Presque tous les systèmes de recommandation ont des difficultés avec le contenu nouveau ou rare - car seule une petite partie des utilisateurs interagit avec lui. Dans son rapport au
Yandex Inside, Daniil Burlakov a partagé un ensemble d'astuces qui sont utilisées dans les recommandations de la musique et a détaillé le modèle populaire de décomposition en valeurs singulières (SVD).
De plus, nous avons de tels interprètes qui sont appelés compositeurs et généralement abattus par les titulaires de droits d'auteur tout comme un fan. Seul Mozart avait «enregistré» plus d'un million de compositions.
- Bonjour à tous! Je m'appelle Daniil Burlakov, je dirige une équipe de recommandations dans les services médias. Aujourd'hui, je veux parler de certains des problèmes que nous résolvons lorsque nous traitons de recommandations dans Music.
Nous avons une merveilleuse équipe qui fait des recommandations non seulement pour Yandex.Music, mais aussi pour tous les services médias: voici Kinopoisk, Poster. Nous résolvons bien plus de problèmes techniques que de recommandations.

Aujourd'hui, je veux parler du produit central Yandex.Music, notre produit le plus important et préféré est les listes de lecture intelligentes, que beaucoup d'entre vous connaissent et écoutent probablement.

Je vais brièvement vous expliquer de quel type de listes de lecture il s'agit et de quel contenu nous les remplissons.
La playlist du jour a été conçue comme un ensemble de morceaux qui seront créés chaque jour pour que vous puissiez les télécharger et les écouter même en l'absence d'Internet. Mais ce sera génial pour vous, ce sera avec vous, et il devrait être mis à jour quotidiennement et contenir quelque chose de nouveau. Ce qui vous convient.
Deja Vu est une liste de lecture plus intéressante. Il est mis à jour une fois par semaine, et il y aura des morceaux que vous n'avez jamais écoutés, et des artistes que vous ne connaissez pratiquement pas ou pas du tout. Premiere - une sélection de nouveaux produits de vos artistes qui pourraient vous plaire.

Le deuxième produit est Yandex.Radio. En 2015, il a été lancé, nous continuons à le développer.
L'idée est de permettre à l'utilisateur d'obtenir un flux personnalisé de musique audio sans rien faire. En fait, j'ai appuyé sur un bouton et j'ai obtenu un merveilleux flux qui ne finira jamais et vous ravira pendant de nombreuses heures. Contrairement aux listes de lecture, il peut déjà être étiqueté. Vous pouvez, par exemple, allumer la radio par genre - rock ou musique de fond, si vous ne voulez pas être distrait pendant le travail. Ou un flux audio entièrement personnalisé - ce que nous appelons la radio «On Your Wave».

Quels problèmes rencontrons-nous lorsque nous faisons ces recommandations? Nous sommes confrontés à deux problèmes principaux, assez typiques pour la plupart des systèmes de recommandation. Ce sont des utilisateurs froids qui viennent de venir à notre service et dont nous ne savons toujours rien, et du contenu cool. Il comprend non seulement des pistes qui sont apparues récemment, mais aussi un grand nombre de pistes rares. Le catalogue Yandex.Music contient plus de 50 millions de titres, beaucoup d'entre eux n'ont encore été écoutés par aucun utilisateur. Par conséquent, un problème se pose: même si la piste est sortie assez longtemps, malheureusement, nous pouvons ne rien savoir de cette piste et ne pas avoir de statistiques.
Les deux problèmes ont été particulièrement aggravés et sont devenus particulièrement importants pour nous, car Yandex.Music est devenu un service international et a commencé à se rendre dans de nombreux pays. Lors de l'entrée dans chaque pays, le contenu local de ce pays devient, tout d'abord, très important. Il est clair que lorsque vous entrez dans un nouveau pays, ignorer la musique locale est plutôt désagréable. Il faut le recommander, le recommander de façon appropriée et comprendre la structure de cette musique interne. En fait, en Russie, personne n'écoute la musique israélienne, et il y a très peu de statistiques à ce sujet, même si nous avons ce contenu.
Passons en revue ces questions. Commençons par le problème des utilisateurs froids. Comment peut-il être résolu?

