Pirater la musique pour démocratiser le contenu dérivéAvertissement: Toutes les propriétés intellectuelles, conceptions et méthodes décrites dans cet article sont divulguées dans US10014002B2 et US9842609B2.
J'aimerais pouvoir revenir en 1965, frapper à la porte d'entrée du studio Abby Road avec un laissez-passer, entrer et entendre les vraies voix de Lennon et McCartney ... Eh bien, essayons. Entrée: MP3 de qualité moyenne des Beatles. La piste supérieure est le mixage d'entrée, la piste inférieure est le chant isolé que notre réseau de neurones a mis en évidence.
Formellement, ce problème est connu sous le nom de
séparation des sources sonores ou
séparation du signal (séparation des sources audio). Il consiste à restaurer ou reconstruire un ou plusieurs des signaux d'origine qui, à la suite d'un processus
linéaire ou convolutionnel , sont mélangés à d'autres signaux. Ce domaine de recherche a de nombreuses applications pratiques, notamment l'amélioration de la qualité du son (parole) et l'élimination du bruit, les remixages musicaux, la distribution spatiale du son, la remasterisation, etc. Les ingénieurs du son appellent parfois cette technique le démixage. Il existe de nombreuses ressources sur ce sujet, de la séparation aveugle des signaux avec l'analyse des composants indépendants (ICA) à la factorisation semi-contrôlée des matrices non négatives et se terminant par des approches ultérieures basées sur des réseaux de neurones. Vous pouvez trouver de bonnes informations sur les deux premiers points dans
ces mini-guides du CCRMA, qui à un moment donné m'ont été très utiles.
Mais avant de plonger dans le développement ... un peu de philosophie d'apprentissage automatique appliquée ...J'étais engagé dans le traitement du signal et de l'image avant même que le slogan «l'apprentissage profond ne résout tout» se soit propagé, je peux donc vous présenter une solution comme un voyage d'
ingénierie des fonctionnalités et montrer
pourquoi le réseau neuronal est la meilleure approche pour ce problème particulier . Pourquoi? Très souvent, je vois des gens écrire quelque chose comme ça:
«Avec l'apprentissage en profondeur, vous n'avez plus à vous soucier du choix des fonctionnalités; il le fera pour vous. "ou pire ...
"La différence entre l'apprentissage automatique et l'apprentissage en profondeur [hé ... l'apprentissage en profondeur est toujours l'apprentissage en machine!] Est
que, dans ML, vous extrayez vous-même les attributs, et dans l'apprentissage en profondeur, cela se produit automatiquement au sein du réseau."Ces généralisations proviennent probablement du fait que les DNN peuvent être très efficaces pour explorer de bons espaces cachés. Mais il est donc impossible de généraliser. Je suis très bouleversé lorsque de récents diplômés et praticiens succombent aux idées fausses ci-dessus et adoptent l'approche du «deep-learning-it-all». Par exemple, il suffit de jeter un tas de données brutes (même après un petit traitement préliminaire) - et tout fonctionnera comme il se doit. Dans le monde réel, vous devez vous occuper de choses comme les performances, l'exécution en temps réel, etc. À cause de telles idées fausses, vous serez coincé en mode expérience pendant très longtemps ...
L'ingénierie des fonctionnalités reste une discipline très importante dans la conception de réseaux de neurones artificiels. Comme dans toute autre technique de ML, dans la plupart des cas, c'est elle qui distingue les solutions efficaces du niveau de production des expériences infructueuses ou inefficaces. Une compréhension approfondie de vos données et de leur nature signifie encore beaucoup ...De A à Z
Ok, j'ai fini le sermon. Voyons maintenant pourquoi nous sommes ici! Comme pour tout problème de traitement des données, voyons d'abord à quoi il ressemble. Jetez un coup d'œil à la prochaine partie de la voix de l'enregistrement studio original.
Voix de studio 'One Last Time', Ariana GrandePas trop intéressant, non? Eh bien, c'est parce que nous visualisons le signal
dans le temps . Ici, nous ne voyons que les changements d'amplitude au fil du temps. Mais vous pouvez extraire toutes sortes d'autres choses, telles que les enveloppes d'amplitude (enveloppe), les valeurs quadratiques moyennes (RMS), le taux de changement des valeurs positives d'amplitude au négatif (taux de passage par zéro), etc., mais ces
signes sont trop
primitifs et pas suffisamment distinctifs, pour aider dans notre problème. Si nous voulons extraire la voix d'un signal audio, nous devons d'abord déterminer d'une manière ou d'une autre la structure de la parole humaine. Heureusement, la
transformée de Fourier de fenêtre (STFT) vient à la rescousse.
Spectre d'amplitude STFT - taille de la fenêtre = 2048, chevauchement = 75%, échelle de fréquence logarithmique [Sonic Visualizer]Bien que j'aime le traitement de la parole et que j'adore jouer avec
les simulations de filtres d'entrée, les cepstres, les sottotamis, les LPC, les MFCC et ainsi de suite
, nous allons ignorer toutes ces absurdités et nous concentrer sur les principaux éléments liés à notre problème afin que l'article puisse être compris par le plus de personnes possible, pas seulement des spécialistes du traitement du signal.
Alors, que nous dit la structure de la parole humaine?
