L'intérêt pour l'analyse d'images pour générer des recommandations augmente chaque jour. Nous avons décidé de comprendre à quel point ce thème tendance est réel. Nous parlons de tester l'utilisation du deep learning (Deep Learning) pour améliorer les recommandations des produits associés.

Dans cet article, nous décrivons l'expérience de l'application de la technologie d'analyse d'image pour améliorer l'algorithme des produits associés. Vous pouvez le lire de deux manières: ceux qui ne sont pas intéressés par les détails techniques de l'utilisation des réseaux de neurones peuvent ignorer les chapitres sur la création d'un ensemble de données et la mise en œuvre de solutions et aller directement aux tests AB et à leurs résultats. Et ceux qui ont une compréhension de base de concepts tels que les plongements, une couche d'un réseau de neurones, etc., seront intéressés par l'ensemble du matériel.
L'apprentissage en profondeur dans le contexte de l'analyse d'images
Dans notre pile technologique, le Deep Learning est utilisé avec succès pour résoudre certains problèmes. Pendant un certain temps, nous n'avons pas osé l'appliquer dans le contexte de l'analyse d'images, mais un certain nombre de prémisses sont récemment apparues qui ont changé d'avis:
- intérêt accru de la communauté pour l'analyse d'images à l'aide de méthodes d'apprentissage approfondi;
- un cercle de cadres «matures» et de réseaux de neurones pré-formés a été défini, à partir duquel on pouvait commencer assez rapidement et simplement;
- l'analyse d'image dans les systèmes de recommandation a souvent été utilisée comme une caractéristique marketing qui garantit des améliorations "sans précédent";
- les besoins alimentaires ont commencé à apparaître dans ce type de recherche.
Dans le contexte de l'intersection des systèmes de recommandation et de l'analyse d'images, il peut y avoir de nombreuses applications de l'apprentissage en profondeur, cependant, à la première étape, nous avons identifié pour nous-mêmes trois façons principales de développer ce domaine:
- Une amélioration générale de la qualité des recommandations, par exemple, des produits connexes pour une robe, est plus qualitativement appropriée en termes de couleur et de style.
- La recherche de produits dans la base de produits d'un magasin à l'aide d'une photographie (In Shop Retrieval) est un mécanisme qui vous permet de rechercher des produits dans la base de données d'un magasin à l'aide d'une photo chargée.
- Détermination des propriétés / attributs du produit à partir de la photo (marquage d'attributs), lorsque des attributs importants sont déterminés à partir de la photo, par exemple, le type de produit - un T-shirt, une veste, un pantalon, etc.
La direction la plus prioritaire et la plus prometteuse pour nous est la première option, et nous avons décidé de l'explorer.
Pourquoi avez-vous choisi un algorithme pour les produits associés
Tout système de recommandation possède deux algorithmes de base statiques: les alternatives et les produits associés. Et si tout est clair avec les alternatives - ce sont des produits similaires au modèle d'origine (par exemple, différents types de chemises), alors avec les produits connexes, tout est beaucoup plus compliqué. Il est important ici de ne pas se tromper avec la correspondance entre les produits de base et recommandés, par exemple, le chargeur doit s'adapter au téléphone, la couleur de la robe aux chaussures, etc.; vous devez tenir compte des commentaires, par exemple, ne pas recommander un téléphone au chargeur, malgré le fait qu'ils soient achetés ensemble; et réfléchir à un tas d'autres nuances qui se posent dans la pratique. En grande partie en raison de la présence de diverses nuances, notre choix s'est porté sur des produits connexes. De plus, ce n'est que dans les produits connexes qu'il est possible de former un look à part entière, si nous parlons du segment de la mode.
Nous avons formulé notre principal objectif de recherche comme «Comprendre si l'algorithme actuel pour les produits connexes peut être considérablement amélioré en utilisant des méthodes d'apprentissage approfondi pour l'analyse d'images»
Je note qu'avant cela, nous n'utilisions pas du tout les informations d'image lors du calcul des recommandations de produits, et voici pourquoi:
- Au cours de l'existence de la plateforme Retail Rocket, nous avons acquis une grande expertise dans le domaine des recommandations de produits. Et la principale conclusion que nous avons reçue pendant cette période est que l'utilisation correcte du comportement des utilisateurs fournit près de 90% du résultat. Oui, il y a le problème d'un démarrage à froid, quand ce sont des choses de contenu, telles que des informations sur l'image, qui peuvent clarifier ou améliorer les recommandations, mais en pratique cet effet est beaucoup moins que ce qu'ils disent en théorie. Par conséquent, nous n'accordons pas beaucoup d'importance aux sources de contenu d'information.
