
Au cours de l'année écoulée, il y a eu tellement de publications sur les microservices que ce serait une perte de temps de dire ce que c'est et pourquoi, donc le reste de la discussion se concentrera sur la question de savoir comment mettre en œuvre cette architecture et pourquoi elle a été confrontée exactement et quels problèmes elle a rencontrés.
Nous avons eu de gros problèmes dans une petite banque: 3 monolithes de python connectés par une quantité monstrueuse d'interactions RPC synchrones avec un grand volume d'héritage. Afin de résoudre au moins partiellement tous les problèmes qui se posent dans ce cas, il a été décidé de passer à une architecture de microservice. Mais avant de décider d'une telle étape, vous devez répondre à 3 questions principales:
- Comment briser un monolithe en microservices et quels critères doivent être suivis.
- Comment les microservices interagiront-ils?
- Comment surveiller?
En fait, de brèves réponses à ces questions seront consacrées à cet article.
Comment briser un monolithe en microservices et quels critères doivent être suivis.
Cette question apparemment simple a finalement déterminé l'ensemble de l'architecture future.
Nous sommes une banque, donc tout le système tourne autour des opérations avec des finances et diverses choses auxiliaires. Il est certainement possible de transférer des transactions financières ACID vers un système distribué avec des sagas , mais dans le cas général, c'est extrêmement difficile. Ainsi, nous avons développé les règles suivantes:
- Conformez-vous à S de SOLID pour les microservices
- La transaction doit être entièrement effectuée dans le microservice - aucune transaction distribuée sur les dommages de la base de données
- Pour fonctionner, le microservice a besoin d'informations de sa propre base de données ou d'une requête
- Essayez d'assurer la propreté (au sens des langages fonctionnels) des microservices
Naturellement, en même temps, il était impossible de les satisfaire complètement, mais même une mise en œuvre partielle simplifie considérablement le développement.
Comment les microservices interagiront-ils?
Il existe de nombreuses options, mais au final, toutes peuvent être résumées par de simples "messages d'échange de microservices", mais si vous implémentez un protocole synchrone (par exemple, RPC via REST), la plupart des inconvénients du monolithe resteront, mais les avantages des microservices n'apparaîtront guère. La solution évidente était donc de prendre n'importe quel courtier de messages et de commencer. Le choix entre RabbitMQ et Kafka s'est installé sur ce dernier, et voici pourquoi:
- Kafka est plus simple et fournit un modèle de messagerie unique - Publier - s'abonner
- Il est relativement facile d'obtenir des données de Kafka une deuxième fois. Ceci est extrêmement pratique pour le débogage ou la correction de bogues lors d'un traitement incorrect, ainsi que pour la surveillance et la journalisation.
- Un moyen clair et simple de faire évoluer le service: ajout de partitions au sujet, lancement de plus d'abonnés - le reste sera fait par kafka.
De plus, je veux attirer l'attention sur une comparaison détaillée de très haute qualité .
Les files d'attente sur kafka + asynchronie nous permettent de:
- Désactivez brièvement tout microservice pour les mises à jour sans conséquences notables pour le reste
- Désactivez tout service pendant une longue période et ne vous souciez pas de la récupération de données. Par exemple, le microservice de fiscalisation a récemment chuté. Il a été réparé après 2 heures, il a pris les comptes bruts de Kafka et a tout traité. Il n'était pas nécessaire, comme auparavant, de restaurer ce qui devait s'y produire et d'exécuter manuellement les journaux HTTP et une table distincte dans la base de données.
- Exécutez des versions de test des services sur les données actuelles de la vente et comparez les résultats de leur traitement avec la version du service sur la vente.
En tant que système de sérialisation des données, nous avons choisi AVRO, pourquoi - décrit dans un article séparé .