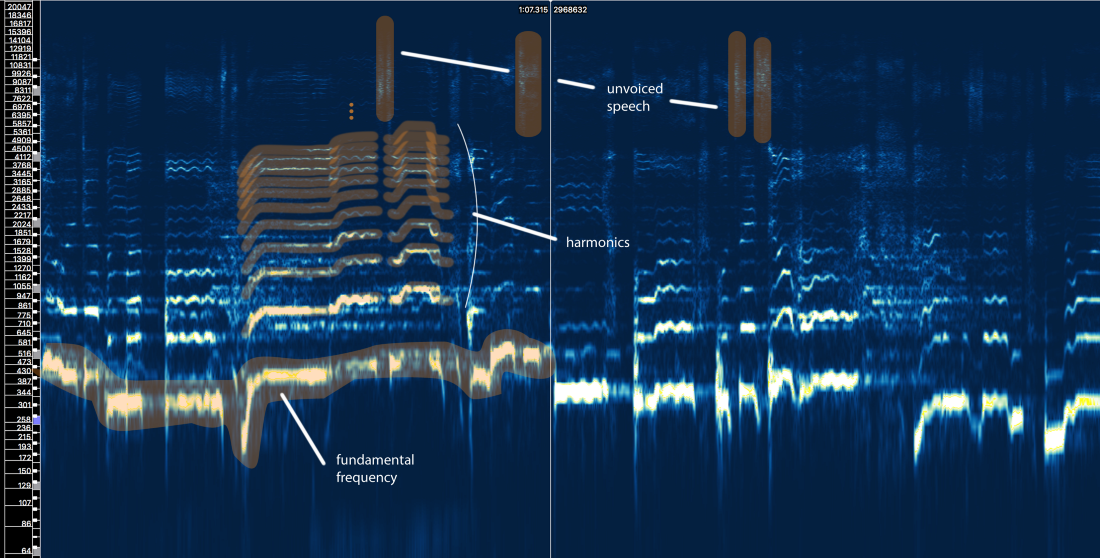
Eh bien, nous pouvons définir trois éléments principaux ici:
- La fréquence fondamentale (f0), qui est déterminée par la fréquence de vibration de nos cordes vocales. Dans ce cas, Ariana chante dans la plage de 300 à 500 Hz.
- Une série d' harmoniques au-dessus de f0 qui suivent une forme ou un motif similaire. Ces harmoniques apparaissent à des fréquences qui sont des multiples de f0.
- Discours non voisé , qui comprend des consonnes telles que `` t '', `` p '', `` k '', `` s '' (qui n'est pas produit par la vibration des cordes vocales), la respiration, etc. Tout cela se manifeste sous la forme de courtes salves dans la région des hautes fréquences.
Première tentative avec des règles
Oublions une seconde ce qu'on appelle le machine learning. Peut-on développer une méthode d'extraction vocale basée sur notre connaissance du signal? Laisse moi essayer ...
Isolement vocal naïf V1.0:- Identifiez les zones vocales. Il y a beaucoup de choses dans le signal d'origine. Nous voulons nous concentrer sur les domaines qui contiennent vraiment du contenu vocal et ignorer tout le reste.
- Faites la distinction entre la parole vocale et non vocale. Comme nous l'avons vu, ils sont très différents. Ils doivent probablement être traités différemment.
- Évaluez le changement de fréquence fondamentale au fil du temps.
- Sur la base de la broche 3, appliquez une sorte de masque pour capturer les harmoniques.
- Faites quelque chose avec des fragments de discours sans voix ...

Si nous travaillons dignement, le résultat devrait être un
masque doux ou
binaire , dont l'application à l'amplitude du STFT (multiplication par éléments) donne une reconstruction approximative de l'amplitude du chant STFT. Ensuite, nous combinons ce STFT vocal avec des informations sur la phase du signal d'origine, calculons le STFT inverse et obtenons le signal temporel du vocal reconstruit.
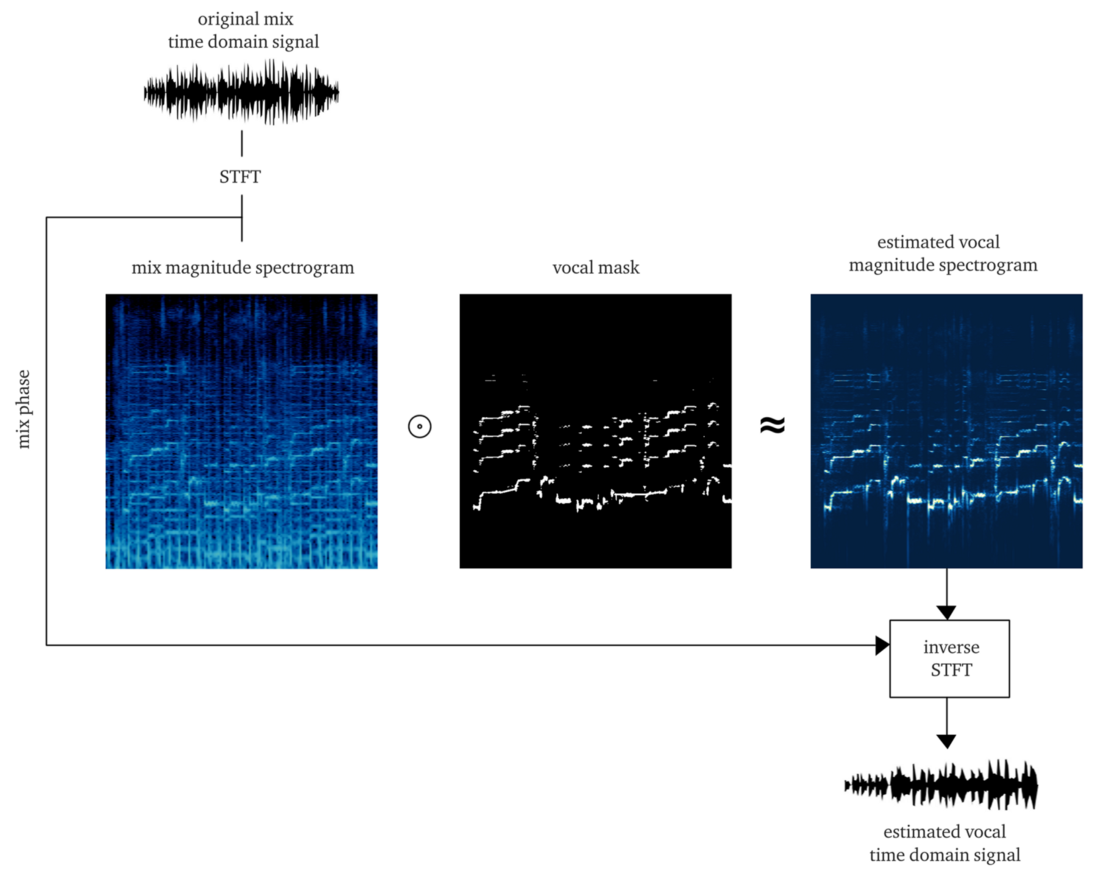
Le faire à partir de zéro est déjà un gros travail. Mais à des fins de démonstration, l'implémentation de
l'algorithme pYIN est applicable . Bien qu'il soit destiné à résoudre l'étape 3, mais avec les paramètres corrects, il exécute décemment les étapes 1 et 2, en suivant la base vocale même en présence de musique. L'exemple ci-dessous contient la sortie après traitement de cet algorithme, sans traitement de la parole non voisée.
