Le principal avantage du marché de l'IoT est le coût. Par conséquent, la priorité est donnée aux composants bon marché mais peu fiables. Les appareils peu fiables se brisent, font des erreurs, gèlent et nécessitent une maintenance. Il n'est pas habituel de parler de manque de fiabilité lors de conférences, mais c'est exactement ce à quoi le rapport de
Stanislav Elizarov (
elstas ) sur InoThings ++ a été consacré - comment tout ne fonctionne pas.

Sous la coupe, nous discuterons des méthodes pour compenser le manque de fiabilité des équipements, des canaux de communication et du personnel utilisant des logiciels; les problèmes de tolérance aux pannes et leurs solutions; facteur humain; du ruban et des chaussettes électriques comme moyen universel de réparer les engins spatiaux et la transmission de données par les camions.
À propos du conférencier :
Stanislav Elizarov est engagé dans le département d'infrastructure de réseau de la société STRIZH, qui produit des compteurs, des capteurs, des stations de base LTE et collecte également des lectures là où tout autre système de communication ne fonctionne tout simplement pas.
Insécurité
"Si quelque chose ne fonctionne pas, alors il est déjà dépassé."
Ceci est une citation du philosophe canadien
Marshall McLuhan , qui décrit avec précision l'état de l'art. Tout refuse: les ordinateurs gèlent, les smartphones ralentissent, les ascenseurs s'arrêtent entre les étages, les sondes spatiales s'égarent et les gens font des erreurs.
Premières erreurs
Le sujet de la fiabilité, en particulier de sa part, est la tolérance aux pannes, aussi importante que la sécurité. La lettre S dans le terme IoT est responsable de la
sécurité , et la lettre R est responsable de la
fiabilité - fiabilité.
Si nous parlons de fiabilité et d'erreurs, alors rappelons
Johann Gutenberg . Officiellement, il est le premier imprimeur, et selon Ilf et Petrov, il est le
premier imprimeur , car il a fait de nombreuses erreurs dans sa Bible.

La technologie de Gutenberg a progressé, le marché du livre a augmenté, les volumes ont augmenté et avec eux des erreurs. 50 ans après l'impression du premier livre,
Gabriel Pierry a proposé Errata - une liste de fautes de frappe à la fin du livre. C'était une bonne astuce, car retaper de grands lots est peu pratique et économiquement non rentable. Si le lecteur remarque une faute de frappe, il ouvre simplement une liste d'erreurs et examine les corrections critiques. Le chef des fautes de frappe était Thomas d'Aquin et sa somme de théologie - 180 pages d'erreurs dans l'erreur officielle.
Les errats modernes sont produits par les producteurs de fer. Dans l'image ci-dessous, l'
errat officiel de la puce
CC1101 la plus populaire, qui est toujours valide. Dans la liste des erreurs, la puce n'accepte parfois pas quelque chose, parfois elle transmet quelque chose de mal et parfois la PLL ne fonctionne pas toujours. Ce n'est pas ce que vous attendez d'un processeur de masse qui existe depuis des décennies.

Un autre exemple est le microprocesseur
MSP430 , construit sur un ensemble d'instructions. Le microprocesseur est à peu près le même que le
PDP-11 , sur lequel Kernigan et Ritchie ont développé Unix. Ce n'est pas l'errat Thomas d'Aquin, mais le constructeur nous propose
27 pages d'erreurs , dont beaucoup lui-même ne sait pas résoudre.
C'est exactement ce qui n'est pas évident sur Internet des objets. Nous lisons la fiche technique d'une puce bon marché et voyons que tout va bien et que tout fonctionne, jusqu'à ce que nous ouvrions les dernières pages avec une liste d'erreurs.

Facteur humain
Avec le fer, c'est plus ou moins clair, les erreurs sont décrites et reproductibles, mais la plus grande source d'erreurs dans les systèmes IoT est l'
homme .
Le 13 janvier 2018, tous les habitants de Gavaev ont
reçu une alerte sur les téléphones portables
concernant une menace de missile et qu'ils devaient se cacher dans un abri anti-bombes.