- Pour élaborer des recommandations de produits sous forme d'informations sur le contenu, nous utilisons des éléments tels que le prix, la catégorie, la description et d'autres propriétés que le magasin nous transmet. Ces propriétés sont indépendantes de la sphère et sont validées qualitativement lors de l'intégration de notre service. La valeur de l'image, au contraire, n'apparaît en fait que dans le segment des articles de mode.
- Maintenir le service de travailler avec des images, valider leur qualité et leur conformité aux marchandises est un processus assez compliqué et un sérieux devoir technique que je ne voulais pas encourir sans confirmation du besoin.
Néanmoins, nous avons décidé de donner une chance aux photos et de voir comment elles affecteront l'efficacité des recommandations de construction. Notre approche n'est pas idéale, c'est sûr que quelqu'un résoudrait le problème différemment. L'objectif de cet article est de présenter notre démarche avec une description des arguments à chaque étape et de présenter les résultats au lecteur.
Formation du concept
Nous avons commencé par croiser les trois composantes de tout produit: une technologie abordable, les ressources disponibles et les besoins des clients. Le concept d '«amélioration des recommandations par des informations sur l'image des produits associés» s'est développé de lui-même. L'implémentation «idéale» de ce produit a été formée comme un problème compilé à l'image d'un look sélectionné. De plus, de telles recommandations devraient non seulement avoir fière allure, mais également fonctionner du point de vue des métriques de base du commerce électronique (Conversion, RPV, AOV) pas pire que notre algorithme de base.
Le look est une image choisie par les stylistes, qui comprend un ensemble de choses différentes se combinant entre elles, par exemple une robe, une veste, un sac, une ceinture, etc. Du côté de nos clients, ce travail est généralement effectué par des personnes spécialement désignées dont le travail est mal automatisé. Après tout, tous les réseaux de neurones ne peuvent pas avoir un sens du goût.
 Un exemple d'image (regardez).
Un exemple d'image (regardez).Immédiatement, il y avait des restrictions sur l'utilisation des informations d'image - en fait, l'application n'a été trouvée que dans le segment de la mode.
Infrastructure et ensemble de données
Tout d'abord, nous avons créé un banc d'essai pour les expériences et le prototypage. Tout est assez standard GPU + Python + Keras ici, donc nous n'entrerons pas dans les détails. Nous avons trouvé un ensemble de données de haute qualité conçu pour résoudre plusieurs problèmes à la fois, de la prédiction des attributs de l'image à la génération de nouvelles textures de vêtements. Ce qui était particulièrement important pour nous, il comprenait des photographies qui constituaient pratiquement un seul regard. En outre, l'ensemble de données comprenait des photographies de modèles de vêtements sous différents angles, que nous avons essayé d'utiliser dans la première étape.
 Exemple de look à partir d'un ensemble de données.
Exemple de look à partir d'un ensemble de données. Exemples d'images du même modèle de vêtements sous différents angles.
Exemples d'images du même modèle de vêtements sous différents angles.Premiers pas
La première idée d'implémenter le produit final à l'aide de l'ensemble de données était assez simple: «Réduisons le problème à la tâche de reconnaître les vêtements par image. Ainsi, lors de la formulation des recommandations, nous «relèverons» les recommandations similaires au produit de base. » En conséquence, il était censé trouver la fonction de «proximité» des marchandises et, en cours de route, résoudre le problème de l'élimination des alternatives dans le problème.
Je dois dire tout de suite que ce type de problème pourrait être résolu en utilisant un réseau neuronal pré-formé conventionnel, tel que ResNet-50. En effet: on retire la dernière couche, on obtient des plongements, enfin, puis le cosinus, comme mesure de «proximité». Cependant, après avoir expérimenté un peu cette approche, nous avons décidé de la laisser principalement pour trois raisons.
- Il n'est pas très clair comment interpréter correctement la proximité qui en résulte. Qu'est-ce que le cosinus = 0,7 dans le domaine des t-shirts, où en règle générale tout est très similaire et qu'est-ce que le cosinus = 0,5 dans le domaine des vestes, où les différences sont plus importantes. Nous avions besoin de ce type d'interprétation afin d'éliminer simultanément les produits très proches - alternatives.
