En 1943, les neuropsychologues américains McCallock et Pitts ont développé un modèle informatique d'un réseau neuronal, et en 1958, le
premier réseau monocouche fonctionnel a reconnu certaines lettres. Maintenant, les réseaux de neurones ne sont tout simplement pas utilisés pour quoi: prédire le taux de change, diagnostiquer les maladies, les pilotes automatiques et créer des graphiques dans les jeux informatiques. À peu près le dernier et parlez.
Evgeni Tumanov travaille en tant qu'ingénieur Deep Learning chez
NVIDIA . Sur la base des résultats de son discours lors de la conférence HighLoad ++, nous avons préparé une histoire sur l'utilisation du Machine Learning et du Deep Learning dans les graphiques. L'apprentissage automatique ne s'arrête pas avec la PNL, la vision par ordinateur, les systèmes de recommandation et les tâches de recherche. Même si vous n'êtes pas très familier avec ce domaine, vous pouvez appliquer les meilleures pratiques de l'article dans votre domaine ou votre industrie.
L'histoire se composera de trois parties. Nous passerons en revue les tâches du graphique qui sont résolues à l'aide de l'apprentissage automatique, obtenons l'idée principale et décrivons le cas de l'application de cette idée dans une tâche spécifique, et spécifiquement dans le
rendu des nuages .
DL / ML supervisé en graphisme ou formation des enseignants en graphisme
Analysons deux groupes de tâches. Pour commencer, notez-les brièvement.
Moteur réel ou moteur de rendu :
- Création d'animations crédibles: locomotion, animation faciale.
- Images rendues en post-traitement: suréchantillonnage, anticrénelage.
- Slowmotion: interpolation d'images.
- Génération de matériaux.
Le deuxième groupe de tâches est désormais conventionnellement appelé "
algorithme lourd ". Nous incluons des tâches telles que le rendu d'objets complexes, tels que les nuages, et
des simulations physiques : eau, fumée.
Notre objectif est de comprendre la différence fondamentale entre les deux groupes. Examinons les tâches plus en détail.
Création d'animations crédibles: locomotion, animation faciale
Au cours des dernières années, de nombreux
articles sont apparus , où les chercheurs proposent de nouvelles façons de générer de belles animations. Utiliser le travail des artistes coûte cher, et les remplacer par un algorithme serait très bénéfique pour tout le monde. Il y a un an, chez NVIDIA, nous travaillions sur un projet dans lequel nous étions engagés dans l'animation faciale de personnages dans des jeux: synchroniser le visage du héros avec la piste audio de la parole. Nous avons essayé de «raviver» le visage pour que chaque point sur lui bouge, et surtout les lèvres, car c'est le moment le plus difficile de l'animation. Manuellement, un artiste pour le faire cher et pendant longtemps. Quelles sont les options pour résoudre ce problème et en faire un
ensemble de
données ?
La première option est d'
identifier les voyelles: la bouche s'ouvre sur les voyelles, la bouche se ferme sur les consonnes . Il s'agit d'un algorithme simple, mais trop simple. Dans les jeux, nous voulons plus de qualité. La deuxième option consiste à
amener les gens à lire différents textes et à écrire leurs visages, puis à comparer les lettres qu'ils prononcent avec les expressions faciales. C'est une bonne idée, et nous l'avons fait dans le cadre d'un
projet commun avec Remedy Entertainment. La seule différence est que dans le jeu, nous ne montrons pas une vidéo, mais un modèle 3D de points. Pour assembler un jeu de données, vous devez comprendre comment se déplacent des points spécifiques sur la face. Nous avons pris des acteurs, demandé de lire des textes avec différentes intonations, tourné sur de très bonnes caméras sous différents angles, après quoi nous avons restauré le modèle 3D des visages sur chaque image, et prédit la position des points sur le visage par le son.
