«En mode trace, le programmeur voit la séquence d'exécution des commandes et les valeurs des variables à cette étape de l'exécution du programme, ce qui facilite la détection des erreurs», nous dit Wikipedia. En tant que fans de Linux, nous nous posons régulièrement la question de savoir quels outils spécifiques sont les meilleurs pour l'implémenter. Et nous voulons partager la traduction d'un article du programmeur Hongley Lai qui recommande bpftrace. Pour l'avenir, je dirai que l'article se termine succinctement: "bpftrace est le futur". Alors pourquoi a-t-il tant impressionné le collègue de Lai? Une réponse détaillée sous la coupe.
Il existe deux principaux outils de trace sous Linux:
strace vous permet de voir quels appels système sont effectués;
ltrace vous permet de voir quelles bibliothèques dynamiques sont appelées.
Malgré leur utilité, ces outils sont limités. Et si vous avez besoin de savoir ce qui se passe dans un appel système ou bibliothèque? Et si vous devez non seulement compiler une liste d'appels, mais aussi, par exemple, collecter des statistiques sur certains comportements? Et si vous avez besoin de suivre plusieurs processus et de comparer les données de plusieurs sources?
En 2019, nous avons enfin obtenu une réponse décente à ces questions sur Linux:
bpftrace basé sur la technologie
eBPF . Bpftrace vous permet d'écrire de petits programmes qui s'exécutent chaque fois qu'un événement se produit.
Dans cet article, je décrirai comment installer bpftrace et enseigner son application de base. Je vais également donner un aperçu de ce à quoi ressemble l'écosystème de trace (par exemple, "qu'est-ce que l'eBPF?") Et comment il a évolué pour devenir ce que nous avons aujourd'hui.
Qu'est-ce qu'une trace?
Comme mentionné précédemment, bpftrace vous permet d'écrire de petits programmes qui s'exécutent chaque fois qu'un événement se produit.
Qu'est-ce qu'un événement? Il peut s'agir d'un appel système, d'un appel de fonction ou même de quelque chose qui se passe dans de telles requêtes. Il peut également s'agir d'un temporisateur ou d'un événement matériel, par exemple, "50 ms se sont écoulées depuis le dernier des mêmes événements", "une défaillance de page s'est produite", "un changement de contexte s'est produit" ou "un cashe-miss processor s'est produit".
Que peut-on faire en réponse à un événement? Vous pouvez promettre quelque chose, collecter des statistiques et exécuter des commandes shell arbitraires. Vous aurez accès à diverses informations contextuelles, telles que le PID actuel, la trace de la pile, l'heure, les arguments d'appel, les valeurs de retour, etc.
Quand l'utiliser? Dans beaucoup. Vous pouvez découvrir pourquoi l'application est lente en compilant une liste des appels les plus lents. Vous pouvez déterminer s'il y a des fuites de mémoire dans l'application et, le cas échéant, où. Je l'utilise pour comprendre pourquoi Ruby utilise autant de mémoire.
Le gros avantage de bpftrace est que vous n'avez pas besoin de recompiler l'application. Il n'est pas nécessaire d'écrire manuellement des appels d'impression ou tout autre code de débogage dans le code source de l'application à l'étude. Il n'est même pas nécessaire de redémarrer les applications. Et tout cela avec des frais généraux très faibles. Cela rend bpftrace particulièrement utile pour le débogage de systèmes directement sur le prod ou dans une autre situation où il y a des problèmes de recompilation.
DTrace: père de trace
Pendant longtemps, le meilleur outil de traçage était
DTrace , un framework de traçage dynamique complet développé à l'origine par Sun Microsystems (les créateurs de Java). Comme bpftrace, DTrace vous permet d'écrire de petits programmes qui s'exécutent en réponse à des événements. En fait, bon nombre des éléments clés de l'écosystème sont largement développés par
Brendan Gregg , un expert DTrace renommé qui travaille actuellement chez Netflix. Ce qui explique les similitudes entre DTrace et bpftrace.
