Dans le
dernier article, nous avons examiné les limites et les obstacles qui surviennent lorsque vous devez mettre à l'échelle des données horizontalement et avoir une garantie des propriétés ACID des transactions. Dans cet article, nous parlons de la technologie FoundationDB et comprenons comment elle aide à surmonter ces limitations lors du développement d'applications stratégiques.
FoundationDB est une base de données NoSQL distribuée avec des transactions ACID sérialisables qui stocke des paires de magasins clé-valeur triées. Les clés et les valeurs peuvent être des séquences arbitraires d'octets. Il n'a pas un seul point d'incidence - toutes les machines de cluster sont égales. Il répartit lui-même les données entre les serveurs du cluster et évolue à la volée: lorsque vous devez ajouter des ressources au cluster, vous ajoutez simplement l'adresse de la nouvelle machine sur les serveurs de configuration et la base de données la récupère elle-même.
Dans FoundationDB, les transactions ne se bloquent jamais. La lecture est implémentée via le
contrôle de version multiversion (MVCC), et la lecture est implémentée via le
contrôle de concurrence optimiste (OCC). Les développeurs affirment que lorsque toutes les machines du cluster sont dans le même centre de données, la latence d'écriture est de 2 à 3 ms et la latence de lecture est inférieure à une milliseconde. La documentation contient des estimations de 10 à 15 ms, ce qui est probablement plus proche des résultats en conditions réelles.
 * Ne prend pas en charge les propriétés ACID sur plusieurs fragments.
* Ne prend pas en charge les propriétés ACID sur plusieurs fragments.FoundationDB a un avantage unique: le redistribution automatique. Le SGBD lui-même assure un chargement uniforme des machines dans le cluster: lorsqu'un serveur est plein, il redistribue les données aux serveurs voisins en arrière-plan. Dans le même temps, la garantie du niveau de sérialisation pour toutes les transactions est préservée, et le seul effet perceptible pour les clients est une légère augmentation de la latence des réponses. La base de données garantit que la quantité de données sur les serveurs de cluster les plus et les moins chargés ne diffère pas de plus de 5%.
L'architecture
Logiquement, un cluster FoundationDB est un ensemble de processus du même type sur différentes machines physiques. Les processus n'ont pas leurs propres fichiers de configuration, ils sont donc interchangeables. Plusieurs processus fixes ont un rôle dédié - coordinateurs, et chaque processus de cluster au démarrage connaît leurs adresses. Il est important que les plantages des coordinateurs soient aussi indépendants que possible, il est donc préférable de les placer sur différentes machines physiques ou même dans différents centres de données.
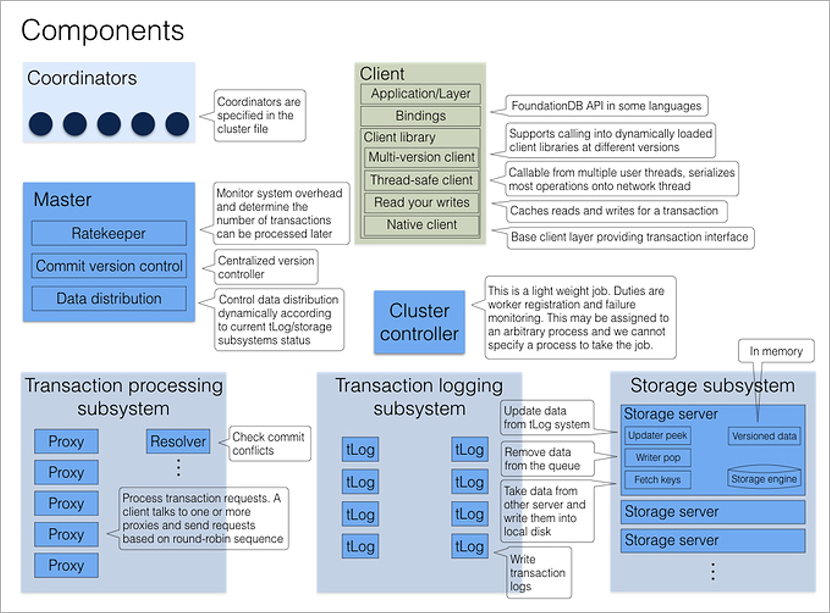
Les coordinateurs s'accordent entre eux via l'algorithme de consensus
Paxos . Ils sélectionnent le processus Cluster Controller, qui attribue ensuite des rôles au reste des processus de cluster. Le Cluster Controller informe en permanence tous les coordinateurs qu'il est vivant. Si la plupart des coordinateurs pensent qu'il est mort, ils en choisissent simplement un nouveau. Ni le Cluster Controller ni les Coordinators ne sont impliqués dans le traitement des transactions; leur tâche principale est d'éliminer la situation de
split brain .