Post-traitement des images de rendu: suréchantillonnage, anticrénelage
Prenons un cas d'un jeu spécifique: nous avons un moteur qui génère des images dans différentes résolutions. Nous voulons rendre l'image dans une résolution de 1000 × 500 pixels, et montrer au joueur 2000 × 1000 - ce sera plus joli. Comment assembler un jeu de données pour cette tâche?
Rendez d'abord l'image en haute résolution, puis réduisez la qualité, puis essayez de former le système pour convertir l'image de basse résolution en haute résolution.
Ralenti: interpolation d'images
Nous avons une vidéo, et nous voulons que le réseau ajoute des images au milieu - pour interpoler les images. L'idée est évidente: filmer une vraie vidéo avec un grand nombre d'images, en supprimer des intermédiaires et essayer de prédire ce qui a été supprimé par le réseau.
Génération de matériaux
Nous ne nous attarderons pas beaucoup sur la génération de matériaux. Son essence est que nous prenons, par exemple, un morceau de bois sous plusieurs angles d'éclairage, et interpolons la vue sous d'autres angles.
Nous avons examiné le premier groupe de problèmes. Le second est fondamentalement différent. Nous parlerons du rendu d'objets complexes, tels que les nuages, plus tard, mais nous allons maintenant traiter des simulations physiques.
Simulations physiques de l'eau et de la fumée
Imaginez une piscine dans laquelle se trouvent des objets solides en mouvement. Nous voulons prédire le mouvement des particules fluides. Il y a des particules dans la piscine au temps
t , et au temps
t + Δt nous voulons obtenir leur position. Pour chaque particule, nous appelons un réseau neuronal et obtenons une réponse où il se trouvera sur la trame suivante.
Pour résoudre le problème,
nous utilisons
l' équation de Navier-Stokes , qui décrit le mouvement d'un fluide. Pour une simulation plausible et physiquement correcte de l'eau, nous devrons résoudre l'équation ou l'approximation de celle-ci. Cela peut être fait de manière informatique, dont beaucoup ont été inventés au cours des 50 dernières années: l'algorithme SPH, FLIP ou Position Based Fluid.
La différence entre le premier groupe de tâches du second
Dans le premier groupe, l'enseignant de l'algorithme est quelque chose d'en haut: un enregistrement de la vie réelle, comme dans le cas des individus, ou quelque chose du moteur, par exemple, le rendu d'images. Dans le deuxième groupe de problèmes, nous utilisons la méthode des mathématiques computationnelles. De cette division thématique, une idée naît.
Idée principale
Nous avons une tâche de calcul complexe qui est longue, difficile et difficile à résoudre par la méthode classique de l'université informatique. Pour le résoudre et accélérer, voire perdre un peu en qualité, il nous faut:
- trouver l'endroit le plus long dans la tâche où le code dure le plus longtemps;
- voir ce que cette ligne produit;
- essayez de prédire le résultat d'une ligne en utilisant un réseau de neurones ou tout autre algorithme d'apprentissage automatique.
Il s'agit d'une méthodologie générale et l'idée principale est une recette sur la façon de trouver une application pour l'apprentissage automatique. Que devez-vous faire pour rendre cette idée utile? Il n'y a pas de réponse exacte - utilisez la créativité, regardez votre travail et trouvez-le. Je fais du graphisme et je ne connais pas très bien d'autres domaines, mais je peux imaginer que dans le milieu universitaire - en physique, chimie, robotique - vous pouvez certainement trouver des applications. Si vous résolvez une équation physique complexe dans votre lieu de travail, vous pouvez également trouver une application pour cette idée. Pour plus de clarté, considérons un cas spécifique.
Tâche de rendu cloud
Nous étions engagés dans ce projet chez NVIDIA il y a six mois: la tâche est de dessiner un nuage physiquement correct, qui est représenté par la densité des gouttelettes liquides dans l'espace.