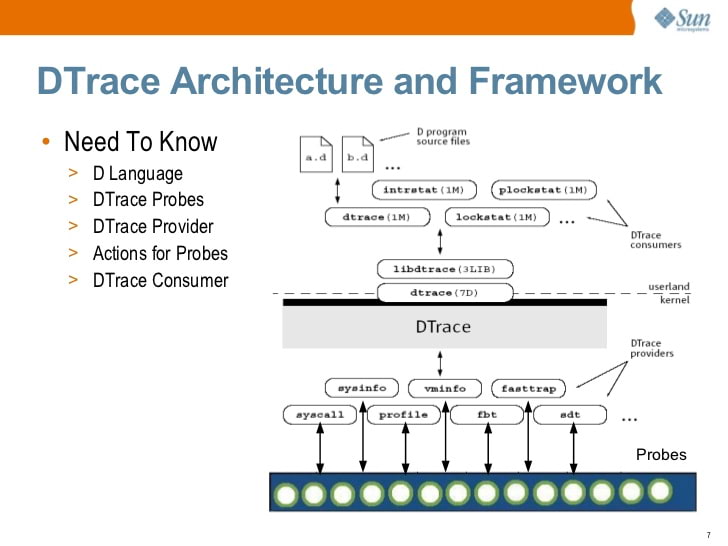 Introduction à Solaris DTrace (2009) par S. Tripathi, Sun Microsystems
Introduction à Solaris DTrace (2009) par S. Tripathi, Sun MicrosystemsÀ un moment donné, Sun a ouvert la source de DTrace. Aujourd'hui, DTrace est disponible sur Solaris, FreeBSD et macOS (bien que la version macOS soit généralement inutilisable car la protection de l'intégrité du système, SIP, a enfreint de nombreux principes sur lesquels DTrace s'exécute).
Oui, vous l'avez bien remarqué ... Linux n'est pas dans cette liste. Ce n'est pas un problème d'ingénierie, c'est un problème de licence. DTrace a été ouvert sous le CDDL au lieu de la GPL.
Le port Linux DTrace est disponible depuis 2011, mais il n'a jamais été pris en charge par les principaux développeurs Linux. Début 2018,
Oracle a rouvert DTrace sous GPL , mais il était déjà trop tard.
Écosystème de traçage Linux
Le traçage est sans aucun doute très utile, et la communauté Linux a cherché à développer ses propres solutions à ce sujet. Mais, contrairement à Solaris, Linux n'est pas réglementé par un fournisseur spécifique, et il n'y a donc pas eu d'effort délibéré pour développer un remplacement entièrement fonctionnel de DTrace. L'écosystème de trace Linux a évolué lentement et naturellement, résolvant les problèmes à mesure qu'ils surviennent. Et ce n'est que récemment que cet écosystème s'est suffisamment développé pour rivaliser sérieusement avec DTrace.
En raison de la croissance naturelle, cet écosystème peut sembler un peu chaotique, composé de nombreuses composantes différentes. Heureusement, Julia Evans a
écrit une revue de cet écosystème (attention, date de publication - 2017, avant l'avènement de bpftrace).
 Écosystème de traces Linux décrit par Julia Evans
Écosystème de traces Linux décrit par Julia EvansTous les éléments ne sont pas également importants. Permettez-moi de résumer brièvement les éléments que je considère les plus importants.
Sources d'événementsLes données d'événement peuvent provenir du noyau ou de l'espace utilisateur (applications et bibliothèques). Certains d'entre eux sont disponibles automatiquement, sans efforts de développement supplémentaires, tandis que d'autres nécessitent une annonce manuelle.