Lorsqu'un client souhaite se connecter à la base de données, il contacte immédiatement tous les coordinateurs pour l'adresse du contrôleur de cluster actuel. Si la plupart des réponses correspondent, il reçoit du contrôleur de cluster la configuration actuelle complète du cluster (s'il ne correspond pas, il appelle à nouveau les coordinateurs).
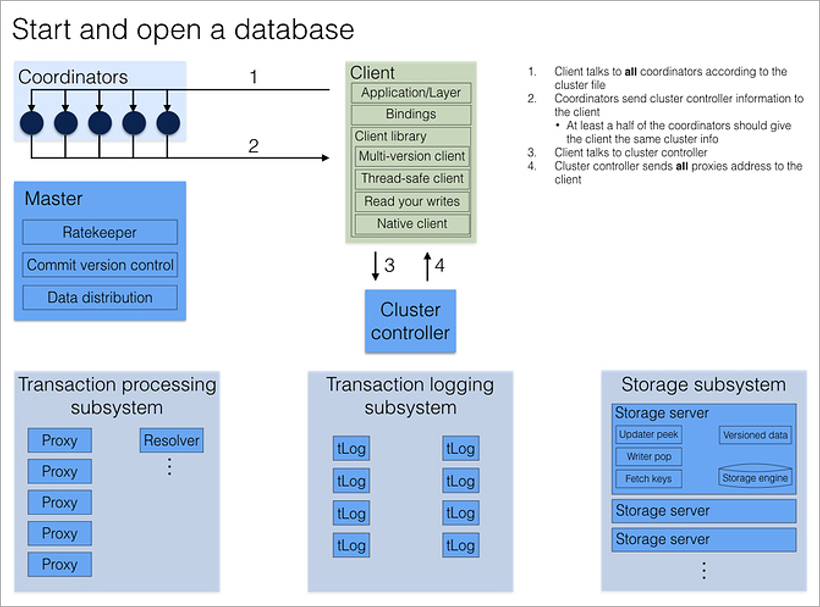
Le Cluster Controller connaît le nombre total de processus disponibles et répartit les rôles: ces 5 seront Proxy, ces 2 seront Resolver, celui-ci sera Master. Et si l'un d'eux meurt, il trouvera immédiatement un remplaçant pour lui, attribuant le rôle nécessaire à un processus libre arbitraire. Tout cela se passe en arrière-plan, invisible pour le programmeur d'application.
Le processus maître est responsable du numéro de la version actuelle de l'ensemble de données (il augmente chaque fois qu'il est écrit dans la base de données), ainsi que de la distribution de nombreuses clés entre les serveurs de stockage et de la limitation du débit (performances artificiellement inférieures sous de lourdes charges: si le cluster sait que le client fera beaucoup de petites demandes, il attendra, les groupera et répondra à l'ensemble du pack en une seule fois).
La journalisation des transactions et le stockage sont deux sous-systèmes de stockage indépendants. Le premier est un stockage temporaire pour écrire rapidement des données sur le disque dans l'ordre de réception, le second est un stockage permanent, où les données sur le disque sont triées par ordre croissant de clés. À chaque validation de transaction, au moins trois processus tLog doivent enregistrer les données avant que le cluster ne signale le succès au client. En parallèle, les données en arrière-plan passent des serveurs tLog aux serveurs de stockage (stockage sur lequel est également redondant).
Traitement des demandes
Toutes les demandes des clients traitent les processus proxy. En ouvrant une transaction, le client accède à n'importe quel proxy, il interroge tous les autres proxy et renvoie le numéro de version actuel des données du cluster. Toutes les lectures suivantes ont lieu à ce numéro de version. Si un autre client a noté les données après avoir ouvert la transaction, je ne verrai tout simplement pas ses modifications.