Un nuage est un objet physiquement complexe, une suspension de gouttelettes liquides qui ne peut pas être modélisée comme un objet solide.
Il ne sera pas possible d'imposer une texture et un rendu sur le nuage, car les gouttelettes d'eau sont difficiles à localiser géométriquement dans l'espace 3D et sont complexes en elles-mêmes: elles n'absorbent pratiquement pas la couleur, mais la reflètent, anisotrope - dans toutes les directions de différentes manières.
Si vous regardez une goutte d'eau sur laquelle le soleil brille et que les vecteurs de l'œil et du soleil sur une goutte sont parallèles, alors un grand pic d'intensité lumineuse sera observé. Cela explique le phénomène physique que tout le monde a vu: par temps ensoleillé, l'une des frontières du nuage est très lumineuse, presque blanche. Nous regardons la frontière du nuage, et la ligne de visée et le vecteur de cette frontière au soleil sont presque parallèles.

Le cloud est un objet physiquement complexe et son rendu par l'algorithme classique nécessite beaucoup de temps. Nous parlerons un peu plus tard de l'algorithme classique. Selon les paramètres, le processus peut prendre des heures, voire des jours. Imaginez que vous êtes un artiste et dessinez un film avec des effets spéciaux. Vous avez une scène compliquée avec un éclairage différent avec lequel vous voulez jouer. Nous avons dessiné une topologie cloud - je ne l'aime pas, et vous voulez la redessiner et obtenir une réponse tout de suite. Il est important d'obtenir une réponse d'un changement de paramètre le plus rapidement possible. C'est un problème. Par conséquent, essayons d'accélérer ce processus.
Solution classique
Pour résoudre le problème, vous devez résoudre cette équation compliquée.

L'équation est dure, mais comprenons sa signification physique. Considérons un faisceau percé d'un nuage perçant un nuage. Comment la lumière pénètre-t-elle dans cette direction? Premièrement, la lumière peut atteindre le point de sortie du rayon du nuage, puis se propager le long de ce rayon à l'intérieur du nuage.
Pour la deuxième méthode de "propagation de la lumière le long de la direction" est le terme intégral de l'équation. Sa signification physique est la suivante.
Considérez le segment à l'intérieur du nuage sur le rayon - du point d'entrée au point de sortie. L'intégration est effectuée précisément sur ce segment, et pour chaque point sur celui-ci, nous considérons l'
énergie dite de
lumière indirecte L (x, ω) - la signification de l'intégrale I
1 - éclairage indirect au point. Il apparaît en raison du fait que les gouttes de différentes manières reflètent la lumière du soleil. En conséquence, une énorme quantité de rayons médiés par les gouttelettes environnantes vient au point. I
1 est l'intégrale sur la sphère qui entoure un point du rayon. Dans l'algorithme classique, il est compté en utilisant la méthode de
Monte Carlo .
L'algorithme classique.
- Rendez une image à partir de pixels et produisez un rayon qui va du centre de la caméra à un pixel, puis plus loin.
- On traverse le faisceau avec le nuage, on trouve les points d'entrée et de sortie.
- Nous considérons le dernier terme de l'équation: traverser, se connecter avec le soleil.
- Échantillonnage d'importance
Comment considérer l'estimation de Monte Carlo I
1, nous n'analyserons pas, car elle est difficile et pas si importante. Il suffit de dire que c'est la partie la plus longue et la plus difficile de tout l'algorithme.
Nous connectons des réseaux de neurones
À partir de l'idée principale et de la description de l'algorithme classique, une recette explique comment appliquer des réseaux de neurones à cette tâche. Le plus difficile est de calculer le score de Monte Carlo. Il donne un nombre qui signifie un éclairage indirect en un point, et c'est exactement ce que nous voulons prédire.

