Au cours des 7 dernières années, avec mon équipe, j'ai soutenu et développé le cœur du produit Miro (ex-RealtimeBoard): interaction client-serveur et cluster, en collaboration avec la base de données.
Nous avons Java avec différentes bibliothèques à bord. Tout est lancé en dehors du conteneur, via le plugin Maven. Il s'appuie sur la plateforme de nos partenaires, ce qui nous permet de travailler avec la base de données et les flux, de gérer l'interaction client-serveur, etc. DB - Redis et PostgreSQL (mon collègue a
écrit sur la façon dont nous passons d'une base de données à une autre ).
En termes de logique métier, l'application contient:
- travailler avec des tableaux personnalisés et leur contenu;
- fonctionnalité d'enregistrement des utilisateurs, de création et de gestion de tableaux;
- générateur de ressources personnalisé. Par exemple, il optimise les grandes images téléchargées vers l'application afin qu'elles ne ralentissent pas sur nos clients;
- de nombreuses intégrations avec des services tiers.
En 2011, alors que nous venions de commencer, tout Miro était sur le même serveur. Tout y était: Nginx sur lequel tournait php pour un site, une application Java et des bases de données.
Le produit développé, le nombre d'utilisateurs et le contenu qu'ils ont ajouté aux cartes ont augmenté, de sorte que la charge sur le serveur a également augmenté. En raison du grand nombre d'applications sur notre serveur, à ce moment-là, nous ne pouvions pas comprendre ce qui donne exactement la charge et, par conséquent, nous ne pouvions pas l'optimiser. Pour résoudre ce problème, nous avons tout divisé en différents serveurs, et nous avons obtenu un serveur Web, un serveur avec notre serveur d'applications et de bases de données.
Malheureusement, après un certain temps, des problèmes sont survenus à nouveau, car la charge sur l'application a continué de croître. Nous avons ensuite réfléchi à la manière de dimensionner l'infrastructure.

Ensuite, je parlerai des difficultés que nous avons rencontrées dans le développement de clusters et la mise à l'échelle des applications et de l'infrastructure Java.
Mettre l'infrastructure à l'échelle horizontalement
Nous avons commencé par collecter des métriques: l'utilisation de la mémoire et du CPU, le temps nécessaire pour exécuter les requêtes des utilisateurs, l'utilisation des ressources système et le travail avec la base de données. D'après les mesures, il était clair que la génération de ressources utilisateur était un processus imprévisible. Nous pouvons charger le processeur à 100% et attendre des dizaines de secondes jusqu'à ce que tout soit fait. Les demandes des utilisateurs pour les tableaux donnaient parfois une charge inattendue. Par exemple, lorsqu'un utilisateur sélectionne un millier de widgets et commence à les déplacer spontanément.
Nous avons commencé à réfléchir à la manière de mettre à l'échelle ces parties du système et sommes parvenus à des solutions évidentes.
Travail à grande échelle avec des tableaux et du contenu . L'utilisateur ouvre la carte comme ceci: l'utilisateur ouvre le client → indique la carte qu'il veut ouvrir → se connecte au serveur → un flux est créé sur le serveur → tous les utilisateurs de cette carte se connectent à un flux → toute modification ou création du widget se produit dans ce flux. Il s'avère que tout travail avec la carte est strictement limité par le flux, ce qui signifie que nous pouvons répartir ces flux entre les serveurs.
Faites évoluer la génération de ressources utilisateur . Nous pouvons supprimer le serveur pour générer des ressources séparément, et il recevra des messages pour la génération, puis répondra que tout est généré.
Tout semble simple. Mais dès que nous avons commencé à étudier ce sujet plus en profondeur, il s'est avéré que nous devions en outre résoudre certains problèmes indirects. Par exemple, si les utilisateurs expirent un abonnement payant, nous devons les en informer, quel que soit le forum sur lequel ils se trouvent. Ou, si l'utilisateur a mis à jour la version de la ressource, vous devez vous assurer que le cache est correctement vidé sur tous les serveurs et que nous fournissons la bonne version.
Nous avons identifié la configuration système requise. L'étape suivante consiste à comprendre comment mettre cela en pratique. En fait, nous avions besoin d'un système qui permettrait aux serveurs du cluster de communiquer entre eux et sur la base duquel nous réaliserions toutes nos idées.
Le premier cluster hors de la boîte
Nous n'avons pas sélectionné la première version du système, car elle était déjà partiellement implémentée dans la plateforme partenaire que nous avons utilisée. Dans ce document, tous les serveurs étaient connectés les uns aux autres via TCP, et en utilisant cette connexion, nous pouvions envoyer des messages RPC à un ou à tous les serveurs à la fois.
Par exemple, nous avons trois serveurs, ils sont connectés les uns aux autres via TCP, et dans Redis, nous avons une liste de ces serveurs. Nous démarrons un nouveau serveur dans le cluster → il s'ajoute à la liste dans Redis → lit la liste pour connaître tous les serveurs du cluster → se connecte à tous.
