
Lorsque les orchestrateurs de conteneurs comme Kubernetes sont arrivés, l'approche du développement et du déploiement d'applications a radicalement changé. Des microservices sont apparus, et pour le développeur, la logique applicative n'est plus connectée à l'infrastructure: créez des applications pour vous et offrez de nouvelles fonctions.
Kubernetes résume les ordinateurs physiques qu'il contrôle. Dites-lui simplement la quantité de mémoire et de puissance de traitement dont vous avez besoin - et vous obtiendrez tout. Infrastructure? Non, pas entendu.
La gestion des images Docker, Kubernetes et des applications le rend portable. Après avoir développé des applications de conteneur avec Kubernetes, vous pouvez les déployer n'importe où: dans un cloud ouvert, localement ou dans un environnement hybride - sans changer le code.
Nous aimons Kubernetes pour l'évolutivité, la portabilité et la gérabilité, mais il ne stocke pas l'état. Mais nous avons presque toutes les applications avec état, c'est-à-dire qu'elles ont besoin d'un stockage externe.
Kubernetes a une architecture très dynamique. Les conteneurs sont créés et détruits en fonction de la charge et des instructions des développeurs. Les gousses et les conteneurs sont auto-réparateurs et se répliquent. Ils sont essentiellement éphémères.
Le stockage externe est trop difficile pour une telle variabilité. Il n'obéit pas aux règles de création et de destruction dynamiques.
Il suffit de déployer une application avec état dans une autre infrastructure: dans un autre cloud, localement ou dans un modèle hybride - comment elle a des problèmes de portabilité. Le stockage externe peut être lié à un cloud spécifique.
Mais ce n'est que dans ces stockages pour les applications cloud que le diable lui-même se cassera la jambe. Et allez comprendre les significations fictives et les significations de la terminologie du stockage dans Kubernetes . Et il existe des référentiels propres à Kubernetes, des plateformes open source, des services gérés ou payants ...
Voici quelques exemples de stockage cloud CNCF :

Il semblerait que déployer la base de données dans Kubernetes - il vous suffit de sélectionner la solution appropriée, de l'emballer dans un conteneur pour travailler sur le disque local et de la déployer sur le cluster en tant que charge de travail suivante. Mais la base de données a ses propres particularités, donc penser n'est pas une glace.
Conteneurs - ils sont tellement pavés qu'ils ne préservent pas leur état. C'est pourquoi ils sont si faciles à démarrer et à arrêter. Et comme il n'y a rien à sauvegarder et à transférer, le cluster ne se soucie pas des opérations de lecture et de copie.
Vous devrez stocker l'état dans la base de données. Si une base de données déployée sur un cluster dans un conteneur ne migre nulle part et ne démarre pas trop souvent, la physique du stockage de données entre en jeu. Idéalement, les conteneurs qui utilisent des données devraient être dans le même foyer que la base de données.
Dans certains cas, la base de données peut bien sûr être déployée dans un conteneur. Dans un environnement de test ou dans des tâches où il y a peu de données, les bases de données vivent confortablement dans des clusters.
La production nécessite généralement un stockage externe.
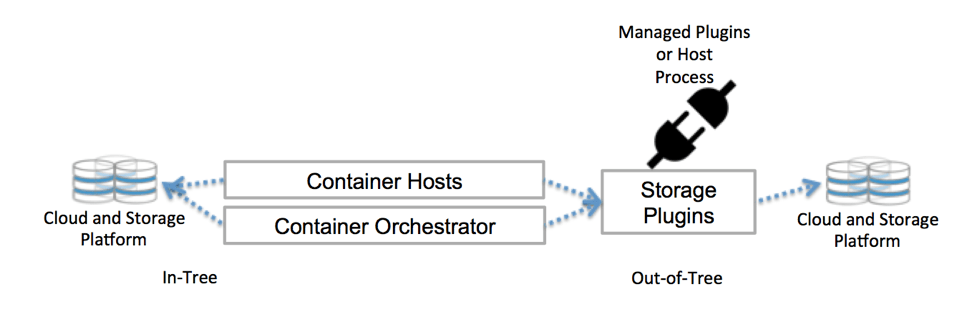
Kubernetes communique avec le référentiel via des interfaces de plan de contrôle. Ils lient Kubernetes au stockage externe. Le stockage externe attaché à Kubernetes est appelé plugins de volume. Avec eux, vous pouvez résumer le stockage et transférer le stockage.