Nous avons décidé de la sortie, maintenant nous comprendrons l'entrée - à partir de quelles informations il sera clair quelle est l'ampleur de la lumière indirecte au point. C'est la lumière qui est réfléchie par les nombreuses gouttelettes d'eau qui entourent le point. La topologie lumineuse est fortement influencée par la topologie de densité autour du point, la direction vers la source et la direction vers la caméra.
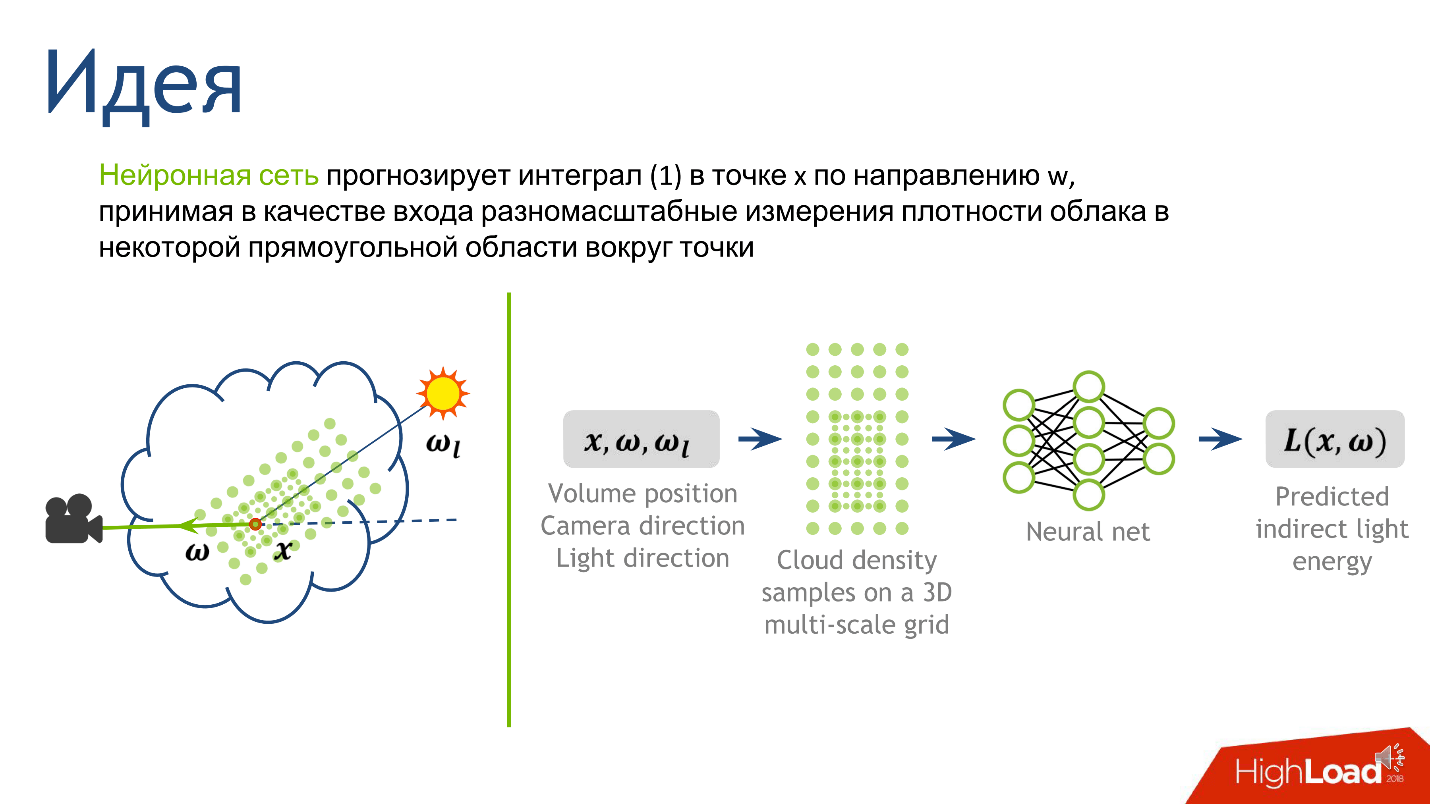
Pour construire l'entrée du réseau neuronal, nous décrivons la densité locale. Il existe de nombreuses façons de le faire, mais nous nous sommes concentrés sur l'article
Diffusion profonde: Rendu des nuages atmosphériques avec prédiction de réseaux de neurones de rayonnement, Kallwcit et al. 2017 et de nombreuses idées sont venues de là.