On ne sait pas exactement qui avait tort: l'opérateur ou la personne qui a conçu l'interface. Mais si vous regardez l'image, la réponse se suggère. Sur quoi appuyer pour déclencher un test, plutôt qu'un combat, avertissant d'une menace de missile? Si vous ne connaissez pas la réponse, vous vous trompez.

Bonne réponseFausse alarme BMD
L'opératrice a appuyé sur le mauvais bouton et le publipostage a commencé. Le système ne comportait aucun paramètre permettant d'empêcher ou de confirmer l'envoi: "Êtes-vous sûr de vouloir mettre en garde contre la menace des missiles?" Il a fallu 30 minutes aux employés du centre pour se rendre compte de ce qui s'était passé et pour envoyer un message indiquant que l'attaque était fausse.
L'homme est un système fiable
Pourquoi ne voyons-nous pas ces erreurs et ne pensons-nous pas que quelque chose ne va pas? Parce que l'homme lui-même corrige toutes les erreurs.
Nous avons l'habitude de corriger les bugs.
Si nous pensons que l'ordinateur ne fonctionne pas très bien, nous le redémarrerons. Si nous voyons que la communication mobile a disparu, alors nous cherchons un endroit où elle prend. Si la machine ne fonctionne pas, nous la réparons.
La photo ci-dessous montre un savoir-faire humain dont vous pouvez être fier. Trois personnes se balançaient dans
l'Apollo 13 entre la Terre et la Lune et ont pu résoudre la tâche non triviale consistant à enfoncer un filtre carré dans un trou rond. En plus des filtres carrés, la mission n'a pas eu de chance dans un autre: explosion d'une bouteille d'oxygène, manque d'eau, dommages au moteur. L'équipe a essayé de survivre à l'aide de chaussettes, de ruban électrique et de paquets de combinaisons.

L'homme, comme ils l'ont dit à la NASA, est un très bon système de sauvegarde et corrige beaucoup. La résolution de problèmes sur un vaisseau spatial à l'aide de ruban et de chaussettes électriques peut être considérée comme presque fiable: cela se fait en peu de temps, cela fonctionnera avec garantie et les gens reviendront vivants, mais cela ne peut pas être autorisé à entrer en production.
Problème de tolérance aux pannes
Le problème de la tolérance aux pannes pour l'Internet des objets est très important car le nombre d'appareils augmente. Selon une société de conseil
McKinsey , en 2013, 10 milliards d'appareils IoT fonctionnaient dans le monde, et d'ici 2020, ce nombre passera à 30 milliards.

Nous ne pouvons tout simplement pas réparer physiquement tous ces compteurs - il n'y aura tout simplement pas assez de temps. Les systèmes qui ont été conçus pour être entretenus par des personnes ne nous aideront pas, mais nous les réparerons.
En 2018, la presse et les journaux scientifiques ont annoncé que les Chinois avaient couvert
100000 capteurs de 2 canaux sur une longueur totale de 1400 km. Un total de 130 types de capteurs: eau, vent, caméras. Du point de vue des dépenses d'exploitation, le système est tout simplement désastreux: combien de personnes avez-vous besoin pour nettoyer les caméras ou supprimer les accrocs? L'ensemble du personnel ne sera occupé qu'à nettoyer et entretenir le système - il n'est pas très autonome.
Par conséquent, je veux parler un peu de
tolérance aux pannes , d'assurer le fonctionnement du système. Avec des exemples simples, je parlerai de trucs qui aideront en peu de temps à obtenir une solution de travail garantie afin de présenter un produit aux investisseurs, puis je réfléchirai à la manière d'augmenter progressivement la fiabilité. Ces astuces sont assez polyvalentes et aideront toujours. La seule chose qu'ils ne sont pas très recommandés pour une utilisation en production, car ils sont comme ce filtre.
Imaginez: le jour viendra où les investisseurs viendront à vous pour un rapport de projet, et vous devrez montrer un produit fonctionnel. Par où commencer, pour ne pas le gâcher?
Simplification
Dans l'image ci-dessous, deux appareils non connectés. À gauche, un jouet appelé
«trieur» : insérez rond en rond et carré en carré. Un enfant d'un an apprendra à utiliser un jouet en 2-3 tentatives, car il est impossible de se tromper avec le «dispositif» - un triangle ne rentrera pas dans un carré.

