Lors du développement d'applications réseau très chargées, il est nécessaire d'équilibrer la charge.
Un outil d'équilibrage L7 populaire est Nginx. Il vous permet de mettre en cache les réponses, de choisir différentes stratégies et même de script sur LUA.
Malgré tous les charmes de Nginx, si:
- Pas besoin de travailler avec HTTP (s).
- Vous devez extraire le maximum du réseau.
- Il n'est pas nécessaire de mettre en cache quoi que ce soit - l'équilibreur a des serveurs API propres et dynamiques.
La question peut se poser: pourquoi avez-vous besoin de Nginx? Pourquoi dépenser des ressources en équilibre sur L7, n'est-il pas plus simple de simplement transférer le paquet SYN? (Routage direct L4).
Équilibrage de la couche 4 ou comment équilibrer dans l'Antiquité
IPVS était un outil de transfert de paquets populaire. Il a effectué des tâches d'équilibrage via le tunnel et le routage direct.
Dans le premier cas, un canal TCP a été établi pour chaque connexion et le paquet de l'utilisateur est allé à l'équilibreur, puis au serviteur, puis dans l'ordre inverse.
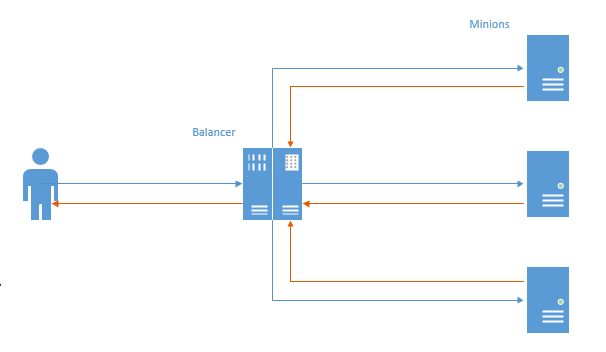
Dans ce schéma, le problème principal est visible: dans la direction opposée, les données vont d'abord à l'équilibreur, puis à l'utilisateur (Nginx fonctionne de la même manière). Un travail inutile est effectué, étant donné que généralement plus de données sont envoyées à l'utilisateur, ce comportement entraîne une perte de performances.
Un tel inconvénient est privé (mais doté de nouveaux) d'une méthode d'équilibrage appelée Direct Routing. Schématiquement, cela ressemble à ceci:
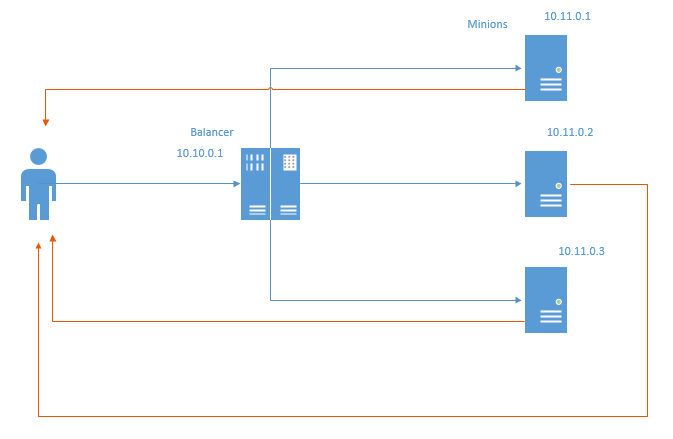
Dans le cas du routage direct, les paquets de retour vont directement à l'utilisateur, contournant l'équilibreur. De toute évidence, les ressources d'équilibrage et le réseau sont enregistrés. En économisant les ressources du réseau, cela n'économise pas tellement le trafic, car la pratique habituelle consiste à connecter les serveurs à une grille distincte et non à prendre en compte le trafic, mais le fait que même le transfert via l'équilibreur représente une perte de millisecondes.
Cette méthode impose certaines restrictions:
- Le centre de données où se trouve l'infrastructure doit permettre d'usurper les adresses locales. Dans le diagramme ci-dessus, chaque serviteur doit renvoyer des paquets au nom de l'IP 10.10.0.1, qui est affecté à l'équilibreur.