- Cette approche nous a un peu limités du point de vue de la formation continue pour nos tâches spécifiques. Par exemple, les caractéristiques importantes qui forment une image holistique ne sont pas toujours les mêmes d'un domaine à l'autre. Quelque part, la couleur et la forme sont plus importantes, mais quelque part le matériau et sa texture. De plus, nous voulions former le réseau à faire moins d'erreurs de genre lorsque les femmes sont recommandées pour les vêtements pour hommes. Une telle erreur est immédiatement évidente et doit être rencontrée aussi rarement que possible. Avec la simple utilisation de réseaux neuronaux pré-entraînés, il nous a semblé que nous étions un peu limités par l'incapacité à fournir des exemples bien «similaires» en termes d'image.
- L'utilisation de réseaux siamois, plus adaptés à ces tâches, semblait être une option plus naturelle et bien étudiée.
Un peu sur le réseau neuronal siamois
Les réseaux de neurones siamois sont largement utilisés pour résoudre les tâches liées à la reconnaissance faciale. En entrée, une image de la personne est fournie, en sortie, le nom de la personne de la base de données à laquelle elle appartient. Un tel problème peut être résolu directement, si vous utilisez softmax et le nombre de classes égal au nombre de personnes reconnaissables sur la dernière couche du réseau neuronal. Cependant, cette approche a plusieurs limites:
- vous devez avoir un nombre d'images suffisamment grand pour chaque classe, ce qui est pratiquement impossible.
- un tel réseau de neurones devra être recyclé chaque fois qu'une nouvelle personne est ajoutée à la base de données, ce qui est très gênant.
Une solution logique dans une telle situation serait d'obtenir la fonction de «similitude» des deux photos afin de répondre à tout moment si les deux photos - fournies à l'entrée du réseau neuronal et à la référence de la base de données - appartiennent à la même personne et, en conséquence, résolvent le problème de reconnaissance faciale. Cela correspond mieux à la façon dont une personne se comporte. Par exemple, un gardien regarde le visage d’une personne et une photo sur un badge et répond à la question de savoir si cette personne en est une ou non. Le réseau neuronal siamois met en œuvre un concept similaire.
Le composant principal du réseau de neurones siamois est le réseau de neurones du squelette, qui produit une intégration d'images. Cette intégration peut être utilisée pour déterminer le degré de similitude entre les deux images. Dans l'architecture du réseau neuronal siamois, le composant de squelette est utilisé deux fois, à chaque fois pour recevoir l'incorporation de l'image. Le chercheur doit afficher les valeurs de sortie 0 ou 1, selon qu'une personne ou des personnes différentes possèdent les photos, et ajuster le réseau neuronal du squelette.
 Un exemple de réseau neuronal siamois. Les plongements des images supérieures et inférieures sont obtenus à partir de l'épine dorsale du réseau neuronal. Image tirée du cours «Réseaux neuronaux convolutionnels» d'Andrey Ng.
Un exemple de réseau neuronal siamois. Les plongements des images supérieures et inférieures sont obtenus à partir de l'épine dorsale du réseau neuronal. Image tirée du cours «Réseaux neuronaux convolutionnels» d'Andrey Ng.Solution basique
Ainsi, après quelques expérimentations, la première version de l'algorithme était la suivante:
- Nous prenons tout réseau neuronal pré-formé comme colonne vertébrale. Nous avons expérimenté avec ResNet-50 et InceptionV3. Sélectionné sur la base de l'équilibre de la taille du réseau et de la précision des prévisions. Nous nous sommes concentrés sur les données présentées dans la documentation officielle de la section Keras «Documentation pour les modèles individuels».
- Nous créons un réseau siamois sur cette base et utilisons Triplet Loss pour la formation.
- À titre d'exemples positifs, nous servons la même image, mais sous un angle différent. À titre d'exemple négatif, nous servons un autre produit.
- Ayant un modèle formé, nous obtenons la métrique de proximité pour n'importe quelle paire de produits de la même manière que la perte de triplet est considérée.