En bref, la méthode de représentation locale de la densité autour d'un point ressemble à ceci.
- Fixez une constante assez petite . Que ce soit le libre parcours moyen dans le cloud.
- Dessinez autour d'un point de notre segment une grille rectangulaire volumétrique de taille fixe , disons 5 * 5 * 9. Au centre de ce cube sera notre point. L'espacement de la grille est une petite constante fixe. Aux nœuds de la grille, nous mesurerons la densité du nuage.
- Augmentons la constante de 2 fois , dessinons une grille plus grande et faisons de même - mesurons la densité aux nœuds de la grille.
- Répétez plusieurs fois l'étape précédente . Nous l'avons fait 10 fois, et après la procédure, nous avons obtenu 10 grilles - 10 tenseurs, chacun d'entre eux stockant la densité des nuages, et chacun des tenseurs couvre un voisinage de plus en plus large autour du point.
Cette approche nous donne la description la plus détaillée d'une petite zone - plus elle est proche du point, plus la description est détaillée. Décidé sur la sortie et l'entrée du réseau, il reste à comprendre comment le former.
La formation
Nous allons générer 100 nuages différents avec des topologies différentes. Nous les rendrons simplement en utilisant l'algorithme classique, noterons ce que l'algorithme reçoit dans la ligne même où il effectue l'intégration de Monte Carlo et notons les propriétés qui correspondent au point. Nous obtenons donc un ensemble de données sur lequel apprendre.

Quoi enseigner ou architecture de réseau
L'architecture réseau pour cette tâche n'est pas le moment le plus crucial, et si vous ne comprenez rien - ne vous inquiétez pas - ce n'est pas la chose la plus importante que je voulais transmettre. Nous avons utilisé l'architecture suivante: pour chaque point il y a 10 tenseurs, chacun étant calculé sur une grille de plus en plus grande. Chacun de ces tenseurs tombe dans le bloc correspondant.
- D'abord dans la première couche régulière entièrement connectée .
- Après avoir quitté la première couche entièrement connectée, dans la deuxième couche entièrement connectée, qui n'a pas d'activation.
Une couche entièrement connectée sans activation n'est qu'une multiplication par une matrice. Au résultat de la multiplication par la matrice, nous ajoutons la sortie du
bloc résiduel précédent, puis n'appliquons que l'activation.