- L'équilibreur ne sait rien de l'état des sbires. Par conséquent, les stratégies Least Conn et Least Time ne sont pas réalisables dès le départ. Dans l'un des articles suivants, je vais essayer de les implémenter et de montrer le résultat.
Voici venir NFTables
Il y a quelques années, Linux a commencé à promouvoir activement NFTables en remplacement des tables IPTables, ArpTables, EBTables et de tout le monde [az] {1,} Tables. Au moment où nous, à Adram, avions besoin de presser toutes les millisecondes de la réponse du réseau, j'ai décidé de retirer le vérificateur et de rechercher - ou peut-être que ipTables a appris à faire le transfert iphash et vous pouvez l'accélérer pour l'équilibrer. Ensuite, je suis tombé sur des nftables, qui peuvent et non seulement cela, mais iptables ne peuvent toujours pas faire cela.
Après plusieurs jours d'essai, j'ai finalement pu obtenir le routage direct et le routage des canaux via les NFTables dans le laboratoire de test et les comparer par rapport à nginx.
Donc, le laboratoire de test. Nous avons 5 voitures:
- nft-router - un routeur qui effectue la tâche de connexion du client et du sous-réseau AppServer. Il y a 2 cartes réseau dessus: 192.168.56.254 - regarde le réseau du serveur d'application, 192.168.97.254 - regarde les clients. Ip_forward est activé et tous les itinéraires sont enregistrés.
- nft-client: client à partir duquel ab, ip 192.168.97.2 sera poursuivi
- nft-balancer: équilibreur. Il possède deux adresses IP: 192.168.56.4, auxquelles les clients accèdent et 192.168.13.1, à partir du sous-réseau des sbires.
- nft-minion-a et nft-minion-b: minions ipy: 192.168.56.2, 192.168.56.3 et 192.168.13.2 et 192.168.13.3 (j'ai essayé d'utiliser à la fois le même réseau et les différents pour équilibrer). Dans les tests, je me suis arrêté sur le fait que les serviteurs ont des types "externes" - dans le sous-réseau 192.168.56.0/24
Toutes les interfaces MTU 1500.
Acheminement direct
Paramètres NFTables sur l'équilibreur:
table ip raw { chain input { type filter hook prerouting priority -300; policy accept; tcp dport http ip daddr set jhash tcp sport mod 2 map { 0: 192.168.56.2, 1: 192.168.56.3 } } }
Une chaîne brute est créée, sur le crochet, avec une priorité de -300.
Si un paquet avec une adresse de destination http arrive, alors en fonction du port source (effectué pour les tests à partir d'une machine, vous avez réellement besoin d'ip saddr), 56.2 ou 56.3 est sélectionné et défini comme adresse de destination dans le paquet, puis envoyé plus loin le long des routes. En gros, pour les ports pairs 56.2, pour les ports impairs, respectivement, 56.3 (en fait, non, car pour les hachages pairs / impairs, mais c'est plus facile à comprendre). Après avoir défini l'IP cible, le paquet retourne au réseau. Aucun NAT ne se produit, le package arrive aux serviteurs avec l'adresse IP source du client, et non l'équilibreur, ce qui est important pour le routage direct.
Paramètres NFT de Minion:
table ip raw { chain output { type filter hook output priority -300; policy accept; tcp sport http ip saddr set 192.168.56.4 } }
Un hook de sortie brut est créé avec une priorité de -300 (la priorité est très importante ici, à des niveaux supérieurs, le ménagement nécessaire ne fonctionnera pas pour les paquets de réponse).
Tout le trafic sortant du port http est signé par 56.4 (équilibreur ip) et envoyé directement au client, contournant l'équilibreur.
Pour vérifier si tout fonctionnera correctement, j'ai amené le client sur un autre réseau et l'ai laissé passer par le routeur.
J'ai également désactivé arp_filter, rp_filter (pour que l'usurpation fonctionne) et activé ip_forward à la fois sur l'équilibreur et sur le routeur.