Et quoi ...? Il semble avoir fait tout le travail, mais il n'y a pas de bonne qualité et proche. Peut-être qu'en dépensant plus de temps, d'énergie et d'argent, nous améliorerons cette méthode ...
Mais laissez-moi vous demander ...
Que se passe-t-il si
quelques voix apparaissent sur la piste, et pourtant on la retrouve souvent dans au moins 50% des pistes professionnelles modernes?
Que se passe-t-il si les voix sont traitées par
réverbération, retards et autres effets? Jetons un coup d'œil au dernier refrain d'Ariana Grande de cette chanson.
Ressentez-vous déjà de la douleur ...? Je le suis.
De telles méthodes sur des règles strictes se transforment très vite en château de cartes. Le problème est trop compliqué. Trop de règles, trop d'exceptions et trop de conditions différentes (effets et réglages de mixage). Une approche en plusieurs étapes implique également que les erreurs dans une étape prolongent les problèmes à l'étape suivante. L'amélioration de chaque étape deviendra très coûteuse: il faudra un grand nombre d'itérations pour bien faire les choses. Et enfin, mais non des moindres, il est probable qu'à la fin, nous aurons un convoyeur très gourmand en ressources, ce qui en soi peut annuler tous les efforts.
Dans une telle situation, il est temps de commencer à réfléchir à une approche plus globale et de laisser ML découvrir une partie des processus et opérations de base nécessaires pour résoudre le problème. Mais nous devons encore montrer nos compétences et nous engager dans l'ingénierie des fonctionnalités, et vous comprendrez pourquoi.Hypothèse: utiliser le réseau neuronal comme une fonction de transfert qui traduit les mixages en voix
En regardant les réalisations des réseaux de neurones convolutifs dans le traitement des photos, pourquoi ne pas appliquer la même approche ici?
 Les réseaux de neurones résolvent avec succès des problèmes tels que la colorisation des images, la netteté et la résolution.
Les réseaux de neurones résolvent avec succès des problèmes tels que la colorisation des images, la netteté et la résolution.En fin de compte, vous pouvez imaginer le signal sonore "comme une image" en utilisant la transformée de Fourier à court terme, non? Bien que ces
images sonores ne correspondent pas à la distribution statistique des images naturelles, elles ont encore des modèles spatiaux (dans l'espace temps et fréquence) sur lesquels former le réseau.
 À gauche: rythme de batterie et ligne de base ci-dessous, plusieurs sons de synthétiseur au milieu, tous mélangés avec des voix. Droite: seulement le chant
À gauche: rythme de batterie et ligne de base ci-dessous, plusieurs sons de synthétiseur au milieu, tous mélangés avec des voix. Droite: seulement le chantLa réalisation d'une telle expérience serait une entreprise coûteuse car il est difficile d'obtenir ou de générer les données de formation nécessaires. Mais en recherche appliquée, j'essaie toujours d'utiliser cette approche: d'abord,
pour identifier un problème plus simple qui confirme les mêmes principes , mais qui ne nécessite pas beaucoup de travail. Cela vous permet d'évaluer l'hypothèse, d'itérer plus rapidement et de corriger le modèle avec des pertes minimales s'il ne fonctionne pas comme il se doit.
La condition implicite est que le
réseau neuronal doit comprendre la structure de la parole humaine . Un problème plus simple peut être le suivant:
un réseau de neurones peut-il déterminer la présence de la parole sur un fragment arbitraire d'un enregistrement sonore . Nous parlons d'un
détecteur d'activité vocale fiable
(VAD) , implémenté sous la forme d'un classificateur binaire.
Nous concevons l'espace des signes
Nous savons que les signaux sonores, tels que la musique et la parole humaine, sont basés sur des dépendances temporelles. Autrement dit, rien ne se passe isolément à un moment donné. Si je veux savoir s'il y a une voix sur un morceau particulier d'enregistrement sonore, alors je dois regarder les régions voisines. Un tel
contexte temporel fournit de bonnes informations sur ce qui se passe dans la zone d'intérêt. Dans le même temps, il est souhaitable d'effectuer une classification avec de très petits incréments de temps afin de reconnaître une voix humaine avec la résolution temporelle la plus élevée possible.

Comptons un peu ...