La première solution la plus simple est de ne rien recommander aux utilisateurs froids. En effet, la solution est très simple, vous pouvez simplement vous renseigner sur les préférences explicites. Ce sont de nombreux assistants qui peuvent être fournis à l'utilisateur.
avant que l'utilisateur ne reçoive sa première playlist de la journée, nous lui demandons de passer par un tel assistant, indiquant ses préférences, un ensemble de genres et d'artistes qu'il souhaite.
En conséquence, la première liste de lecture de l'utilisateur devient assez significative, adaptée à l'utilisateur et, très probablement, à partir de la toute première liste de lecture, l'utilisateur tombera amoureux de lui.
Malheureusement, cette approche n'est pas toujours possible.

Notre deuxième produit, Yandex.Radio, a été conçu comme un produit qui ne nécessite aucun effort de l'utilisateur. Il veut juste venir allumer la musique sans rien faire. De plus, Yandex.Radio est intégré à de nombreux autres systèmes, tels que Yandex.Drive, où il est plutôt étrange et peu pratique de forcer simplement l'utilisateur à s'asseoir dans la voiture, cliquez sur une sorte d'assistant s'il y est arrivé pour la première fois.
Par conséquent, nous sommes allés dans l'autre sens. Nous commençons par des recommandations, disons, pour l'utilisateur moyen, afin que la plupart des utilisateurs des premières pistes obtiennent un maximum de plaisir et qu'ils aiment la musique. Et nous offrons une personnalisation très rapide. Contrairement à la playlist que vous avez reçue et il est avec vous toute la journée, tous vos 60 titres. Et si, par exemple, nous n'avons pas deviné avec le fait que votre genre préféré est la musique populaire (qui sera une bonne supposition pour commencer), alors les 60 pistes ne vous concerneront pas, et ce sera triste, et très probablement, demain vous ne le serez pas reviens.
Cependant, si nous mettons la première piste de musique populaire à la radio et que vous dites que vous ne voulez pas l'écouter, nous personnaliserons instantanément la piste suivante pour vous et vous proposerons autre chose, par exemple du rock ou un autre genre.
En fait, en fait, ces deux solutions ferment le problème des utilisateurs froids à un degré ou à un autre.
Comment le problème de contenu pourrait-il être résolu par analogie? La solution numéro un, ainsi que sur les utilisateurs, est de ne pas recommander de contenu sympa. Mais ici, contrairement aux utilisateurs, le contenu lui-même ne reprendra pas et ne chauffera pas. Ainsi, le problème est que si nous ne collectons pas nous-mêmes de statistiques sur lui, alors le nouveau produit de l'artiste qui vient de sortir ne sera pas livré, et les utilisateurs qui n'auront pas vu les nouvelles de leur artiste seront très probablement bouleversés.

Une situation similaire avec un contenu international. Nous sommes allés dans un nouveau pays, et ne pas le recommander, ignorer ce contenu, évidemment, ne nous convient pas.
La deuxième solution, si nous agissons complètement par analogie, la recommande en quelque sorte en moyenne. L'analogie la plus simple consiste à proposer ce contenu à tout le monde de suite ou à le recommander comme musique populaire. Avec l'option de recommander, en moyenne, il n'est généralement pas très clair ce qu'est la musique moyenne. On peut appeler cela de la musique populaire par la force, mais on peut difficilement dire que toute la musique est si similaire les unes aux autres qu'elle ressemble à de la musique populaire. Par conséquent, si vous trouvez une composition de Beethoven entre une musique populaire, la plupart des gens ne seront probablement pas heureux de la recevoir. Cette solution ne nous convient donc pas non plus.

Qu'y a-t-il d'autre sur les pistes? Avec la piste elle-même, de nombreuses métadonnées nous parviennent du détenteur des droits d'auteur, telles que le genre de la piste, l'artiste, l'album et l'année de sortie. Allons-y. Comment pourraient-ils être utilisés? Par exemple, un genre. Un genre est une bonne information qui nous permet de deviner plus ou moins. Par exemple, cela résout le problème avec Beethoven ou une chanson qui aurait pu apparaître accidentellement dans quelqu'un à la radio: nous connaissons le genre du morceau, et il est peu probable que nous le glissions sur ceux à qui il ne convient pas.
Mais malheureusement, il ne permet pas de construire une bonne recommandation, car le concept du genre lui-même est assez subjectif, et ne permet pas de construire de bonnes recommandations sur la base de celui-ci. Naturellement, il existe de nombreux sous-genres au sein des genres, et c'est exactement ce que les titulaires de droits d'auteur nous envoient.

