Vous êtes-vous déjà demandé à quoi ressemblent les données avec lesquelles vous travaillez dans les entrailles de Python? À propos de la façon dont les variables sont créées et stockées en mémoire? Comment et quand sont-ils retirés? Le matériel, dont nous publions la traduction, est consacré à la recherche dans les profondeurs de Python, au cours de laquelle nous essaierons de découvrir les caractéristiques de la gestion de la mémoire dans ce langage. Après avoir étudié cet article, vous comprendrez comment fonctionnent les mécanismes de bas niveau des ordinateurs, en particulier ceux liés à la mémoire. Vous comprendrez comment Python résume les opérations de bas niveau et comment il gère la mémoire.

Savoir ce qui se passe en Python vous permettra de mieux comprendre certains comportements de ce langage. J'espère que cela vous donnera l'occasion d'apprécier l'énorme travail qui est fait dans la mise en œuvre de ce langage que vous utilisez pour que vos programmes fonctionnent exactement comme vous en avez besoin.
La mémoire est un livre vide
La mémoire de l'ordinateur, au tout début de son utilisation, peut être représentée sous la forme d'un livre vide destiné à des histoires courtes. Bien qu'il n'y ait rien sur ses pages, mais très bientôt des auteurs d'histoires apparaîtront, chacun voulant écrire sa propre histoire dans ce livre.
Puisqu'une histoire ne peut pas être écrite au-dessus d'une autre, les auteurs doivent faire attention aux pages du livre sur lesquelles ils écrivent. Avant d'écrire quoi que ce soit, ils consultent le rédacteur en chef. Il décide où exactement les auteurs peuvent enregistrer des histoires.
Étant donné que le livre dont nous parlons existe depuis un certain temps, de nombreuses histoires qu'il contient sont déjà dépassées. Si personne ne lit une histoire ou ne la mentionne dans ses œuvres, cette histoire est supprimée du livre, laissant place à de nouvelles histoires.
En général, nous pouvons dire que la mémoire de l'ordinateur est très similaire à un tel livre. En fait, des blocs continus de mémoire d'une longueur fixe sont même appelés pages, nous pensons donc que la comparaison de la mémoire avec un livre est très réussie.
Les auteurs qui écrivent leurs histoires dans un livre sont différentes applications ou processus qui doivent stocker des données en mémoire. Le rédacteur en chef, qui décide sur quelles pages du livre les auteurs peuvent écrire, est le mécanisme qui traite de la gestion de la mémoire. Et celui qui supprime les vieilles histoires du livre, faisant de la place pour les nouvelles, peut être comparé au mécanisme de collecte des ordures.
Gestion de la mémoire: le chemin du fer aux programmes
La gestion de la mémoire est un processus au cours duquel les programmes écrivent des données dans la mémoire et les lisent. Un gestionnaire de mémoire est une entité qui détermine où exactement une application peut placer ses données en mémoire. Étant donné que le nombre de fragments de mémoire pouvant être alloués aux applications n'est pas infini, tout comme le nombre de pages dans un livre n'est pas infini, le gestionnaire de mémoire, au service des applications, doit trouver des fragments de mémoire libres et les fournir aux applications. Ce processus, dans lequel la mémoire est allouée aux applications, est appelé allocation de mémoire.
En revanche, lorsque certaines données ne sont plus nécessaires, elles peuvent être supprimées ou, en d'autres termes, libérer la mémoire qu'elles occupent. Mais qu'est-ce qu'ils «isolent» et «libèrent» exactement en parlant de mémoire?
Quelque part sur votre ordinateur, il existe un périphérique physique qui stocke les données utilisées par les programmes Python pendant leur fonctionnement. Avant qu'un objet Python n'apparaisse dans la mémoire physique, le code doit passer par plusieurs couches d'abstraction.
L'une des principales couches de ce type, située au-dessus du matériel (comme la RAM ou le disque dur) est le système d'exploitation (OS). Il exécute (ou refuse de répondre) aux demandes de lecture des données de la mémoire et d'écriture des données dans la mémoire.