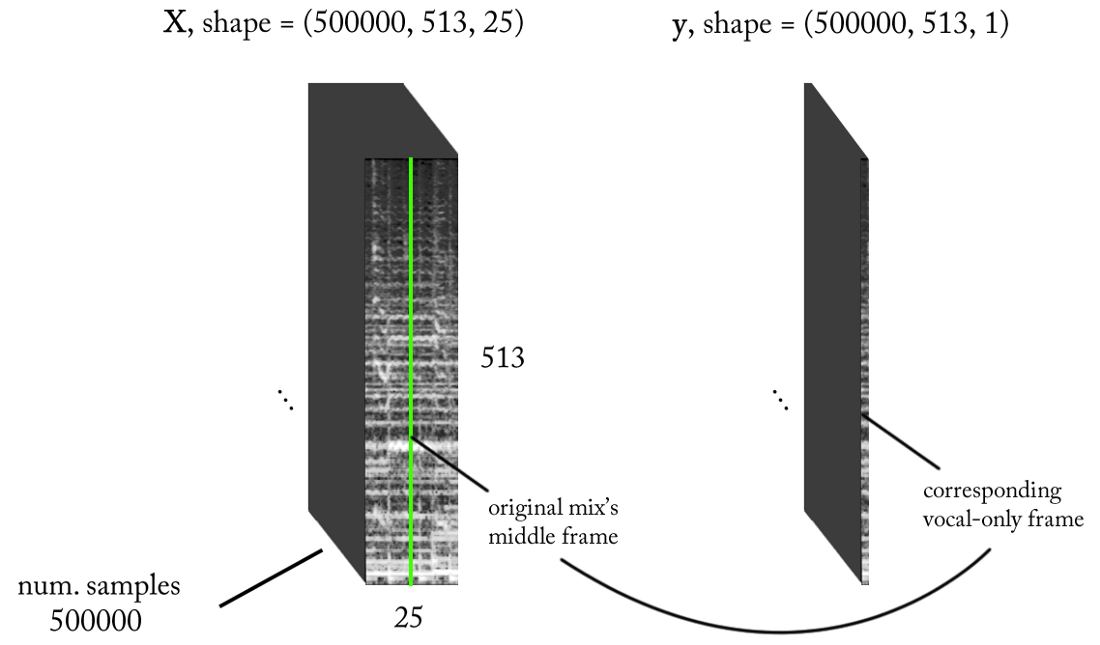
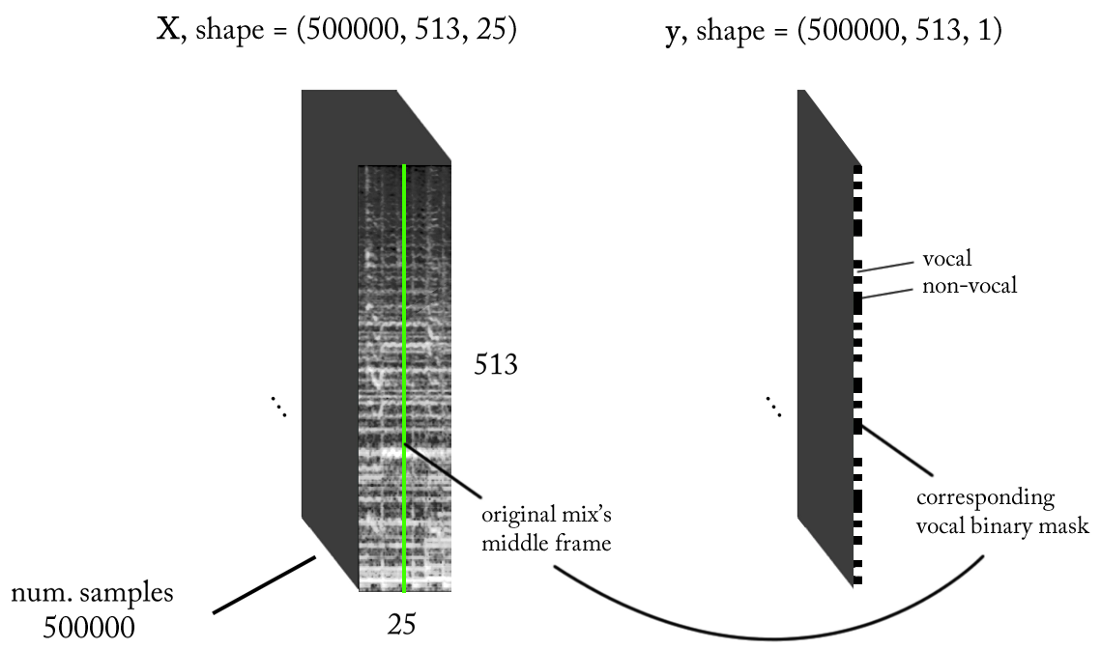
- Fréquence d'échantillonnage (fs): 22050 Hz (nous sous-échantillonnons de 44100 à 22050)
- Conception STFT: taille de fenêtre = 1024, taille de houblon = 256, interpolation de l' échelle de craie pour le filtre de pondération, en tenant compte de la perception. Puisque notre entrée est réelle , vous pouvez travailler avec la moitié du STFT (une explication dépasse le cadre de cet article ...) tout en conservant le composant DC (facultatif), ce qui nous donne 513 bins de fréquence.
- Résolution de classification cible: une trame STFT (~ 11,6 ms = 256/22050)
- Contexte temporel cible: ~ 300 millisecondes = 25 trames STFT.
- Le nombre cible d'exemples de formation: 500 000.