Les plugins de volume étaient auparavant créés , liés, compilés et fournis à l'aide de la base de code Kubernetes. Cela limitait considérablement les développeurs et nécessitait une maintenance supplémentaire: si vous souhaitez ajouter de nouveaux référentiels, veuillez modifier la base de code de Kubernetes.
Déployez maintenant des plugins de volume sur le cluster - je ne veux pas. Et vous n'avez pas besoin de creuser dans la base de code. Merci à CSI et Flexvolume.
Stockage natif Kubernetes
Comment Kubernetes résout-il les problèmes de stockage? Il existe plusieurs solutions: options éphémères, stockage persistant dans des volumes persistants, requêtes de revendication de volume persistant, classes de stockage ou StatefulSets. Allez le comprendre, en général.
Les volumes persistants (PV) sont des unités de stockage préparées par l'administrateur. Ils ne dépendent pas des foyers et de leur vie éphémère.
Les revendications de volume persistantes (PVC) sont des demandes de stockage, c'est-à-dire PV. Avec PVC, vous pouvez lier le stockage à un nœud et ce nœud l'utilisera.
Vous pouvez travailler avec le stockage de manière statique ou dynamique.
Avec une approche statique, l'administrateur prépare les PV, qui sont censés être nécessaires à l'avance, avant les demandes, et ces PV sont liés manuellement à des pods spécifiques à l'aide de PVC explicites.
Dans la pratique, les PV spécialement définis ne sont pas compatibles avec la structure portable Kubernetes - le stockage dépend de l'environnement, comme AWS EBS ou un lecteur permanent GCE. Pour lier manuellement, vous devez pointer vers un référentiel spécifique dans le fichier YAML.
L'approche statique contredit généralement la philosophie de Kubernetes: les processeurs et la mémoire ne sont pas alloués à l'avance et ne sont pas liés à des pods ou des conteneurs. Ils sont émis dynamiquement.
Pour l'approvisionnement dynamique, nous utilisons des classes de stockage. L'administrateur de cluster n'a pas besoin de créer le PV à l'avance. Il crée plusieurs profils de stockage, comme des modèles. Lorsqu'un développeur fait une demande PVC, au moment de la demande, l'un de ces motifs est créé et attaché au foyer.

Donc, dans les termes les plus généraux, Kubernetes fonctionne avec un stockage externe. Il existe de nombreuses autres options.
CSI - Interface de stockage de conteneurs
Il y a une telle chose - Interface de stockage de conteneurs . Le CSI a été créé par le groupe de travail du coffre-fort de la CNCF, qui a décidé de définir une interface de stockage de conteneurs standard afin que les pilotes du coffre-fort fonctionnent avec n'importe quel orchestre.
Les spécifications CSI sont déjà adaptées pour Kubernetes, et il existe des tonnes de plugins de pilotes pour les déploiements dans le cluster Kubernetes. Vous devez accéder au référentiel via un pilote de volume compatible CSI - utilisez le type de volume csi dans Kubernetes.
Avec CSI, le stockage peut être considéré comme une autre charge de travail pour la conteneurisation et le déploiement sur le cluster Kubernetes.
Pour plus de détails, écoutez Jie Yu parler de CSI dans notre podcast .
Projets open source
Les outils et projets pour les technologies cloud se multiplient rapidement, et une bonne partie des projets open source - ce qui est logique - résout l'un des principaux problèmes de production: travailler avec le stockage dans l'architecture cloud.
Les plus populaires d'entre eux sont Ceph et Rook.