Il existe une application au-dessus du système d'exploitation, dans notre cas, l'une des implémentations de Python (il peut s'agir d'un progiciel qui fait partie de votre système d'exploitation ou qui est téléchargé depuis
python.org ). C'est ce progiciel qui est engagé dans la gestion de la mémoire, assurant le fonctionnement de votre code Python. Cet article se concentre sur les algorithmes et les structures de données que Python utilise pour gérer la mémoire.
Implémentation de référence Python
L'implémentation de référence Python est appelée CPython. Il est écrit en C. Lorsque j'en ai entendu parler pour la première fois, cela m'a littéralement perturbé. Un langage de programmation écrit dans un autre langage? Eh bien, en fait, ce n'est pas entièrement vrai.
La spécification Python est décrite en anglais simple dans
ce document . Cependant, cette spécification seule, le code écrit en Python, bien sûr, ne peut pas s'exécuter. Pour ce faire, vous avez besoin de quelque chose qui, suivant les règles de cette spécification, peut interpréter le code écrit en Python.
De plus, vous avez besoin de quelque chose qui puisse exécuter le code interprété sur l'ordinateur. L'implémentation de référence Python résout ces deux tâches. Il convertit le code en instructions qui sont ensuite exécutées sur la machine virtuelle.
Les machines virtuelles sont similaires aux ordinateurs ordinaires en silicium, métal et autres matériaux, mais elles sont implémentées dans un logiciel. Ils sont généralement occupés à traiter des instructions de base, similaires aux instructions écrites dans
Assembler .
Python est un langage interprété. Le code écrit en Python est compilé en un ensemble d'instructions pratiques pour l'ordinateur, dans ce que l'on appelle le
code d'octets . Ces instructions sont interprétées par la machine virtuelle lorsque vous exécutez votre programme.
Avez-vous déjà vu des fichiers avec l'extension
.pyc ou le dossier
__pycache__ ? Ils contiennent le même bytecode qui est interprété par la machine virtuelle.
Il est important de noter qu’en plus de CPython, il existe d’autres implémentations Python. Par exemple, lorsque vous utilisez
IronPython, le code Python est compilé dans une instruction Microsoft CLR. En
Jython, le code est compilé en bytecode Java et exécuté dans une machine virtuelle Java. Dans le monde Python, il existe une chose telle que
PyPy , mais elle mérite un article séparé, alors ici nous venons de le mentionner.
Aux fins de cet article, je me concentrerai sur le fonctionnement des mécanismes de gestion de la mémoire dans l'implémentation de référence Python - CPython.
Il convient de noter que bien que la plupart de ce dont nous allons parler ici soit vrai pour les nouvelles versions de Python, les choses peuvent changer à l'avenir. Par conséquent, faites attention au fait que dans cet article, je me concentre sur la dernière version de Python au moment de la rédaction -
Python 3.7 .
Ainsi, le progiciel CPython est écrit en C, il interprète le bytecode Python. Qu'est-ce que cela a à voir avec la gestion de la mémoire? Le fait est que les algorithmes et les structures de données utilisés pour la gestion de la mémoire existent dans du code CPython écrit, comme déjà mentionné, en C.Pour comprendre comment fonctionne la gestion de la mémoire en Python, vous devez d'abord comprendre un peu le CPython.
Le langage C dans lequel CPython est écrit n'a pas de support intégré pour la programmation orientée objet. Pour cette raison, de nombreuses solutions architecturales intéressantes sont utilisées dans le code CPython.
Vous avez peut-être entendu dire que tout en Python est un objet, même les types de données primitifs comme
int et
str . Et c'est effectivement le cas au niveau de l'implémentation du langage dans CPython. Il existe une structure appelée
PyObject , qui est utilisée par les objets créés dans CPython.
Une structure est un type de données composite qui peut regrouper des données de différents types. Si vous comparez cela à une programmation orientée objet, la structure est similaire à une classe qui a des attributs mais pas de méthodes.
PyObject est l'ancêtre de tous les objets Python. Cette structure ne contient que deux champs:
ob_refcnt - compteur de références.ob_type - pointeur vers un autre type.
