La détection des attaques fait partie de la sécurité des informations depuis des décennies. Les premières implémentations connues du système de détection d'intrusion (IDS) remontent au début des années 80.
De nos jours, il existe toute une industrie de détection d'attaque. Il existe un certain nombre de types de produits - tels que les solutions IDS, IPS, WAF et pare-feu - dont la plupart offrent une détection d'attaque basée sur des règles. L'idée d'utiliser une sorte de détection d'anomalies statistiques pour identifier les attaques en production ne semble pas aussi réaliste qu'auparavant. Mais cette hypothèse est-elle justifiée?
Détection d'anomalies dans les applications Web
Les premiers pare-feu conçus pour détecter les attaques d'applications Web sont apparus sur le marché au début des années 1990. Les techniques d'attaque et les mécanismes de protection ont évolué considérablement depuis lors, les attaquants se précipitant pour prendre une longueur d'avance.
La plupart des pare-feu d'applications Web (WAF) actuels tentent de détecter les attaques de manière similaire, avec un moteur basé sur des règles intégré dans un proxy inverse d'un certain type. L'exemple le plus important est mod_security, un module WAF pour le serveur Web Apache, qui a été créé en 2002. La détection basée sur des règles présente certains inconvénients: par exemple, elle ne parvient pas à détecter de nouvelles attaques (zéro jour), même si ces mêmes attaques pourrait facilement être détecté par un expert humain. Ce fait n'est pas surprenant, car le cerveau humain fonctionne très différemment d'un ensemble d'expressions régulières.
Du point de vue d'un WAF, les attaques peuvent être divisées en attaques séquentielles (séries temporelles) et celles consistant en une seule requête ou réponse HTTP. Nos recherches se sont concentrées sur la détection de ce dernier type d'attaques, notamment:
- Injection SQL
- Scriptage intersite
- Injection d'entité externe XML
- Traversée de chemin
- OS commandant
- Injection d'objets
Mais d'abord, posons-nous la question: comment un humain le ferait-il?
Que ferait un humain en voyant une seule demande
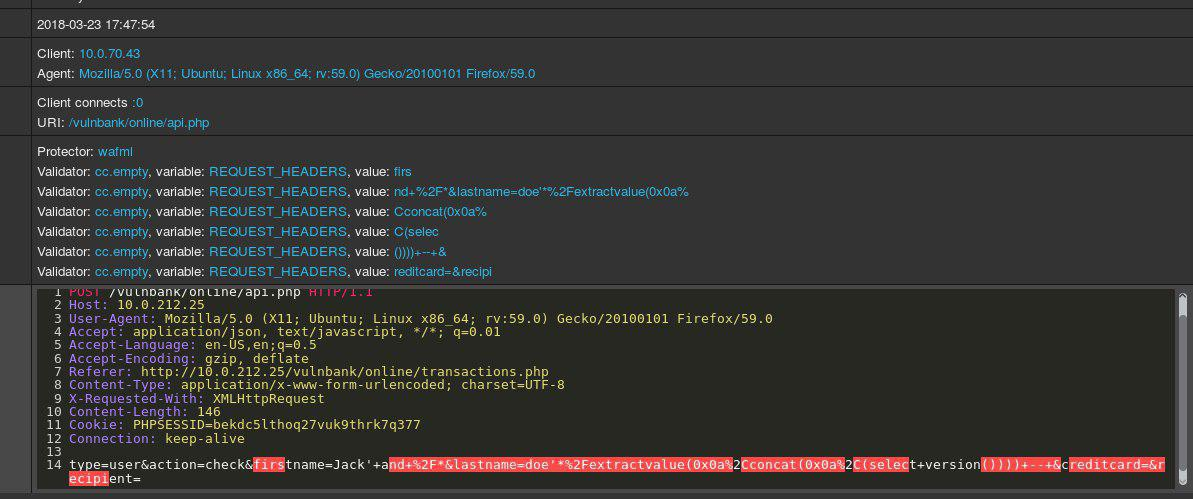
Jetez un œil à un exemple de requête HTTP régulière vers une application:
Si vous deviez détecter des demandes malveillantes envoyées à une application, il est fort probable que vous souhaitiez observer les demandes bénignes pendant un certain temps. Après avoir examiné les demandes d'un certain nombre de points de terminaison d'exécution d'application, vous auriez une idée générale de la structure des demandes sécurisées et de leur contenu.