L'enregistrement d'une transaction est un peu plus compliqué car vous devez résoudre des conflits. Cela inclut le processus Resolver, qui stocke en mémoire toutes les clés modifiées pendant une certaine période de temps. Lorsque le client termine la transaction de validation, le résolveur vérifie si les données qu'il lisait sont obsolètes. (C'est-à-dire si la transaction qui a été ouverte plus tard que la mienne a été terminée et a changé les clés que j'ai lues.) Si cela se produit, la transaction est annulée et la bibliothèque cliente elle-même (!) Fait une deuxième tentative de validation. La seule chose à laquelle le développeur doit penser est que les transactions sont idempotentes, c'est-à-dire qu'une utilisation répétée devrait donner un résultat identique. Une façon d'y parvenir consiste à enregistrer une valeur unique dans la transaction et, au début de la transaction, à vérifier sa présence dans la base de données.
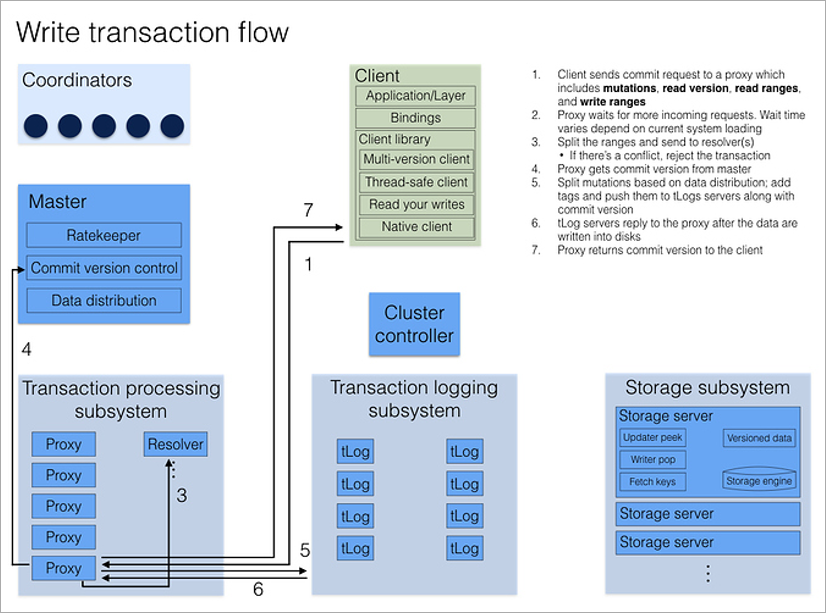
Comme dans tout système client-serveur, il existe des situations où la transaction s'est terminée avec succès, mais le client n'a pas reçu de confirmation en raison d'une déconnexion. La bibliothèque cliente les traite comme n'importe quelle autre erreur - elle réessaye simplement. Cela pourrait potentiellement conduire à la réexécution de l'ensemble de la transaction. Cependant, si la transaction est idempotente, cela ne pose aucun problème - cela n'affectera pas le résultat final.
Mise à l'échelle
Il peut y avoir des milliers de serveurs dans un sous-système de stockage. Lequel d'entre eux un client doit-il contacter lorsqu'il a besoin de données sur une certaine clé? Depuis Cluster Controller, le client connaît la configuration complète de l'ensemble du cluster et il inclut des plages de clés sur chaque serveur de stockage. Par conséquent, il accède simplement aux serveurs de stockage souhaités directement sans aucune demande intermédiaire.
Si le serveur de stockage souhaité n'est pas disponible, la bibliothèque cliente prend une nouvelle configuration à partir du Cluster Controller. Si, à la suite d'une panne de serveur, le cluster comprend que la redondance est insuffisante, il commence immédiatement à collecter un nouveau nœud à partir de morceaux d'un autre stockage.
Supposons que vous enregistrez un gigaoctet de données dans une transaction. Comment pouvez-vous répondre rapidement? En aucun cas, FoundationDB n'a simplement limité la taille d'une transaction à 10 mégaoctets. De plus, il s'agit d'une restriction sur toutes les données concernées par la transaction - lues ou écrites. Chaque entrée dans la base de données est également limitée - la clé ne peut pas dépasser 10 kilo-octets, la valeur est de 100 kilo-octets. (Dans le même temps, pour des performances optimales, les développeurs recommandent des clés d'une longueur de 32 octets et des valeurs d'une longueur de 10 kilo-octets.)