Le compteur de référence est utilisé pour implémenter le mécanisme de récupération de place. Un autre champ
PyObject est un pointeur sur un type d'objet spécifique. Ce type est représenté par une autre structure qui décrit l'objet Python (par exemple, il peut s'agir d'un type
dict ou
int ).
Chaque objet a son propre mécanisme d'allocation de mémoire, unique pour un tel objet, qui sait comment obtenir la mémoire nécessaire pour stocker cet objet. De plus, chaque objet possède son propre mécanisme de libération de mémoire, qui «libère» la mémoire lorsqu'elle n'est plus nécessaire.
Cependant, il convient de noter que dans toutes ces conversations sur l'allocation et la libération de mémoire, il y a un facteur important. Le fait est que la mémoire de l'ordinateur est une ressource partagée. Si, en même temps, deux processus différents essaient d'écrire quelque chose dans la même zone de mémoire, quelque chose de mauvais peut se produire.
Interprète Global Lock
Global Interpreter Lock (GIL) est une solution à un problème courant qui se produit lorsque vous travaillez avec des ressources informatiques partagées telles que la mémoire. Lorsque deux threads tentent de modifier simultanément la même ressource, ils peuvent «entrer en collision» l'un avec l'autre. Le résultat sera un gâchis et aucun des flux n'atteindra ses objectifs.
Revenons à l'analogie du livre. Imaginez que deux auteurs aient décidé arbitrairement que maintenant c'était à leur tour de prendre des notes. Mais ils ont également décidé de prendre des notes simultanément sur la même page.
Chacun d'eux ne fait pas attention au fait que l'autre essaie d'écrire son histoire. Ensemble, ils commencent à écrire du texte sur la page. En conséquence, deux histoires y seront enregistrées, l'une au-dessus de l'autre, ce qui rendra la page complètement illisible.
L'une des solutions à ce problème est un mécanisme d'interpréteur global unique qui bloque les ressources partagées avec lesquelles un certain thread travaille. Dans notre exemple, il s'agit d'un «mécanisme» qui «bloque» la page d'un livre. Un tel mécanisme élimine la situation décrite ci-dessus, dans laquelle deux auteurs écrivent simultanément du texte sur la même page.
Le mécanisme GIL en Python accomplit cela en bloquant l'intégralité de l'interpréteur. Par conséquent, rien ne peut interférer avec le fonctionnement du thread actuel. Et lorsque CPython travaille avec de la mémoire, il utilise le GIL pour s'assurer que ce travail est effectué en toute sécurité et efficacement.
Il y a des forces et des faiblesses à cette approche, et le GIL fait l'objet d'un débat acharné dans la communauté Python. Pour en savoir plus sur GIL, vous pouvez consulter
ce matériel .
Collecte des ordures
Revenons à l'analogie du livre et imaginons que certaines des histoires enregistrées dans ce livre sont désespérément obsolètes. Personne ne les lit, personne ne les mentionne nulle part. Et si personne ne lit ou ne se réfère à certains documents dans leurs œuvres, alors ces documents peuvent être éliminés, laissant la place à de nouveaux textes.
Ces vieux contes oubliés peuvent être comparés à des objets Python dont le nombre de références est nul. Ce sont les mêmes compteurs dont nous avons parlé lors de la discussion sur la structure
PyObject .
Le compteur de liens est incrémenté pour plusieurs raisons. Par exemple, le compteur est incrémenté si l'objet stocké dans une variable est écrit dans une autre variable:
numbers = [1, 2, 3]
Il augmente lorsque l'objet est passé à une fonction en tant qu'argument:
total = sum(numbers)
Et voici un autre exemple d'une situation dans laquelle le nombre dans le compteur de référence augmente. Cela se produit si l'objet est inclus dans la liste:
matrix = [numbers, numbers, numbers]
Python permet au programmeur de découvrir la valeur actuelle du compte de référence d'un certain objet en utilisant le module
sys . Pour cela, la construction suivante est utilisée:
sys.getrefcount(numbers)
getfefcount() , vous devez vous rappeler que le passage d'un objet à la méthode
getfefcount() augmente la valeur du compteur de 1.