 Vue d'ensemble des sources les plus importantes d'événements tracés sous Linux
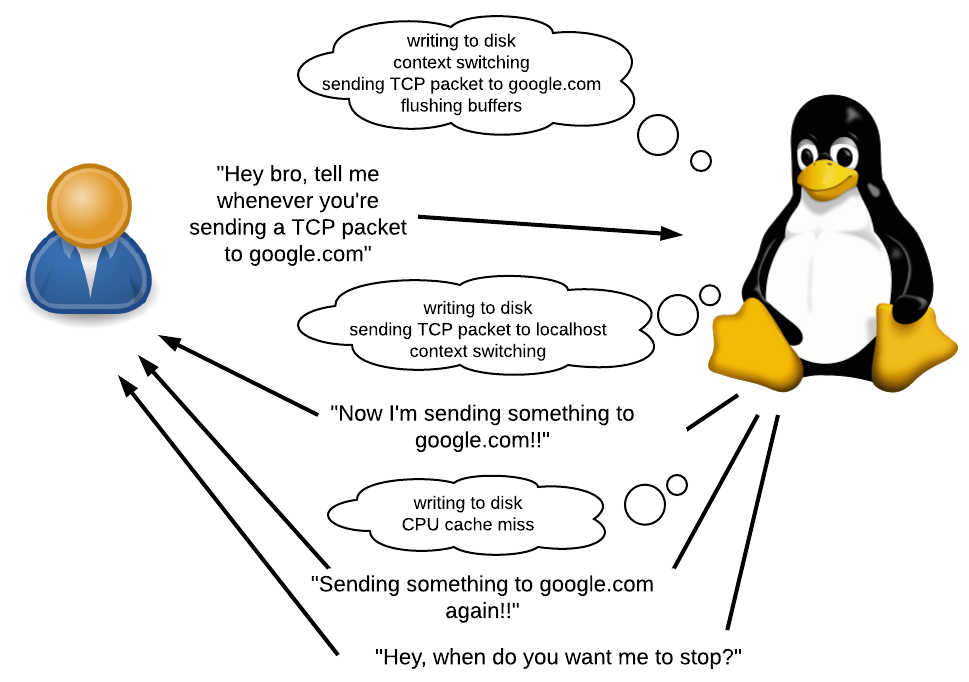
Vue d'ensemble des sources les plus importantes d'événements tracés sous LinuxDu côté du noyau, il y a des kprobes (
de «kernel probes», «kernel sensor», environ Per. ) - un mécanisme qui vous permet de tracer tout appel de fonction à l'intérieur du noyau. Avec lui, vous pouvez tracer non seulement les appels système eux-mêmes, mais aussi ce qui se passe à l'intérieur d'eux (car les points d'entrée des appels système appellent d'autres fonctions internes). Vous pouvez également utiliser kprobes pour tracer les événements du noyau qui ne sont pas des appels système, par exemple, "des données tamponnées sont écrites sur le disque", "un paquet TCP est envoyé sur le réseau" ou "un changement de contexte est en cours".
Les points de trace du noyau permettent de suivre les événements non standard définis par les développeurs du noyau. Ces événements ne sont pas au niveau des appels de fonction. Pour créer de tels points, les développeurs du noyau placent manuellement la macro TRACE_EVENT dans le code du noyau.
Les deux sources ont des avantages et des inconvénients. Kprobes fonctionne "automatiquement" car ne nécessite pas que les développeurs du noyau codent manuellement le code. Mais les événements kprobe peuvent changer arbitrairement d'une version du noyau à une autre, car les fonctions changent constamment - elles sont ajoutées, supprimées, renommées.
Les points de trace du noyau sont généralement plus stables dans le temps et peuvent fournir des informations contextuelles utiles qui pourraient ne pas être disponibles si kprobes est utilisé. À l'aide de kprobes, vous pouvez accéder aux arguments d'appel de fonction. Mais à l'aide de points de trace, vous pouvez obtenir toutes les informations que le développeur du noyau décide de décrire manuellement.
Dans l'espace utilisateur, il existe un analogue de kprobes - uprobes. Il est conçu pour tracer les appels de fonction dans l'espace utilisateur.