- En supposant que nous utilisons une fenêtre coulissante par incréments de 1 intervalle de temps STFT pour générer des données d'entraînement, nous avons besoin d'environ 1,6 heures de son balisé pour générer 500 000 échantillons de données
Avec les exigences ci-dessus, les entrées et sorties de notre classificateur binaire sont les suivantes:
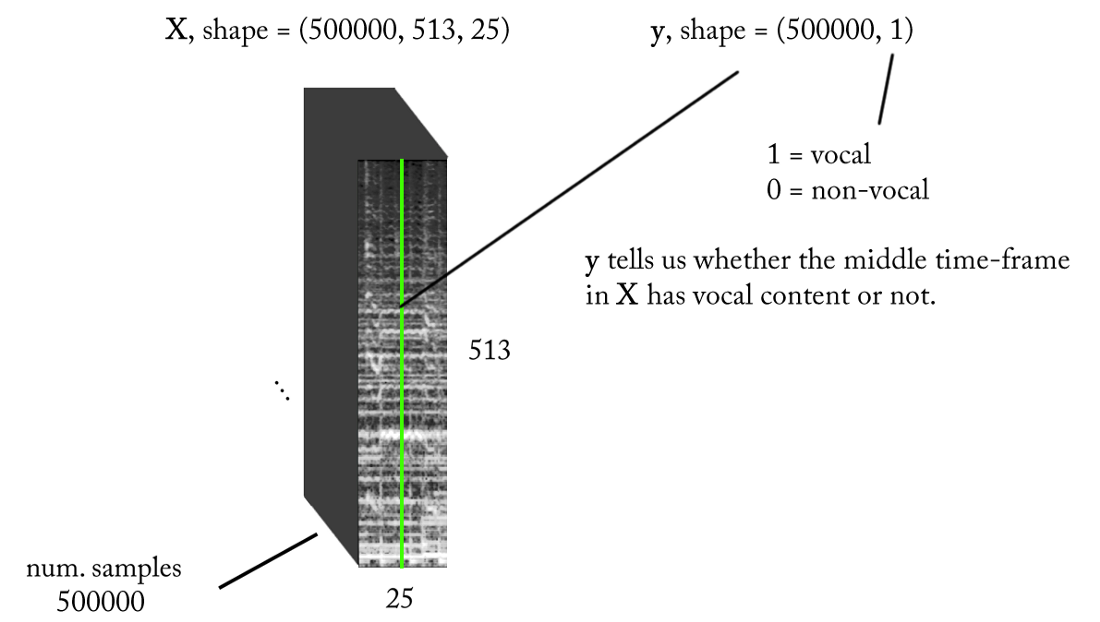
Modèle
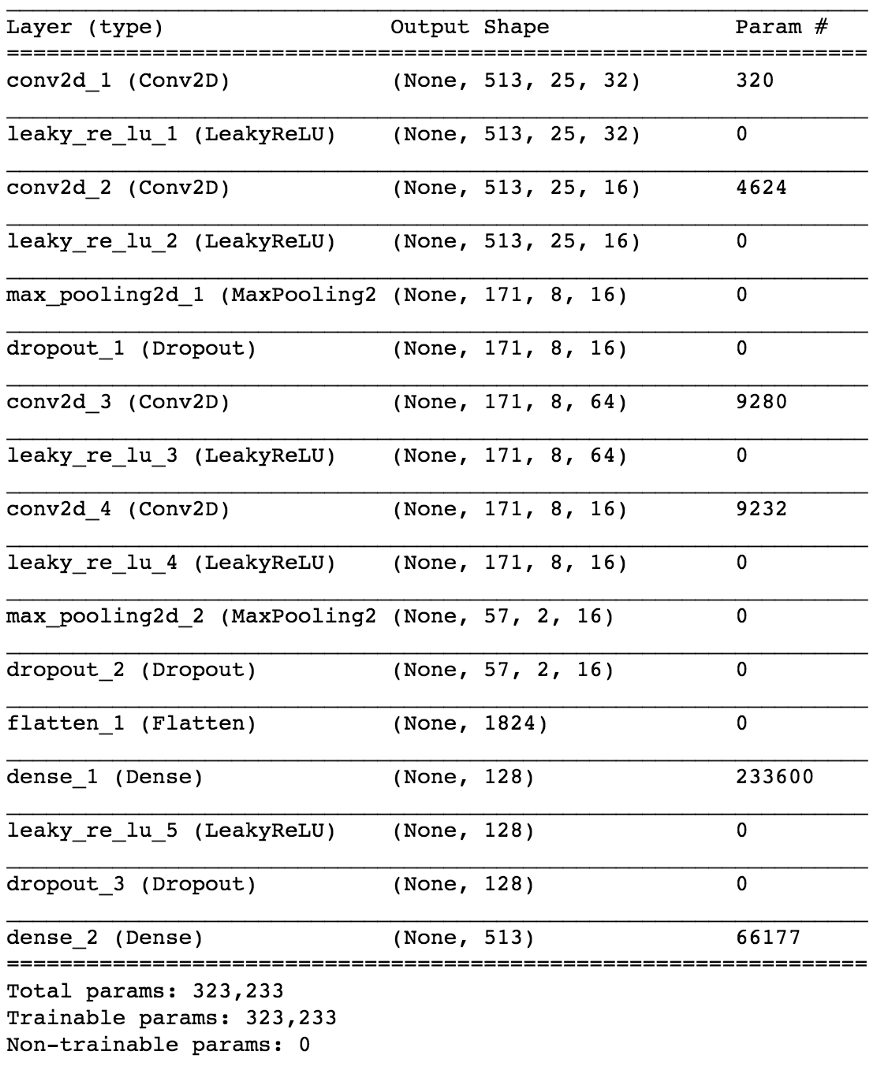
En utilisant Keras, nous allons construire un petit modèle de réseau neuronal pour tester notre hypothèse.
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])
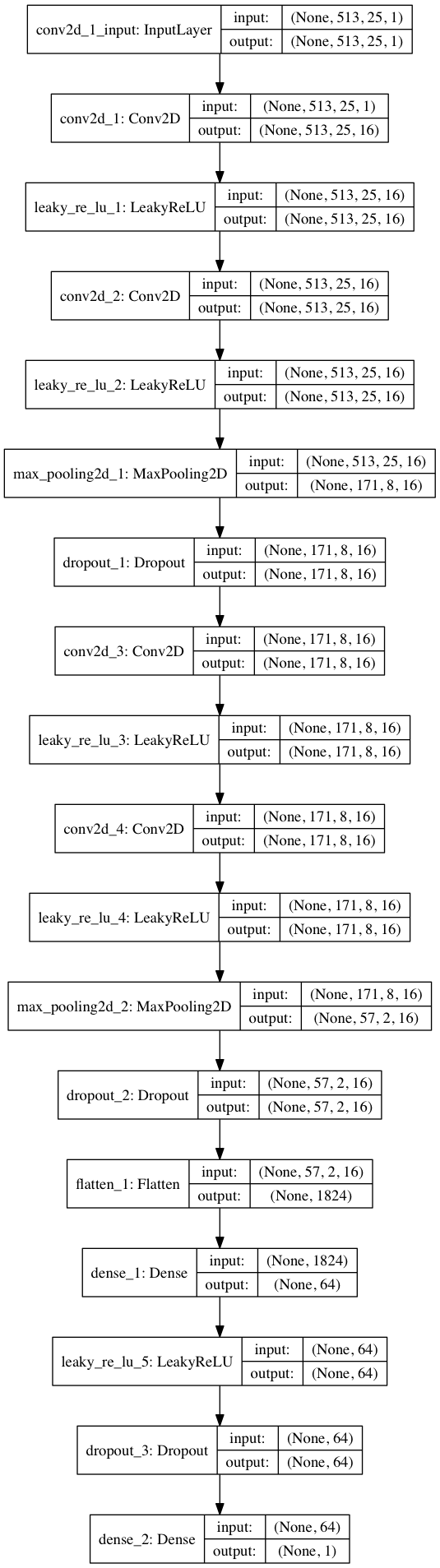
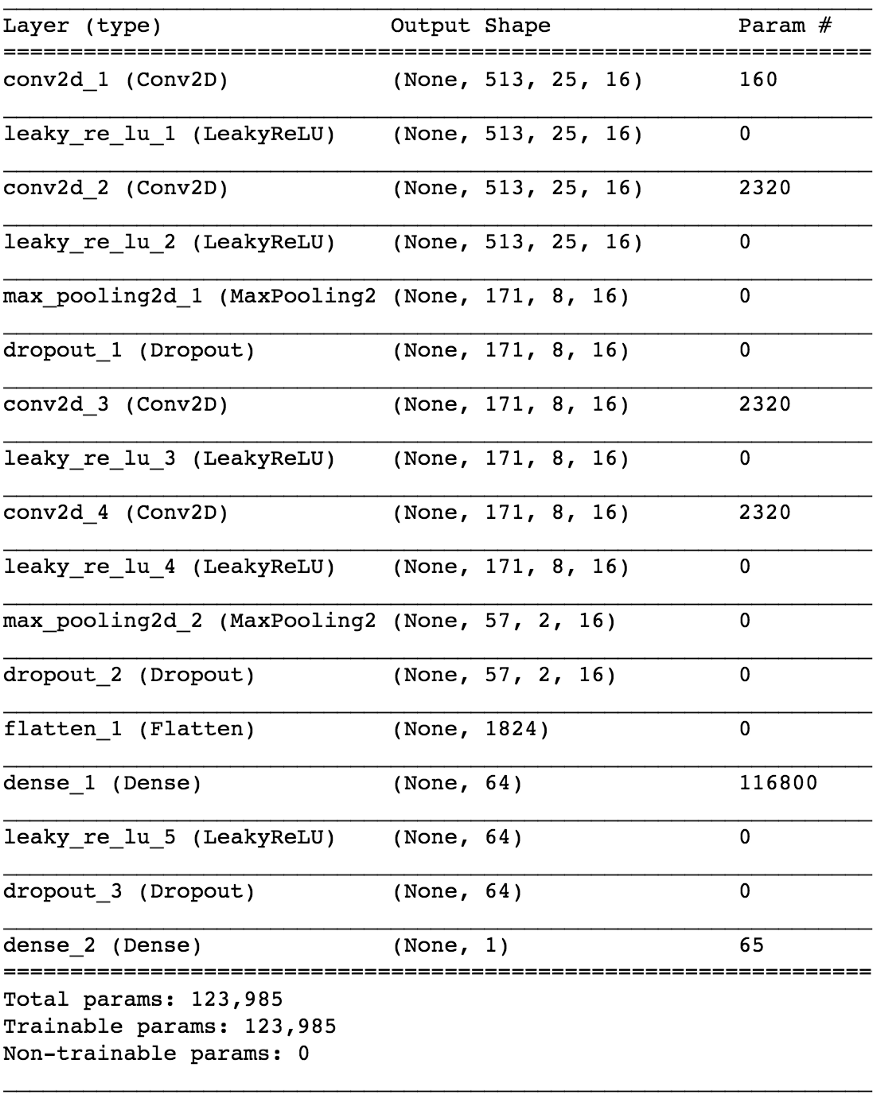
En divisant les données 80/20 en formation et test après ~ 50 époques, nous obtenons la