Dans tous les cas, si l'objet est toujours utilisé quelque part dans le code, son compteur de référence sera supérieur à 0. Lorsque la valeur du compteur chute à 0, une fonction spéciale entre en jeu, ce qui "libère" la mémoire occupée par l'objet. Cette mémoire peut ensuite être utilisée par d'autres objets.
Nous nous posons maintenant des questions sur ce qu'est la «libération de mémoire» et sur la manière dont d'autres objets peuvent utiliser cette mémoire. Afin de répondre à ces questions, parlons des mécanismes de gestion de la mémoire dans CPython.
Mécanismes de gestion de la mémoire dans CPython
Nous allons maintenant parler de la façon dont CPython possède une architecture de mémoire et de la façon dont la gestion de la mémoire s'y fait.
Comme déjà mentionné, il existe plusieurs couches d'abstraction entre CPython et la mémoire physique. Le système d'exploitation extrait la mémoire physique et crée une couche de mémoire virtuelle avec laquelle les applications peuvent travailler (cela s'applique également à Python).
Le gestionnaire de mémoire virtuelle d'un système d'exploitation spécifique alloue un morceau de mémoire pour le processus Python. Les zones gris foncé dans l'image suivante sont les morceaux de mémoire qui appartiennent au processus Python.
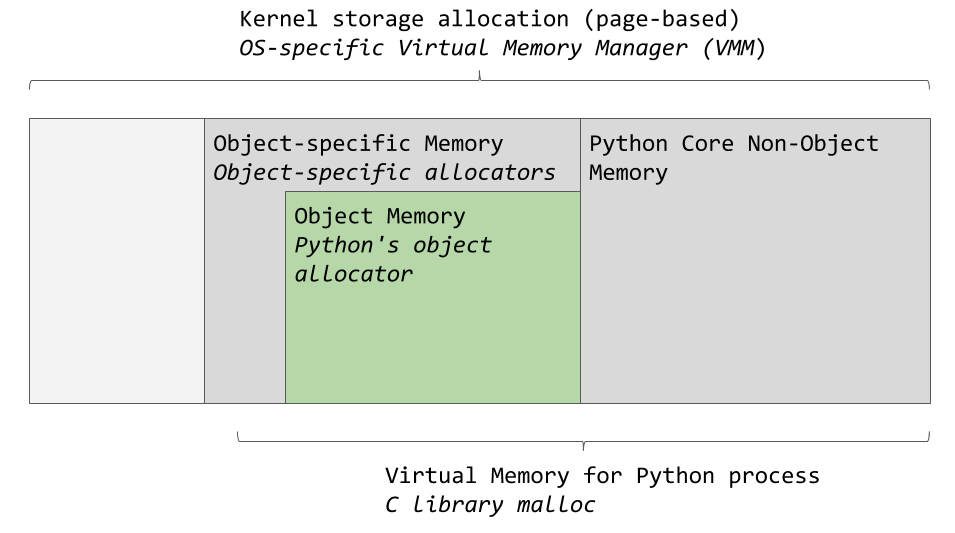 Zones de mémoire utilisées par CPython
Zones de mémoire utilisées par CPythonPython utilise une certaine quantité de mémoire pour un usage interne et pour des besoins non liés à l'allocation de mémoire aux objets. Un autre morceau de mémoire est utilisé pour stocker des objets (ce sont des valeurs de types
int ,
dict et autres comme ça). Veuillez noter qu'il s'agit d'un schéma simplifié. Si vous voulez voir l'image complète, jetez un oeil au code source de
CPython , où tout ce dont nous parlons se passe.
CPython dispose d'une fonction d'allocation de mémoire pour les objets, qui est responsable de l'allocation de mémoire dans la zone destinée au stockage des objets. La chose la plus intéressante se produit lorsque ce mécanisme fonctionne. Elle est appelée lorsque l'objet a besoin de mémoire ou dans les cas où la mémoire doit être libérée.
