
Lorsque je me présente et dis ce que fait notre startup, l'interlocuteur pose immédiatement la question: avez-vous déjà travaillé sur Facebook, ou votre développement a-t-il été créé sous l'influence de Facebook? Beaucoup sont conscients des efforts de Facebook pour maintenir son graphique social, car la société a publié
plusieurs articles sur l'infrastructure de ce graphique, qu'elle a soigneusement conçue.
Google a parlé de
son graphique de connaissances , mais rien de l'infrastructure interne. Cependant, la société dispose également de sous-systèmes spécialisés. En fait, une grande attention est accordée au graphique des connaissances. Personnellement, j'ai mis au moins deux de mes promotions sur ce cheval - et j'ai commencé à travailler sur un nouveau graphique en 2010.
Google devait construire l'infrastructure non seulement pour servir des relations complexes dans le Knowledge Graph, mais aussi pour prendre en charge tous les blocs thématiques
OneBox dans les résultats de recherche qui ont accès à des données structurées. L'infrastructure est nécessaire pour 1) un contournement de qualité des faits avec 2) une bande passante suffisamment élevée et 3) un délai suffisamment faible pour parvenir à accéder à une bonne partie des requêtes de recherche sur le Web. Il s'est avéré qu'aucun système ou base de données disponible ne peut effectuer les trois actions.
Maintenant que j'ai expliqué pourquoi une infrastructure est nécessaire, dans le reste de l'article, je parlerai de mon expérience dans la création de tels systèmes, y compris pour
Knowledge Graph et
OneBox .
Comment le sais-je?
Je vais me présenter brièvement. J'ai travaillé chez Google de 2006 à 2013. D'abord en tant que stagiaire, puis en tant qu'ingénieur logiciel dans l'infrastructure de recherche Web. Google a
acquis Metaweb en 2010 et mon équipe vient de lancer
Caffeine . Je voulais faire autre chose - et j'ai commencé à travailler avec les gars de Metaweb (à San Francisco), passant du temps à voyager entre San Francisco et Mountain View. Je voulais découvrir comment utiliser le graphique des connaissances pour améliorer ma recherche sur le Web.
Il y a eu de tels projets sur Google avant moi. Il est à noter que le projet appelé
Squared a été créé dans un bureau de New York, et il a été question de Knowledge Cards. Ensuite, il y a eu des efforts sporadiques d'individus / petites équipes, mais à cette époque, il n'y avait pas de chaîne d'équipe établie, ce qui m'a finalement forcé à quitter Google. Mais nous y reviendrons plus tard ...
Histoire de Metaweb
Comme déjà mentionné, Google a acquis Metaweb en 2010. Metaweb a construit un graphique de connaissances de haute qualité en utilisant plusieurs méthodes, y compris l'exploration et l'analyse de Wikipédia, ainsi qu'un système d'édition de style wiki de crowdsourcing utilisant
Freebase . Tout cela a fonctionné sur la base de la propre base de données graphique de Graphd - le démon graphique (maintenant
publié sur GitHub).
Graphd avait des propriétés assez typiques. En tant que démon, il fonctionnait sur un serveur, stockait toutes les données en mémoire et pouvait émettre un site Freebase complet. Après l'achat, Google a défini l'une des tâches pour continuer à travailler avec Freebase.
Google a bâti un empire sur du matériel standard et des logiciels distribués. Un SGBD côté serveur ne serait jamais en mesure de servir les résultats de l'exploration, de l'indexation et de la recherche. D'abord créé SSTable, puis Bigtable, qui évolue horizontalement sur des centaines ou des milliers de machines qui partagent des pétaoctets de données. Les machines sont attribuées par Borg (
K8 est venu d'ici), elles communiquent via Stubby (gRPC est venu d'ici) avec la résolution des adresses IP via le service de nom Borg (BNC à l'intérieur de K8) et stockent les données dans le système de fichiers Google (
GFS , vous pouvez dire Hadoop FS).