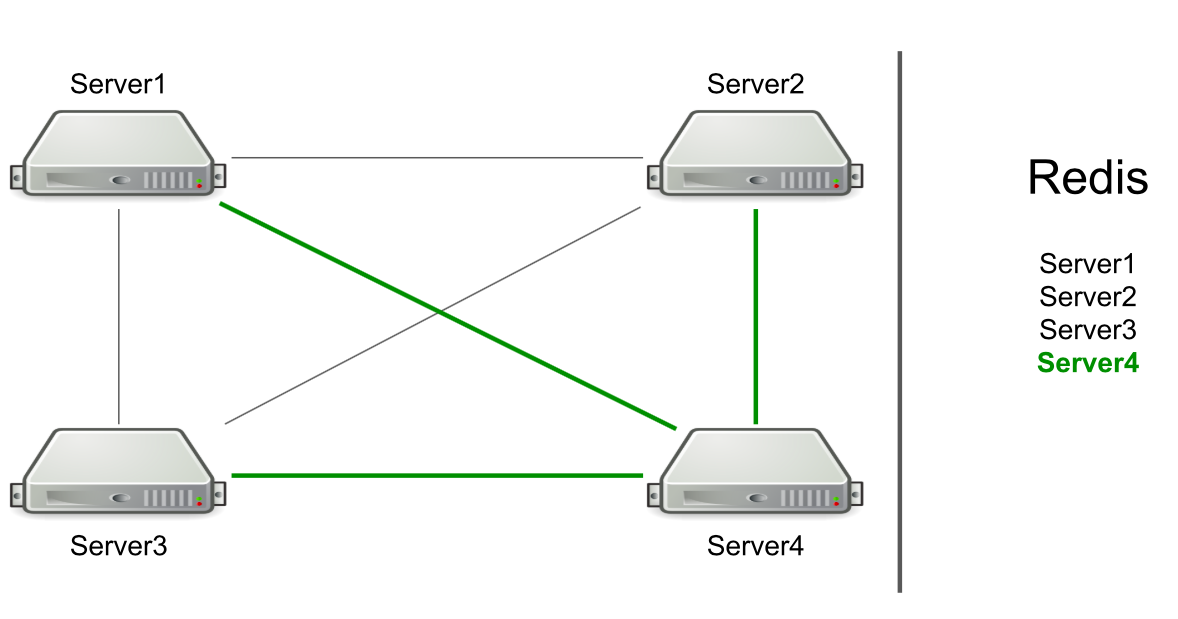
Basé sur RPC, la prise en charge du vidage du cache et de la redirection des utilisateurs vers le serveur souhaité a déjà été mise en œuvre. Nous avons dû faire une génération de ressources utilisateur et informer les utilisateurs que quelque chose s'était passé (par exemple, un compte avait expiré). Pour générer des ressources, nous avons choisi un serveur arbitraire et lui avons envoyé une demande de génération, et pour les notifications concernant l'expiration d'un abonnement, nous avons envoyé une commande à tous les serveurs dans l'espoir que le message atteindrait l'objectif.
Le serveur lui-même détermine à qui envoyer le message.
Cela ressemble à une fonctionnalité, pas à un problème. Mais le serveur se concentre uniquement sur la connexion à un autre serveur. S'il y a des connexions, alors il y a un candidat pour envoyer un message.
Le problème est que le serveur numéro 1 ne sait pas que le serveur numéro 4 est actuellement sous forte charge et ne peut pas y répondre assez rapidement. Par conséquent, les demandes du serveur n ° 1 sont traitées plus lentement qu'elles ne le pourraient.
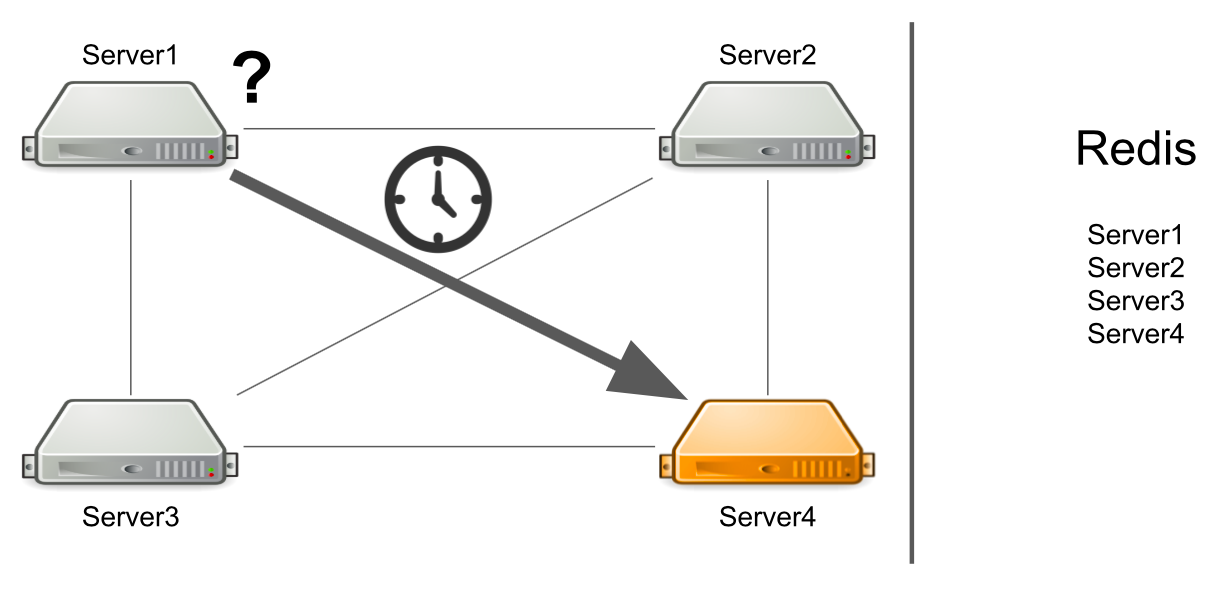
Le serveur ne sait pas que le deuxième serveur est figé
Mais que se passe-t-il si le serveur n'est pas seulement lourdement chargé, mais se bloque généralement? De plus, il se bloque pour ne plus prendre vie. Par exemple, j'ai épuisé toute la mémoire disponible.