Pour les bancs, dans le cas de NFT, Nginx + php7.2-FPM est utilisé via une socket Unix sur chaque serviteur. Il n'y avait rien sur l'équilibreur.
Dans le cas de Nginx, nous avons utilisé: nginx sur l'équilibreur et php7.2-FPM sur TCP sur les sbires. En conséquence, je n'ai pas équilibré le serveur Web derrière l'équilibreur, mais immédiatement FPM (ce qui sera plus honnête avec nginx et plus cohérent avec la vie réelle).
Pour NFT, seule la stratégie de hachage a été utilisée (
nft dr dans le tableau), pour nginx: hash (
ngx eq ) et
less conn (
ngx lc )
Plusieurs tests ont été effectués.
- Petit script rapide (petit) .
<?php system('hostname');
- Le script avec un retard aléatoire (rand) .
<?php usleep(mt_rand(100000,200000)); echo "ok";
- Un script avec l'envoi d'une grande quantité de données (taille) .
<?php $size=$_GET['size']; $file='/tmp/'.$size; if (!file_exists($file)) { $dummy=""; exec ("dd if=/dev/urandom of=$file bs=$size count=1 2>&1",$dummy); } fpassthru (fopen($file,'rb'));
Les tailles suivantes ont été utilisées:
512.1440.1460.1480.1500.2048.65535.655350 octets.
Avant les tests, j'ai réchauffé les fichiers statiques de chaque séide.
Testé trois fois par test:
Au départ, j'avais prévu d'apporter le temps de test, les millisecondes et le reste, par conséquent je me suis arrêté à RPS - ils sont représentatifs et corrélés avec les indicateurs de temps.
A obtenu les résultats suivants:
Test de taille - colonnes - la taille des données données.

Comme vous pouvez le voir, le routage direct nft gagne par une énorme marge.
Je comptais sur quelques autres résultats liés à la taille de la trame Ethernet, mais aucune corrélation n'a été trouvée. Peut-être que 512 corps ne rentrent pas dans 1500 MTU, bien que, je doute, le petit test sera indicatif.
J'ai remarqué que sur les gros volumes (650k), nginx réduit la séparation. Cela a peut-être quelque chose à voir avec les tampons et la taille de TCP Windows.
Le résultat du test rand. Montre comment le moins conn gère dans des conditions de vitesse différente d'exécution de script sur différents serviteurs.
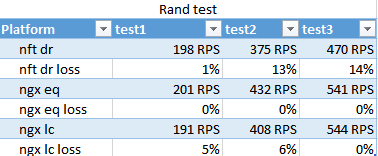
Étonnamment, le hachage nginx a fonctionné plus rapidement que le moins conn, et ce n'est que dans la dernière passe que le moins conn a pris un peu d'avance, ce qui ne prétend pas être significatif.
Le nombre de passes est très différent du fait que 100 threads partent immédiatement et le FPM-ok dès le début en charge environ 10. Au troisième passage, ils ont eu le temps de s'y habituer - ce qui montre l'applicabilité des stratégies pour les rafales.
NFT aurait perdu ce test. Nginx optimise bien l'interaction avec les FPM dans de telles situations.
petit test
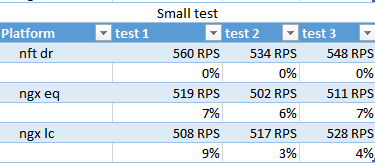
nft gagne marginalement sur RPS, moins conn est à nouveau un outsider.
Par ailleurs, dans ce test, on voit que 400-500RPS est émis, bien que, sur le test avec l'envoi de 512 octets, il était de 1500 - il semble que le système mange ce millier.
Conclusions
NFT a bien fonctionné dans une situation d'optimisation de charges uniformes: lorsque beaucoup de données sont fournies, que le temps de fonctionnement de l'application est déterminé et que les ressources du cluster sont suffisantes pour traiter le flux entrant sans entrer dans une chute.
Dans une situation où la charge sur chaque demande est chaotique et il est impossible d'équilibrer uniformément la charge du serveur avec le reste primitif de la division de hachage, le NFT perdra.