Les capteurs USDT («Traces de l'espace utilisateur définis statiquement») sont un analogue des points de trace du noyau dans l'espace utilisateur. Les développeurs d'applications doivent ajouter manuellement des capteurs USDT à leur code.
Fait intéressant: DTrace fournit depuis longtemps l'API C pour définir son propre analogue de capteurs USDT (en utilisant la macro DTRACE_PROBE). Les développeurs de l'écosystème Trace sur Linux ont décidé de laisser le code source compatible avec cette API, donc toutes les macros DTRACE_PROBE sont automatiquement converties en capteurs USDT!
Par conséquent, en théorie, strace peut être implémenté à l'aide de kprobes et ltrace peut être implémenté à l'aide d'uprobes. Je ne sais pas si cela est déjà pratiqué ou non.
InterfacesLes interfaces sont des applications qui permettent aux utilisateurs d'utiliser facilement des sources d'événements.
Voyons comment fonctionnent les sources d'événements. Le workflow est le suivant:
- Le noyau représente un mécanisme - généralement un fichier / proc ou / sys ouvert en écriture - qui enregistre à la fois l'intention de suivre l'événement et ce qui doit suivre l'événement.
- Après l'enregistrement, le noyau localise en mémoire le noyau / la fonction dans l'espace utilisateur / les points de trace / les capteurs USDT et modifie leur code pour que quelque chose d'autre se produise.
- Le résultat de cette «autre chose» peut être collecté ultérieurement en utilisant un mécanisme.
Je ne voudrais pas faire tout ça manuellement! Les interfaces viennent donc à la rescousse: elles font tout cela pour vous.
Il existe des interfaces pour tous les goûts et toutes les couleurs. Dans le domaine des
interfaces basées sur
eBPF, il existe des
interfaces de bas niveau qui nécessitent une compréhension approfondie de la façon d'interagir avec les sources d'événements et du fonctionnement du bytecode eBPF. Et ils sont de haut niveau et faciles à utiliser, bien que durant leur existence ils n'aient pas fait preuve d'une grande flexibilité.
C'est pourquoi bpftrace - la dernière interface - est mon préféré. Il est convivial et flexible comme DTrace. Mais il est assez récent et nécessite un polissage.
eBPF
eBPF est la
nouvelle étoile de trace Linux sur laquelle bpftrace est basé. Lorsque vous tracez un événement, vous voulez que quelque chose se passe dans le noyau. Quelle manière flexible de déterminer ce qu'est ce «quelque chose»? Bien sûr, en utilisant un langage de programmation (ou en utilisant un code machine).
eBPF (version améliorée du Berkeley Packet Filter). Il s'agit d'une machine virtuelle hautes performances qui s'exécute dans le noyau et présente les propriétés / limitations suivantes:
- Toutes les interactions dans l'espace utilisateur se produisent via des «cartes» eBPF, qui sont un stockage de données de valeur clé.
- Il n'y a pas de cycles pour que chaque programme eBPF se termine à un moment précis.
- Attendez, nous avons dit Batch Filter? Vous avez raison: ils ont été initialement conçus pour filtrer les paquets réseau. C'est une tâche similaire: lors du transfert de paquets (l'occurrence d'un événement), vous devez effectuer une action administrative (accepter, supprimer, journaliser ou rediriger un paquet, etc.) Une machine virtuelle a été inventée pour accélérer ces actions (avec capacité JIT) compilation). Une version «étendue» est envisagée du fait que, par rapport à la version d'origine du Berkeley Packet Filter, eBPF peut être utilisé en dehors du contexte réseau.
Voilà. Avec bpftrace, vous pouvez déterminer les événements à suivre et ce qui doit se produire en réponse. Bpftrace compile votre programme bpftrace de haut niveau en bytecode eBPF, suit les événements et charge le bytecode dans le noyau.