Dans ce cas, le serveur n ° 1 ne connaît pas le problème, il continue donc d'attendre une réponse. Les serveurs restants du cluster ne connaissent pas non plus la situation avec le serveur n ° 4, ils enverront donc beaucoup de messages au serveur n ° 4 et attendront une réponse. Il en sera ainsi jusqu'à la mort du serveur numéro 4.
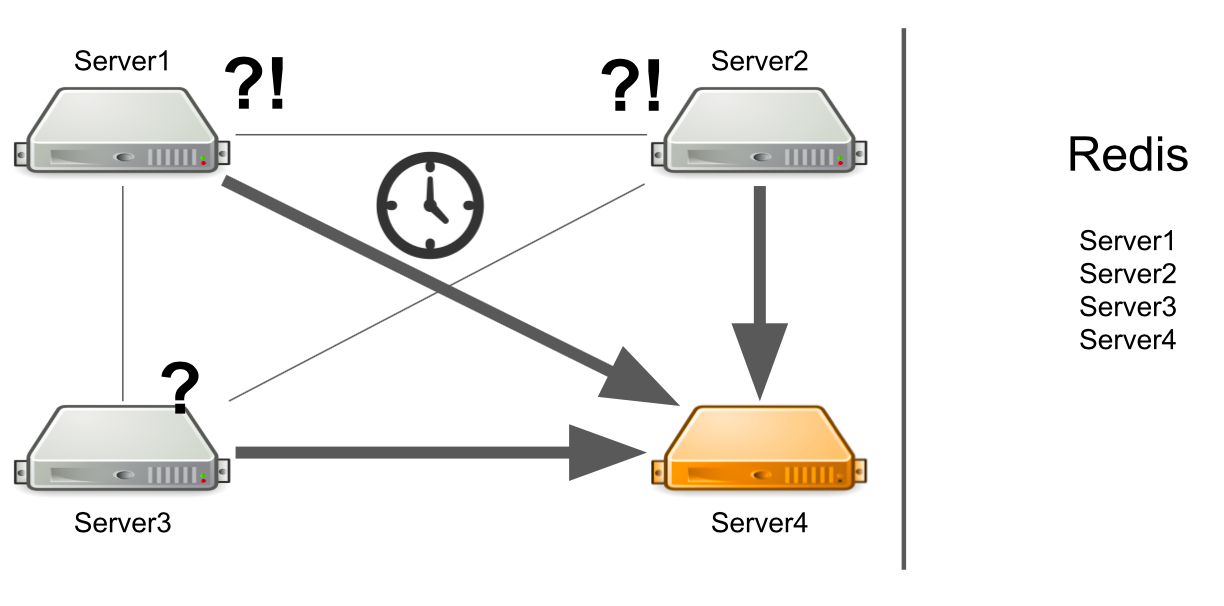
Que faire Nous pouvons ajouter indépendamment une vérification de l'état du serveur au système. Ou nous pouvons rediriger les messages des serveurs «malades» vers des serveurs «sains». Tout cela prendra trop de temps aux développeurs. En 2012, nous avions peu d'expérience dans ce domaine, nous avons donc commencé à chercher des solutions toutes faites à tous nos problèmes à la fois.
Courtier de messages. Activemq
Nous avons décidé d'aller dans le sens de Message Broker pour configurer correctement la communication entre les serveurs. Ils ont choisi ActiveMQ en raison de la possibilité de configurer la réception de messages sur le consommateur à un certain moment. Certes, nous n'avons jamais saisi cette opportunité, nous avons donc pu choisir RabbitMQ, par exemple.
En conséquence, nous avons transféré l'intégralité de notre système de cluster vers ActiveMQ. Qu'est-ce que cela a donné:
- Le serveur ne détermine plus lui-même à qui le message est envoyé, car tous les messages transitent par la file d'attente.