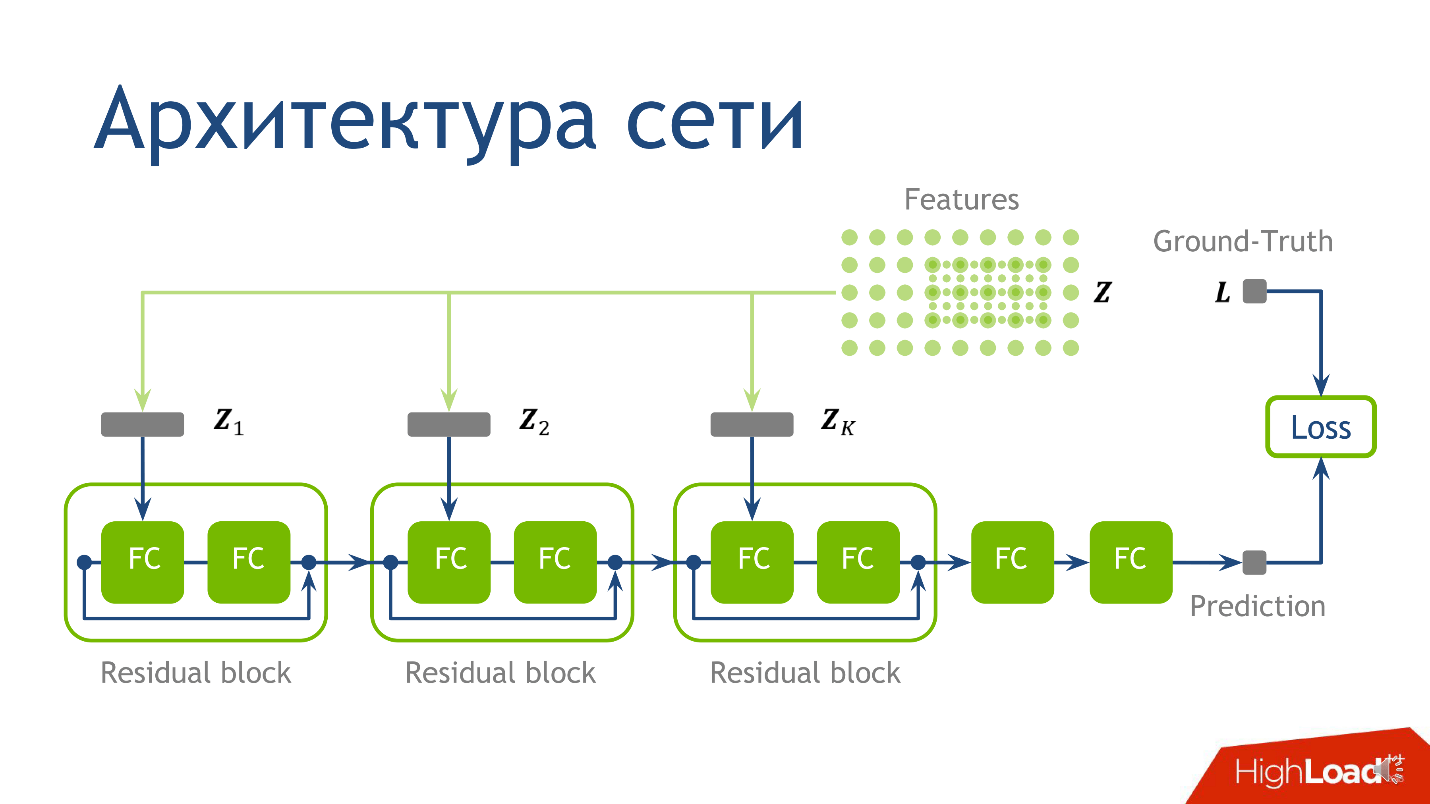
Nous prenons un point, comptons les valeurs sur chacune des grilles, plaçons les tenseurs obtenus dans le bloc résiduel correspondant - et vous pouvez effectuer l'
inférence du réseau neuronal - mode de production du réseau. Nous l'avons fait et nous nous sommes assurés d'obtenir des photos de nuages.
Résultats
La première observation - nous avons obtenu ce que nous voulions: un appel de réseau de neurones, par rapport à l'estimation de Monte Carlo, fonctionne plus rapidement, ce qui est déjà bon.
Mais il y a une autre observation sur les résultats de la formation - c'est la convergence du nombre d'échantillons. De quoi tu parles?

Lors du rendu d'une image, découpons-la en petites tuiles - carrés de pixels, disons 16 * 16. Considérez une tuile d'image sans perte de généralité. Lorsque nous rendons cette tuile, pour chaque pixel de la caméra, nous libérons beaucoup de rayons correspondant à un pixel et ajoutons un peu de bruit aux rayons afin qu'ils soient légèrement différents. Ces rayons sont appelés
anti-aliasing et sont inventés pour réduire le bruit dans l'image finale.
