Bonjour encore. Aujourd'hui, nous continuons à partager du matériel dédié au lancement du cours
"Network Engineer" , qui commence déjà début mars. Nous voyons que beaucoup étaient intéressés par la
première partie de l'article «Approche synesthésique par machine pour détecter les attaques DDoS réseau» et aujourd'hui, nous voulons partager avec vous la seconde - la dernière partie.
3.2 Classification d'images dans le problème de la détection d'anomaliesL'étape suivante consiste à résoudre le problème de classification de l'image résultante. En général, la solution au problème de détection des classes (objets) dans une image consiste à utiliser des algorithmes d'apprentissage automatique pour créer des modèles de classe, puis des algorithmes pour rechercher des classes (objets) dans une image.

La construction d'un modèle comprend deux étapes:
a) Extraction d'entités pour une classe: tracer des vecteurs d'entités pour les membres de la classe.

Fig. 1
b) Formation aux caractéristiques du modèle obtenu pour les tâches de reconnaissance ultérieures.
L'objet classe est décrit à l'aide de vecteurs de fonction. Les vecteurs sont formés de:
a) informations sur les couleurs (histogramme à gradient orienté);
b) informations contextuelles;
c) des données sur la disposition géométrique des parties de l'objet.
L'algorithme de classification (prévision) peut être divisé en deux étapes:
a) Extraire des fonctionnalités de l'image. A ce stade, deux tâches sont effectuées:
- Étant donné que l'image peut contenir des objets de nombreuses classes, nous devons trouver tous les représentants. Pour ce faire, vous pouvez utiliser une fenêtre coulissante qui traverse l'image du coin supérieur gauche au coin inférieur droit.
- L'image est mise à l'échelle car l'échelle des objets dans l'image peut changer.
b) associer une image à une classe particulière. Une description formelle de la classe, c'est-à-dire un ensemble de fonctionnalités mises en évidence par leurs images de test, est utilisée en entrée. Sur la base de ces informations, le classificateur décide si l'image appartient à la classe et évalue le degré de certitude pour la conclusion.
Méthodes de classification. Les méthodes de classification vont des approches principalement heuristiques aux procédures formelles basées sur des méthodes de statistiques mathématiques. Il n'y a pas de classification généralement acceptée, mais plusieurs approches de classification d'images peuvent être distinguées:
- méthodes de modélisation d'objets basées sur les détails;
- méthodes du «sac de mots»;
- méthodes d'appariement des pyramides spatiales.
Pour l'implémentation présentée dans cet article, les auteurs ont choisi l'algorithme «word bag» pour les raisons suivantes:
- Les algorithmes de modélisation basés sur les détails et les pyramides spatiales correspondantes sont sensibles à la position des descripteurs dans l'espace et à leur position relative. Ces classes de méthodes sont efficaces dans les tâches de détection d'objets dans une image; cependant, en raison des caractéristiques des données d'entrée, elles sont mal applicables au problème de la classification des images.
- L'algorithme du «sac de mots» a été largement testé dans d'autres domaines de la connaissance, il montre de bons résultats et est assez simple à mettre en œuvre.
Pour analyser le flux vidéo projeté à partir du trafic, nous avons utilisé le classificateur naïf de Bayes [25]. Il est souvent utilisé pour classer les textes en utilisant le modèle de sac de mots. Dans ce cas, l'approche est similaire à l'analyse de texte, au lieu des mots, seuls les descripteurs sont utilisés. Le travail de ce classificateur peut être divisé en deux parties: la phase de formation et la phase de prévision.
Phase d'apprentissage . Chaque trame (image) est envoyée à l'entrée de l'algorithme de recherche de descripteur, dans ce cas, la transformation de caractéristique invariante d'échelle (SIFT) [26]. Après cela, la tâche de corrélation des points singuliers entre les trames est effectuée. Un point particulier de l'image d'un objet est un point susceptible d'apparaître sur d'autres images de cet objet.