- Tolérance aux pannes configurée. Pour lire la file d'attente, vous pouvez exécuter non pas un, mais plusieurs serveurs. Même si l'un d'eux tombe, le système continuera de fonctionner.
- Les serveurs sont apparus des rôles, ce qui a permis de diviser le serveur par type de charge. Par exemple, un générateur de ressources peut uniquement se connecter à une file d'attente pour lire des messages afin de générer des ressources, et un serveur avec des cartes peut se connecter à une file d'attente pour ouvrir des cartes.
- La communication RPC, c'est-à-dire chaque serveur a sa propre file d'attente privée, où d'autres serveurs lui envoient des événements.
- Vous pouvez envoyer des messages à tous les serveurs via Topic, que nous utilisons pour réinitialiser les abonnements.
Le schéma semble simple: tous les serveurs sont connectés au courtier et il gère la communication entre eux. Tout fonctionne, les messages sont envoyés et reçus, des ressources sont créées. Mais il y a de nouveaux problèmes.
Que faire lorsque tous les serveurs nécessaires reposent?
Supposons que le serveur n ° 3 veuille envoyer un message pour générer des ressources dans une file d'attente. Il s'attend à ce que son message soit traité. Mais il ne sait pas que pour une raison quelconque, il n'y a pas un seul destinataire du message. Par exemple, les destinataires ont planté en raison d'une erreur.
Pour tout le temps d'attente, le serveur envoie beaucoup de messages avec une requête, c'est pourquoi une file d'attente de messages apparaît. Par conséquent, lorsque des serveurs qui fonctionnent apparaissent, ils sont obligés de traiter d'abord la file d'attente accumulée, ce qui prend du temps. Du côté de l'utilisateur, cela conduit au fait que l'image téléchargée par lui n'apparaît pas immédiatement. Il n'est pas prêt à attendre, alors il quitte le tableau.
En conséquence, nous dépensons la capacité du serveur pour la génération de ressources, et personne n'a besoin du résultat.
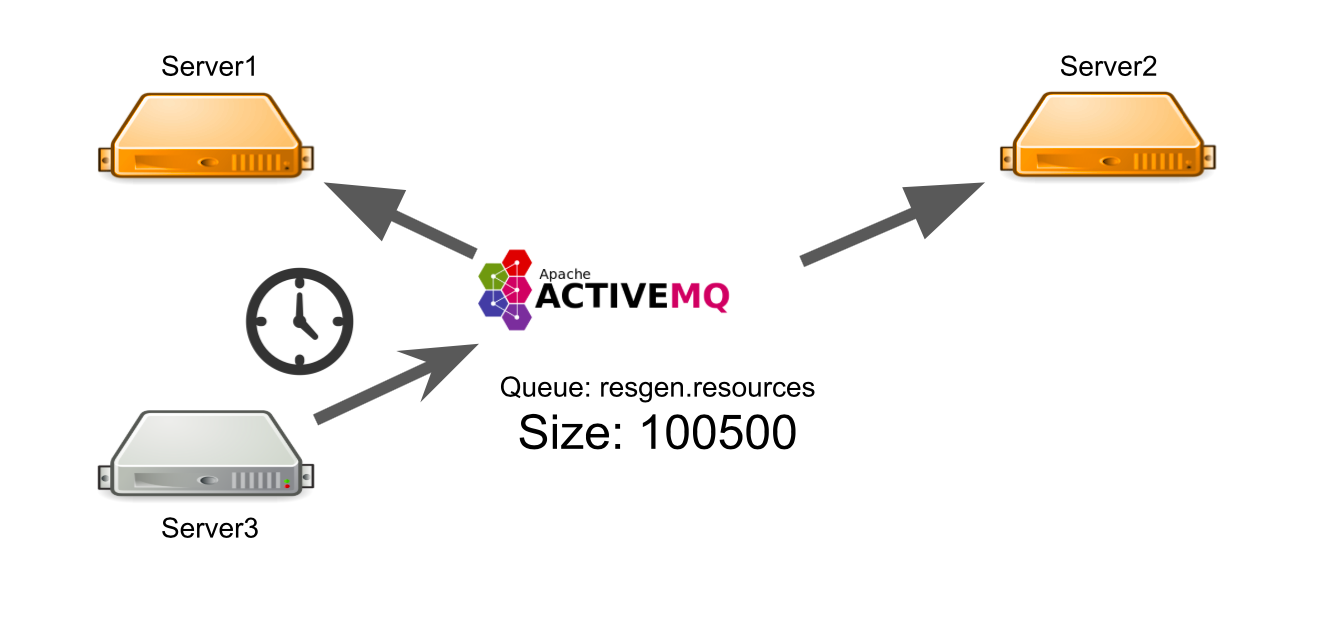
Comment puis-je résoudre le problème? Nous pouvons mettre en place une surveillance qui vous informera de ce qui se passe. Mais à partir du moment où la surveillance rapporte quelque chose, jusqu'au moment où nous comprenons que nos serveurs sont mauvais, le temps passera. Cela ne nous convient pas.