Les processus peuvent mourir, les machines peuvent se briser, mais le système dans son ensemble est indestructible et continuera de bourdonner.Graphd est entré dans un tel environnement. L'idée d'une base de données servant un site Web entier sur un serveur est étrangère à Google (y compris moi). En particulier, Graphd avait besoin de 64 Go ou plus de mémoire pour fonctionner. S'il vous semble que c'est un peu, rappelez-vous: c'est 2010. La plupart des serveurs Google étaient équipés d'un maximum de 32 Go. En fait, Google a dû acheter des machines spéciales avec suffisamment de RAM pour servir Graphd dans sa forme actuelle.
Remplacement de graphd
Le brainstorming a commencé sur la façon de déplacer les données Graphd ou de réécrire le système pour qu'il fonctionne de manière distribuée. Mais, voyez-vous, les graphiques sont compliqués. Ce n'est pas une base de données de valeurs-clés pour vous, où vous pouvez simplement prendre un élément de données, le déplacer vers un autre serveur et le publier lorsque vous demandez une clé. Les graphiques effectuent des jointures et des solutions de contournement efficaces qui nécessitent que les logiciels fonctionnent de manière spécifique.
Une idée était d'utiliser un projet appelé MindMeld (IIRC). Il était supposé que la mémoire d'un autre serveur serait disponible beaucoup plus rapidement via l'équipement réseau. Il aurait dû être plus rapide que les RPC ordinaires, suffisamment rapide pour pseudo-répliquer l'accès direct à la mémoire requis par la base de données en mémoire. Mais l'idée n'est pas allée trop loin.
Une autre idée qui est devenue un projet était de créer un système de service graphique vraiment distribué. Quelque chose qui peut non seulement remplacer Graphd pour Freebase, mais aussi vraiment fonctionner en production.
Elle s'appelait Dgraph - un graphe distribué, inversé de Graphd (graph-daemon).Si vous êtes intéressé, alors oui. Ma startup, Dgraph Labs, la société et le projet open source Dgraph portent le nom de ce projet sur Google (remarque: Dgraph est une marque de commerce de Dgraph Labs; pour autant que je sache, Google ne publie pas de projets dont les noms correspondent aux noms internes).
Dans presque tout le reste du texte, lorsque je mentionne Dgraph, je veux dire le projet Google interne, et non le projet open source que nous avons créé. Mais plus à
ce sujet plus tard.
L'histoire de Cerebro: le moteur du savoir
Création d'une infrastructure par inadvertance pour les graphiquesBien que je sache généralement que Dgraph essayait de remplacer Graphd, mon objectif était de créer quelque chose pour améliorer la recherche sur le Web. Chez Metaweb, j'ai rencontré un ingénieur de recherche DH qui a créé
Cubed .
Comme je l'ai mentionné, un groupe hétéroclite d'ingénieurs de la division de New York a développé Google
Squared . Mais le système DH était
bien meilleur. J'ai commencé à penser comment l'implémenter sur Google. Google avait des pièces de puzzle que je pouvais facilement utiliser.
La première partie du puzzle est le moteur de recherche. C'est un moyen de déterminer avec précision quels mots sont liés les uns aux autres. Par exemple, lorsque vous voyez une phrase comme [tom hanks films], cela peut vous dire que [tom] et [hanks] sont liés. De même, d'après [la météo de san francisco], nous voyons une connexion entre [san] et [francisco]. Ce sont des choses évidentes pour les gens, mais pas si évidentes pour les voitures.
La deuxième partie du puzzle est de comprendre la grammaire. Lorsque dans la requête [livres d'auteurs français], la machine peut interpréter cela comme des [livres] de [auteurs français], c'est-à-dire des livres des auteurs français. Mais elle peut aussi interpréter cela comme [des livres français] de [auteurs], c'est-à-dire des livres en français de n'importe quel auteur. J'ai utilisé le tagger
Part-Of-Speech (POS) de l'Université de Stanford pour mieux analyser la grammaire et construire l'arborescence.