Mais quelle que soit la méthode de sérialisation choisie, il est important de comprendre comment le protocole sera mis à jour. Bien qu'AVRO supporte la résolution de schéma, nous ne l'utilisons pas et décidons de manière purement administrative:
- Les données dans les rubriques sont écrites et lues uniquement via AVRO, le nom de la rubrique correspond au nom du schéma (et Confluent a une approche différente - ils écrivent les schémas ID AVRO à partir du registre dans les octets élevés du message, afin qu'ils puissent avoir différents types de messages dans une rubrique
- Si vous devez ajouter ou modifier des données, un nouveau schéma est créé avec un nouveau sujet dans kafka, après quoi tous les producteurs passent à un nouveau sujet, puis sont suivis par les abonnés
Nous stockons les circuits AVRO eux-mêmes dans des sous-modules git et nous nous connectons à tous les projets kafka. Ils ont décidé de ne pas encore mettre en place un registre centralisé des régimes.
PS: mes collègues ont fait l'option opensource mais uniquement avec le schéma JSON au lieu d'AVRO .
Quelques subtilités
Chaque abonné reçoit tous les messages du sujet
C'est la spécificité du modèle d'interaction Publier - s'abonner - lorsqu'il est abonné à un sujet, l'abonné les recevra tous. Par conséquent, si le service n'a besoin que de certains messages, il devra les filtrer. Si cela devient un problème, il sera possible de créer un routeur de service séparé qui disposera des messages dans plusieurs rubriques différentes, mettant ainsi en œuvre une partie de la fonctionnalité RabbitMQ qui n'est pas dans le kafka. Maintenant, nous avons un abonné sur python dans un thread qui traite environ 7 à 5 000 messages par seconde, mais si vous exécutez via PyPy, la vitesse passe à 11-15 000 / sec.
Limiter la durée de vie d'un pointeur dans un sujet
Dans les paramètres de la kafka, il y a un paramètre qui limite le temps pendant lequel la kafka "se souvient" de l'endroit où le lecteur s'est arrêté - la valeur par défaut est 2 jours. Il serait bon de le porter à une semaine, de sorte que si le problème survient les jours fériés et que 2 jours ne soient pas résolus, cela ne conduirait pas à une perte de position dans le sujet.
Lire le délai de confirmation
Si le lecteur Kafka ne confirme pas la lecture dans les 30 secondes (paramètre configurable), le courtier pense que quelque chose s'est mal passé et une erreur se produit lors de la tentative de confirmation de la lecture. Pour éviter cela, lors du traitement d'un message pendant une longue période, nous envoyons des confirmations de lecture sans déplacer le pointeur.
Le graphique des connexions est difficile à comprendre.
Si vous dessinez honnêtement toutes les relations dans graphviz, un hérisson de l'apocalypse, qui est traditionnel pour les microservices, apparaît avec des dizaines de connexions dans un nœud. Pour au moins en quelque sorte le rendre (le graphique des connexions) lisible, nous nous sommes mis d'accord sur la notation suivante: microservices - ovales, sujets de kafka - rectangles. Ainsi, sur un graphique, il est possible d'afficher à la fois le fait de l'interaction et son type. Mais, hélas, ça ne va pas beaucoup mieux. Cette question est donc toujours ouverte.