La même idée a été proposée par la société Harris, qui produit des stations de radio militaires. La photo de droite est
Harris Falcon 3 , une merveille d'ingénierie. Regardez les interfaces, elles sont toutes différentes. Dans un état de bataille, dans des conditions où il n'y a pas de temps pour réfléchir, l'opérateur physiquement ne pourra pas faire quelque chose de mal. Le câble d'alimentation n'entrera pas dans le connecteur de l'antenne, et par un simple buste, l'opérateur radio connectera tous les systèmes, même pas le cerveau. Il s'agit d'un moyen simple et efficace de prévenir les erreurs et de réduire leur probabilité. Vous direz:
- Et si nous avons une présentation demain. Avons-nous besoin de souder toutes les interfaces? Nous avons tout fait de même là-bas: 4 ports USB, 5 ports Ethernet, nous allons certainement faire une erreur.Pas de doute, la simplification fonctionne également ici - fermez tout. Si vous avez 4 ports USB et que l'un d'eux est garanti de fonctionner, laissez-le et fermez le reste. Par exemple, avec du ruban électrique - sentez-vous comme un astronaute.
La simplification, ce n'est pas seulement créer une interface dans laquelle les erreurs sont impossibles, mais aussi supprimer tout ce qui est superflu. C'est là que la fiabilité commence.
Nous avons créé un appareil simple - un prototype, prêt à être montré. Et ensuite? Ensuite, pensez à la redondance.
Redondance
Les dispositifs de l'Internet des objets fonctionnent sur la base
de la théorie de l'information : il existe une source de signal, un récepteur, un encodeur, un modulateur, un milieu de propagation et une source d'erreur qui interfère et déforme la situation réelle. Un bon moyen de réduire les interférences consiste à
ajouter de la redondance , à l'aide de laquelle nous pouvons détecter une situation critique et en atténuer les effets: avertir l'opérateur ou corriger l'erreur.