La troisième partie du puzzle est de comprendre les entités. [français] peut signifier beaucoup. Il peut s'agir d'un pays (région), d'une nationalité (liée au peuple français), d'une cuisine (liée à la nourriture) ou d'une langue. J'ai ensuite appliqué un autre système pour obtenir une liste d'entités auxquelles un mot ou une phrase peut correspondre.
La quatrième partie du puzzle était de comprendre la relation entre les entités. Quand on sait comment connecter des mots en phrases, dans quel ordre les phrases doivent être exécutées, c'est-à-dire leur grammaire, et à quelles entités elles peuvent correspondre, vous devez trouver la relation entre ces entités afin de créer des interprétations de machine. Par exemple, nous exécutons la requête [livres d'auteurs français], et POS dit que c'est [livres] de [auteurs français]. Nous avons plusieurs entités pour [français] et plusieurs pour [auteurs]: l'algorithme devrait déterminer comment elles sont liées. Par exemple, ils peuvent être liés par lieu de naissance, c'est-à-dire par des auteurs nés en France (bien qu'ils puissent écrire en anglais). Ou il pourrait s'agir d'auteurs de nationalité française. Soit des auteurs qui parlent ou écrivent le français (mais qui ne sont pas liés à la France en tant que pays), ou des auteurs qui aiment simplement la cuisine française.
Système de graphe d'index de recherche
Pour déterminer s'il existe une connexion entre des objets et comment ils sont connectés, vous avez besoin d'un système de graphes. Graphd n'allait jamais évoluer au niveau de Google, mais vous pouviez utiliser la recherche elle-même. Les données du graphe de connaissances sont stockées au format
Triples triples, c'est-à-dire que chaque fait est représenté par trois parties: sujet (entité), prédicat (relation) et objet (autre entité). Les demandes vont comme
[SP] → [O] ou
[PO] → [S] , et parfois
[SO] → [P] .
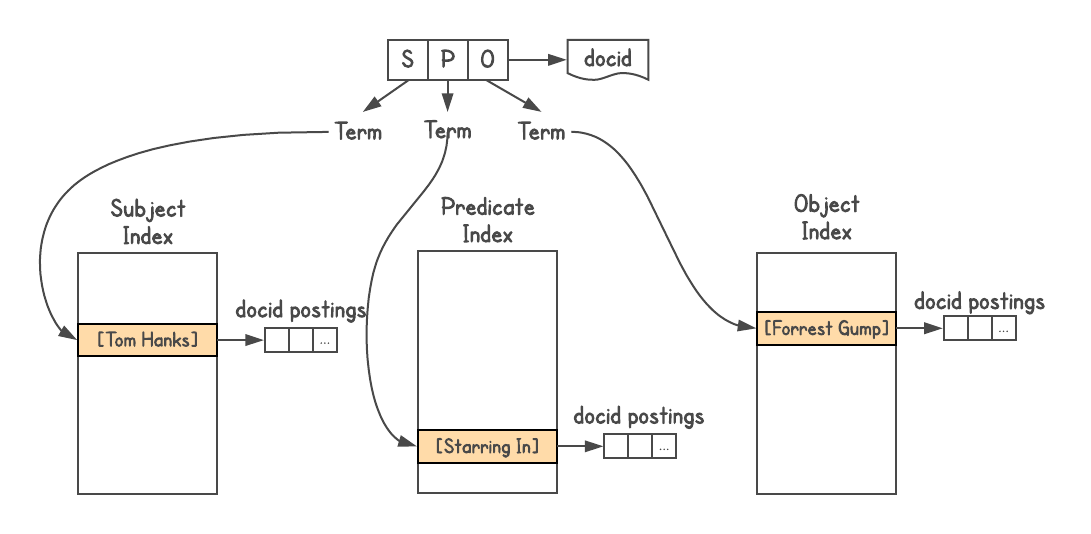 J'ai utilisé l'index de recherche Google
J'ai utilisé l'index de recherche Google , attribué un docid à chaque triple et créé trois index, un pour S, P et O.En outre, l'index est emboîtable, j'ai donc ajouté des informations sur le type de chaque entité (c'est-à-dire, acteur, livre, personne et etc.).