précision lors du test ~ 97% . C'est une preuve suffisante que notre modèle est capable de distinguer les voix dans les fragments sonores musicaux (et les fragments sans voix). Si nous vérifions certaines cartes d'entités de la 4ème couche convolutionnelle, nous pouvons conclure que le réseau neuronal semble avoir optimisé ses noyaux pour effectuer deux tâches: filtrer la musique et filtrer les voix ...
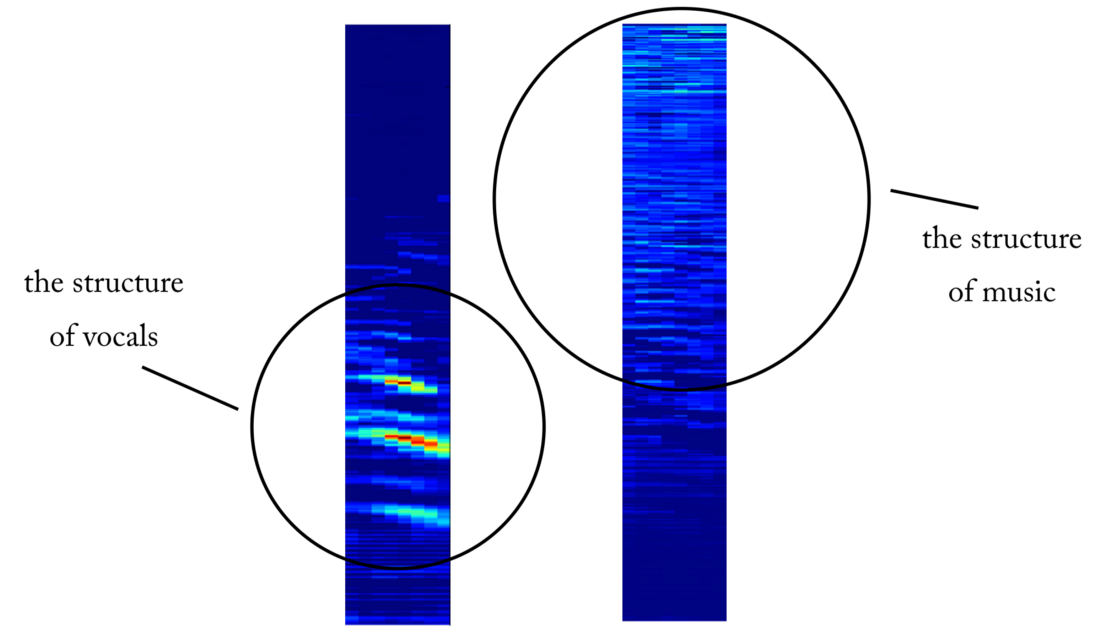 Un exemple de carte d'objets à la sortie de la 4ème couche convolutionnelle. Apparemment, la sortie de gauche est le résultat des opérations du noyau dans une tentative de préserver le contenu vocal tout en ignorant la musique. Les valeurs élevées ressemblent à la structure harmonieuse de la parole humaine. La carte des objets à droite semble être le résultat de la tâche opposée.