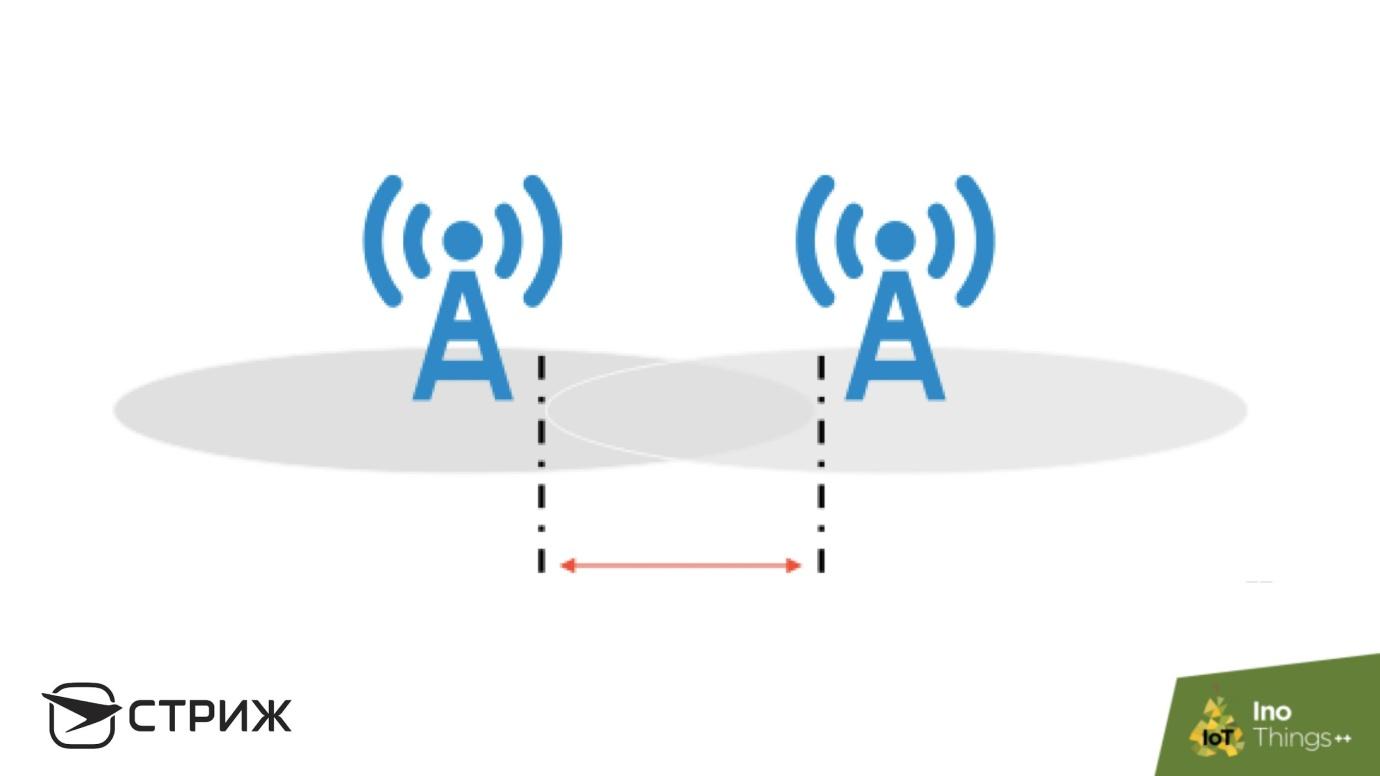
Un exemple de redondance est le réseau STRIZH. La plupart des appareils du réseau sont transmis sans confirmation: l'appareil émet un signal et la station de base le reçoit.
Imaginez la situation. Nous avons une zone d'interférence dans laquelle la probabilité de livraison de message à la station de base est de 90%, et lors de la présentation, il ne doit pas montrer plus de 1% de perte. Il semble qu'il y ait beaucoup de travail: corriger les protocoles, réduire la portée, mais une solution simple et rapide est la redondance. À côté de la station qui reçoit le signal avec une probabilité de livraison de 0,9, placez la seconde, avec la même probabilité de livraison, et la probabilité de défaillance des deux stations en même temps est de 0,01. Le
théorème de multiplication des probabilités s'applique ici: la probabilité de défaillance de chaque station individuellement est de 0,1, et la défaillance des deux n'est que de 1%, à condition que les stations de base soient indépendantes. Dans cette zone, la probabilité de réception entre les stations de base sera la plus élevée.
Une autre façon de démontrer le principe de redondance est
Watchdog Timer . Il s'agit d'un périphérique physique intégré par la plupart des fabricants de processeurs. Si le Watchdog Timer n'a pas reçu de signal de l'ordinateur après un certain temps, l'appareil redémarre l'ordinateur.

L'utilisation de WT n'améliore pas la fiabilité, mais la
disponibilité . L'ordinateur détecte le problème, prend des mesures de contrôle et redémarre l'ordinateur. Il aime beaucoup la NASA et
connaît de nombreuses façons d' utiliser Watchdog Timer.
Voici un exemple de temporisateur de surveillance à plusieurs étapes: lorsque certains événements se produisent, il envoie un
NMI - une interruption matérielle qui sera nécessaire pour travailler sur le processeur. Lorsqu'un événement se produit, Watchdog indique à l'ordinateur: "Essayez de vous redémarrer, sinon coupez l'alimentation." Si la première minuterie ne fonctionne pas, la seconde fonctionnera.