J'ai fait un tel système, bien que j'ai vu un problème avec la profondeur des jointures (ce qui est expliqué ci-dessous) et il ne convient pas aux requêtes complexes. En fait, lorsque quelqu'un de l'équipe Metaweb m'a demandé de publier un système pour mes collègues, j'ai refusé.Pour déterminer la relation, vous pouvez voir le nombre de résultats fournis par chaque requête. Par exemple, combien de résultats [français] et [auteur] donnent-ils? Nous prenons ces résultats et voyons comment ils sont liés aux [livres], etc. Ainsi, de nombreuses interprétations de la requête par la machine sont apparues. Par exemple, la requête [films tom hanks] génère une variété d'interprétations, comme [films réalisés par tom hanks], [films avec tom hanks], [films produits par tom hanks], mais rejette automatiquement les interprétations comme [films nommés tom hanks].
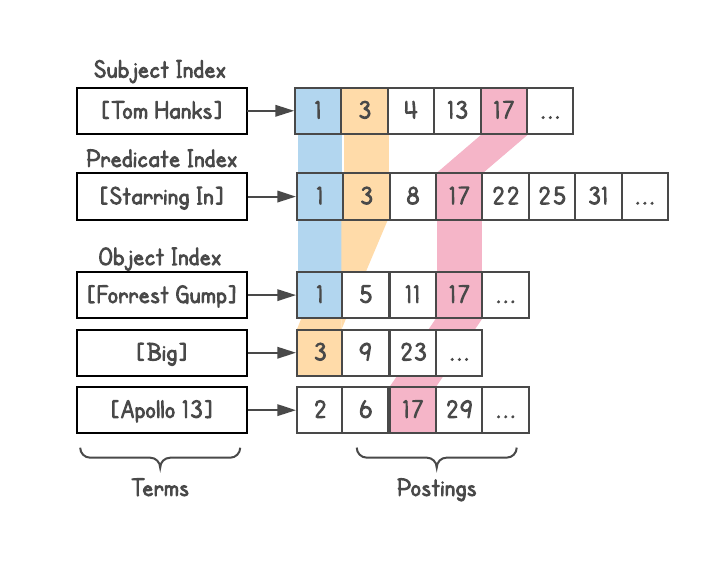
Chaque interprétation génère une liste de résultats - entités valides sur le graphique - et renvoie également leurs types (présents dans les pièces jointes). Cela s'est avéré être une fonction extrêmement puissante car la compréhension du type de résultats a ouvert des possibilités telles que le filtrage, le tri ou l'expansion. Vous pouvez trier les films avec l'année de sortie, la durée du film (court, long), la langue, les récompenses reçues, etc.
Le projet semblait si intelligent que nous (DH était également partiellement impliqué en tant qu'expert sur le graphe des connaissances) l'avons nommé Cerebro, en l'honneur de l'appareil du même nom du film
"X-Men" .
Cerebro a souvent révélé des faits très intéressants qui n'étaient pas à l'origine dans la requête de recherche. Par exemple, à la demande des [présidents américains], Cerebro se rendra compte que les présidents sont des personnes et que les gens ont une croissance. Cela nous permet de trier les présidents par croissance et de montrer qu'Abraham Lincoln est le plus haut président des États-Unis. De plus, les personnes peuvent être filtrées par nationalité. Dans ce cas, l'Amérique et le Royaume-Uni figurent sur la liste, car les États-Unis avaient un président britannique, à savoir George Washington. (Avertissement: les résultats sont basés sur l'état du graphe des connaissances au moment de l'expérience; je ne peux pas garantir leur exactitude).