Pour résoudre le problème de la comparaison de points particuliers d'un objet dans différentes images, un descripteur est utilisé. Un descripteur est une structure de données, un identifiant pour un point singulier qui le distingue des autres. Elle peut ou non être invariante par rapport aux transformations de l'image de l'objet. Dans notre cas, le descripteur est invariant par rapport aux transformations de perspective, c'est-à-dire à l'échelle. La poignée vous permet de comparer le point caractéristique d'un objet dans une image avec le même point caractéristique dans une autre image de cet objet.
Ensuite, l'ensemble des descripteurs obtenus à partir de toutes les images est trié en groupes par similitude à l'aide de la méthode de regroupement k-means [26, 27]. Ceci est fait afin de former le classificateur, ce qui permettra de déterminer si l'image représente un comportement anormal.
Voici un algorithme étape par étape pour l'apprentissage du classificateur de descripteur d'image:
Étape 1 Extrayez tous les descripteurs des ensembles avec et sans attaque.
Étape 2 Regroupement de tous les descripteurs à l'aide de la méthode k-means dans n grappes.
Étape 3 Calcul de la matrice A (m, k), où m est le nombre d'images et k est le nombre de grappes. L'élément (i; j) stockera la valeur de la fréquence d'apparition des descripteurs du j-ème cluster sur la i-ème image. Une telle matrice sera appelée matrice de la fréquence d'occurrence.
Étape 4 Calcul des poids des descripteurs par la formule tf idf [28]:
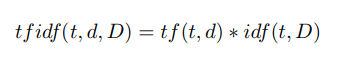
Ici tf («terme fréquence») est la fréquence d'apparition du descripteur dans cette image et est définie comme
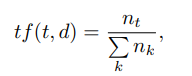
où t est le descripteur, k est le nombre de descripteurs dans l'image, nt est le nombre de descripteurs t dans l'image. De plus, idf («fréquence de document inverse») est la fréquence d'image inverse avec un descripteur donné dans l'échantillon et est définie comme
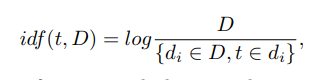
où D est le nombre d'images avec un descripteur donné dans l'échantillon, {di ∈ D, t ∈ di} est le nombre d'images en D, où t est en nt! = 0.
Étape 5 Substitution des poids correspondants au lieu des descripteurs dans la matrice A.
Étape 6 Classification. Nous utilisons l'amplification de classificateurs naïfs de Bayes (adaboost).
Étape 7 Enregistrement du modèle formé dans un fichier.
Étape 8 Ceci conclut la phase de formation.
Phase de prédiction . Les différences entre la phase d'apprentissage et la phase de prévision sont faibles: les descripteurs sont extraits de l'image et corrélés avec les groupes existants. Sur la base de ce rapport, un vecteur est construit. Chaque élément de ce vecteur est la fréquence d'apparition des descripteurs de ce groupe dans l'image. En analysant ce vecteur, le classificateur peut faire une prévision d'attaque avec une certaine probabilité.
Un algorithme de prévision général basé sur une paire de classificateurs est présenté ci-dessous.
Étape 1 Extraire tous les descripteurs de l'image;
Étape 2 Regroupement de l'ensemble de descripteurs résultant;
Étape 3 Calcul du vecteur [1, k];
Étape 4 Calcul du poids pour chaque descripteur selon la formule tf idf présentée ci-dessus;
Étape 5 Remplacer la fréquence d'occurrence des vecteurs par leur poids;
Étape 6 Classification du vecteur résultant selon un classificateur préalablement formé;
Étape 7 Conclusion sur la présence d'anomalies dans le réseau observé basée sur la prévision du classifieur.
4. Évaluation de l'efficacité de détectionLa tâche d'évaluer l'efficacité de la méthode proposée a été résolue expérimentalement. Dans l'expérience, un certain nombre de paramètres établis expérimentalement ont été utilisés. Pour le clustering, 1000 clusters ont été utilisés. Les images générées avaient 1000 par 1000 pixels.