Toute transaction peut potentiellement devenir une source de conflit, puis elle devra être annulée. Par conséquent, pour des raisons de vitesse, jusqu'à ce que la commande commit arrive, il est logique de conserver les modifications actuelles dans la RAM et non sur le disque. Supposons que vous écrivez des données dans une base de données avec une charge de 1 Go / seconde. Ensuite, dans un cas extrême, votre cluster allouera 3 Go de RAM chaque seconde (nous écrivons des transactions sur 3 machines). Comment limiter une telle croissance en avalanche de la mémoire utilisée? Il est très simple de limiter le temps de transaction maximum. Dans FoundationDB, une transaction ne peut pas durer plus de 5 secondes. Si le client tente d'accéder à la base de données 5 secondes après l'ouverture de la transaction, le cluster ignorera toutes ses commandes jusqu'à ce qu'il en ouvre une nouvelle.
Indices
Supposons que vous gardiez une liste de personnes, chaque personne a un identifiant unique, nous l'utilisons comme clé, et dans la valeur, nous écrivons tous les autres attributs - nom, sexe, âge, etc.
| Clé | Valeur |
| 12345 | (Ivanov Ivan Ivanovich, M, 35 ans) |
Comment obtenir une liste de toutes les personnes de 30 ans sans recherche exhaustive? Pour cela, un index est généralement créé dans la base de données. Un index est une autre vue de données conçue pour rechercher rapidement des attributs supplémentaires. Nous pouvons simplement ajouter des entrées du formulaire:
Maintenant, pour obtenir la liste dont vous avez besoin, il vous suffit de rechercher la plage de touches (30, *). Étant donné que FoundationDB stocke les données triées par clé, une telle requête s'exécutera très rapidement. Bien sûr, l'index prend de l'espace disque supplémentaire, mais très peu. Veuillez noter que tous les attributs ne sont pas dupliqués, mais uniquement l'âge et l'identifiant.
Il est important que les opérations d'ajout de l'enregistrement lui-même et de son index soient effectuées en une seule transaction.
Fiabilité
FoundationDB est écrit en C ++. Les auteurs ont commencé à y travailler en 2009, la première version a été publiée en 2013 et en mars 2015, ils ont été achetés par Apple. Trois ans plus tard, Apple a ouvert le code source de manière inattendue.
La rumeur veut qu'Apple l'utilise, entre autres, pour stocker les données du service iCloud.
Les développeurs expérimentés ne font généralement pas immédiatement confiance aux nouvelles solutions. Cela peut prendre des années avant que la technologie ne s'établisse de manière fiable et qu'elle commence à être massivement utilisée en production. Pour réduire ce temps, les auteurs ont fait une extension intéressante du langage C ++:
Flow . Il vous permet d'émuler gracieusement le travail avec des composants externes non fiables avec la possibilité d'une répétition prévisible complète de l'exécution du programme. Chaque appel vers un réseau ou un disque est encapsulé dans un wrapper (Acteur), et chaque Acteur a plusieurs implémentations. L'implémentation standard écrit les données sur le disque ou sur le réseau, comme prévu. Et l'autre écrit sur le disque 999 fois sur 1000 et perd 1 fois sur 1000. Une implémentation réseau alternative peut, par exemple, permuter des octets dans des paquets réseau. Il y a même des acteurs qui imitent le travail d'un administrateur système imprudent. Cela peut supprimer le dossier de données ou échanger deux dossiers. Les développeurs
pilotent des milliers de simulations , en remplaçant différents acteurs et en utilisant Flow atteignent une reproductibilité à 100%: si un test échoue, ils peuvent redémarrer la simulation et obtenir un plantage au même endroit. En particulier, pour éliminer l'incertitude introduite par les threads de commutation du planificateur du système d'exploitation, chaque processus FoundationDB est strictement monothread.
Lorsqu'un
chercheur qui a découvert
des scénarios de perte de données dans presque toutes les solutions NoSQL populaires a été invité à tester FoundationDB, il a refusé, notant qu'il ne voyait pas le point, car les auteurs ont
fait un travail géant et les ont
testés beaucoup plus profondément et plus en profondeur que le sien.
Il est habituel de penser que les échecs de cluster sont aléatoires, mais les devops expérimentés savent que c'est loin d'être le cas. Si vous disposez de 10 000 disques du même fabricant et du même nombre d'autres, le taux d'échec sera différent. Dans FoundationDB, une configuration dite orientée machine est possible dans laquelle vous pouvez indiquer au cluster quelles machines se trouvent dans le même centre de données et quels processus se trouvent sur la même machine. La base de données en tiendra compte lors de la répartition de la charge entre les machines. Et les machines d'un cluster ont généralement des caractéristiques différentes. FoundationDB prend également cela en compte, examine la longueur des files d'attente de demandes et redistribue la charge de manière équilibrée: les machines les plus faibles reçoivent moins de demandes.