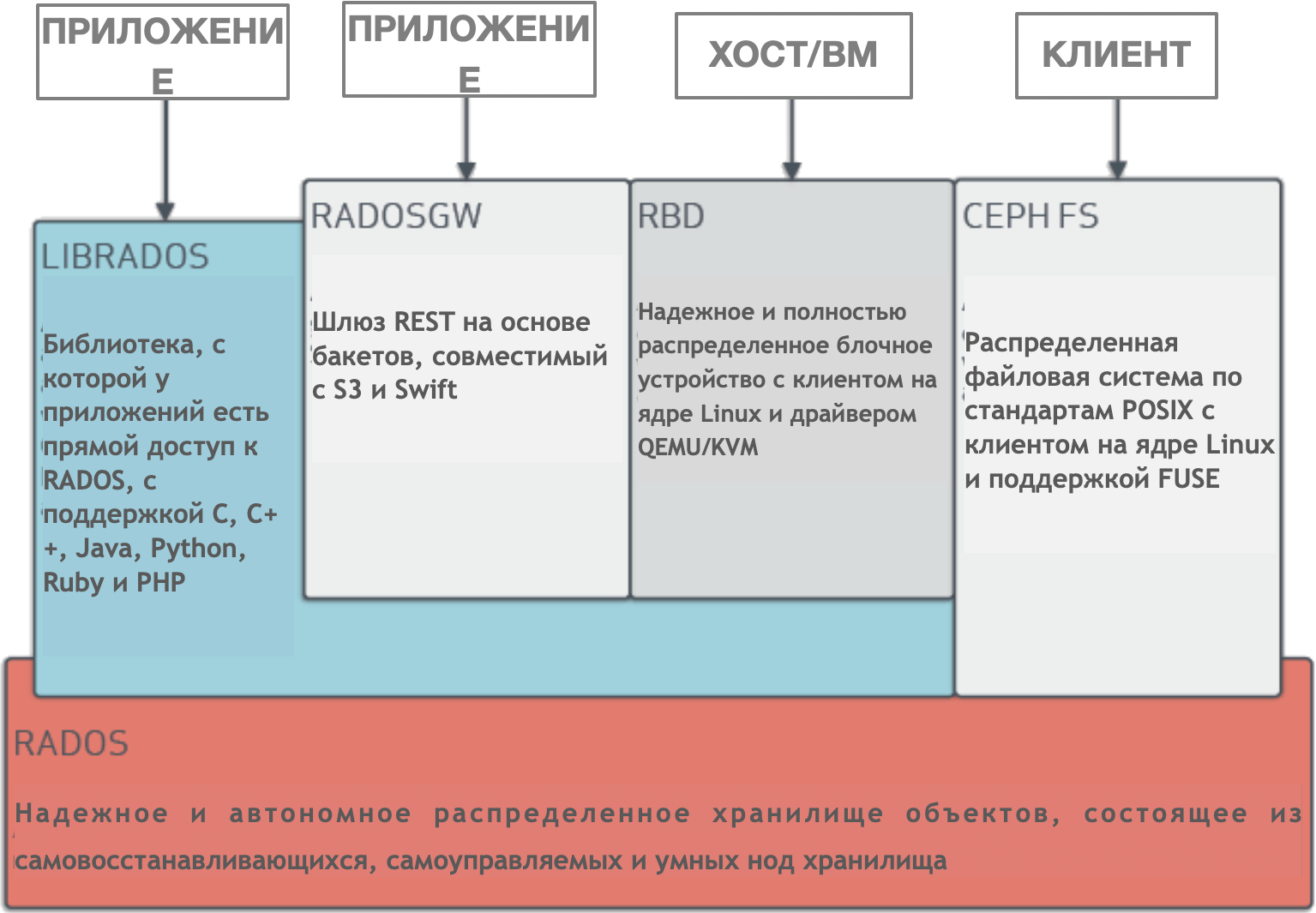
Ceph est un cluster de stockage distribué géré dynamiquement avec une mise à l'échelle horizontale. Ceph fournit une abstraction logique pour les ressources de stockage. Il n'a pas de point de défaillance unique, il se gère lui-même et fonctionne sur la base d'un logiciel. Ceph fournit des interfaces pour stocker simultanément des blocs, des objets et des fichiers pour un seul cluster de stockage.