En règle générale, l'ajout ou la suppression de données à des objets Python tels que
list et
int n'implique pas le traitement simultané de très grandes quantités d'informations. Par conséquent, l'architecture de l'outil d'allocation de mémoire est conçue en tenant compte du traitement de petites quantités de données. De plus, cet outil cherche à ne pas allouer de mémoire jusqu'à ce qu'il devienne clair qu'elle est absolument nécessaire.
Les commentaires dans le
code source décrivent l'outil d'allocation de mémoire comme "un outil d'allocation de mémoire rapide et spécialisé pour les petits blocs qui est conçu pour être utilisé au-dessus du malloc universel." Dans ce cas,
malloc est une fonction de bibliothèque C conçue pour allouer de la mémoire.
Discutons de la stratégie d'allocation de mémoire utilisée par CPython. Tout d'abord, nous parlerons de trois entités - les soi-disant blocs (blocs), les piscines (pools) et les arènes (arène), et comment ils sont liés les uns aux autres.
Les arènes sont les plus grands fragments de mémoire. Ils sont alignés sur les bordures des pages de mémoire. La limite de page est l'endroit où le bloc continu de mémoire de longueur fixe finit par être utilisé par le système d'exploitation. Python, tout en travaillant avec la mémoire, suppose que la taille de la page de mémoire système est de 256 Ko.
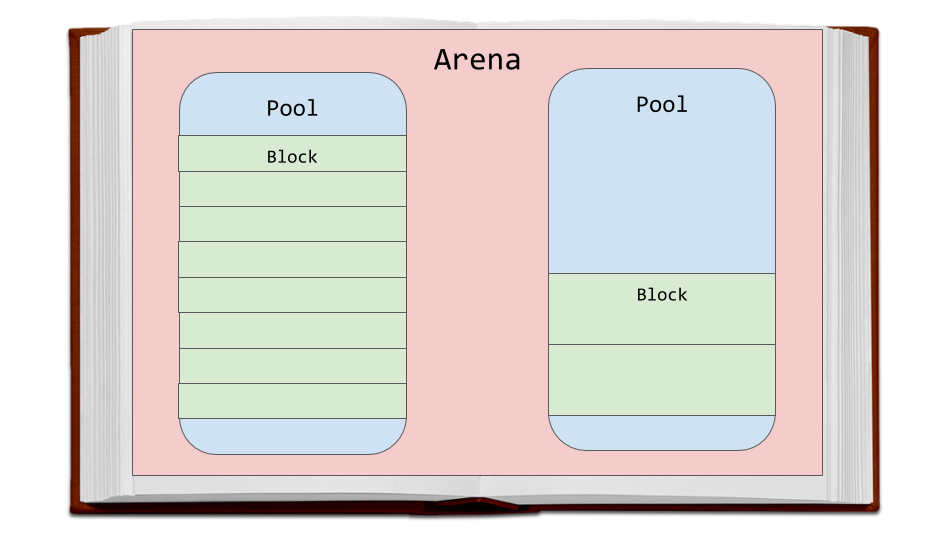 Arénas, piscines et blocs
Arénas, piscines et blocsLes pools sont situés sur les arènes, qui sont des pages de mémoire virtuelle de 4 Ko. Ils ressemblent aux pages du livre de notre exemple. Les pools sont divisés en petits blocs de mémoire.
Tous les blocs d'un même pool appartiennent à la même classe de taille. La classe de taille à laquelle appartient le bloc détermine la taille de ce bloc, qui est sélectionnée en tenant compte de la taille de mémoire demandée. Voici un tableau extrait du code source qui montre la quantité de données que le système demande de stocker en mémoire, les tailles des blocs alloués et les identificateurs des classes de taille.