Jours sombres avant eBPF
Avant eBPF, les options de solution étaient, pour le moins, maladroites.
SystemTap est un peu le prédécesseur «le plus sérieux» de bpftrace dans la famille Linux. Les scripts SystemTap sont traduits en langage C et chargés dans le noyau en tant que modules. Le module de noyau résultant est alors chargé.
Cette approche était très fragile et mal prise en charge en dehors de Red Hat Enterprise Linux. Pour moi, cela n'a jamais bien fonctionné sur Ubuntu, ce qui avait tendance à casser SystemTap à chaque mise à jour du noyau en raison d'un changement dans la structure des données du noyau. On dit également que dans les premiers jours de son existence, SystemTap a
facilement conduit à la panique du noyau .
Installation de Bpftrace
Il est temps de retrousser vos manches! Dans ce guide, nous verrons comment installer bpftrace sur Ubuntu 18.04. Les versions plus récentes de la distribution ne sont pas souhaitables, car lors de l'installation, nous aurons besoin de packages qui ne sont pas encore compilés pour eux.
Installation de dépendanceTout d'abord, installez Clang 5.0, lbclang 5.0 et LLVM 5.0, y compris tous les fichiers d'en-tête. Nous utiliserons les packages fournis par llvm.org, car ceux des référentiels Ubuntu sont
problématiques .
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - cat <<EOF | sudo tee -a /etc/apt/sources.list deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main EOF sudo apt update sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-dev
Suivant:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-dev
Et enfin, installez libbfcc-dev depuis l'amont, pas depuis le référentiel Ubuntu. Il n'y a
pas de fichiers d' en-
tête dans le package qui se trouve dans Ubuntu. Et ce problème n'a pas été résolu même à 18h10.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt update sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)
Installation principale de BpftraceIl est temps d'installer bpftrace lui-même depuis la source! Clonons-le, assemblons-le et installons-le dans / usr / local:
git clone https://github.com/iovisor/bpftrace cd bpftrace mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=DEBUG .. make -j4 sudo make install
Et vous avez terminé! L'exécutable sera installé dans / usr / local / bin / bpftrace. Vous pouvez modifier la destination à l'aide de l'argument cmake, qui ressemble à ceci par défaut:
DCMAKE_INSTALL_PREFIX=/usr/local.
Exemples d'une ligneExécutons quelques lignes simples bpftrace pour comprendre nos capacités. Je les ai extraites du
guide de
Brendan Gregg , qui contient une description détaillée de chacun d'eux.
# 1. Affichez une liste de capteurs
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
# 2. Salutations
bpftrace -e 'BEGIN { printf("hello world\n"); }'
# 3. Ouverture d'un fichier
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
# 4. Le nombre d'appels système par processus
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 5. Répartition des appels read () par nombre d'octets
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'
# 6. Traçage dynamique du contenu read ()
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
# 7. Temps passé sur les appels read ()
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
# 8. Comptage des événements au niveau du processus
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'
# 9. Profilage des piles de travail du noyau
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'
# 10. Planificateur de traces
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'
# 11. E / S de blocage de trace
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'
Consultez le site Web de Brendan Gregg pour savoir
quel type de sortie les équipes ci-dessus peuvent générer .
Syntaxe de script et exemple de synchronisation d'E / SLa chaîne passée par le commutateur '-e' est le contenu du script bpftrace. La syntaxe dans ce cas est, conditionnellement, un ensemble de constructions:
<event source> /<optional filter>/ { <program body> }
Examinons le septième exemple, sur le timing des opérations de lecture du système de fichiers:
kprobe:vfs_read { @start[tid] = nsecs; } <- 1 -><-- 2 -> <---------- 3 --------->
Nous
suivons l'événement à partir du mécanisme
kprobe , c'est-à-dire que nous
suivons le début de la fonction du noyau.
La fonction du noyau pour le traçage est
vfs_read , cette fonction est appelée lorsque le noyau effectue une opération de lecture à partir du système de fichiers (VFS de "Virtual FileSystem", abstraction du système de fichiers à l'intérieur du noyau).
