Récemment, par nécessité, j'ai parcouru toutes les offres d'emploi pour les développeurs Go, et la moitié d'entre eux (au moins) mentionnent la plate-forme de traitement des messages
Apache Kafka et la base de données
Redis NoSQL. Eh bien, tout le monde, bien sûr, veut que le candidat connaisse Docker et d'autres comme lui. Toutes ces exigences pour nous, qui ont vu les opinions des ingénieurs système, semblent en quelque sorte mesquines ou quelque chose. Eh bien, en fait, en quoi une ligne diffère-t-elle d'une autre? La situation avec les bases de données NoSQL est, bien sûr, plus diversifiée, mais elles semblent toujours plus simples que n'importe quel MS SQL Server. Tout cela, bien sûr, est mon effet personnel, l'effet
Dunning-Kruger , mentionné à plusieurs reprises sur le Habré.
Donc, comme tous les employeurs l'exigent, il est nécessaire d'étudier ces technologies. Mais commencer par lire toute la documentation du début à la fin n'est pas très intéressant. À mon avis, il est plus productif de lire l'introduction, de créer un prototype fonctionnel, de corriger les erreurs, de rencontrer des problèmes, de les résoudre. Et après tout cela, avec compréhension, lisez la documentation, ou même un livre séparé.

Ceux qui sont intéressés par un court laps de temps pour se familiariser avec les capacités de base de ces produits, lisez la suite.
Le programme de formation tiendra compte des chiffres. Il se composera d'un générateur de grands nombres, d'un processeur de nombres, d'une file d'attente, d'un stockage de colonnes et d'un serveur Web.
Pendant le développement, les modèles de conception suivants seront appliqués:
L'architecture du système ressemblera à ceci:
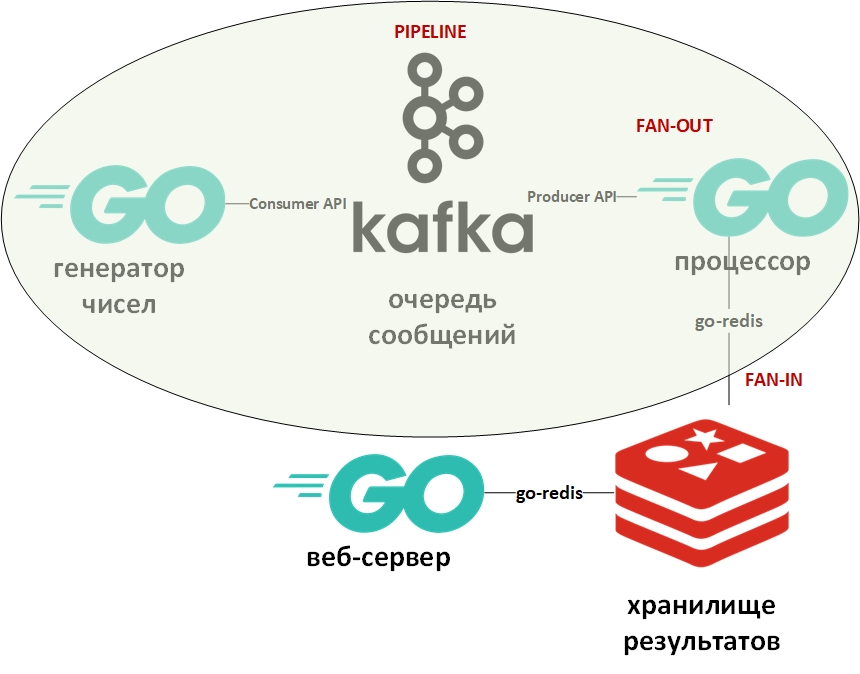
Dans l'image, l'ovale indique le modèle de conception du convoyeur. Je m'y attarderai plus en détail.
Le modèle «convoyeur» suppose que les informations se présentent sous la forme d'un flux et sont traitées par étapes. Habituellement, il existe un générateur (source d'informations) et un ou plusieurs processeurs (processeurs d'informations). Dans ce cas, le générateur sera un programme sur Go qui met en file d'attente de grands nombres aléatoires. Et le processeur (le seul) sera un programme qui prend les données de la file d'attente et effectue la factorisation. Sur Go pur, ce modèle est assez facile à implémenter en utilisant des canaux (chan). Ci-dessus, il y a un lien vers mon github avec un exemple. Ici, la file d'attente de messages jouera le rôle de canaux.
Fan-In - Les modèles Fan-Out sont généralement utilisés ensemble et, tels qu'appliqués à Go, signifient la parallélisation des calculs à l'aide de goroutines, suivie d'un résumé des résultats et de leur transfert, par exemple, dans le pipeline. Un lien vers un exemple est également donné ci-dessus. Encore une fois, le canal a été remplacé par la file d'attente, les goroutins sont restés en place.
Maintenant, quelques mots sur Apache Kafka. Kafka est un système de gestion des messages doté d'excellents outils de clustering, utilise un journal des transactions (exactement comme dans un SGBDR) pour stocker les messages et prend en charge à la fois le modèle de file d'attente et le modèle éditeur / abonné. Ce dernier est atteint grâce à des groupes de destinataires du message. Chaque message ne reçoit qu'un seul membre du groupe (traitement parallèle), mais le message sera remis une fois à chaque groupe. Il peut y avoir de nombreux groupes de ce type, ainsi que des destinataires au sein de chaque groupe.
Pour travailler avec Kafka, j'utiliserai le package «github.com/segmentio/kafka-go».