Le deuxième problème est qu'une personne ordinaire peut généralement nommer une douzaine de genres, tandis que les titulaires de droits d'auteur nous envoient des milliers de genres, et c'est un problème assez important pour les regrouper, trouver des similaires entre eux, etc. Malheureusement, ce problème n'est pas toujours résolu.
Ensuite, évidemment, il y a des problèmes avec le fait que, malheureusement, les titulaires de droits d'auteur sont souvent confus et font des erreurs. Et nous avons régulièrement des problèmes et des rapports que nous collectons des morceaux qui sont populaires dans la radio rock, et le détenteur des droits d'auteur a mis le genre rock sur eux. Par analogie, nous collectons du jazz et d'autres stations de radio. Et nous avons régulièrement des rapports d'utilisateurs demandant à être corrigés, car une piste avec une erreur a volé vers ces stations de radio.
Je veux vous proposer de deviner le genre du morceau.
Ce n'est pas une bande-son. C'est du métal. Et nous avons un gros problème quand ils nous envoient un tel balisage.
Je propose d'aller à la partie suivante et de parler des interprètes de la piste. J'ai déjà dit qu'il y avait un problème, qu'un nouvel artiste, une nouvelle piste ou un nouvel album sortait, et cela devrait être recommandé. En particulier, les informations sur l'artiste nous sauveront toujours. Nous savons que l'utilisateur a écouté cet artiste, et nous pouvons le lui recommander en conséquence. C'est ce que nous faisons. Cependant, il existe également des difficultés. Par exemple, si nous ne savions rien de l'artiste lui-même ou que l'utilisateur ne l'écoutait pas, les informations que cette piste possède tel ou tel artiste ne nous disent rien. De même avec des pistes rares. Il y avait une piste rare d'un artiste rare, nous avons appris que maintenant cette piste rare lui appartient. Malheureusement, encore une fois, il n'y a pas beaucoup d'informations qui lui permettront d'être en quelque sorte recommandé à d'autres personnes qui ne connaissent pas son travail.

Le deuxième problème concerne les reprises et remixes. Encore une fois, de vils détenteurs de droits d'auteur interviennent ici et font souvent des erreurs. En particulier, lorsque nous avons une piste originale et sa pochette, les détenteurs des droits d'auteur ne prennent souvent pas la peine de nommer ces pistes de différentes manières, de signer que l'une d'entre elles est un remix ou même simplement de poser différents artistes pour elles, quand c'est le cas.
Je veux vous proposer deux pistes afin de comprendre à quel point le son est différent pour des pistes qui s'appellent exactement les mêmes. Ainsi, nous obtenons deux pistes qui peuvent être appelées similaires, elles ont un rythme relativement similaire, un texte relativement similaire, mais elles sont différentes. Et pour nous, c'est un seul et même morceau, car son nom, son artiste et tout le reste sont exactement les mêmes.
De plus, nous avons de tels artistes vils qui sont appelés compositeurs et généralement abattus par les titulaires de droits d'auteur tout comme un fan. Seul Mozart avait «enregistré» plus d'un million de compositions. Il est clair que pour les amateurs de musique classique, cela ne sera pas possible. Si l'utilisateur a dit qu'il aime Mozart, alors nous avons des millions de pistes, diverses reprises de mélodies classiques standard. En conséquence, nous ne pouvons pratiquement rien y faire.