Lorsque
vfs_read commence à
s'exécuter (c'est-à-dire avant que la fonction n'ait effectué un travail utile), le programme bpftrace démarre. Il enregistre l'horodatage actuel (en nanosecondes) dans un tableau associatif global appelé
st art . La clé est
tid , une référence à l'ID de thread actuel.
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); } <-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->
1. Nous
suivons l'événement à partir du mécanisme
kretprobe , qui est similaire à
kprobe , sauf qu'il est appelé lorsque la fonction renvoie le résultat de son exécution.
2. La fonction du noyau pour le traçage est
vfs_read .
3. Il s'agit d'un filtre facultatif. Il vérifie si l'heure de début a déjà été enregistrée. Sans ce filtre, le programme peut être démarré pendant la lecture et n'attraper que la fin, ce qui donne une heure
estimée de
démarrage nsecs - 0 , au lieu de
nsecs - .
4. Le corps du programme.
nsecs - st art [tid] calcule le temps écoulé depuis le début de la fonction vfs_read.
@ns [comm] = hist (...) ajoute les données spécifiées à l'histogramme bidimensionnel stocké dans
@ns . La clé de
communication fait référence au nom de l'application en cours. Nous aurons donc un histogramme commande par commande.
delete (...) supprime l'heure de début du tableau associatif, car nous n'en avons plus besoin.
Telle est la conclusion finale. Veuillez noter que tous les histogrammes sont affichés automatiquement. L'utilisation explicite de la commande d'impression d'histogramme n'est pas requise.
@ns n'est pas une variable spéciale, donc l'histogramme n'est pas affiché à cause de cela.
@ns[snmp-pass]: [0, 1] 0 | | [2, 4) 0 | | [4, 8) 0 | | [8, 16) 0 | | [16, 32) 0 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 0 | | [256, 512) 27 |@@@@@@@@@ | [512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1k, 2k) 22 |@@@@@@@ | [2k, 4k) 1 | | [4k, 8k) 10 |@@@ | [8k, 16k) 1 | | [16k, 32k) 3 |@ | [32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64k, 128k) 7 |@@ | [128k, 256k) 28 |@@@@@@@@@@ | [256k, 512k) 2 | | [512k, 1M) 3 |@ | [1M, 2M) 1 | |
Exemple de capteur USDTPrenons ce code C et enregistrons-le dans le fichier
tracetest.c :
#include <sys/sdt.h> #include <sys/time.h> #include <unistd.h> #include <stdio.h> static long myclock() { struct timeval tv; gettimeofday(&tv, NULL); DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec); return tv.tv_sec; } int main(int argc, char **argv) { while (1) { myclock(); sleep(1); } return 0; }
Ce programme s'exécute sans fin en appelant
myclock () une fois par seconde.
myclock () interroge l'heure actuelle et renvoie le nombre de secondes depuis le début de l'ère.
L'appel à
DTRACE_PROBE1 définit ici un point de trace USDT statique.
- La macro DTRACE_PROBE1 est tirée de sys / sdt.h. La macro officielle USDT, qui fait de même, s'appelle STAP_PROBE1 (STAP de SystemTap, qui était le premier mécanisme Linux pris en charge par USDT). Mais comme USDT est compatible avec les capteurs d'espace utilisateur DTrace, DTRACE_PROBE1 n'est qu'une référence à STAP_PROBE1 .
- Le premier paramètre est le nom du fournisseur. Je crois que c'est un vestige de DTrace, car bpftrace ne semble pas faire quoi que ce soit d'utile avec. Cependant, il y a une nuance ( que j'ai découverte lors du débogage du problème à l'application 328 ): le nom du fournisseur doit être identique au nom de fichier binaire de l'application, sinon bpftrace ne pourra pas trouver le point de trace.
- Le deuxième paramètre est le nom du point de trace.