Ceph a une architecture très complexe avec RADOS, librados, RADOSGW, RDB, algorithme CRUSH et divers composants (moniteurs, OSD, MDS). Nous n'entrerons pas dans les détails de l'architecture, il suffit de comprendre que Ceph est un cluster de stockage distribué qui simplifie l'évolutivité, élimine un point de défaillance unique sans sacrifier les performances et fournit un stockage unique avec accès aux objets, blocs et fichiers.
Naturellement, Ceph est adapté au cloud. Vous pouvez déployer un cluster Ceph de différentes manières, par exemple, en utilisant Ansible ou dans un cluster Kubernetes via CSI et PVC.
Architecture de Ceph
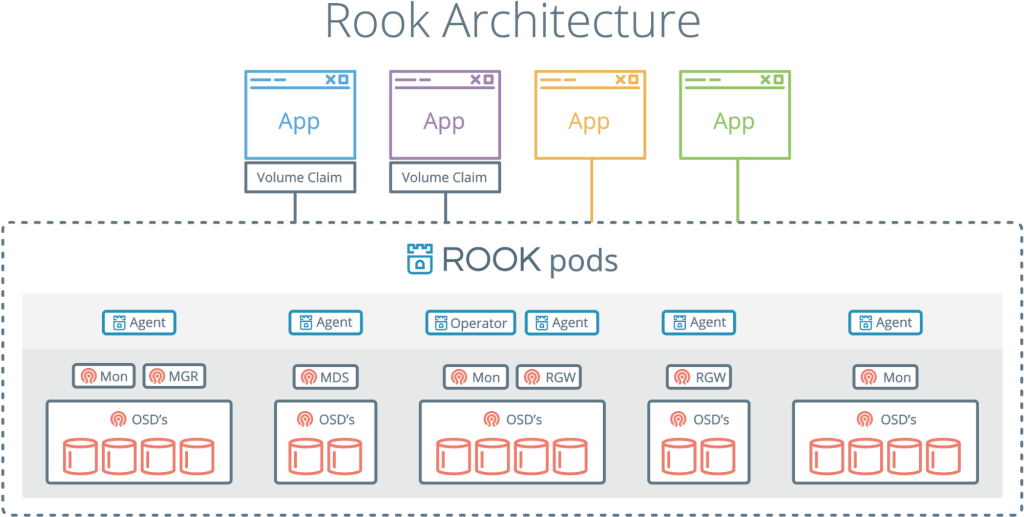
Rook est un autre projet intéressant et populaire. Il combine Kubernetes avec son informatique et Ceph avec ses référentiels en un seul cluster.
Rook est un orchestrateur de stockage cloud qui complète Kubernetes. Ils emballent Ceph dans des conteneurs avec lui et utilisent la logique de gestion de cluster pour un fonctionnement fiable de Ceph dans Kubernetes. Rook automatise le déploiement, l'amorçage, le réglage, la mise à l'échelle, le rééquilibrage - en général, tout ce que l'administrateur du cluster fait.
Avec Rook, un cluster Ceph peut être déployé à partir de yaml, comme Kubernetes. Dans ce fichier, l'administrateur décrit ce dont il a besoin dans le cluster. Rook lance un cluster et commence à surveiller activement. C'est quelque chose comme un opérateur ou un contrôleur - cela garantit que toutes les exigences de yaml sont remplies. Rook fonctionne avec des cycles de synchronisation - il voit l'état et prend des mesures s'il y a des écarts.
Il n'a pas son état permanent et n'a pas besoin d'être contrôlé. C'est dans l'esprit de Kubernetes.
Rook, combinant Ceph et Kubernetes, est l'une des solutions de stockage cloud les plus populaires: 4000 étoiles sur Github, 16,3 millions de téléchargements et plus d'une centaine de contributeurs.
Le projet Rook a déjà été accepté à la CNCF et s'est récemment retrouvé dans un incubateur .
Bassam Tabara vous en dira plus sur Rook dans notre épisode du référentiel Kubernetes .
Si l'application a un problème, vous devez connaître les exigences et créer un système ou prendre les outils nécessaires. Cela s'applique également au stockage dans le cloud. Et bien que le problème ne soit pas simple, les outils et les approches ont échoué. La technologie cloud continue d'évoluer et de nouvelles solutions nous attendront sûrement.