4.1 Ensemble de données expérimentalesPour les expériences, l'installation a été montée. Il se compose de trois appareils connectés par un canal de communication. Le schéma fonctionnel d'installation est illustré à la figure 2.
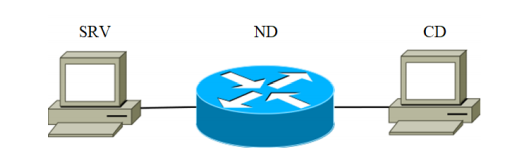
Fig.1
Le périphérique SRV agit en tant que serveur attaquant (ci-après dénommé serveur cible). Les périphériques répertoriés dans le tableau 1 avec le code SRV ont été utilisés séquentiellement comme serveur cible. Le second est un périphérique réseau conçu pour transmettre des paquets réseau. Les caractéristiques de l'appareil sont présentées dans le tableau 1 sous le code ND-1.
Tableau 1. Spécifications des périphériques réseau
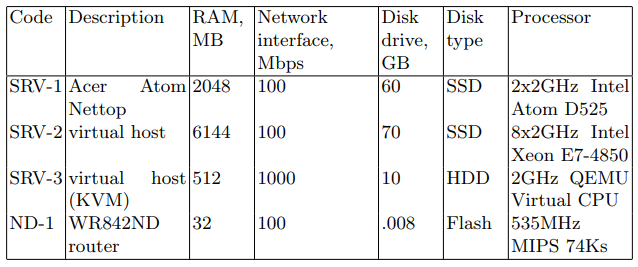
Sur les serveurs cibles, les paquets réseau ont été écrits dans un fichier PCAP pour une utilisation ultérieure dans les algorithmes de découverte. L'utilitaire tcpdump a été utilisé pour cette tâche. Les jeux de données sont décrits dans le tableau 2.
Tableau 2. Ensembles de paquets réseau interceptés
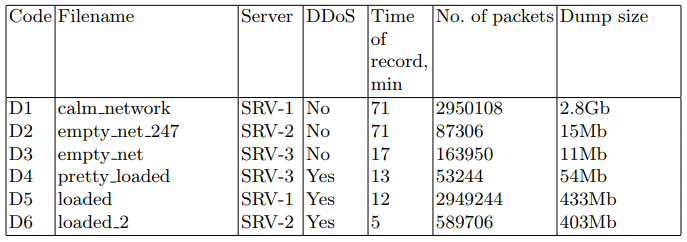
Les logiciels suivants ont été utilisés sur les serveurs cibles: distribution Linux, serveur Web nginx 1.10.3, SGBD postgresql 9.6. Une application Web spéciale a été écrite pour émuler le démarrage du système. L'application demande une base de données avec une grande quantité de données. La demande est conçue pour minimiser l'utilisation de la mise en cache divers. Au cours des expériences, des demandes pour cette application Web ont été générées.
L'attaque a été effectuée à partir du troisième périphérique client (tableau 1) à l'aide de l'utilitaire Apache Benchmark. La structure du trafic de fond pendant l'attaque et le reste du temps est présentée dans le tableau 3.
Tableau 3. Fonctions de trafic en arrière-plan
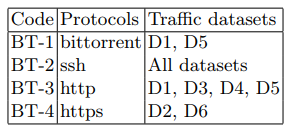
En tant qu'attaque, nous implémentons la version DoS distribuée du déluge HTTP GET. Une telle attaque, en fait, est la génération d'un flux constant de requêtes GET, dans ce cas à partir d'un périphérique CD-1. Pour le générer, nous avons utilisé l'utilitaire ab du paquet apache-utils. En conséquence, des fichiers contenant des informations sur l'état du réseau ont été reçus. Les principales caractéristiques de ces fichiers sont présentées dans le tableau 2. Les principaux paramètres du scénario d'attaque sont présentés dans le tableau 4.
À partir du vidage du trafic réseau reçu, des ensembles d'images générées TD # 1 et TD # 2 ont été obtenus, qui ont été utilisés au stade de la formation. L'échantillon TD # 3 a été utilisé pour la phase de prédiction. Un résumé des ensembles de données de test est présenté dans le tableau 5.