Une autre option consiste à exécuter Service Discovery, ou un registre de services qui saura quels serveurs avec quels rôles s'exécutent. Dans ce cas, nous recevrons immédiatement un message d'erreur s'il n'y a pas de serveurs gratuits.
Certains services ne peuvent pas être mis à l'échelle horizontalement
Il s'agit d'un problème de notre premier code, pas d'ActiveMQ. Permettez-moi de vous montrer un exemple:
Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER);
Nous avons un service pour travailler avec les droits des utilisateurs sur la carte: l'utilisateur peut être le propriétaire de la carte ou son éditeur. Il ne peut y avoir qu'un seul propriétaire au conseil d'administration. Supposons que nous ayons un scénario où nous voulons transférer la propriété d'une carte d'un utilisateur à un autre. Sur la première ligne, nous obtenons le propriétaire actuel de la carte, sur la seconde - nous prenons l'utilisateur qui était l'éditeur, et devient maintenant le propriétaire. De plus, le propriétaire actuel nous a mis le rôle d'ÉDITEUR, et l'ancien éditeur - le rôle de PROPRIÉTAIRE.
Voyons comment cela fonctionnera dans un environnement multi-thread. Lorsque le premier thread établit le rôle EDITOR et que le second thread essaie de prendre le propriétaire actuel, il peut arriver que OWNER n'existe pas, mais il y a deux EDITOR.
La raison en est le manque de synchronisation. Nous pouvons résoudre le problème en ajoutant un bloc de synchronisation sur la carte.
synchronized (board) { Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER); }
Cette solution ne fonctionnera pas dans le cluster. La base de données SQL pourrait nous aider avec cela à l'aide de transactions. Mais nous avons Redis.
Une autre solution consiste à ajouter des verrous distribués au cluster afin que la synchronisation se fasse à l'intérieur de l'ensemble du cluster, et pas seulement d'un serveur.
Un seul point d'échec lors de l'entrée dans la planche
Le modèle d'interaction entre le client et le serveur est dynamique. Il faut donc stocker l'état de la carte sur le serveur. Par conséquent, nous avons créé un rôle distinct pour les serveurs - BoardServer, qui gère les demandes des utilisateurs liées aux cartes.
Imaginez que nous ayons trois BoardServer, dont l'un est le principal. L'utilisateur lui envoie une requête «Ouvrez-moi la carte avec id = 123» → le serveur recherche dans sa base de données si la carte est ouverte et sur quel serveur elle se trouve. Dans cet exemple, la carte est ouverte.
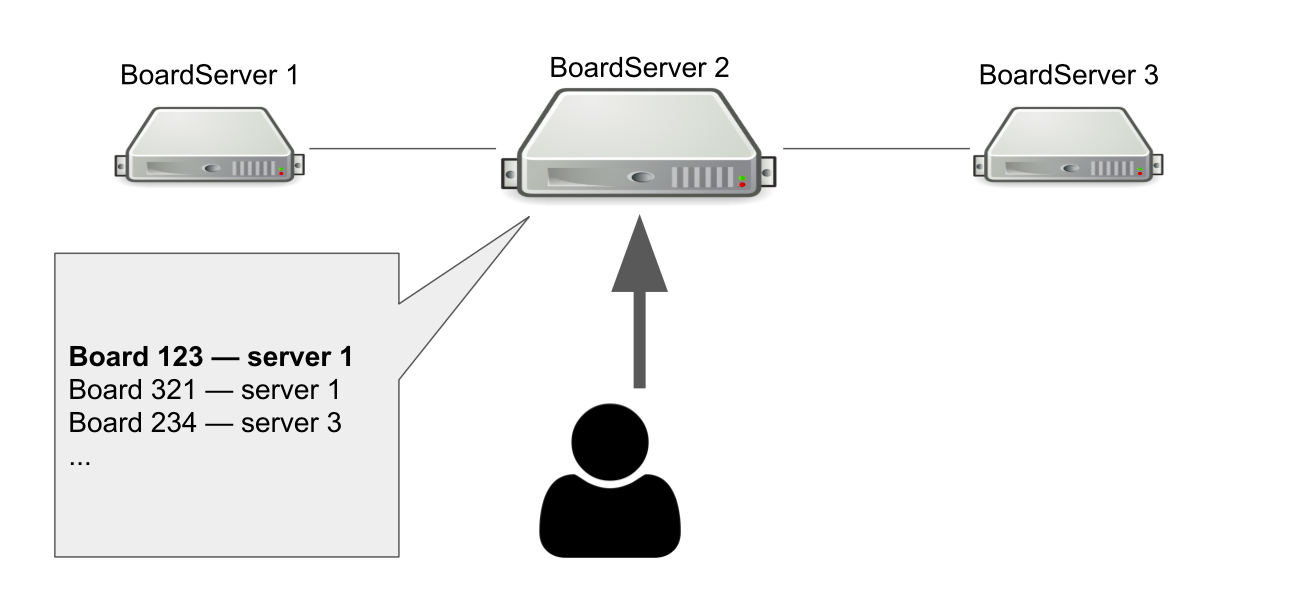
Le serveur principal répond que vous devez vous connecter au serveur n ° 1 → l'utilisateur se connecte. Évidemment, si le serveur principal meurt, l'utilisateur ne pourra plus accéder à de nouvelles cartes.