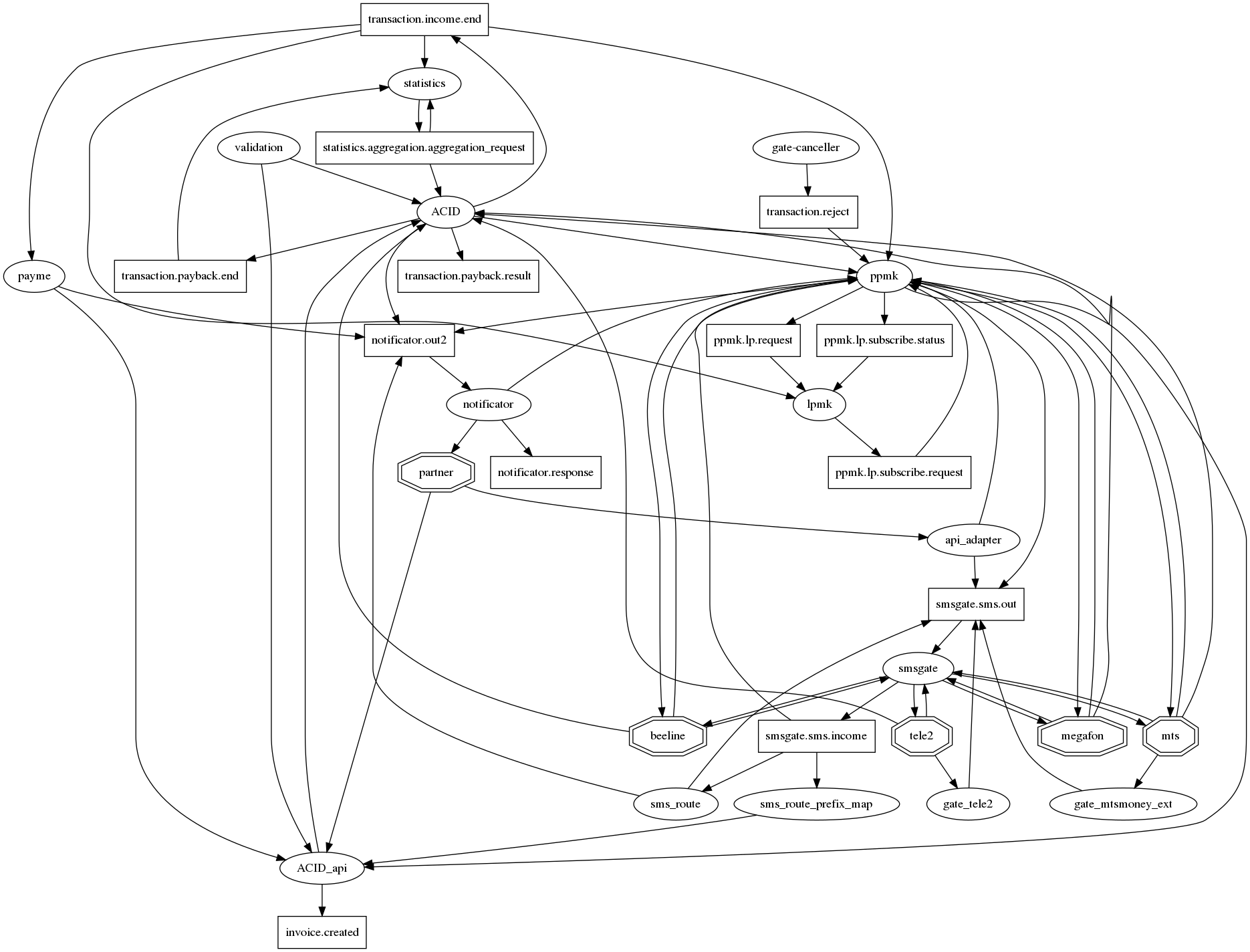
Comment surveiller?
Même dans le cadre du monolithe, nous avions des journaux dans les fichiers et Sentry. Mais alors que nous passions à l'interaction via Kafka et déployions vers k8, les journaux étaient déplacés vers ElasticSearch et, en conséquence, nous avons d'abord surveillé la lecture des journaux de l'abonné dans Elastic. Pas de journaux - pas de travail.