Code de calcul de perte de triplet.L'accord avec Triplet Loss sur un projet réel était la première fois, ce qui a créé un certain nombre de difficultés. Au début, ils ont longtemps lutté avec le fait que les intégrations reçues se résumaient toutes à un point. Il y avait plusieurs raisons: nous n'avons pas normalisé les plongements avant de calculer la perte; marge le paramètre alpha était trop petit et les exemples trop difficiles. La normalisation et les intégrations ajoutées ont commencé à varier. Le deuxième problème est devenu de façon inattendue l'explosion du gradient. Heureusement, Keras a permis de résoudre ce problème tout simplement - nous avons ajouté clipnorm = 1.0 à l'optimiseur, ce qui n'a pas permis aux gradients de croître pendant l'entraînement.
Le travail était itératif: nous avons formé le modèle, réduit la perte, regardé le résultat final et décidé de manière experte dans quelle direction nous allions. À un moment donné, il est devenu clair que nous avons immédiatement mis en place des exemples assez complexes et la complexité ne change pas dans le processus d'apprentissage, ce qui affecte négativement le résultat final. Heureusement, l'ensemble de données avec lequel nous avons travaillé avait une bonne arborescence qui reflétait le produit lui-même, par exemple Hommes -> Pantalons, Hommes -> Pulls, etc. Cela nous a permis de refaire le générateur et nous avons commencé à donner des exemples «faciles» pour les premières époques, puis plus complexes et ainsi de suite. Les exemples les plus difficiles sont les produits de la même catégorie de produits, par exemple les pantalons, comme négatifs.
En conséquence, nous avons obtenu un modèle dont la sortie différait de la méthodologie «naïve» pour l'utilisation de ResNet-50. Cependant, la qualité des recommandations finales ne nous convenait pas complètement. Premièrement, il y avait un problème avec les erreurs de genre, mais on comprenait comment le résoudre. Étant donné que l'ensemble de données divisait les vêtements en hommes et femmes, il était facile de collecter des exemples négatifs pour la formation. Deuxièmement, lors de la formation sur l'ensemble de données, le résultat final, nous avons vérifié visuellement nos clients - il est immédiatement devenu clair qu'il était nécessaire de se recycler sur leurs exemples, car pour certains, l'algorithme fonctionnait très mal si les marchandises ne se chevauchaient pas bien avec ce qui était montré pendant la formation. . Enfin, la qualité était souvent médiocre, car l'image d'entraînement était souvent bruyante et contenait, par exemple, non seulement un jean, mais aussi un t-shirt.
 L'image d'un jean sur lequel on voit en fait aussi un T-shirt et des bottes.
L'image d'un jean sur lequel on voit en fait aussi un T-shirt et des bottes.La première expérience a servi de base à la solution suivante, même si nous n'avons pas immédiatement commencé à mettre en œuvre un modèle amélioré.
 Un exemple de recommandations basées sur une solution de base. Il y a des erreurs de genre, des alternatives se présentent également.
Un exemple de recommandations basées sur une solution de base. Il y a des erreurs de genre, des alternatives se présentent également.Modèle amélioré
Nous avons commencé par former ResNet-50 sur les données de notre ensemble de données. L'ensemble de données contient des informations sur ce qui est montré dans l'image. Il est extrait de la structure du jeu de données Hommes -> Pantalons, Femmes -> Cardigans et plus. Cette procédure a été effectuée pour deux raisons: premièrement, ils voulaient «diriger» l'épine dorsale - un réseau neuronal vers le domaine de l'habillement; deuxièmement, comme les vêtements sont également divisés par sexe, ils espéraient se débarrasser du problème des erreurs de genre rencontrées dans la première version.
À la deuxième étape, nous avons essayé d'éliminer simultanément le bruit des images d'entrée et d'obtenir des paires positives de produits connexes pour une formation plus approfondie. L'ensemble de données que nous utilisons est également conçu pour résoudre le problème de détection d'objets dans l'image. Autrement dit, pour chaque image il y a: les coordonnées du rectangle qui décrit l'objet et sa classe. Pour résoudre ce genre de problème, nous avons utilisé un
projet prêt à l'emploi . Ce projet utilise l'architecture de réseau neuronal RetinaNet en utilisant une perte focale spéciale. L'essence de cette perte est de se concentrer davantage non pas sur le fond de l'image, qui se trouve dans presque toutes les images, mais sur l'objet qui doit être détecté. En tant que colonne vertébrale d'un réseau de neurones pour la formation, nous avons utilisé notre réseau pré-formé ResNet-50.