Alors pourquoi avons-nous besoin d'un serveur qui sait où les cartes sont ouvertes? Nous avons donc un seul point de décision. Si quelque chose arrive aux serveurs, nous devons comprendre si la carte est réellement disponible afin de la retirer du registre ou de la rouvrir ailleurs. Il serait possible d'organiser cela à l'aide d'un quorum, lorsque plusieurs serveurs résolvent un problème similaire, mais à cette époque, nous n'avions pas les connaissances nécessaires pour implémenter le quorum de manière indépendante.
Passer à Hazelcast
D'une manière ou d'une autre, nous avons réglé les problèmes qui se sont posés, mais ce n'est peut-être pas la plus belle des façons. Maintenant, nous devions comprendre comment les résoudre correctement, nous avons donc formulé une liste d'exigences pour une nouvelle solution de cluster:
- Nous avons besoin de quelque chose qui surveillera l'état de tous les serveurs et leurs rôles. Appelez-le Service Discovery.
- Nous avons besoin de verrous de cluster qui aideront à garantir la cohérence lors de l'exécution de requêtes dangereuses.
- Nous avons besoin d'une structure de données distribuée qui garantira que les cartes se trouvent sur certains serveurs et informera en cas de problème.
C'était l'année 2015. Nous avons opté pour Hazelcast - In-Memory Data Grid, un système de cluster pour stocker des informations dans la RAM. Nous avons alors pensé que nous avions trouvé une solution miracle, le Saint Graal du monde de l'interaction de cluster, un cadre miracle qui peut tout faire et combine des structures de données distribuées, des verrous, des messages RPC et des files d'attente.
Comme avec ActiveMQ, nous avons transféré presque tout à Hazelcast:
- génération de ressources utilisateur via ExecutorService;
- verrou distribué lorsque les droits sont modifiés;
- rôles et attributs des serveurs (Service Discovery);
- un registre unique de tableaux ouverts, etc.
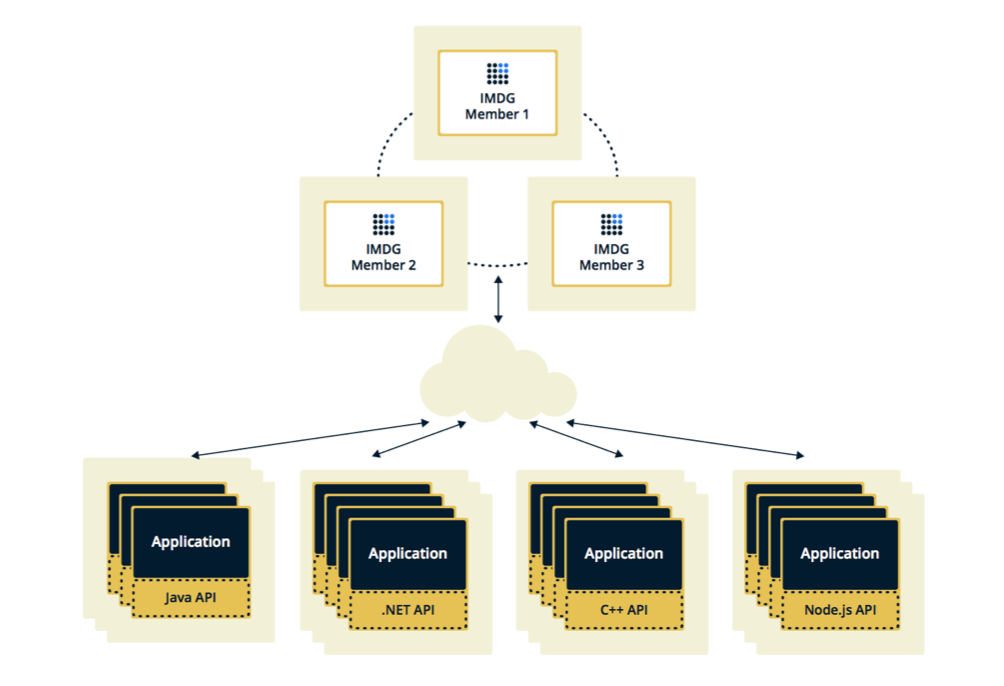
Topologies Hazelcast
Hazelcast peut être configuré dans deux topologies. La première option est Client-Serveur, lorsque les membres sont situés séparément de l'application principale, ils forment eux-mêmes un cluster et toutes les applications s'y connectent en tant que base de données.
La deuxième topologie est Embedded, lorsque les membres Hazelcast sont intégrés dans l'application elle-même. Dans ce cas, nous pouvons utiliser moins d'instances, l'accès aux données est plus rapide, car les données et la logique métier elle-même sont au même endroit.