Un exemple de carte d'objets à la sortie de la 4ème couche convolutionnelle. Apparemment, la sortie de gauche est le résultat des opérations du noyau dans une tentative de préserver le contenu vocal tout en ignorant la musique. Les valeurs élevées ressemblent à la structure harmonieuse de la parole humaine. La carte des objets à droite semble être le résultat de la tâche opposée.Du détecteur vocal à la déconnexion du signal
Après avoir résolu le problème de classification plus simple, comment pouvons-nous passer à la véritable séparation du chant et de la musique? Eh bien, en regardant la première méthode
naïve , nous voulons toujours obtenir en quelque sorte un spectrogramme d'amplitude pour le chant. Maintenant, cela devient une tâche de régression. Ce que nous voulons faire est de calculer le spectre d'amplitude correspondant pour les voix dans cette période à partir de la STFT du signal d'origine, c'est-à-dire du mixage (avec un contexte temporel suffisant).
Qu'en est-il de l'ensemble de données de formation? (vous pouvez me demander en ce moment)Merde ... pourquoi donc. J'allais considérer cela à la fin de l'article afin de ne pas être distrait du sujet!
Si notre modèle est bien formé, alors pour une conclusion logique, il vous suffit d'implémenter une fenêtre coulissante simple pour le mélange STFT. Après chaque prévision, déplacez la fenêtre vers la droite d'un intervalle de temps, prédisez la prochaine trame avec voix et associez-la à la prédiction précédente. Quant au modèle, prenons le même modèle que celui utilisé pour le détecteur de voix et apportons de petits changements: la forme d'onde de sortie est désormais (513.1), activation linéaire en sortie, MSE en fonction des pertes. Nous commençons maintenant l'entraînement.
Ne vous réjouissez pas encore ...Bien que cette représentation des E / S soit logique, après avoir entraîné notre modèle plusieurs fois, avec divers paramètres et normalisations de données, il n'y a aucun résultat. Il semble que nous en demandions trop ...
Nous sommes passés d'un classifieur binaire à une
régression sur un vecteur à 513 dimensions. Bien que le réseau étudie le problème dans une certaine mesure, les voix restaurées ont toujours des artefacts évidents et des interférences provenant d'autres sources. Même après avoir ajouté des couches supplémentaires et augmenté le nombre de paramètres du modèle, les résultats ne changent pas beaucoup. Et puis la question se pose:
comment «simplifier» la tâche du réseau par la tromperie, et en même temps obtenir les résultats souhaités?Et si, au lieu d'estimer l'amplitude des voix STFT, nous formions le réseau pour obtenir un masque binaire, qui, appliqué au mixage STFT, nous donne un spectrogramme d'amplitude des voix simplifié mais
perceptuellement acceptable ?
En expérimentant diverses heuristiques, nous avons trouvé un moyen très simple (et, bien sûr, peu orthodoxe en termes de traitement du signal ...) d'extraire la voix de mixages à l'aide de masques binaires. Sans entrer dans les détails, l'essentiel est le suivant. Imaginez la sortie comme une image binaire, où la valeur «1» indique la
présence dominante de contenu vocal à une fréquence et une période de temps données, et la valeur «0» indique la présence dominante de musique à un endroit donné. Nous pouvons appeler cela la
binarisation de la perception , juste pour trouver un nom. Visuellement, ça a l'air assez moche, pour être honnête, mais les résultats sont étonnamment bons.
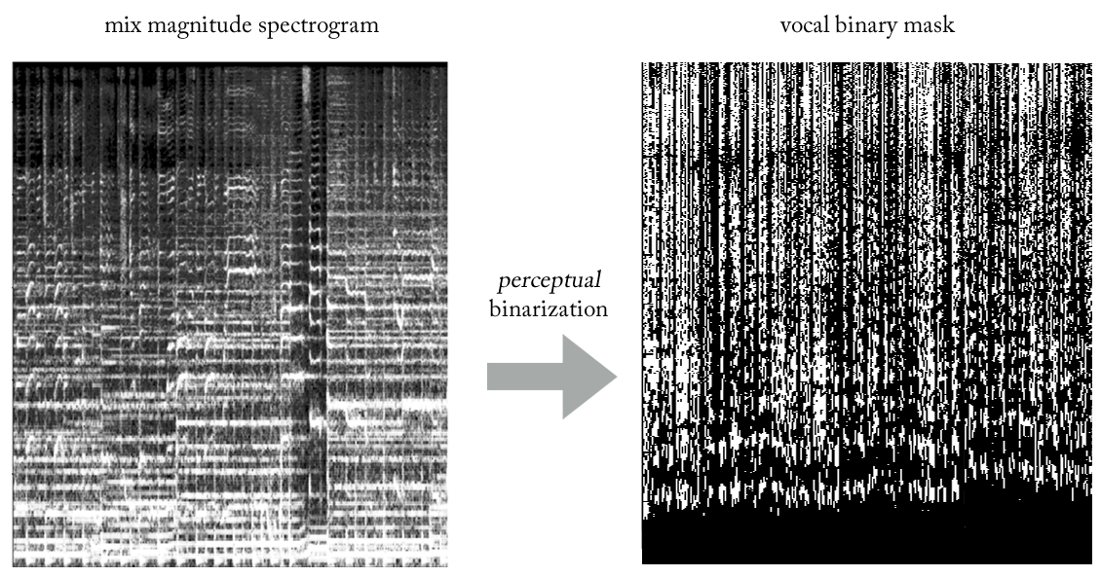
Maintenant, notre problème devient une sorte de classification-régression hybride (très grossièrement ...). Nous demandons au modèle de «classer les pixels» en sortie comme vocaux ou non vocaux, bien que conceptuellement (ainsi que du point de vue de la fonction de perte MSE utilisée) la tâche reste régressive.
Bien que cette distinction puisse sembler inappropriée pour certains, elle est en fait d'une grande importance dans la capacité du modèle à étudier la tâche, la seconde étant plus simple et plus limitée. En même temps, cela nous permet de garder notre modèle relativement petit en termes de nombre de paramètres, étant donné la complexité de la tâche, ce qui est très souhaitable pour travailler en temps réel, ce qui dans ce cas était une exigence de conception. Après quelques ajustements mineurs, le modèle final ressemble à ceci.
Comment récupérer un signal temporel?
En fait, comme dans la
méthode naïve . Dans ce cas, pour chaque passage, nous prédisons une période du masque de voix binaire. Encore une fois, réalisant une simple fenêtre coulissante avec un pas d'une période, nous continuons à évaluer et à combiner des périodes successives, qui constituent finalement le masque binaire vocal entier.