Liens bleus contre connaissances
Cerebro a vraiment pu comprendre les demandes des utilisateurs. Après avoir reçu des données pour l'ensemble du graphique, nous pourrions générer des interprétations de la requête par la machine, générer une liste de résultats et comprendre beaucoup de ces résultats pour une étude plus approfondie du graphique. Cela a été expliqué ci-dessus: dès que le système comprend qu'il s'agit de films, de personnes ou de livres, etc., certains filtres et tris peuvent être activés. Vous pouvez même faire le tour des nœuds et afficher des informations connexes: des [présidents américains] aux [écoles où ils sont allés] ou [aux enfants dont ils sont les parents]. Voici quelques autres requêtes générées par le système lui-même: [femmes politiciennes afro-américaines], [acteurs de Bollywood mariés à des politiciens], [enfants de nous présidents], [films avec tom hanks sortis dans les années 90]
DH a démontré cette opportunité de passer d'une liste à une autre dans un autre projet appelé
Parallax .
Cerebro a montré un résultat très impressionnant, et la direction de Metaweb l'a soutenu. Même en termes d'infrastructure, il s'est avéré efficace et fonctionnel. Je l'ai appelé
le moteur de connaissances (comme un moteur de recherche). Mais sur Google, personne n'a spécifiquement abordé ce sujet. Elle intéressait peu mon responsable, ils m'ont conseillé de parler avec une personne, puis avec une autre, et en conséquence j'ai eu la chance de démontrer le système à un très haut responsable de recherche.
La réponse n'était pas celle que j'espérais . Pour démontrer les résultats du moteur de connaissance de [livres d'auteurs français], il a lancé une recherche Google, a montré dix lignes avec des liens bleus et a déclaré que Google pourrait faire de même. De plus, ils ne veulent pas prendre le trafic des sites, car ils se mettent en colère.
Si vous pensez qu'il a raison, pensez-y: lorsque Google effectue une recherche sur Internet, il ne comprend vraiment pas la demande. Le système recherche les bons mots dans la bonne position, en tenant compte du poids de la page, etc. Il s'agit d'un système très complexe, mais il ne comprend ni la requête ni les résultats. L'utilisateur fait lui-même tout le travail: lire, analyser, extraire les informations nécessaires des résultats et des recherches ultérieures, additionner une liste complète des résultats, etc.
Par exemple, pour [les livres d'auteurs français], une personne essaiera d'abord de trouver une liste exhaustive, bien qu'une page avec une telle liste puisse ne pas être trouvée. Triez ensuite ces livres par années de publication ou filtrez par éditeurs, etc. - tout cela nécessite qu'une personne traite une grande quantité d'informations, de nombreuses recherches et traite les résultats. Cerebro est en mesure de réduire ces efforts et de rendre l'interaction utilisateur simple et sans faille.
Mais alors, il n'y avait pas de compréhension complète de l'importance du graphique des connaissances. Le manuel n'était pas sûr de son utilité ni de la manière de le relier à la recherche.
Cette nouvelle approche de la connaissance n'est pas facile pour l'organisation qui a obtenu un tel succès en fournissant aux utilisateurs des liens vers des pages Web.Au cours de l'année, j'ai eu du mal à comprendre les managers et j'ai finalement abandonné. Un responsable du bureau de Shanghai s'est tourné vers moi et je lui ai remis le projet en juin 2011. Il a mis sur lui une équipe de 15 ingénieurs. J'ai passé une semaine à Shanghai, transmettant aux ingénieurs tout ce que j'ai créé et appris. DH était également impliqué dans cette entreprise et il a longtemps dirigé l'équipe.
Problème de profondeur de jointure
Dans le système graphique Cerebro, il y avait un problème avec la profondeur de l'union. La jointure est effectuée lorsque le résultat d'une requête précoce est nécessaire pour terminer une requête ultérieure. Une union typique comprend certains
SELECT , c'est-à-dire un filtre dans certains résultats d'un ensemble de données universel, puis ces résultats sont utilisés pour filtrer par une autre partie de l'ensemble de données. Je vais vous expliquer avec un exemple.
Dites que vous voulez savoir [les gens de SF qui mangent des sushis]. Toutes les personnes se voient attribuer des données, y compris qui vit dans quelle ville et quel type de nourriture ils mangent.