Maintenant, vous êtes présenté avec la demande suivante:

Vous avez immédiatement l'impression que quelque chose ne va pas. Il faut un peu plus de temps pour comprendre exactement quoi, et dès que vous localisez la partie exacte de la demande qui est anormale, vous pouvez commencer à réfléchir au type d'attaque dont il s'agit. Essentiellement, notre objectif est de faire en sorte que notre IA de détection d'attaque aborde le problème d'une manière qui ressemble à ce raisonnement humain.
Pour compliquer notre tâche, un certain trafic, même s'il peut sembler malveillant à première vue, peut en fait être normal pour un site Web particulier.
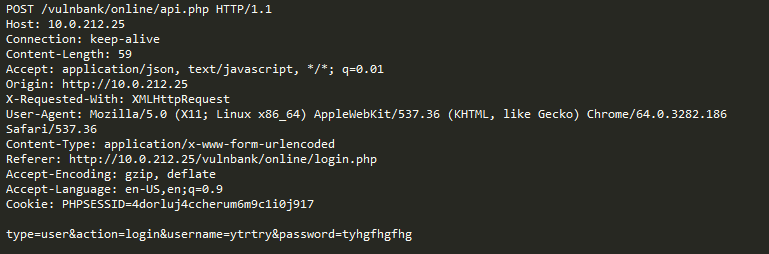
Par exemple, examinons la demande suivante:
Est-ce une anomalie? En fait, cette demande est bénigne: il s'agit d'une demande typique liée à la publication de bogues sur le traqueur de bogues Jira.
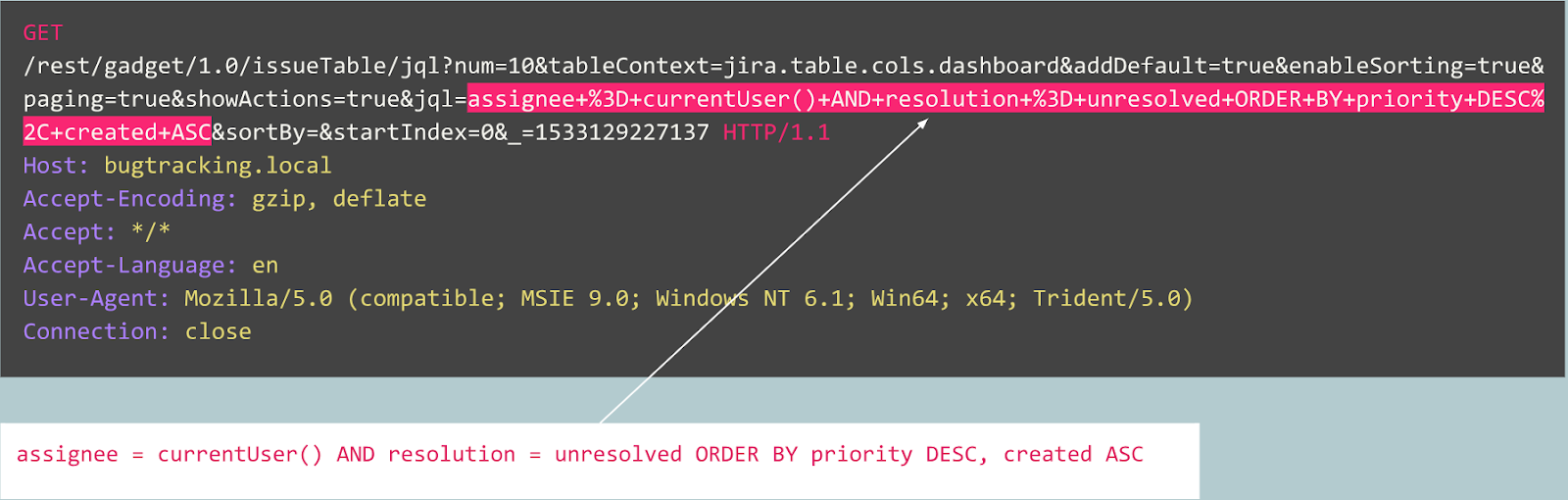
Voyons maintenant un autre cas:

Au début, la demande ressemble à une inscription d'utilisateur typique sur un site Web propulsé par le CMS Joomla. Cependant, l'opération demandée est «user.register» au lieu du «registration.register» normal. L'ancienne option est obsolète et contient une vulnérabilité permettant à quiconque de s'inscrire en tant qu'administrateur.