En conséquence, trois classes d'objets sont détectées sur chaque image du jeu de données: «haut», «bas» et «vue générale». Après avoir défini les classes «supérieure» et «inférieure», nous coupons simplement l'image en deux images distinctes, qui seront plus tard utilisées comme une paire d'exemples positifs pour calculer la perte de triplet. La qualité de détection des objets s'est avérée assez élevée, le seul reproche était qu'il n'était pas toujours possible de trouver une classe dans l'image. Ce n'était pas un problème pour nous, car nous pouvions facilement augmenter le nombre d'images pour les prédictions.
 Un exemple de détection des classes «haut» et «bas» et découpe de l'image.
Un exemple de détection des classes «haut» et «bas» et découpe de l'image.Avec ce type de séparateur d'images, nous avons eu l'occasion de jeter un coup d'œil sur Internet et de le diviser en composants pour une utilisation dans la formation. Pour augmenter l'échantillon de formation et vaincre le problème avec une couverture insuffisante des exemples survenus lors du développement de la solution de base, nous avons élargi l'ensemble de données en raison des images «coupées» d'un de nos clients. Le seul problème était que nous ne distinguions pas des objets tels que "accessoire", "coiffure", "chaussures" et ainsi de suite. Cela a créé quelques limitations, mais il convenait parfaitement pour tester le concept. Après avoir reçu des résultats positifs, nous avons prévu d'étendre le modèle aux classes décrites ci-dessus.
Après avoir reçu un ensemble de données étendu, nous avons utilisé la méthodologie déjà éprouvée pour construire le réseau siamois à partir d'une solution de base, bien qu'il y ait plusieurs différences. Premièrement, en tant que colonne vertébrale du réseau neuronal, nous avons utilisé le réseau ResNet-50 maintenant formé décrit ci-dessus. Deuxièmement, maintenant, comme exemples positifs, nous avons soumis des paires de haut en bas et vice versa, nous permettant d'apprendre du réseau neuronal exactement la «correspondance» de l'image. Eh bien, en fait une douzaine d'époques plus tard, un mécanisme est apparu qui nous a permis d'évaluer la «conformité» des marchandises à une seule image.
 Un exemple de recommandations basées sur l'utilisation d'un réseau neuronal. Les shorts sont recommandés pour le produit de base; les t-shirts sont recommandés.
Un exemple de recommandations basées sur l'utilisation d'un réseau neuronal. Les shorts sont recommandés pour le produit de base; les t-shirts sont recommandés.Le résultat final nous a plu: les recommandations se sont avérées visuellement de bonne qualité et, ce qui est particulièrement bon, leur construction n'a nécessité aucun historique d'interactions avec les utilisateurs. Cependant, des problèmes subsistaient, le principal étant la disponibilité d'alternatives dans le cadre de l'extradition. Il y a donc eu des extraditions dans lesquelles le «bas» a été recommandé au «bas», la même chose s'est produite avec la catégorie «haut». Cela nous a fait réfléchir et affiner la solution pour supprimer les alternatives.
Supprimer les alternatives
Pour résoudre le problème de la disponibilité d'alternatives, l'émission a été assez rapide. Les premières expériences avec le ResNet-50 «vanille» ont aidé. Un tel réseau de neurones a donné comme biens «similaires» ceux qui coïncidaient le plus dans l'image - en fait, des alternatives. Autrement dit, il pourrait être utilisé pour identifier des alternatives.
 Un exemple de recommandations basées sur le ResNet-50 «vanille». Les marchandises sont des alternatives.
Un exemple de recommandations basées sur le ResNet-50 «vanille». Les marchandises sont des alternatives.En utilisant cette propriété utile de ResNet-50, nous avons commencé à filtrer le plus près possible les produits de l'émission, éliminant ainsi les alternatives. Il y avait aussi des inconvénients de cette approche - la même situation incompréhensible avec quel seuil choisir pour le filtrage. Parfois, un grand nombre de produits étaient filtrés, bien qu'ils ne soient pas apparemment des alternatives. Cependant, nous ne nous sommes pas concentrés sur ce problème et avons continué à travailler davantage.