La redondance fonctionne bien dans le système d'exploitation. Notre station de base est structurée comme ceci. Il se compose de
modules divers et
indépendants . L'autonomie des modules empêche les erreurs d'un module à l'autre - un «pool» d'erreurs est créé, que nous bloquons. Plus haut dans la hiérarchie se trouve un
ensemble de superviseurs : des scripts qui surveillent la situation en fonction de certains paramètres. Par exemple, que le processus se trouve dans le système d'exploitation, ce n'est pas un zombie et ne découle pas de la mémoire. L'élément racine est un
planificateur , par exemple, cron.
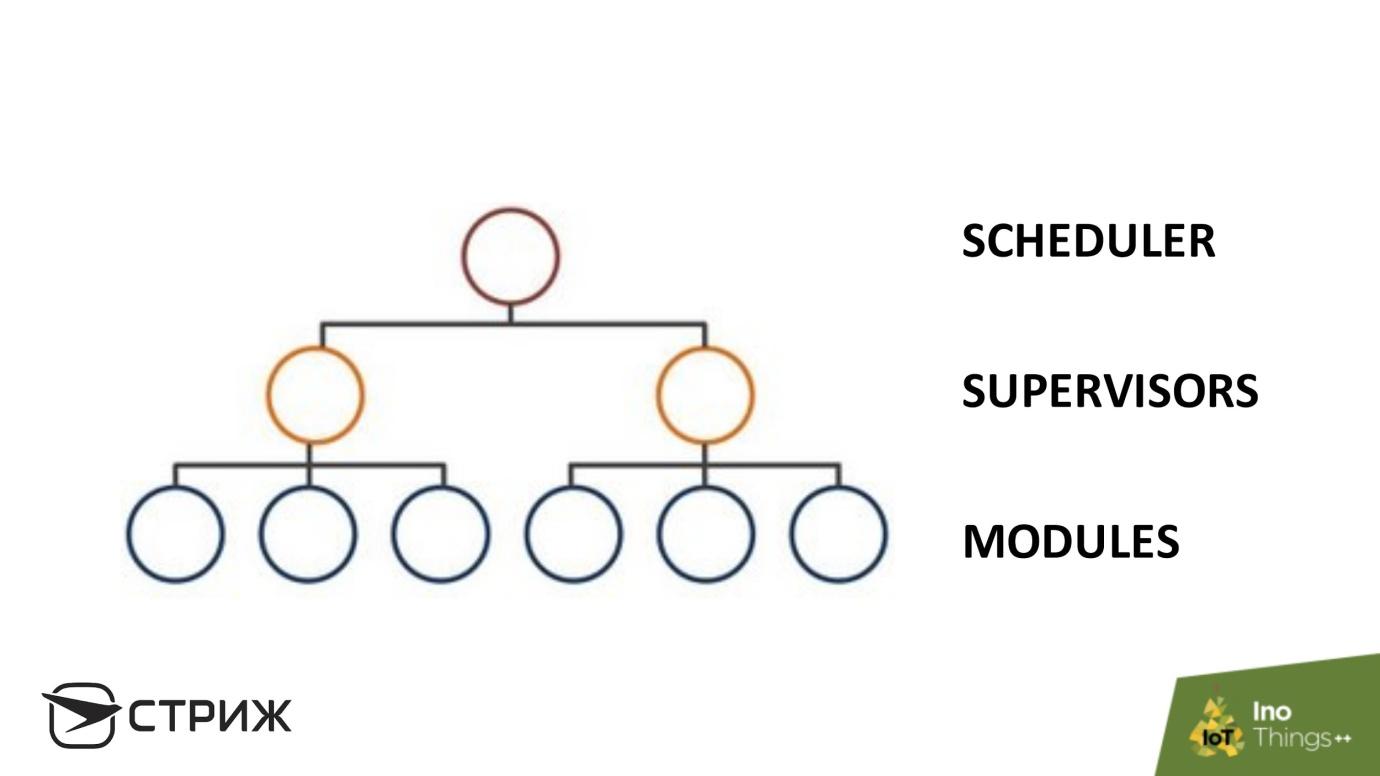
La structure hiérarchique crée de bons paramètres pour la disponibilité du système: si le module tombe, le superviseur voit et redémarre, il y a une certaine redondance dans les modules, certains modules remplissent la fonction des autres.
Transition vers un autre référentiel
Ma méthode préférée et la plus populaire parmi les mathématiciens. Si l'on sait dans quelles conditions l'équipement fonctionne, alors dans ces conditions il est nécessaire de conduire un pilote. Je vais vous montrer avec des exemples.
Exemple n ° 1 . Nous avons créé un appareil qui fonctionne bien à température ambiante, et ils nous disent:
- Nous démontrons le projet dans le Grand Nord. Maintenant, il y a −40, mais faites-le fonctionner.Nous fonctionnons sur Internet et recherchons une solution:
- Nous avons besoin de quartz et de lecteurs flash thermostables qui ne tomberont pas en panne à -40.Le temps presse, les ressources diminuent et la panique s'accentue. Nous pensons que le projet est un échec, mais nous serons sauvés par le passage au référentiel dans lequel opère la station de base. Nous plaçons l'appareil dans la boîte dans laquelle se trouvent le chauffage et le relais thermique. Ce sont des gars assez stables et travaillent presque toujours. Lorsqu'il fait froid dehors - la boîte chauffe et l'appareil fonctionne dans des conditions normales - nous sommes passés à un système de référence dans lequel nous connaissons et utilisons la solution.
 Exemple n ° 2