La quantité de données en octets
| Taille de bloc
| taille de la classe idx
|
1-8
| 8
| 0
|
9-16
| 16
| 1
|
17-24
| 24
| 2
|
25-32
| 32
| 3
|
33-40
| 40
| 4
|
41-48
| 48
| 5
|
49-56
| 56
| 6
|
57-64
| 64
| 7
|
65-72
| 72
| 8
|
...
| ...
| ...
|
497-504
| 504
| 62
|
505-512
| 512
| 63
|
Par exemple, si 42 octets doivent être stockés, les données seront placées dans un bloc de 48 octets.
Piscines
Les pools sont constitués de blocs appartenant à la même classe de taille. Chaque pool est associé à d'autres pools contenant des blocs de la même classe de taille à l'aide du mécanisme de liste doublement lié. Avec cette approche, l'algorithme d'allocation de mémoire peut facilement trouver de l'espace libre pour un bloc d'une taille donnée, même s'il s'agit de trouver de l'espace libre dans différents pools.
La liste des
usedpools vous permet de garder une trace de tous les pools dans lesquels il y a de la place pour les données appartenant à une classe de taille particulière. Lorsqu'il est demandé d'enregistrer un bloc d'une certaine taille, l'algorithme recherche dans cette liste une liste de pools qui stockent des blocs de la taille requise.
Les piscines elles-mêmes doivent être dans l'un des trois états. À savoir, ils peuvent être utilisés (état
used ), ils peuvent être remplis (
full ) ou vides (
empty ). Le pool utilisé a des blocs libres dans lesquels il est possible d'enregistrer des données d'une taille appropriée. Tous les blocs du pool rempli sont alloués pour les données. Un pool vide ne contient aucune donnée et, si nécessaire, il peut être affecté à des blocs de stockage appartenant à n'importe quelle classe de taille.
La liste
freepools stocke des informations sur tous les pools qui sont à l'état
empty . Par exemple, s'il n'y a aucune entrée dans la liste des pools
usedpools sur les pools stockant des blocs de 8 octets (classe avec idx 0), un nouveau pool est initialisé, qui est à l'état
empty , conçu pour stocker de tels blocs. Ce nouveau pool est ajouté à la liste des
usedpools , il peut être utilisé pour répondre aux demandes de sauvegarde des données reçues après sa création.
Supposons que dans un pool à l'état
full , certains blocs soient libérés. Cela est dû au fait que les données qui y sont stockées ne sont plus nécessaires. Ce pool sera à nouveau dans la liste des
usedpools et il peut être utilisé pour les données de la classe de taille correspondante.
La connaissance de cet algorithme nous permet de comprendre comment l'état des pools change pendant le fonctionnement (et comment les classes de taille changent, les blocs auxquels ils peuvent être stockés).
Blocs
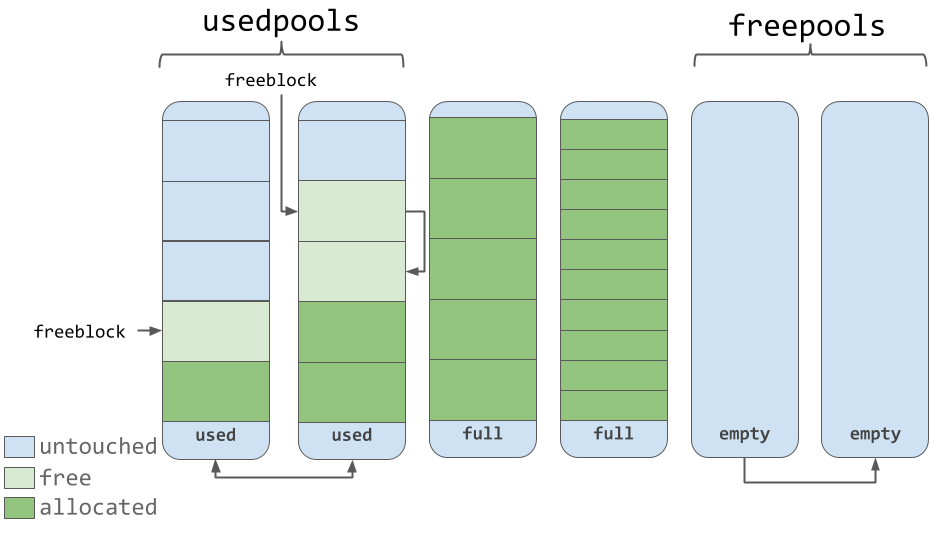 Piscines utilisées, pleines et vides
Piscines utilisées, pleines et videsComme vous pouvez le voir sur l'illustration précédente, les pools contiennent des pointeurs vers les blocs de mémoire "libres" qu'ils contiennent. En ce qui concerne le travail avec des blocs, une petite caractéristique doit être notée, qui est indiquée dans le code source. Le système de gestion de la mémoire utilisé dans CPython, à tous les niveaux (arénas, pools, blocs), s'efforce d'allouer de la mémoire uniquement lorsque cela est absolument nécessaire.