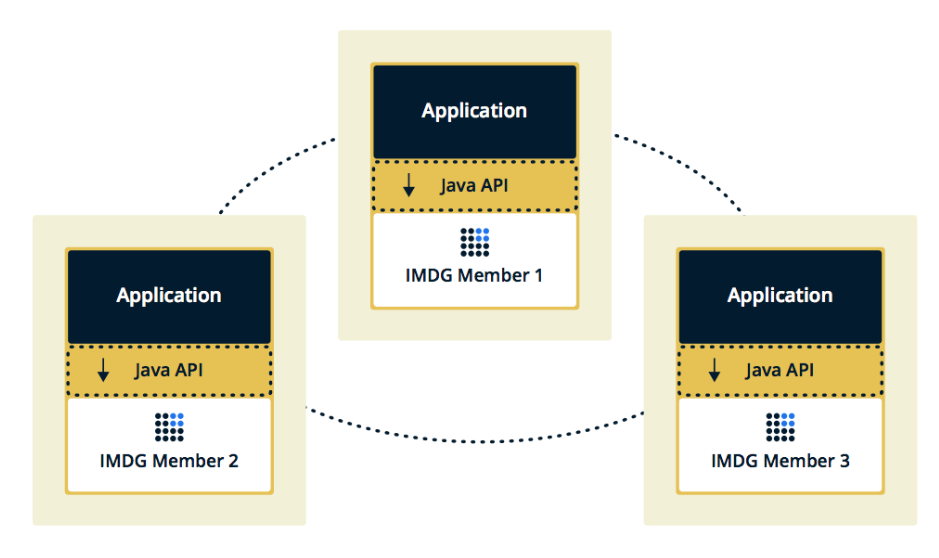
Nous avons choisi la deuxième solution car nous l'avons jugée plus efficace et économique à mettre en œuvre. Efficace, car la vitesse d'accès aux données Hazelcast sera plus faible, car peut-être que ces données sont sur le serveur actuel. Économique, car nous n'avons pas besoin de dépenser d'argent pour des instances supplémentaires.
Le cluster se bloque lorsque le membre se bloque
Quelques semaines après avoir activé Hazelcast, des problèmes sont apparus sur la prod.
Au début, notre surveillance a montré que l'un des serveurs commençait à surcharger progressivement la mémoire. Pendant que nous regardions ce serveur, les autres serveurs ont également commencé à se charger: le CPU a augmenté, puis la RAM, et après cinq minutes, tous les serveurs ont utilisé toute la mémoire disponible.
À ce stade des consoles, nous avons vu ces messages:
2015-07-15 15:35:51,466 [WARN] (cached18) com.hazelcast.spi.impl.operationservice.impl.Invocation: [my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7 2015-07-15 15:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService', op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783, waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0, tryCount=250, tryPauseMillis=500, invokeCount=1, callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
Ici, Hazelcast vérifie si l'opération envoyée au premier serveur «mourant» est en cours. Hazelcast a essayé de se tenir au courant et a vérifié l'état de l'opération plusieurs fois par seconde. En conséquence, il a spammé tous les autres serveurs avec cette opération, et après quelques minutes, ils ont volé hors de la mémoire, et nous avons collecté plusieurs Go de journaux de chacun d'eux.
La situation s'est répétée plusieurs fois. Il s'est avéré qu'il s'agit d'une erreur dans Hazelcast version 3.5, dans laquelle le mécanisme de pulsation a été implémenté, qui vérifie l'état des demandes. Il n'a pas vérifié certains des cas limites que nous avons rencontrés. J'ai dû optimiser l'application pour ne pas tomber dans ces cas, et après quelques semaines Hazelcast a corrigé l'erreur à la maison.
Ajout et suppression fréquents de membres de Hazelcast
Le prochain problème que nous avons découvert est l'ajout et la suppression de membres de Hazelcast.
Tout d'abord, je vais décrire brièvement comment Hazelcast fonctionne avec les partitions. Par exemple, il y a quatre serveurs, et chacun stocke une partie des données (dans la figure, elles sont de couleurs différentes). L'unité est la partition principale, le diable est la partition secondaire, c'est-à-dire sauvegarde de la partition principale.

Lorsqu'un serveur est éteint, les partitions sont envoyées à d'autres serveurs. Si le serveur meurt, les partitions ne sont pas transférées depuis celui-ci, mais depuis les serveurs qui sont toujours en vie et qui contiennent une sauvegarde de ces partitions.