Après cela, ils ont commencé à utiliser Prometheus et kafka-exporter a légèrement modifié son tableau de bord: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
En conséquence, nous obtenons ces images:
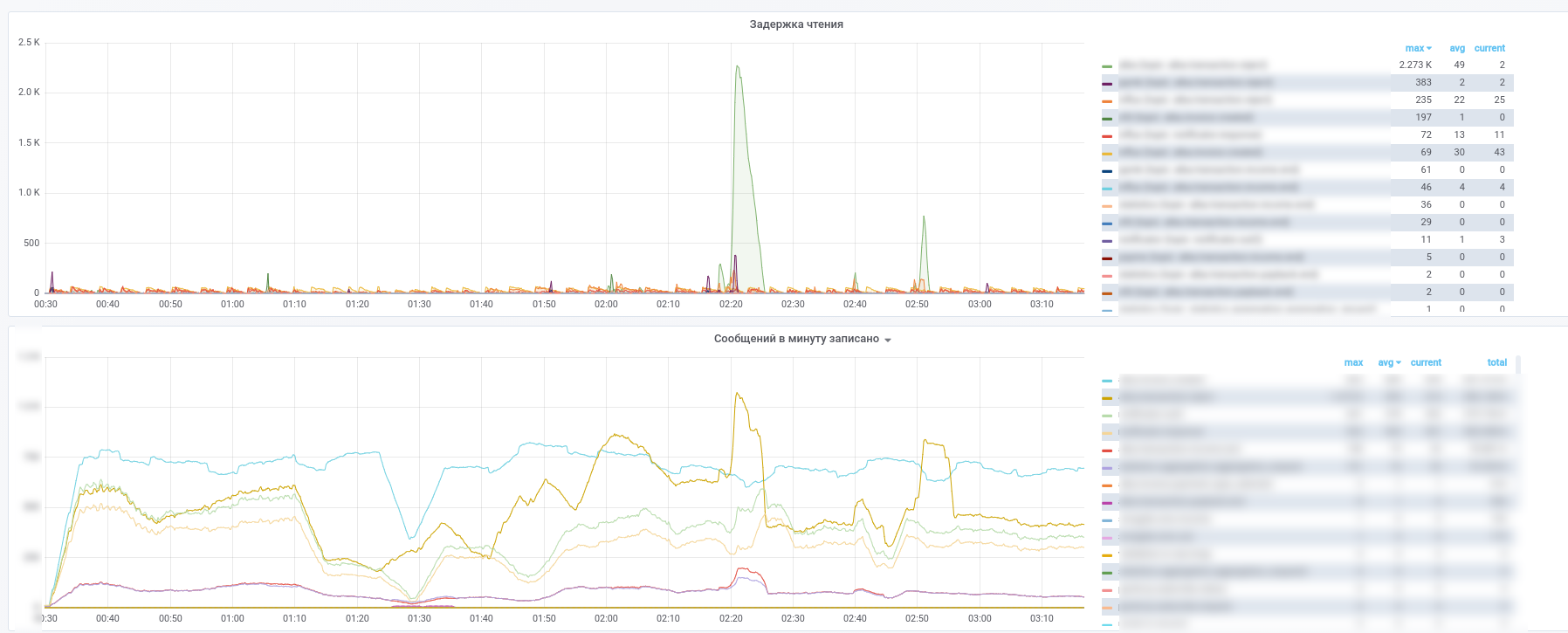
Vous pouvez voir quel service a cessé de traiter quels messages.
De plus, tous les messages des sujets clés (transactions de paiement, notifications des partenaires, etc.) sont copiés dans InfluxDB, qui est configuré dans le même grafana. Ainsi, nous pouvons non seulement enregistrer le fait de la transmission des messages, mais également effectuer divers échantillons en fonction du contenu. Ainsi, les réponses à des questions telles que «quel est le délai moyen pour une réponse d'un service» ou «Le flux de transactions est-il très différent aujourd'hui d'hier dans ce magasin» sont toujours à portée de main.
De plus, pour simplifier l'analyse des incidents, nous utilisons l'approche suivante: chaque service, lors du traitement d'un message, le complète avec des méta-informations contenant l'UUID émis lorsque le système affiche un tableau d'enregistrements du type:
- nom du service
- UUID du processus de traitement dans ce microservice
- horodatage de démarrage du processus
- temps de traitement
- jeu de balises
Par conséquent, lorsque le message passe à travers le graphe de calcul, le message est enrichi d'informations sur le chemin parcouru sur le graphe. Il s'avère un analogue de zipkin / opentracing pour MQ, qui permet de recevoir un message pour restaurer facilement son chemin sur le graphique. Cela acquiert une valeur spéciale dans les cas où des cycles apparaissent sur le graphique. Rappelez-vous l'exemple d'un petit service dont la part des paiements n'est que de 0,0001%. En analysant les méta-informations contenues dans le message, il peut déterminer s'ils sont à l'origine du paiement, sans contacter la base de données pour vérification.