La requête ci-dessus est une jointure à un niveau. Si l'application accède à la base de données, elle fera une demande pour la première étape. Ensuite, quelques requêtes (une requête pour chaque résultat) pour découvrir ce que chaque personne mange, en ne choisissant que ceux qui mangent des sushis.
La deuxième étape souffre du problème de fan-out. Si la première étape donne un million de résultats (la population de San Francisco), alors la deuxième étape devrait être donnée sur demande à tout le monde, en demandant leurs habitudes alimentaires, puis en appliquant un filtre.

Les ingénieurs système distribués résolvent généralement ce problème par
diffusion , c'est-à-dire par distribution omniprésente. Ils accumulent les résultats correspondants, en faisant une demande à chaque serveur du cluster. Cela fournit une jointure, mais provoque des problèmes de latence de la demande.
La diffusion ne fonctionne pas bien dans un système distribué. Ce problème est mieux expliqué par
Jeff Dean de Google dans son discours "Atteindre une réponse rapide dans les grands services en ligne" (
vidéos ,
diapositives ). Le retard total est toujours supérieur au retard du composant le plus lent.
De petits reflets sur des ordinateurs individuels entraînent des retards, et l'inclusion de nombreux ordinateurs dans la requête augmente considérablement la probabilité de retards.Considérons un serveur avec un retard de plus de 1 ms dans 50% des cas et de plus de 1 s dans 1% des cas. Si la demande est envoyée à un seul de ces serveurs, seulement 1% des réponses dépassent une seconde. Mais si la demande va à des centaines de ces serveurs, 63% des réponses dépassent une seconde.
Ainsi, la diffusion d'une demande augmente considérablement le délai. Pensez maintenant, et si vous avez besoin de deux, trois ou plusieurs associations? Il est trop lent à exécuter en temps réel.
Le problème du déploiement des fans lorsque la demande de diffusion est inhérent à la plupart des bases de données non natives de graphiques, y compris le
graphique Janus ,
Twitter FlockDB et
Facebook TAO .
Les associations distribuées sont un problème complexe. Les bases de données graphiques natives permettent d'éviter ce problème en stockant un ensemble de données universel sur un serveur (base de données autonome) et en effectuant toutes les jointures sans accéder à d'autres serveurs. Par exemple,
Neo4j fait cela.
Dgraph: unions avec une profondeur arbitraire
Ayant terminé les travaux sur Cerebro et ayant une expérience dans la construction d'un système de gestion de graphes, j'ai participé au projet Dgraph, devenant l'un des trois chefs de projets techniques. Nous avons appliqué des concepts innovants qui ont résolu le problème de la profondeur de l'union.
En particulier, Dgraph sépare les données du graphique afin que chaque jointure puisse être entièrement effectuée par une machine. En revenant à l'
subject-predicate-object (SPO), chaque instance de Dgraph contient tous les sujets et objets correspondant à chaque prédicat de cette instance. Plusieurs prédicats sont stockés dans une instance, chacun étant complètement stocké.
Cela nous a permis de répondre aux demandes avec une profondeur arbitraire d'associations , éliminant ainsi le problème du déploiement des fans pendant la diffusion. Par exemple, la requête [les habitants de SF qui mangent des sushis] générera un
maximum de deux appels réseau dans la base de données, quelle que soit la taille du cluster. Le premier défi va trouver toutes les personnes qui vivent à San Francisco. La deuxième demande enverra cette liste pour croiser toutes les personnes qui mangent des sushis. Ensuite, vous pouvez ajouter des restrictions ou des extensions supplémentaires, chaque étape ne prévoit toujours pas plus d'un appel réseau.

Cela crée le problème des très gros prédicats sur le même serveur, mais il peut être résolu en divisant davantage les prédicats entre deux ou plusieurs instances à mesure que la taille augmente. Dans le pire des cas, un prédicat sera divisé sur l'ensemble du cluster. Mais cela ne se produira que dans une situation fantastique, lorsque toutes les données correspondent à un seul prédicat. Dans d'autres cas, cette approche peut réduire considérablement le retard des demandes dans les systèmes réels.