4.2 Critères de performanceLes principaux paramètres évalués au cours de cette étude étaient:
Tableau 4. Caractéristiques d'une attaque DDoS

Tableau 5. Ensembles d'images de test

a) DR (Detection Rate) - le nombre d'attaques détectées par rapport au nombre total d'attaques. Plus ce paramètre est élevé, plus l'efficacité et la qualité de l'ADS sont élevées.
b) FPR (False Positive Rate) - le nombre d'objets «normaux», classés à tort comme une attaque, par rapport au nombre total d'objets «normaux». Plus ce paramètre est bas, plus l'efficacité et la qualité du système de détection d'anomalies sont élevées.
c) CR (taux complexe) est un indicateur complexe qui prend en compte la combinaison des paramètres DR et FPR. Étant donné que les paramètres DR et FPR ont pris une importance égale dans l'étude, l'indicateur complexe a été calculé comme suit: CR = (DR + FPR) / 2.
1000 images marquées comme "anormales" ont été soumises au classificateur. Sur la base des résultats de reconnaissance, DR a été calculé en fonction de la taille de l'échantillon d'apprentissage. Les valeurs suivantes ont été obtenues: pour TD # 1 DR = 9,5% et pour TD # 2 DR = 98,4%. De plus, la seconde moitié des images («normales») a été classée. Sur la base du résultat, le FPR a été calculé (pour TD # 1 FPR = 3,2% et pour TD # 2 FPR = 4,3%). Ainsi, les indicateurs de performance complets suivants ont été obtenus: pour TD # 1 CR = 53,15% et pour TD # 2 CR = 97,05%.
5. Conclusions et recherches futuresLes résultats expérimentaux montrent que la méthode proposée pour détecter les anomalies montre des résultats élevés dans la détection des attaques. Par exemple, dans un grand échantillon, la valeur d'un indicateur de performance complet atteint 97%. Cependant, cette méthode a certaines limites d'application:
1. Les valeurs de DR et FPR montrent la sensibilité de l'algorithme à la taille de l'ensemble d'apprentissage, qui est un problème conceptuel pour les algorithmes d'apprentissage automatique. L'augmentation de l'échantillon améliore les performances de détection. Cependant, il n'est pas toujours possible de mettre en œuvre un ensemble de formation suffisamment grand pour un réseau particulier.
2. L'algorithme développé est déterministe, la même image est classée à chaque fois avec le même résultat.
3. Les indicateurs d'efficacité de l'approche sont suffisamment bons pour confirmer le concept, mais le nombre de faux positifs est également important, ce qui peut entraîner des difficultés de mise en œuvre pratique.
Afin de surmonter la limitation décrite ci-dessus (point 3), il est censé changer le classificateur bayésien naïf en un réseau neuronal convolutionnel, ce qui, selon les auteurs, devrait augmenter la précision de l'algorithme de détection d'anomalies.