Redis, d'autre part, est une base de données de colonnes de valeurs-clés en mémoire qui prend en charge la possibilité de stocker de manière permanente des données. Le type de données principal pour les clés et les valeurs est les chaînes, mais il en existe d'autres. Redis est considérée comme l'une des bases de données les plus rapides (ou les plus) de sa catégorie. Il est bon de stocker toutes sortes de statistiques, de métriques, de flux de messages, etc.
Pour travailler avec Redis, j'utiliserai le package «github.com/go-redis/redis».
Étant donné que cet article est un démarrage rapide, nous déploierons les deux systèmes à l'aide de Docker à l'aide d'images prêtes à l'emploi de DockerHub. J'utilise docker-compose sur Windows 10 en mode conteneur sur une machine virtuelle Linux (créée automatiquement par la machine virtuelle Docker) avec ce fichier docker-compose.yml comme ceci:
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1" KAFKA_DELETE_TOPIC_ENABLE: "true" volumes: - /var/run/docker.sock:/var/run/docker.sock redis: image: redis ports: - "6379:6379"
Enregistrez ce fichier, allez dans le répertoire avec lui et exécutez:
docker-compose up -d
Trois conteneurs doivent télécharger et démarrer: Kafka (file d'attente), Zookeeper (serveur de configuration pour Kafka) et (Redis).
Vous pouvez vérifier que les conteneurs fonctionnent à l'aide de la commande:
docker-compose ps
Cela devrait être quelque chose comme:
Name State Ports -------------------------------------------------------------------------------------- docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
Selon le fichier yml, trois files d'attente devraient être créées automatiquement, vous pouvez les voir avec la commande:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181
Il devrait y avoir des files d'attente (sujets - sujets en termes de Kafka) générées, résolues et non résolues.
Le générateur de données met les numéros en file d'attente à l'infini avec un retard aléatoire. Son code est extrêmement simple. Vous pouvez vérifier la présence de messages dans la file d'attente générée à l'aide de la commande:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning
Ensuite, le
processeur - ici, vous devez faire attention à la parallélisation du traitement des valeurs de la file d'attente dans le bloc de code suivant:
var wg sync.WaitGroup c := 0
Étant donné que la lecture de la file d'attente de messages bloque le programme, j'ai créé un objet context.Context avec un délai d'expiration de 15 secondes. Ce délai mettra fin au programme si la file d'attente est vide pendant une longue période.
De plus, pour chaque gorutine qui factorise le nombre, la durée de fonctionnement maximale est également définie. Je voulais que les chiffres qui pouvaient prendre en compte soient écrits dans une seule base de données. Et les chiffres qui n'ont pas pu être factorisés dans le temps imparti ont été transférés vers une autre base de données.
Pour déterminer l'heure approximative, le repère a été utilisé:
func BenchmarkFactorize(b *testing.B) { ch := make(chan []int) var factors []int for i := 1; i < bN; i++ { num := 2345678901234 go factorize(num, ch) factors = <-ch b.Logf("\n%d %+v\n\n", num, factors) } }
Les repères dans Go sont des variétés de tests et sont placés dans un fichier contenant des tests. Sur la base de cette mesure, le nombre maximum pour le générateur de nombres aléatoires a été sélectionné. Sur mon ordinateur, une partie des chiffres a eu le temps de prendre en compte, et une partie - pas.
Les nombres qui pouvaient être décomposés étaient écrits dans le DB n ° 0, les nombres non décomposés dans le DB n ° 1.
Ici, je dois dire qu'à Redis il n'y a pas de tables et de tables au sens classique. Par défaut, le SGBD contient 16 bases de données disponibles pour le programmeur. Ces bases diffèrent par leur nombre - de 0 à 15.
La limite de temps pour les goroutines dans le processeur a été fournie en utilisant le contexte et l'instruction select:
C'est une autre astuce de développement typique sur Go. Sa signification est que l'instruction select parcourt les canaux et exécute le code correspondant au premier canal actif. Dans ce cas, soit goroutine affichera le résultat sur son canal, soit le canal contextuel avec un timeout se fermera. Au lieu du contexte, vous pouvez utiliser un canal arbitraire qui agira en tant que gestionnaire et fournira l'arrêt forcé des goroutines.
Les sous-programmes pour écrire dans la base de données exécutent la commande pour sélectionner la base de données souhaitée (0 ou 1) et écrire des paires de la forme (nombre - facteurs) pour les nombres analysés ou (nombre - nombre) pour les nombres non décomposés.
func storeSolved(item data) (err error) {
La dernière partie sera le
serveur Web , qui affichera une liste de nombres décomposés et non décomposés sous forme json. Il aura deux points d'extrémité:
http.HandleFunc("/solved", solvedHandler) http.HandleFunc("/unsolved", unsolvedHandler)
Le gestionnaire de requêtes http qui reçoit des données de Redis et les renvoie sous json ressemble à ceci:
func solvedHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization")
Le résultat de la demande à:
localhost / résolu [{ "Key": "1604388558816", "Val": "[1,2,3,227]" }, { "Key": "545232916387", "Val": "[1,545232916387]" }, { "Key": "1786301239076", "Val": "[1,2]" }, { "Key": "698495534061", "Val": "[1,3,13,641,165331]" }]
Vous pouvez maintenant vous plonger dans la documentation et la littérature spécialisée. J'espère que l'article vous a été utile.
Je demande aux experts de ne pas être trop paresseux et de signaler mes erreurs.