Cela signifie que les pools peuvent contenir des blocs dans l'un des trois états suivants:
untouched est la partie de la mémoire qui n'a pas encore été allouée.free - la partie de la mémoire qui était déjà allouée, mais qui a ensuite été rendue «libre» par CPython et ne contient plus de données précieuses.allocated est la partie de la mémoire qui contient des données précieuses.
Le pointeur
freeblock pointe vers une liste liée individuellement de blocs de mémoire libres. En d'autres termes, il s'agit d'une liste d'endroits où vous pouvez mettre des données. Si plusieurs blocs libres sont nécessaires pour placer des données, l'outil d'allocation de mémoire prendra plusieurs blocs du pool qui sont dans un état
untouched .
Comme l'outil de gestion de la mémoire rend les blocs «libres», ils, lorsqu'ils acquièrent l'état
free , arrivent en haut de la liste des
freeblock . Les blocs contenus dans cette liste ne représentent pas nécessairement une région de mémoire contiguë similaire à celle représentée sur la figure précédente. Ils peuvent en fait ressembler à celui ci-dessous.
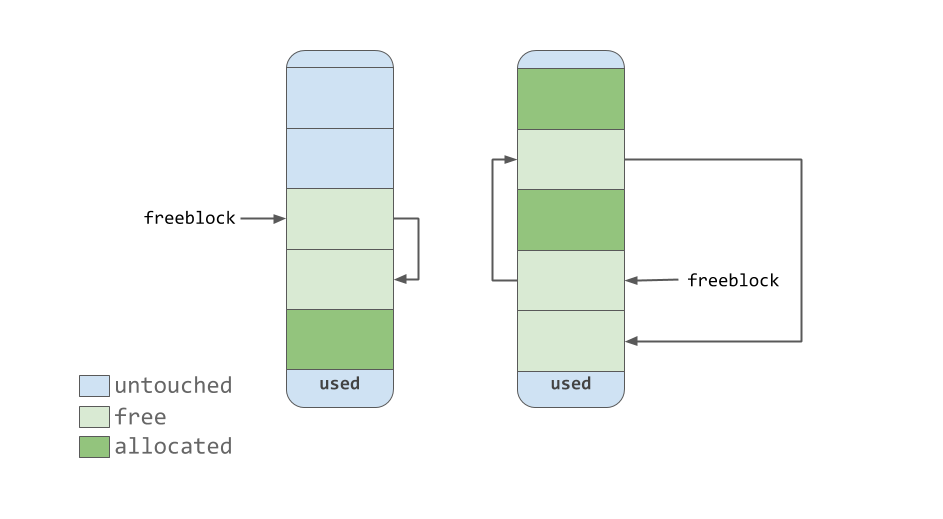 Liste de blocs libres liée unique
Liste de blocs libres liée uniqueArènes
Les arènes contiennent des piscines. Ces pools, comme déjà mentionné, peuvent résider dans les états
used ,
full ou
empty . Il convient de noter que les arénas n'ont pas d'états similaires à ceux des piscines.
Les arénas sont organisés en une liste doublement liée appelée
usable_arenas . Cette liste est triée selon le nombre de pools gratuits disponibles. Moins il y a de piscines gratuites dans l'arène, plus l'arène est proche du haut de la liste.