Je veux vous dire plus en détail comment ce problème pourrait être résolu, mais pour commencer, relâchons nos exigences. Nous voulions recommander des morceaux que personne n'écoutait, et réfléchissons maintenant à comment recommander uniquement des morceaux qui seraient rares. Le filtrage collaboratif nous aide ici. Comment ça marche et qu'est-ce qu'on obtient finalement?
Pour commencer, nous devons faire une matrice de notes d'utilisateurs, où il y aura des utilisateurs sur les lignes, il y aura des pistes sur les colonnes, à l'intersection de la colonne et la ligne il y aura sa note. Il est clair que pour la majeure partie de la matrice, nous ne connaissons pas les commentaires des utilisateurs, les utilisateurs ne pouvaient même pas écouter l'intégralité de notre catalogue.
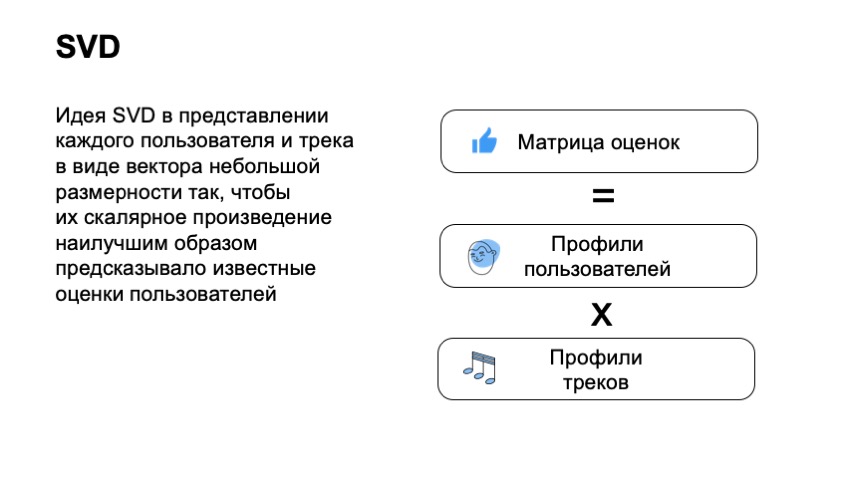
Avec cette matrice, nous voulons que l'utilisateur et la piste associent des vecteurs petits et suffisamment courts pour que le produit scalaire du vecteur utilisateur et du vecteur élément prédise bien la note de l'utilisateur. Ainsi, nous obtenons que pour chaque article et pour chaque utilisateur, nous devons trouver deux vecteurs afin que leur produit final puisse mieux prédire notre estimation. Par exemple, si dans ce cas, nous dirions que l'utilisateur a aimé la piste - c'est 1, s'il ne l'aimait pas - 0. Et dans ce cas, nous pouvons réellement appliquer la technique standard, la décomposition SVD, et obtenir des vecteurs optimaux pour les utilisateurs et pour les pistes.