- Tout paramètre supplémentaire est le contexte fourni par les développeurs. Le nombre 1 dans DTRACE_PROBE1 signifie que nous voulons passer un paramètre supplémentaire.
Assurons-nous que sys / sdt.h est disponible pour nous, et montons le programme:
sudo apt install systemtap-sdt-dev gcc tracetest.c -o tracetest -Wall -g
Nous demandons à bpftrace de sortir le PID et "time is [number]" chaque fois que
testprobe est atteint:
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'
Bpftrace continue de fonctionner pendant que nous appuyons sur Ctrl-C. Par conséquent, ouvrez un nouveau terminal et exécutez
- y
tracetest :
# Dans le nouveau terminal
./tracetest
Revenez au premier terminal avec bpftrace, là vous devriez voir quelque chose comme:
Attaching 1 probe... 30909: time is 1549023215 30909: time is 1549023216 30909: time is 1549023217 ... ^C
Exemple d'allocation de mémoire à l'aide de glibc ptmallocJ'utilise bpftrace pour comprendre pourquoi Ruby utilise autant de mémoire. Et dans le cadre de mes recherches, j'ai besoin de comprendre comment l'allocateur de mémoire de glibc utilise
les régions de mémoire .
Afin d'optimiser les performances multicœurs, l'allocateur de mémoire glibc alloue plusieurs «zones» à partir du système d'exploitation. Lorsque l'application demande l'allocation de mémoire, l'allocateur sélectionne une zone qui n'est pas utilisée et marque une partie de cette zone comme «utilisée». Étant donné que les threads utilisent différentes zones, le nombre de verrous est réduit, ce qui améliore les performances multithread.
Mais cette approche génère beaucoup de déchets, et il semble qu'une telle consommation de mémoire élevée dans Ruby soit précisément à cause de cela. Afin de mieux comprendre la nature de ces déchets, je me suis demandé: qu'est-ce que cela signifie de «choisir une zone qui n'est pas utilisée»? Cela peut signifier l'un des éléments suivants:
- Chaque fois que malloc () est appelé, l'allocateur parcourt toutes les zones et trouve celle qui n'est pas actuellement verrouillée. Et seulement s'ils sont tous bloqués, il essaiera d'en créer un nouveau.
- La première fois que malloc () est appelé sur un thread spécifique (ou lorsque le thread démarre), l'allocateur sélectionne celui qui n'est pas actuellement bloqué. Et s'ils sont tous bloqués, il essaiera d'en créer un nouveau.
- La première fois que malloc () est appelé sur un thread spécifique (ou lorsque le thread démarre), l'allocateur essaiera de créer une nouvelle région, qu'il y ait ou non des régions déverrouillées. Seulement si une nouvelle zone ne peut pas être créée (par exemple, lorsque la limite est épuisée), elle réutilisera la zone existante.
- Il y a probablement plus d'options que je n'ai pas envisagées.
Il n'y a pas de réponse spécifique dans la documentation, laquelle de ces fonctionnalités vous permet de sélectionner une zone qui n'est pas utilisée. J'ai étudié le code source de la glibc, qui a suggéré que l'option 3 pourrait le faire. Mais je voulais vérifier expérimentalement que j'avais interprété le code source correctement, sans avoir besoin de déboguer le code dans la glibc.
Voici la fonction d'allocation de mémoire glibc qui crée une nouvelle zone. Mais vous ne pouvez l'appeler qu'après avoir vérifié la limite.
static mstate _int_new_arena(size_t size) { mstate arena; size = calculate_how_much_memory_to_ask_from_os(size); arena = do_some_stuff_to_allocate_memory_from_os(); LIBC_PROBE(memory_arena_new, 2, arena, size); do_more_stuff(); return arena; }
Puis-je utiliser des
uprobes pour tracer la fonction
_int_new_arena ? Malheureusement non. Pour une raison quelconque, ce symbole n'est pas disponible dans la glibc Ubuntu 18.04. Même après l'installation des symboles de débogage.