Cet exploit est connu sous le nom de «Joomla <3.6.4 Account Creation / Privilege Escalation» (CVE-2016-8869, CVE-2016-8870).

Comment nous avons commencé
Nous avons d'abord examiné les recherches précédentes, car de nombreuses tentatives pour créer différents algorithmes statistiques ou d'apprentissage automatique pour détecter les attaques ont été faites au fil des décennies. L'une des approches les plus fréquentes consiste à résoudre la tâche d'affectation à une classe («requête bénigne», «injection SQL», «XSS», «CSRF», etc.). Bien que l'on puisse atteindre une précision décente avec la classification pour un ensemble de données donné, cette approche ne résout pas certains problèmes très importants:
- Le choix de l'ensemble de classe . Et si votre modèle pendant l'apprentissage est présenté avec trois classes («bénigne», «SQLi», «XSS») mais en production, il rencontre une attaque CSRF ou même une toute nouvelle technique d'attaque?
- Le sens de ces classes . Supposons que vous deviez protéger 10 clients, chacun d'eux exécutant des applications Web complètement différentes. Pour la plupart d'entre eux, vous n'auriez aucune idée de ce à quoi ressemble une seule attaque «Injection SQL» contre leur application. Cela signifie que vous devrez en quelque sorte construire artificiellement vos ensembles de données d'apprentissage - ce qui est une mauvaise idée, car vous finirez par apprendre à partir de données avec une distribution complètement différente de vos données réelles.
- Interprétabilité des résultats de votre modèle . Très bien, le modèle a donc créé le label «Injection SQL» - et maintenant? Vous et surtout votre client, qui est le premier à voir l'alerte et qui n'est généralement pas un expert en attaques Web, devez deviner quelle partie de la demande le modèle considère comme malveillante.
Gardant cela à l'esprit, nous avons décidé d'essayer la classification de toute façon.
Comme le protocole HTTP est basé sur du texte, il était évident que nous devions jeter un œil aux classificateurs de texte modernes. L'un des exemples bien connus est l'analyse des sentiments de l'ensemble de données de revue de films IMDB. Certaines solutions utilisent des réseaux de neurones récurrents (RNN) pour classer ces revues. Nous avons décidé d'utiliser un modèle de classification RNN similaire avec quelques légères différences. Par exemple, les RNN de classification en langage naturel utilisent des incorporations de mots, mais il n'est pas clair quels mots il y a dans un langage non naturel comme HTTP. C'est pourquoi nous avons décidé d'utiliser des incorporations de caractères dans notre modèle.
Les intégrations prêtes à l'emploi ne sont pas pertinentes pour résoudre le problème, c'est pourquoi nous avons utilisé des mappages simples de caractères avec des codes numériques avec plusieurs marqueurs internes tels que
GO et
EOS .
Après avoir terminé le développement et les tests du modèle, tous les problèmes prédits plus tôt se sont produits, mais au moins notre équipe est passée d'une réflexion au ralenti à quelque chose de productif.
Comment nous avons procédé
À partir de là, nous avons décidé d'essayer de rendre les résultats de notre modèle plus interprétables. À un moment donné, nous sommes tombés sur le mécanisme de «l'attention» et avons commencé à l'intégrer dans notre modèle. Et cela a donné des résultats prometteurs: finalement, tout s'est réuni et nous avons obtenu des résultats interprétables par l'homme. Maintenant, notre modèle a commencé à produire non seulement les étiquettes mais aussi les coefficients d'attention pour chaque caractère de l'entrée.
Si cela pouvait être visualisé, par exemple, dans une interface Web, nous pourrions colorer l'endroit exact où une attaque «Injection SQL» a été trouvée. C'est un résultat prometteur, mais les autres problèmes restent en suspens.