Qu'est-ce que cela nous donne? cela nous donne le prochain gros plus. Pour la plupart des approches, nous ne pouvons pas dire que les deux pistes sont similaires si personne n'a écouté ensemble. Habituellement, une partie importante des approches est basée sur le fait que certains utilisateurs ont interagi avec les éléments A et B, et nous constatons qu'ils sont similaires en conséquence. Le filtrage collaboratif sous forme de SVD nous permet de le faire même si aucun utilisateur n'a écouté deux pistes ensemble. Ils nous permettent de l'évaluer assez bien. C'est le premier plus.
Qu'est-ce que cela nous donne? Ayant un vecteur de piste, nous pouvons le recommander à un cercle beaucoup plus large de personnes et recommander des pistes beaucoup moins populaires. Et le principal avantage, nous obtenons toujours une représentation vectorielle des pistes, ce qui est très pratique à utiliser, avec laquelle vous pouvez rapidement rechercher des pistes similaires.
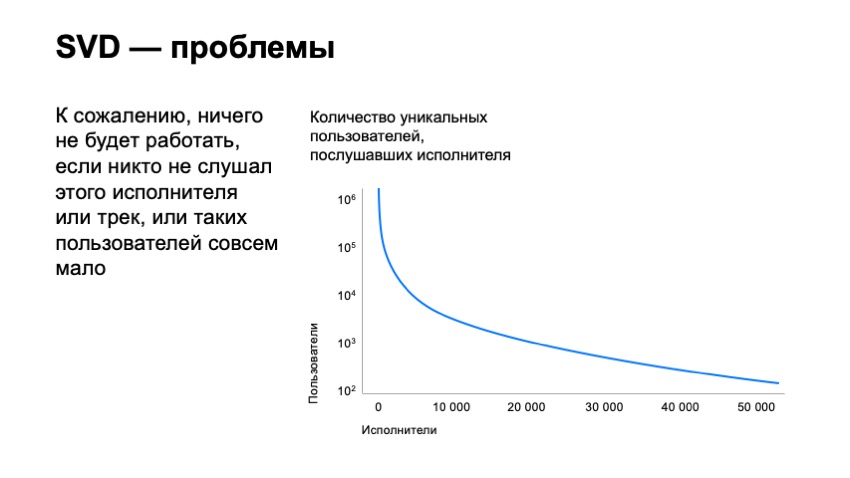
Cependant, cela ne résout pas tous nos problèmes. nous n'avons que légèrement déplacé la barre pour le nombre de pistes que nous pouvons recommander. Si nous construisons un graphique du nombre d'utilisateurs qui ont écouté les artistes, trions les artistes en fait par leur popularité, nous verrons que des millions d'utilisateurs écoutent les meilleurs artistes sur notre service. Si l'on regarde déjà la 10 millième position de ces artistes, il n'y aura que mille utilisateurs. Si nous regardons même le 50 000e artiste, il n'y aura qu'une centaine d'utilisateurs. Il est clair que ses pistes n'auront que des dizaines d'utilisateurs qui l'ont écouté, ce qui rend en fait impossible de les recommander, car le vecteur SVD de ces pistes sera extrêmement instable et ne fonctionnera pas.
Comment pouvons-nous essayer de résoudre ce problème? Que voulons-nous?
Nous voulons prendre une nouvelle piste rare dont nous ne savons rien, par exemple une piste rare d'Israël, et nous voulons obtenir une sorte de représentation vectorielle pour elle, qui serait très similaire à notre vecteur SVD, ce qui est très pratique pour travailler avec et faire des recommandations.
La seule chose que nous n'avons pas prise en compte est l'audio de cette piste elle-même. Grâce à l'audio, nous avons pu recommander les pistes. Comment pourrions-nous, en utilisant une piste audio, obtenir un vecteur SVD. la première chose que nous voulons faire est une petite conversion.
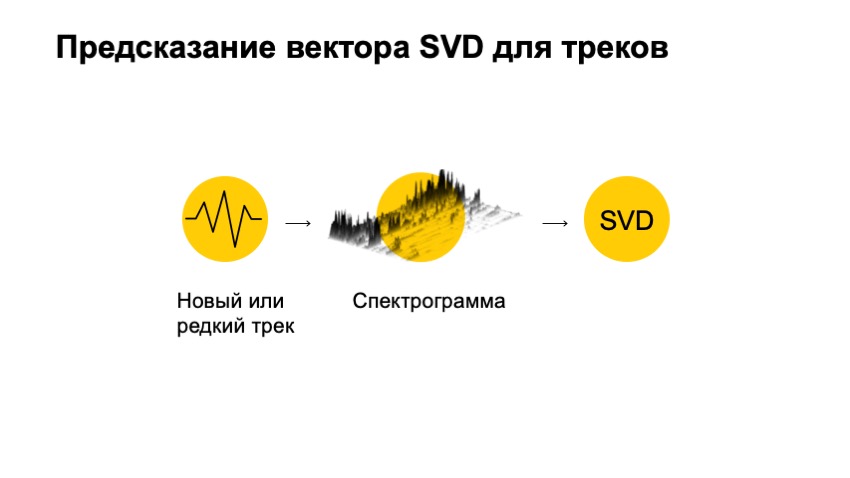
Qu'est-ce qui est essentiellement audio? Vous pouvez imaginer un graphique de tension. Dans tous les cas, il s'agit d'un ensemble de nombres unidimensionnel, ce qui est plutôt gênant pour travailler, il est très grand et long, cela n'a pas beaucoup de sens en soi. Mais nous pouvons vérifier son spectre, faire des transformations de Fourier sur lui, très brièvement, pour voir à quel point il ressemble à un type spécifique de sinusoïde. Combien il ressemble à une sorte de sinusoïde. Et voyez combien de sinusoïdes sont dans ce graphique, et faites de même pour chacune des fréquences.
Si nous faisons cela pour l'ensemble de la piste dans son ensemble, bien sûr, nous obtiendrons des informations, mais très peu, cela en dira très peu, car, par exemple, les transitions entre les parties de la piste sont très importantes pour la musique, alors que dans le spectre, nous le ferons avoir sous forme indirecte sur un changement de très grandes fréquences, qui devraient concerner les secondes, les minutes, et cela est assez gênant et mal présenté sous la forme d'un spectre.