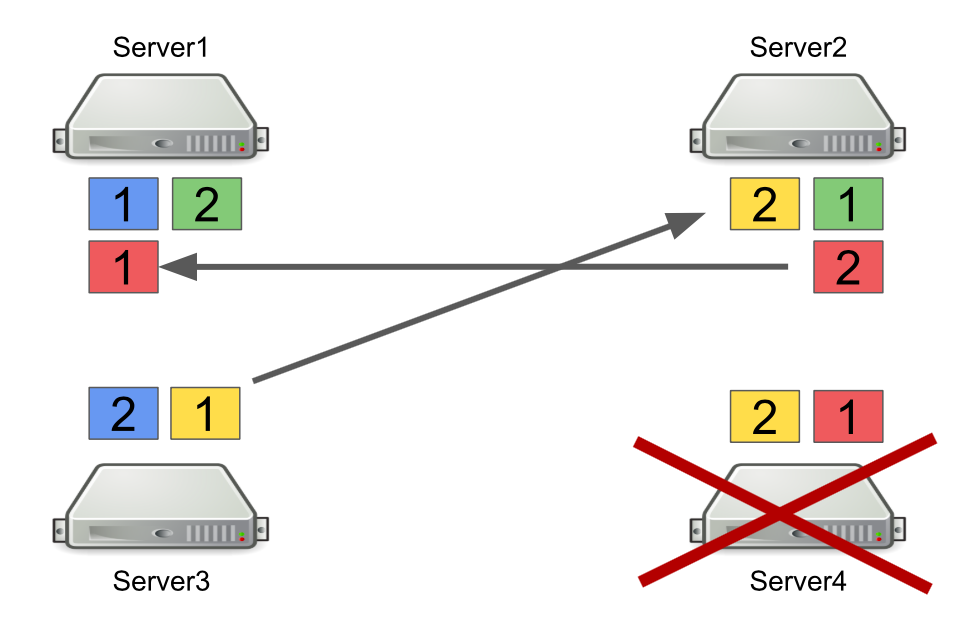
Il s'agit d'un mécanisme fiable. Le problème est que nous allumons et éteignons souvent les serveurs pour équilibrer la charge, et le rééquilibrage des partitions prend également du temps. Et plus il y a de serveurs en cours d'exécution et plus nous stockons de données dans Hazelcast, plus il faut de temps pour rééquilibrer les partitions.
Bien sûr, nous pouvons réduire le nombre de sauvegardes, c'est-à-dire partitions secondaires. Mais ce n'est pas sûr, car quelque chose va mal tourner.
Une autre solution consiste à basculer vers la topologie client-serveur afin que l'activation et la désactivation des serveurs n'affectent pas le cluster Hazelcast principal. Nous avons essayé de le faire et il s'est avéré que les demandes RPC ne pouvaient pas être effectuées sur les clients. Voyons pourquoi.
Pour ce faire, considérez l'exemple d'envoi d'une demande RPC à un autre serveur. Nous prenons le ExecutorService, qui vous permet d'envoyer des messages RPC, et de soumettre avec une nouvelle tâche.
hazelcastInstance .getExecutorService(...) .submit(new Task(), ...);
La tâche elle-même ressemble à une classe Java standard qui implémente Callable.
public class Task implements Callable<Long> { @Override public Long call() { return 42; } }
Le problème est que les clients Hazelcast peuvent être non seulement des applications Java, mais aussi des applications C ++, .NET et autres. Naturellement, nous ne pouvons pas générer et convertir notre classe Java vers une autre plate-forme.
Une option consiste à passer à l'utilisation des requêtes http au cas où nous voudrions envoyer quelque chose d'un serveur à un autre et obtenir une réponse. Mais nous devrons alors abandonner partiellement Hazelcast.
Par conséquent, comme solution, nous avons choisi d'utiliser des files d'attente au lieu de ExecutorService. Pour ce faire, nous avons mis en œuvre indépendamment un mécanisme pour attendre qu'un élément soit exécuté dans la file d'attente, qui traite les cas limites et renvoie le résultat au serveur demandeur.
Qu'avons-nous appris
Faites preuve de flexibilité dans le système. L'avenir change constamment, il n'y a donc pas de solutions parfaites. Pour bien faire, «bien» ne fonctionne pas, mais vous pouvez essayer d'être flexible et de l'intégrer dans le système. Cela nous a permis de reporter d'importantes décisions architecturales jusqu'au moment où il n'est plus impossible de les accepter.
Robert Martin dans Clean Architecture écrit sur ce principe:
«Le but de l'architecte est de créer une forme pour le système qui fera de la politique l'élément le plus important et les détails non liés à la politique. Cela retardera et retardera les décisions sur les détails. »
Il n'existe pas d'outils et de solutions universels. S'il vous semble qu'un cadre résout tous vos problèmes, ce n'est probablement pas le cas. Par conséquent, lors de la mise en œuvre d'un cadre, il est important de comprendre non seulement les problèmes qu'il résoudra, mais aussi ceux qu'il entraînera.
Ne réécrivez pas tout de suite. Si vous êtes confronté à un problème d'architecture et qu'il semble que la seule bonne solution est de tout écrire à partir de zéro, attendez. Si le problème est vraiment grave, trouvez une solution rapide et regardez comment le système fonctionnera à l'avenir. Très probablement, ce ne sera pas le seul problème en architecture, avec le temps vous en trouverez plus. Et ce n'est que lorsque vous sélectionnez un nombre suffisant de problèmes que vous pouvez commencer à refactoriser. Seulement dans ce cas, il y aura plus d'avantages que sa valeur.