Préparation des tests AB
Pour la vérification finale de pratiquement tout changement dans les algorithmes, nous utilisons largement l'outil de test AB. De plus, nous n'avons qu'une seule règle: «quelle que soit la taille de la perte, quelle que soit la complexité et la multiplicité du réseau neuronal, la beauté des recommandations - tout cela n'est pas pris en compte s'il n'y a pas de résultat au test AB». La logique est assez simple: un test AB est le plus honnête, compréhensible pour toutes les parties (en particulier les clients et les entreprises) et une méthode précise pour mesurer le résultat. Retail Rocket - ( «
A/- 99% - ? »). - .
-. ,
RecSys 2016 . . , , , , . , - , .
, . , . , . - . , , , , - . : .
- , . -, , , , . -, — , , , , . , . , , , “», .
:
- “” “”, , , , . , , , .
- , . proof-of-concept , .
, , . , , .
AB-
, , - . — fashion. . , , . , , .
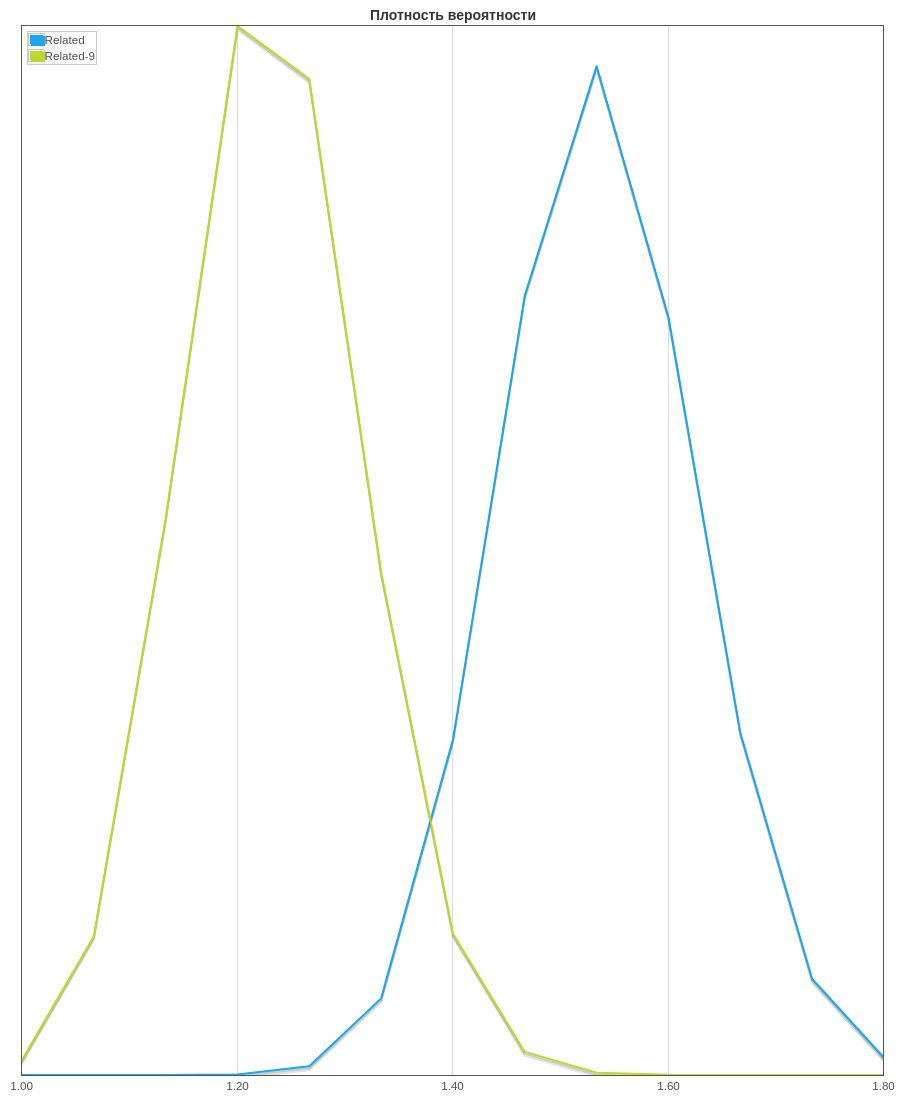
. 3 . , 95%.
 . Related-9 — “” , Related — .
. Related-9 — “” , Related — . . Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.
. Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.: . , , , “” CTR. , , CTR , . - , - - , -. , .
 CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%.
CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%., , , , . , , . , , . .
, , . , , . - . , — — , . , . , , , Retail Rocket.
, , , , « ». , . , .
, Retail Rocket