- Nous libérons plusieurs rayons anti-aliasing pour chaque pixel.
- À l'intérieur du faisceau de la caméra, dans le nuage, sur un segment, nous calculons n échantillons de points sur lesquels nous voulons effectuer une évaluation Monte Carlo, ou appeler un réseau pour eux.
Il existe encore des échantillons qui correspondent à la connexion avec les sources lumineuses. Ils apparaissent lorsque nous connectons un point avec une source de lumière, par exemple, avec le soleil. C'est facile à faire, car le soleil est les rayons qui tombent sur la terre parallèlement les uns aux autres. Par exemple, le ciel, en tant que source de lumière, est beaucoup plus compliqué, car il apparaît comme une sphère infiniment éloignée, qui a une fonction de couleur dans la direction. Si le vecteur semble droit verticalement dans le ciel, la couleur est bleue. Le plus bas est le plus brillant. Au fond de la sphère se trouve généralement une couleur neutre imitant la terre: vert, marron.
Lorsque nous connectons un point avec le ciel pour comprendre la quantité de lumière qui y pénètre, nous libérons toujours quelques rayons pour obtenir une réponse qui converge vers la vérité. Nous lançons plus d'un rayon pour obtenir une meilleure note. Par conséquent, l'ensemble du
rendu du pipeline nécessite autant d'échantillons.
Lorsque nous avons formé le réseau neuronal, nous avons remarqué qu'il apprenait une solution beaucoup plus moyenne. Si nous fixons le nombre d'échantillons, nous voyons que l'algorithme classique converge vers la ligne gauche de la colonne d'image, et le réseau apprend vers la droite. Cela ne signifie pas que la méthode d'origine est mauvaise - nous convergeons simplement plus rapidement. Lorsque nous augmentons le nombre d'échantillons, la méthode originale sera de plus en plus proche de ce que nous obtenons.
Notre principal résultat que nous voulions obtenir est une augmentation de la vitesse de rendu. Pour un nuage spécifique dans une résolution spécifique avec des paramètres d'échantillonnage, nous voyons que les images obtenues par le réseau et la méthode classique sont presque identiques, mais nous obtenons la bonne image 800 fois plus rapidement.

Implémentation
Il existe un programme Open Source pour la modélisation 3D -
Blender , qui implémente l'algorithme classique. Nous-mêmes n'avons pas écrit d'algorithme, mais avons utilisé ce programme: nous nous sommes formés à Blender, notant tout ce dont nous avions besoin derrière l'algorithme. La production a également été effectuée dans le cadre du programme: nous avons formé le réseau à
TensorFlow , l'avons transféré en C ++ à l'aide de TensorRT, et nous avons déjà intégré le réseau TensorRT dans Blender, car son code est ouvert.
Depuis que nous avons tout fait pour Blender, notre solution a toutes les fonctionnalités du programme: nous pouvons rendre n'importe quel type de scène et beaucoup de nuages. Les nuages dans notre solution sont définis en créant un cube, à l'intérieur duquel nous déterminons la fonction de densité d'une manière spécifique pour les programmes 3D. Nous avons optimisé ce processus - la densité du cache. Si un utilisateur veut dessiner le même nuage sur une pile de configurations différentes d'une scène: dans différentes conditions d'éclairage, avec différents objets sur la scène, il n'a pas besoin de recalculer constamment la densité des nuages. Ce qui s'est passé, vous pouvez regarder la
vidéo .
En conclusion, je répète une fois de plus l'idée principale que je voulais transmettre:
si dans votre travail pendant longtemps et dur vous considérez quelque chose comme un algorithme de calcul spécifique, et cela ne vous convient pas - trouvez la place la plus difficile dans le code, remplacez-la par un réseau de neurones, et peut-être que cela vous aidera.— , Saint HighLoad++ 2019 . , , , — 1 . .
, , . , .