Nous avons commencé à voir que nous pouvions bénéficier en allant dans le sens du mécanisme d'attention et en s'éloignant de la classification. Après avoir lu de nombreuses recherches connexes (par exemple, «L'attention est tout ce dont vous avez besoin», Word2Vec et les architectures codeur-décodeur) sur les modèles de séquence et en expérimentant nos données, nous avons pu créer un modèle de détection d'anomalies qui fonctionnerait dans plus ou moins de la même manière qu'un expert humain.
Codeurs automatiques
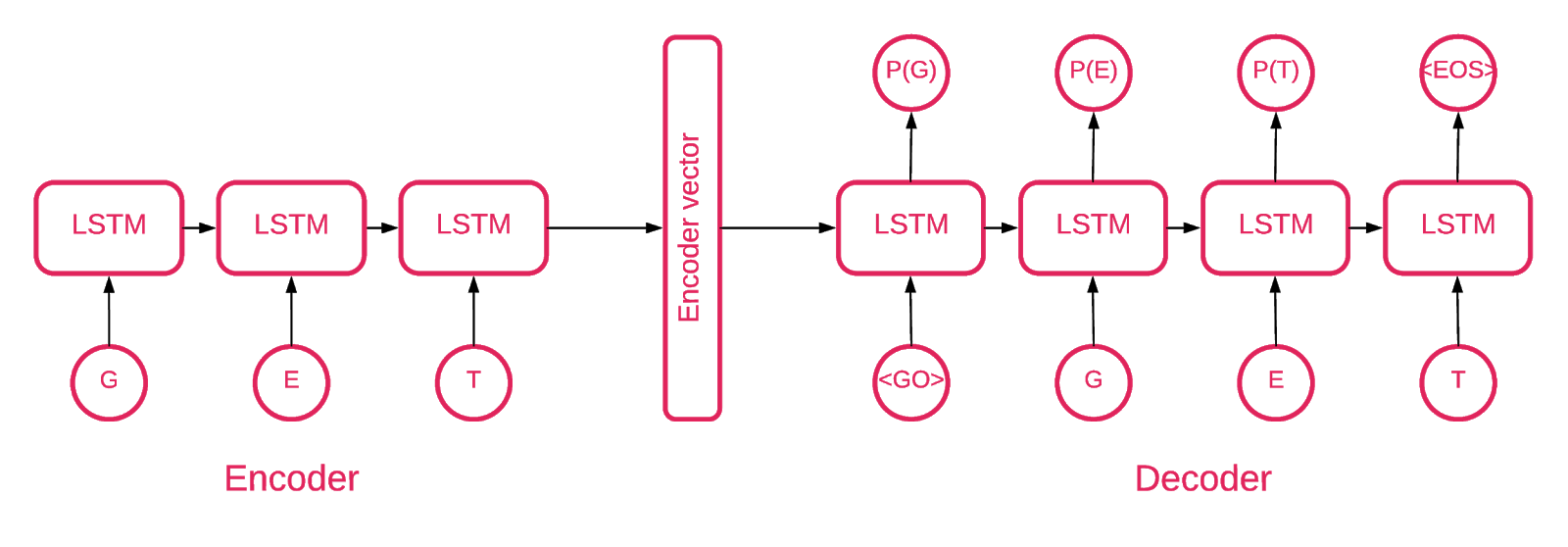
À un moment donné, il est devenu clair qu'un encodeur automatique séquence à séquence convenait le mieux à notre objectif.
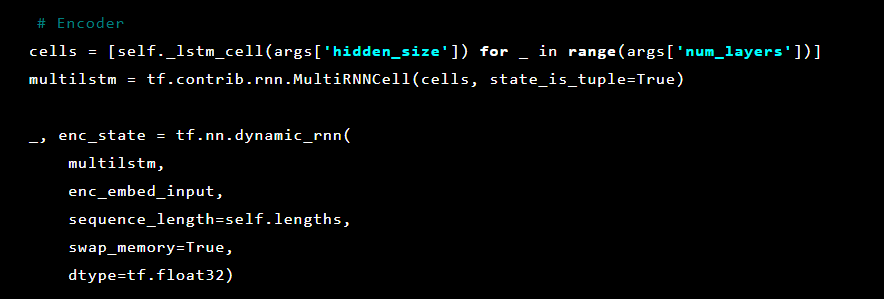
Un modèle de séquence à séquence se compose de deux modèles de mémoire multicouche à long terme (LSTM): un codeur et un décodeur. Le codeur mappe la séquence d'entrée à un vecteur de dimensionnalité fixe. Le décodeur décode le vecteur cible à l'aide de cette sortie du codeur.