Le sharding n'était pas la seule innovation de Dgraph. Tous les objets ont reçu des identifiants entiers, ils ont été triés et enregistrés sous la forme d'une liste (liste de publication) pour traverser rapidement ces listes plus tard. Cela vous permet de filtrer rapidement pendant la fusion, de trouver des liens communs, etc. Les idées des moteurs de recherche Google sont également utiles ici.
Combiner tous les blocs OneBox via Plasma
Le dgraph de Google n'était pas une base de données . C'était l'un des sous-systèmes, qui répondait également aux mises à jour. Elle avait donc besoin d'indexation. J'ai une vaste expérience de travail avec des systèmes d'indexation incrémentielle en temps réel fonctionnant sous
caféine .
J'ai commencé un projet d'unification de tous les OneBox dans ce système d'indexation de graphiques, y compris la météo, les horaires de vol, les événements, etc. Vous ne connaissez peut-être pas le terme OneBox, mais vous l'avez certainement vu - il s'agit d'une fenêtre distincte qui apparaît lorsque certains types de requêtes sont exécutées, où Google renvoie des informations plus riches. Pour voir OneBox en action, essayez [
météo en sf ].
Auparavant, chaque OneBox fonctionnait sur un backend autonome et était soutenu par différents groupes de développement.
Il y avait un riche ensemble de données structurées, mais les unités OneBox n'ont pas échangé de données entre elles. Premièrement, différents backends ont augmenté les coûts de main-d'œuvre à plusieurs reprises. Deuxièmement, le manque de partage d'informations a limité l'éventail des demandes auxquelles Google pouvait répondre.
Par exemple, [les événements de SF] peuvent afficher des événements et [la météo de SF] peut afficher la météo. Mais si [les événements de SF] comprenaient qu'il pleuvait maintenant, alors vous pourriez filtrer ou trier les événements par type "à l'intérieur" ou "à l'extérieur" (
peut-être vaut-il mieux aller au cinéma plutôt que le football sous une pluie battante) )
Avec l'aide de l'équipe Metaweb, nous avons commencé à convertir toutes ces données au format SPO et à les indexer avec un seul système. Je l'ai nommé
Plasma, un moteur d'indexation de graphiques en temps réel pour servir Dgraph.
Gestion de Leapfrog
Comme Cerebro, le projet Plasma a reçu peu de ressources, mais a continué de gagner du terrain. Finalement, lorsque la direction a réalisé que les blocs OneBox faisaient inévitablement partie de notre projet, elle a immédiatement décidé de mettre les
«bonnes personnes» pour gérer le système graphique. Au plus fort du jeu politique, trois dirigeants ont été remplacés, chacun n'ayant aucune expérience de travail avec les graphiques.
Pendant ce saut de Dgraph, les chefs de projet de
Spanner ont appelé Dgraph
un système
trop complexe . Pour référence, Spanner est une base de données SQL distribuée dans le monde entier qui a besoin de sa propre montre GPS pour garantir la cohérence globale.
L'ironie de tout ça souffle encore sur mon toit.Dgraph a été annulé, Plasma a survécu. Et à la tête du projet, ils ont mis une nouvelle équipe avec un nouveau leader, avec une hiérarchie claire et relevant du PDG. La nouvelle équipe - avec une mauvaise compréhension des graphiques et des problèmes associés - a décidé de créer un sous-système d'infrastructure basé sur l'index de recherche Google existant (comme je l'ai fait pour Cerebro). J'ai suggéré d'utiliser le système que j'avais déjà fait pour Cerebro, mais il a été rejeté. J'ai modifié Plasma pour explorer et étendre chaque nœud de connaissances en plusieurs niveaux afin que le système puisse le voir comme un document Web. Ils ont appelé ce système TS (
abréviation ).
