemples et documentation.
Merci d'avoir lu!