Un encodeur automatique est donc un modèle de séquence à séquence qui définit ses valeurs cibles égales à ses valeurs d'entrée. L'idée est d'apprendre au réseau à recréer ce qu'il a vu, ou, en d'autres termes, à rapprocher une fonction d'identité. Si l'autoencodeur formé reçoit un échantillon anormal, il est susceptible de le recréer avec un degré d'erreur élevé car il n'a jamais vu un tel échantillon auparavant.
Le code
Notre solution est composée de plusieurs parties: initialisation du modèle, formation, prédiction et validation.
La plupart du code situé dans le référentiel est explicite, nous nous concentrerons uniquement sur les parties importantes.
Le modèle est initialisé en tant qu'instance de la classe Seq2Seq, qui a les arguments de constructeur suivants:
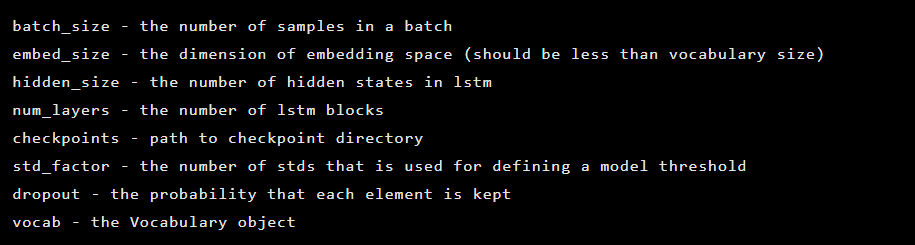
Après cela, les couches de l'encodeur automatique sont initialisées. Tout d'abord, l'encodeur:
Et puis le décodeur:
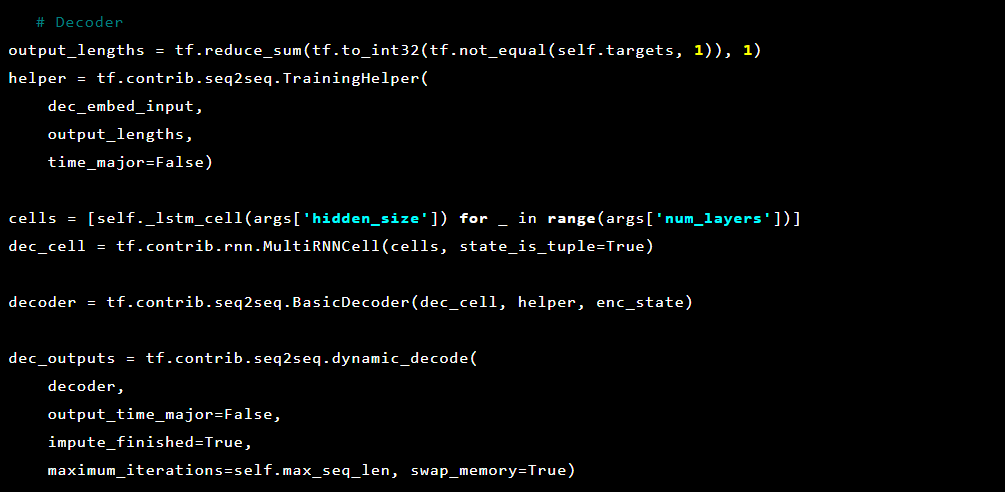
Puisque nous essayons de résoudre la détection d'anomalies, les cibles et les entrées sont les mêmes. Ainsi, notre feed_dict ressemble à ceci:
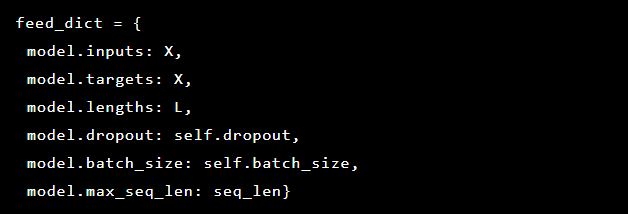
Après chaque époque, le meilleur modèle est enregistré en tant que point de contrôle, qui peut ensuite être chargé pour faire des prédictions. À des fins de test, une application Web en direct a été configurée et protégée par le modèle afin qu'il soit possible de tester si les attaques réelles ont réussi ou non.