Ainsi, FoundationDB fournit des transactions ACID et le plus haut niveau d'isolation, sérialisable, sur un cluster de milliers de machines. Avec une flexibilité incroyable et des performances élevées, cela ressemble à de la magie. Mais vous devez tout payer, il y a donc des limites technologiques.
Limitations
En plus des limites déjà mentionnées sur la taille et la durée de la transaction, il est important de noter les caractéristiques suivantes:
- Le langage de requête n'est pas SQL, c'est-à-dire que les développeurs ayant une expérience SQL devront réapprendre.
- La bibliothèque cliente ne prend en charge que 5 langages de haut niveau (Phyton, Ruby, Java, Golang et C). Il n'y a pas encore de client officiel pour C #. Puisqu'il n'y a pas d'API REST, la seule façon de prendre en charge une autre langue est d'écrire un wrapper dessus au-dessus de la bibliothèque C standard.
- Il n'y a pas de mécanismes de partage, toute cette logique doit être fournie par votre application.
- Le format de stockage des données n'est pas documenté (bien qu'il ne soit généralement pas documenté non plus dans les bases de données commerciales). C'est un risque, car si soudainement le cluster ne s'assemble pas, il n'est pas immédiatement clair quoi faire et devra fouiller dans les fichiers source.
- Un modèle de programmation strictement asynchrone peut sembler compliqué aux développeurs débutants.
- Vous devez constamment penser à l'idempotence des transactions.
- Si vous devez diviser de longues transactions en petites transactions, vous devez vous-même vous soucier de l'intégrité au niveau mondial.
Traduit de l'anglais, «Foundation» signifie «Foundation» et les auteurs de ce SGBD voient son rôle de cette façon: fournir un haut niveau de fiabilité au niveau des enregistrements simples, et toute autre base de données peut être implémentée en tant que complément à la fonctionnalité de base. Ainsi, en plus de FoundationDB, vous pouvez potentiellement créer d'autres couches - documents, graphiques, etc. La question reste de savoir comment ces couches évolueront sans perte de performances. Par exemple, les auteurs de CockroachDB ont déjà emprunté cette voie - en créant une couche SQL au-dessus de RocksDB (magasin de valeurs de clés locales) et ils ont rencontré des problèmes de performances inhérents aux jointures relationnelles.
À ce jour, Apple a développé et publié 2 couches au-dessus de FoundationDB:
Document Layer (prend en charge MongoDB API) et
Record Layer (stocke les enregistrements sous forme d'ensembles de champs au format
Protocol Buffers , prend en charge les index, n'est disponible qu'en Java). Il est agréable et agréablement surprenant que la société historiquement fermée d'Apple suive aujourd'hui les traces de Google et de Microsoft et publie le code source des technologies utilisées à l'intérieur.
Perspectives
Il existe un tel conflit existentiel dans le développement de logiciels: l'entreprise veut constamment des changements, des améliorations par rapport au produit. Mais en même temps, il veut un logiciel fiable. Et ces deux exigences se contredisent, car lorsque le logiciel change, des bugs apparaissent et l'entreprise en souffre. Par conséquent, si dans votre produit vous pouvez compter sur une technologie fiable et éprouvée et écrire moins de code vous-même, cela vaut toujours la peine. En ce sens, malgré certaines restrictions, il est cool de ne pas pouvoir sculpter des béquilles dans différentes bases de données NoSQL, mais d'utiliser une solution éprouvée en production avec des propriétés ACID.
Il y a un an, nous étions
optimistes quant à une autre technologie - CockroachDB, mais elle ne répondait pas à nos attentes de performance. Depuis lors, nous avons perdu notre appétit pour l'idée d'une couche SQL sur un magasin de valeurs-clés distribué, et n'avons donc pas examiné attentivement, par exemple,
TiDB . Nous prévoyons d'essayer soigneusement FoundationDB comme base de données secondaire pour les plus grands ensembles de données de notre projet. Si vous avez déjà de l'expérience dans l'utilisation réelle de FoundationDB ou TiDB en production, nous serons heureux d'entendre votre avis dans les commentaires.