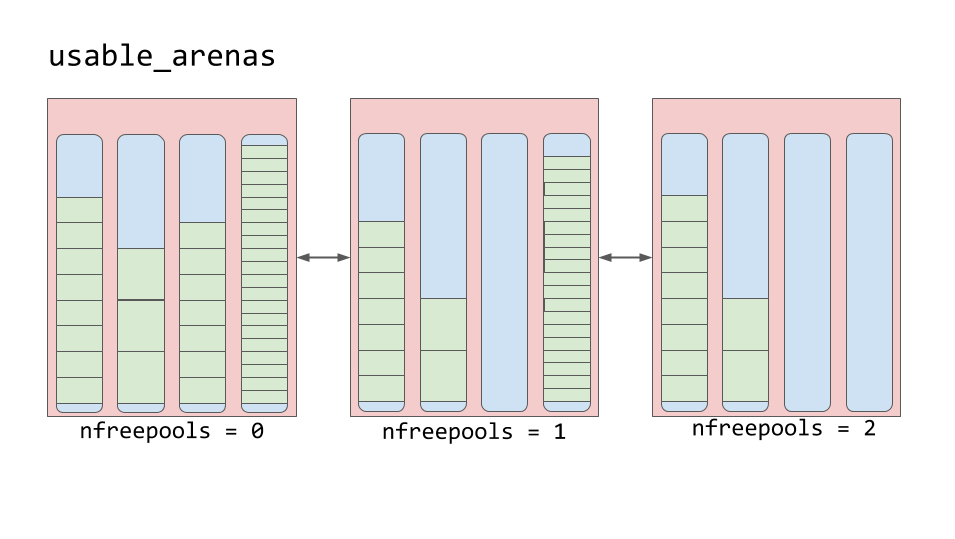 Liste des arénas utilisables
Liste des arénas utilisablesCela signifie que l'arène, qui est plus forte que d'autres remplies de données, sera sélectionnée pour y placer de nouvelles données. Et pourquoi pas l'inverse? Pourquoi ne pas publier de nouvelles données dans l'arène avec l'espace le plus libre?
En fait, cette fonctionnalité nous amène à l'idée de vraiment libérer de la mémoire. Vous avez peut-être remarqué que nous avons souvent utilisé ici le concept de «libération de mémoire», en le mettant entre guillemets. La raison pour laquelle cela a été fait est que bien que le bloc puisse être considéré comme «libre», le morceau de mémoire qu'il représente n'est pas réellement retourné au système d'exploitation. Le processus Python contient ce morceau de mémoire et l'utilise plus tard pour stocker de nouvelles données. La véritable libération de mémoire est le retour à son système d'exploitation, qui pourra l'utiliser.
Les arènes sont la seule entité du schéma considéré ici, dont la mémoire représentée peut être véritablement libérée. Le bon sens veut que le schéma de travail avec les arènes décrit ci-dessus vise à permettre aux arènes presque vides de se vider complètement. Avec cette approche, ce morceau de mémoire représenté par une arène complètement vide peut être vraiment libéré, ce qui réduira la quantité de mémoire consommée par Python.
Résumé
Voici ce que vous avez appris en lisant ce document:
- Qu'est-ce que la gestion de la mémoire et pourquoi est-elle importante?
- Comment l'implémentation de référence de Python, Cpython, écrite dans le langage de programmation C est arrangée.
- Quelles structures de données et quels algorithmes sont utilisés dans CPython pour la gestion de la mémoire.
La gestion de la mémoire fait partie intégrante du travail des programmes informatiques. Python résout presque toutes les tâches de gestion de mémoire inaperçues par le programmeur. Python permet à quiconque écrit dans ce langage d'ignorer les nombreux petits détails liés au travail avec les ordinateurs. Cela donne au programmeur la possibilité de travailler à un niveau supérieur, de créer son propre code sans se soucier de l'emplacement de stockage de ses données.
Chers lecteurs! Si vous avez de l'expérience avec le développement Python, dites-nous comment vous abordez l'utilisation de la mémoire dans vos programmes. Par exemple, cherchez-vous à le sauvegarder?