Inspirés par le mécanisme d'attention, nous avons essayé de l'appliquer à l'autoencodeur mais nous avons remarqué que les probabilités produites par la dernière couche fonctionnent mieux pour marquer les parties anormales d'une demande.

Au stade des tests avec nos échantillons, nous avons obtenu de très bons résultats: la précision et le rappel étaient proches de 0,99. Et la courbe ROC était d'environ 1. Certainement une belle vue!
Les résultats
Notre modèle d'autoencodeur Seq2Seq décrit s'est révélé capable de détecter des anomalies dans les requêtes HTTP avec une grande précision.
Ce modèle agit comme un humain: il n'apprend que les requêtes utilisateur «normales» envoyées à une application web. Il détecte les anomalies dans les demandes et met en évidence la place exacte dans la demande considérée comme anormale. Nous avons évalué ce modèle contre les attaques sur l'application de test et les résultats semblent prometteurs. Par exemple, la capture d'écran précédente montre comment notre modèle a détecté une injection SQL répartie sur deux paramètres de formulaire Web. Ces injections SQL sont fragmentées, car la charge utile d'attaque est fournie dans plusieurs paramètres HTTP. Les WAF classiques basés sur des règles ne détectent pas correctement les tentatives d'injection SQL fragmentées car ils inspectent généralement chaque paramètre séparément.
Le code du modèle et les données de train / test ont été publiés sous forme de cahier Jupyter afin que chacun puisse reproduire nos résultats et suggérer des améliorations.
Conclusion
Nous pensons que notre tâche était assez simple: trouver un moyen de détecter les attaques avec un minimum d'effort. D'une part, nous avons cherché à éviter de trop compliquer la solution et à créer un moyen de détecter les attaques qui, comme par magie, apprennent à décider par elles-mêmes ce qui est bon et ce qui est mauvais. En même temps, nous voulions éviter les problèmes avec le facteur humain lorsqu'un expert (faillible) décide ce qui indique une attaque et ce qui ne l’est pas. Et donc globalement, l'autoencodeur avec l'architecture Seq2Seq semble résoudre très bien notre problème de détection des anomalies.
Nous voulions également résoudre le problème de l'interprétabilité des données. Lors de l'utilisation d'architectures de réseaux neuronaux complexes, il est très difficile d'expliquer un résultat particulier. Lorsqu'une série entière de transformations est appliquée, l'identification des données les plus importantes derrière une décision devient presque impossible. Cependant, après avoir repensé l'approche de l'interprétation des données par le modèle, nous avons pu obtenir des probabilités pour chaque caractère de la dernière couche.
Il est important de noter que cette approche n'est pas une version prête pour la production. Nous ne pouvons pas divulguer les détails de la façon dont cette approche pourrait être mise en œuvre dans un produit réel. Mais nous vous avertirons qu'il n'est pas possible de simplement prendre ce travail et de le "brancher". Nous faisons cette mise en garde car après la publication sur GitHub, nous avons commencé à voir certains utilisateurs qui tentaient simplement d'implémenter notre solution actuelle en gros dans leurs propres projets, avec des résultats infructueux (et sans surprise).
La preuve de concept est disponible
ici (github.com).
Auteurs: Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseny Reutov (
Raz0r )
Lectures complémentaires
- Comprendre les réseaux LSTM
- Réseaux de neurones récurrents augmentés et attention
- L'attention est tout ce dont vous avez besoin
- L'attention est tout ce dont vous avez besoin (annoté)
- Tutoriel de traduction automatique de neurones (seq2seq)
- Codeurs automatiques
- Apprentissage de séquence en séquence avec les réseaux de neurones
- Construire des encodeurs automatiques à Keras