Heureusement, il existe un capteur USDT dans cette fonction.
LIBC_PROBE est un alias de macro pour
STAP_PROBE .
Le nom du fournisseur est libc.
Le nom du capteur est memory_arena_new.
Le nombre 2 signifie qu'il y a 2 arguments supplémentaires spécifiés par le développeur.
arena est l'adresse de la zone qui a été extraite du système d'exploitation, et la taille est sa taille.
Avant de pouvoir utiliser ce capteur, nous devons
contourner le problème 328 . Nous devons créer un lien symbolique avec glibc quelque part avec le nom
libc , car bpftrace s'attend à ce que le nom de la bibliothèque (qui serait autrement
libc-2.27.so ) soit identique au nom du fournisseur
(libc) .
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libc
Nous demandons maintenant à bpftrace de se connecter au capteur USD_ memory_arena_new, dont le nom du fournisseur est
libc :
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'
Dans un autre terminal, nous exécuterons Ruby, qui créera trois threads qui ne font rien et se terminent en une seconde. En raison du blocage global de l'interpréteur, Ruby
malloc () ne doit pas être appelé en parallèle par différents threads.
ruby -e '3.times { Thread.new { } }; sleep 1'
De retour au terminal avec bpftrace, nous verrons:
Attaching 1 probe... PID 431: created new arena at 0x7f40e8000020, size 576 PID 431: created new arena at 0x7f40e0000020, size 576 PID 431: created new arena at 0x7f40e4000020, size 576
Voici la réponse à notre question! Chaque fois que vous créez un nouveau fil dans Ruby, la glibc met en évidence un nouveau domaine indépendamment de la compétitivité.
Quels sont les points de trace disponibles? Que dois-je tracer?Vous pouvez répertorier tous les points de trace matériels, temporisateurs, kprobe et du noyau statique en exécutant la commande:
sudo bpftrace -l
Vous pouvez répertorier tous les points de trace de la sonde (caractères de fonction) d'une application ou d'une bibliothèque en procédant comme suit:
nm /path-to-binary
Vous pouvez répertorier tous les points de trace de l'application ou de la bibliothèque USDT en exécutant la commande suivante:
/usr/share/bcc/tools/tplist -l /path-to/binary
En ce qui concerne les points de trace à utiliser: cela ne ferait pas de mal de comprendre le code source de ce que vous allez tracer. Je vous recommande d'étudier le code source.
Astuce: un format structurel pour les points de trace dans le noyauVoici une astuce utile sur les points de trace du noyau. Vous pouvez vérifier quels champs d'argument sont disponibles en lisant le fichier / sys / kernel / debug / tracing / events!
Par exemple, supposons que vous souhaitiez tracer les appels à
madvise (..., MADV_DONTNEED) :
sudo bpftrace -l | grep madvise
- nous dira que nous pouvons utiliser tracepoint: syscalls: sys_enter_madvise.
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format
- nous fournira les informations suivantes:
name: sys_enter_madvise ID: 569 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:int __syscall_nr; offset:8; size:4; signed:1; field:unsigned long start; offset:16; size:8; signed:0; field:size_t len_in; offset:24; size:8; signed:0; field:int behavior; offset:32; size:8; signed:0; print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))
Signature Madvise selon le manuel:
(void * addr, size_t length, int advice) . Les trois derniers champs de cette structure correspondent à ces paramètres!
Quelle est la signification de MADV_DONTNEED? A en juger par grep MADV_DONTNEED / usr / include, cela équivaut à 4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */
Notre équipe bpftrace devient donc:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'
Conclusion
Bpftrace est merveilleux! Bpftrace est l'avenir!
Si vous voulez en savoir plus sur lui, je vous recommande de vous familiariser avec
son leadership , ainsi que le
premier post de 2019 sur le blog de Brendan Gregg.
Bon débogage!