Les références1. Mohiuddin A., Abdun NM, Jiankun H.: Une étude des techniques de détection des anomalies de réseau. Dans: Journal of Network and Computer Applications. Vol. 60, p. 21 (2016)
2. Afontsev E.: Anomalies de réseau, 2006
nag.ru/articles/reviews/15588 setevyie-anomalii.html
3. Berestov AA: Architecture d'agents intelligents basée sur un système de production pour se protéger contre les attaques de virus sur Internet. Dans: XV Conférence scientifique panrusse sur les problèmes de sécurité de l'information dans le système des écoles supérieures », pp. 180? 276 (2008)
4. Galtsev AV: Analyse du système de trafic pour identifier les conditions de réseau anormales: La thèse du Candidat Degree of Technical Sciences. Samara (2013)
5. Kornienko AA, Slyusarenko IM: Systèmes et méthodes de détection des intrusions: état actuel et direction de l'amélioration, 2008
citforum.ru/security internet / ids overview /
6. Kussul N., Sokolov A.: Détection adaptative d'anomalies dans le comportement des utilisateurs de systèmes informatiques à l'aide de chaînes de Markov d'ordre variable. Partie 2: Méthodes de détection des anomalies et résultats des expériences. Dans: Problèmes informatiques et de contrôle. Numéro 4, pp. 83? 88 (2003)
7. Mirkes EM: Neuro-ordinateur: projet de norme. Science, Novossibirsk, pp. 150-176 (1999)
8. Tsvirko DA Prediction of a network attack route using production model methods, 2012
academy.kaspersky.com/downloads/academycup participants / cvirko d. ppt
9. Somayaji A.: Réponse automatisée utilisant des retards d'appels système. Dans: USENIX Security Symposium 2000, pp. 185-197, 2000
10. Ilgun K.: USTAT: Un système de détection d'intrusion en temps réel pour UNIX. Dans: IEEE Symposium on Research in Security and Privacy, University of California (1992)
11. Eskin E., Lee W. et Stolfo SJ: le système de modélisation nécessite la détection d'intrusions avec des tailles de fenêtres dynamiques. Dans: DARPA Information Survivability Conference and Exposition (DISCEX II), juin 2001
12. Ye N., Xu M. et Emran SM: réseaux probabilistes avec liens non orientés pour la détection d'anomalies. In: 2000 IEEE Workshop on Information Assurance and Security, West Point, NY (2000)
13. Michael CC et Ghosh A.: Deux approches basées sur les états pour la détection d'anomalies par programme. Dans: ACM Transactions on Information and System Security. Non. 5 (2), 2002
14. Garvey TD, Lunt TF: Détection d'intrusion basée sur un modèle. Dans: 14th Nation computer security conference, Baltimore, MD (1991)
15. Theus M. et Schonlau M.: Détection d'intrusions basée sur des zéros structurels. Dans: Bulletin statistique statistique et graphique. Non. 9 (1), pp. 12? 17 (1998)
16. Tan K.: L'application des réseaux de neurones à la sécurité informatique unix. Dans: Conférence internationale de l'IEEE sur les réseaux de neurones. Vol. 1, pp. 476? 481, Perth, Australie (1995)
17. Ilgun K., Kemmerer RA, Porras PA: State Transition Analysis: A Rule-Based Intrusion Detection System. Dans: IEEE Trans. Software Eng. Vol. 21, non. 3, (1995)
18. Eskin E.: Détection d'anomalies sur des données bruyantes en utilisant les distributions de probabilité apprises. Dans: 17th International Conf. sur l'apprentissage automatique, pp. 255? 262. Morgan Kaufmann, San Francisco, Californie (2000)
19. Ghosh K., Schwartzbard A. et Schatz M.: Apprentissage des profils de comportement du programme pour la détection des intrusions. In: 1er atelier USENIX sur la détection des intrusions et la surveillance du réseau, pp. 51? 62, Santa Clara, Californie (1999)
20. Ye N.: Un modèle de chaîne de Markov du comportement temporel pour la détection d'anomalies. In: 2000 IEEE Systems, Man, and Cybernetics, Information Assurance and Security Workshop (2000)
21. Axelsson S.: L'erreur de taux de base et ses implications pour la difficulté de détection d'intrusion. Dans: ACM Conference on Computer and Communications Security, pp. 1? 7 (1999)
22. Chikalov I, Moshkov M, Zielosko B.: Optimisation des règles de décision basées sur des méthodes de programmation dynamique. Dans Vestnik de l'Université d'État Lobachevsky de Nizhni Novgorod, no. 6, pp. 195-200
23. Chen CH: Manuel de reconnaissance des formes et de vision par ordinateur. Université du Massachusetts Dartmouth, États-Unis (2015)
24. Gantmacher FR: Théorie des matrices, p. 227. Science, Moscou (1968)
25. Murty MN, Devi VS: Pattern Recognition: An Algorithmic. Pp. 93-94 (2011)
Traditionnellement, nous attendons vos commentaires et nous invitons tout le monde à une
journée portes ouvertes , qui se tiendra lundi prochain.