Cela signifiait que le nouveau sous-système ne serait pas en mesure d'effectuer des associations profondes. Encore une fois, c'est une malédiction que je vois dans de nombreuses entreprises parce que les ingénieurs partent de la mauvaise idée que «les graphiques sont un problème simple qui peut être résolu en construisant simplement une couche au-dessus d'un autre système».
Quelques mois plus tard, en mai 2013, j'ai quitté Google après avoir travaillé sur Dgraph / Plasma pendant environ deux ans.
Postface
- Quelques années plus tard, la section «Internet Search Infrastructure» a été renommée «Internet Search Infrastructure and Knowledge Graph», et le chef à qui j'ai montré à Cerebro a dirigé la direction «Knowledge Graph» expliquant comment ils ont l'intention de remplacer les simples liens de connaissances bleus pour répondre directement aux questions des utilisateurs aussi souvent que possible.
- Lorsque l'équipe de Shanghai travaillant sur Cerebro était sur le point de le mettre en production, le projet leur a été retiré et confié à la division de New York. Finalement, il a été lancé sous le nom de Knowledge Strip. Si vous recherchez [ films de tom hanks ], vous le verrez en haut. Il s'est un peu amélioré depuis le premier lancement, mais ne prend toujours pas en charge le niveau de filtrage et de tri qui a été défini dans Cerebro.
- Les trois responsables techniques qui ont travaillé sur Dgraph (y compris moi-même) ont finalement quitté Google. Pour autant que je sache, les autres travaillent maintenant chez Microsoft et LinkedIn.
- J'ai réussi à obtenir deux promotions chez Google, et je devais en obtenir une troisième lorsque j'ai quitté l'entreprise en tant qu'ingénieur logiciel senior (ingénieur logiciel senior).
- À en juger par certaines rumeurs fragmentaires, la version actuelle de TS est en fait très proche de la conception du système de graphes de Cerebro, et chaque sujet, prédicat et objet a un index. Par conséquent, elle souffre toujours du problème de la profondeur de l'unification.
- Le plasma a depuis été réécrit et renommé, mais il continue de fonctionner comme un système d'indexation de graphiques en temps réel pour TS. Ensemble, ils continuent de publier et de traiter toutes les données structurées sur Google, y compris le Knowledge Graph.
- L'incapacité de Google à réaliser des unions profondes est visible dans de nombreux endroits. Par exemple, nous ne voyons toujours pas l'échange de données entre les blocs OneBox: [les villes les plus pluvieuses en Asie] ne donne pas une liste de villes, bien que toutes les données soient dans la colonne des connaissances (à la place, la page Web est citée dans les résultats de la recherche); [les événements de SF] ne peuvent pas être filtrés par la météo; Les résultats des [présidents américains] ne sont pas triés, filtrés ou développés par d'autres faits: leurs enfants ou les écoles où ils ont étudié. Je crois que c'était l'une des raisons de l'arrêt du support Freebase .
Dgraph: Phoenix Bird
Deux ans après avoir quitté Google, j'ai décidé de
développer Dgraph . Dans d'autres entreprises, je vois la même indécision concernant les graphiques que dans Google. Il y avait de nombreuses solutions inachevées dans l'espace graphique, en particulier, de nombreuses solutions personnalisées assemblées à la hâte sur des bases de données relationnelles ou NoSQL, ou comme l'une des nombreuses fonctionnalités des bases de données multimodèles. S'il existait une solution native, elle souffrait de problèmes d'évolutivité.
Rien de ce que j'ai vu avait une histoire cohérente avec un design productif et évolutif.
Construire une base de données graphique évolutive horizontalement avec une faible latence et des jointures de profondeur arbitraires est une tâche extrêmement difficile , et je voulais m'assurer que nous avons construit le Dgraph correctement.
L'équipe Dgraph a passé les trois dernières années non seulement à étudier ma propre expérience, mais aussi à investir beaucoup de ses propres efforts dans la conception - la création d'une base de données de graphiques qui n'a pas d'analogues sur le marché. Ainsi, les entreprises ont la possibilité d'utiliser une solution fiable, évolutive et productive au lieu d'une autre solution semi-finie.