Par conséquent, nous allons plus loin et coupons la piste en petits morceaux. Dans chaque pièce, nous faisons une telle transformation. En conséquence, nous obtenons une telle image, je l'ai dessinée sous forme tridimensionnelle, de sorte qu'il est plus visible que nous ayons déplié les fréquences sur un plan dans le temps et en hauteur - l'énergie qui était à ce moment-là. Et ils ont obtenu le soi-disant spectrogramme.
Comment pourrions-nous, à l'aide de ce spectrogramme, obtenir le vecteur SVD? La réponse à notre époque est assez banale: prenons un réseau de neurones et entraînons-le à prédire le vecteur SVD.
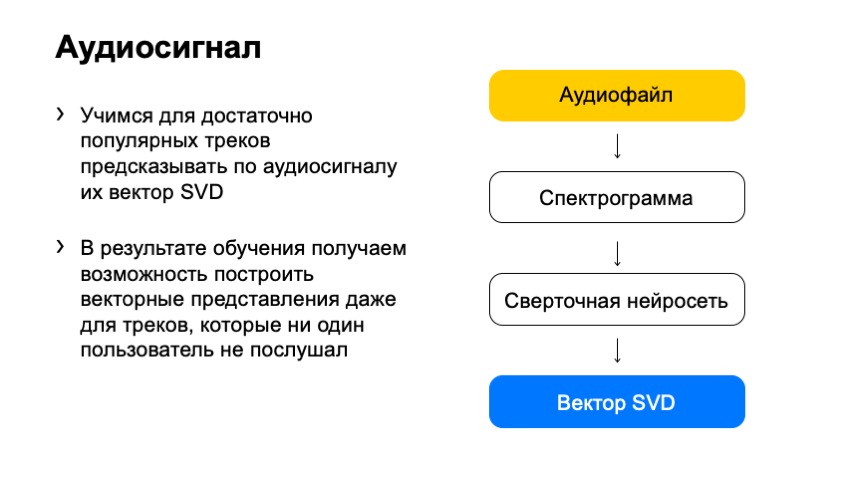
Nous l'avons donc fait. Qu'avons-nous choisi comme formation? Ces pistes SVD dont nous connaissons le vecteur avec certitude. Nous avons spécialement sélectionné des pistes populaires dont le feedback était suffisamment important pour que le vecteur SVD soit déjà complètement silencieux, et nous avons pu le calculer clairement. Et - ils ont formé le réseau neuronal pour prédire ces vecteurs.
Qu'avons-nous finalement obtenu? Un réseau qui peut prendre n'importe quelle piste et prédire son vecteur SVD. Nous avons obtenu une solution très simple qui fonctionne très bien.
Je veux montrer un exemple d'une paire de pistes que nous avons retirées. L'une de ces pistes est assez populaire, et son vecteur SVD pourrait être reconnu assez précisément, et la seconde est très impopulaire. Je veux suggérer de deviner laquelle de ces pistes est moins populaire et laquelle est plus populaire.
Première piste:
Deuxième piste:
La réponse
Le premier morceau est plus populaire. Si vous regardez le nombre d'auditeurs qui connaissaient cette piste et pouvaient la trouver eux-mêmes, sans l'aide de recommandations, alors la première piste pourrait être trouvée par plus de 1000 utilisateurs, et la seconde - seulement 10. Et puis, comment nous avons appliqué notre technologie, nous ne pouvions pas même essayer de recommander cette piste, car il n'y avait rien à quoi se raccrocher pour des recommandations. Nous ne pouvions l'offrir qu'à ces 10 utilisateurs.
Lorsque nous l'avons appliqué en production, nous avons eu beaucoup de bons retours. L'une des listes de lecture, «Deja Vu», où nous devons intégrer des pistes que l'utilisateur n'a pas écoutées, organiser la découverte pour l'utilisateur, s'est considérablement améliorée après que nous ayons pu appliquer cette technologie.
Bien sûr, nous l'avons appliqué lors de l'entrée dans de nouveaux pays et avons également reçu de nombreuses critiques positives. Ils ont noté que les listes de lecture savent bien personnaliser. De plus, les éditeurs israéliens ont été assez surpris que le service russe en Israël ne recommande pas les artistes russes en grande quantité, mais la musique locale et la musique internationale.

À propos des chiffres que nous avons réussi à atteindre. Plus important encore, nous voulions atteindre le nombre de nouveaux produits pour les utilisateurs dans le flux audio, afin qu'il devienne plus diversifié. , . , : . . . 1,5% . , . , - , , . , , .
: . , , , . . Merci de votre attention.