Créer un ensemble d'entraînement
Comme vous le savez, l'un des principaux problèmes lors de l'enseignement avec un enseignant (laissez ces exemples de jouets avec des jeux de données prêts à l'emploi) est les données correctes (en quantité et en qualité) pour le problème spécifique que vous essayez de résoudre. Sur la base des représentations décrites des entrées et des sorties, pour former notre modèle, vous aurez d'abord besoin d'un nombre important de mixages et de leurs pistes vocales correspondantes, parfaitement alignées et normalisées. Cet ensemble peut être créé de plusieurs façons, et nous avons utilisé une combinaison de stratégies, de la création manuelle de paires [mix <-> voix] basées sur plusieurs a cappels trouvés sur Internet, à la recherche de matériel musical de groupe de rock et de scrapbooking Youtube. Juste pour vous donner une idée de la lourdeur et de la pénibilité de ce processus, une partie du projet consistait à développer un tel outil pour créer automatiquement des paires [mix <-> voix]:

Une très grande quantité de données est nécessaire pour que le réseau neuronal apprenne la fonction de transfert pour la diffusion de mixages vocaux. Notre ensemble final était composé d'environ 15 millions d'échantillons de mélanges de 300 ms et de leurs masques binaires vocaux correspondants.
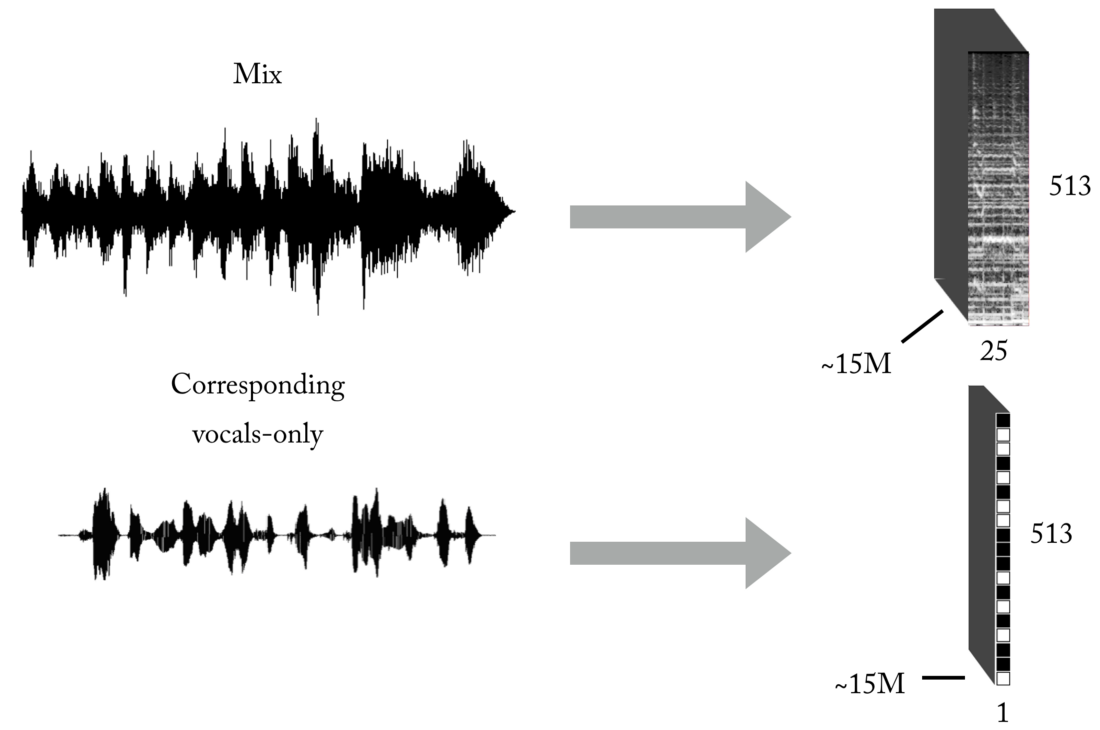
Architecture de pipeline
Comme vous le savez probablement, la création d'un modèle ML pour une tâche spécifique ne représente que la moitié de la bataille. Dans le monde réel, vous devez penser à l'architecture logicielle, surtout si vous avez besoin de travailler en temps réel ou à proximité.
Dans cette implémentation particulière, la reconstruction dans le domaine temporel peut se produire immédiatement après la prédiction du masque de voix binaire complet (mode autonome) ou, plus intéressant, en mode multithread, où nous recevons et traitons des données, restaurons la voix et reproduisons le son - le tout en petits segments, près de streaming et même presque en temps réel, le traitement de la musique qui est enregistrée à la volée avec un minimum de retard. En fait, c'est un sujet distinct, et je vais le laisser pour un autre article
sur les pipelines ML en temps réel ...
Je suppose que j'en ai assez dit, alors pourquoi ne pas écouter quelques exemples!?
Daft Punk - Get Lucky (enregistrement studio)
Ici, vous pouvez entendre une interférence minimale des tambours ...Adele - Set Fire to the Rain (enregistrement en direct!)
Remarquez comment au tout début notre modèle extrait les cris de la foule sous forme de contenu vocal :). Dans ce cas, il y a des interférences provenant d'autres sources. Comme il s'agit d'un enregistrement live, il semble acceptable que les voix extraites soient de moins bonne qualité que les précédentes.Oui, et «autre chose» ...
Si le système fonctionne pour le chant, pourquoi ne pas l'appliquer à d'autres instruments ...?
L'article est déjà assez volumineux, mais compte tenu du travail accompli, vous méritez d'entendre la dernière démo. Avec la même logique exacte que lors de l'extraction de voix, nous pouvons essayer de diviser la musique stéréo en composants (batterie, basse, voix, autres), en apportant quelques changements à notre modèle et, bien sûr, en ayant le jeu d'entraînement approprié :).
Merci d'avoir lu. Enfin, comme vous pouvez le voir, le modèle actuel de notre réseau de neurones convolutionnels n'est pas si spécial. Le succès de ce travail a été déterminé par l'
ingénierie des fonctionnalités et le processus de test d'hypothèse soigné, dont je parlerai dans les prochains articles!