Exemple n ° 2 . Transition vers des images en mouvement. Imaginez que nous collections des données sur les conteneurs d'un train. La première solution standard consiste à utiliser des modems gsm. Cette méthode ne convient pas: pour les objets se déplaçant rapidement, vous devez utiliser des appareils LTE ou 5G qui font du bon travail avec Doppler, ce qui est cher. Si le train traverse la Russie, alors à son arrivée à la gare, tous les modems se connecteront à la gare et il se plantera simplement en raison de la congestion du réseau.
Solution: transition vers un référentiel fixe. Rappelons la relativité du mouvement: on place la station de base à l'intérieur du train et elle est immobile par rapport au train en mouvement. La station collectera les informations de tous les capteurs et transmettra plus loin à l'aide d'une passerelle, d'un satellite ou d'un modem LTE.
Cette approche augmente la fiabilité, aide à résoudre les tâches impossibles et organise un
réseau tolérant aux retards - un
réseau résistant aux ruptures . Pour une raison quelconque, ils n'aiment pas l'approche en Russie, mais ils font activement la promotion de la division
Disney Research de la même société. Ils n'ont pas l'Internet des objets, mais l'Internet des jouets -
Internet des jouets . L'entreprise craint que les enfants africains ne regardent pas les dessins animés Disney. Réaliser des réseaux de données, installer des tours, tirer de la fibre en Afrique coûte cher, et ils le voleront de toute façon, alors ils sont allés dans l'autre sens et ont utilisé
les idées de
Richard Hamming :
La transmission à distance est identique à la transmission dans le temps, c'est-à-dire le stockage. Si vous ne pouvez pas transmettre, enregistrez les informations et transférez-les au récepteur.
Disney a
fait exactement cela : ils ont équipé les gares routières et les bus d'un système de routeurs Wi-Fi les moins chers et d'un ensemble de disques durs. Le bus s'arrête à la gare, télécharge rapidement un ensemble de films Disney via Wi-Fi sur les lecteurs, puis démarre. Il vient dans un village, dans un autre, et télécharge des films dans chacun - les enfants africains sont satisfaits. Ce que l'on appelle les
Mul-Networks - des mules bon marché qui se déplacent lentement, font mal avec le Doppler, mais fournissent des informations à tous les points.
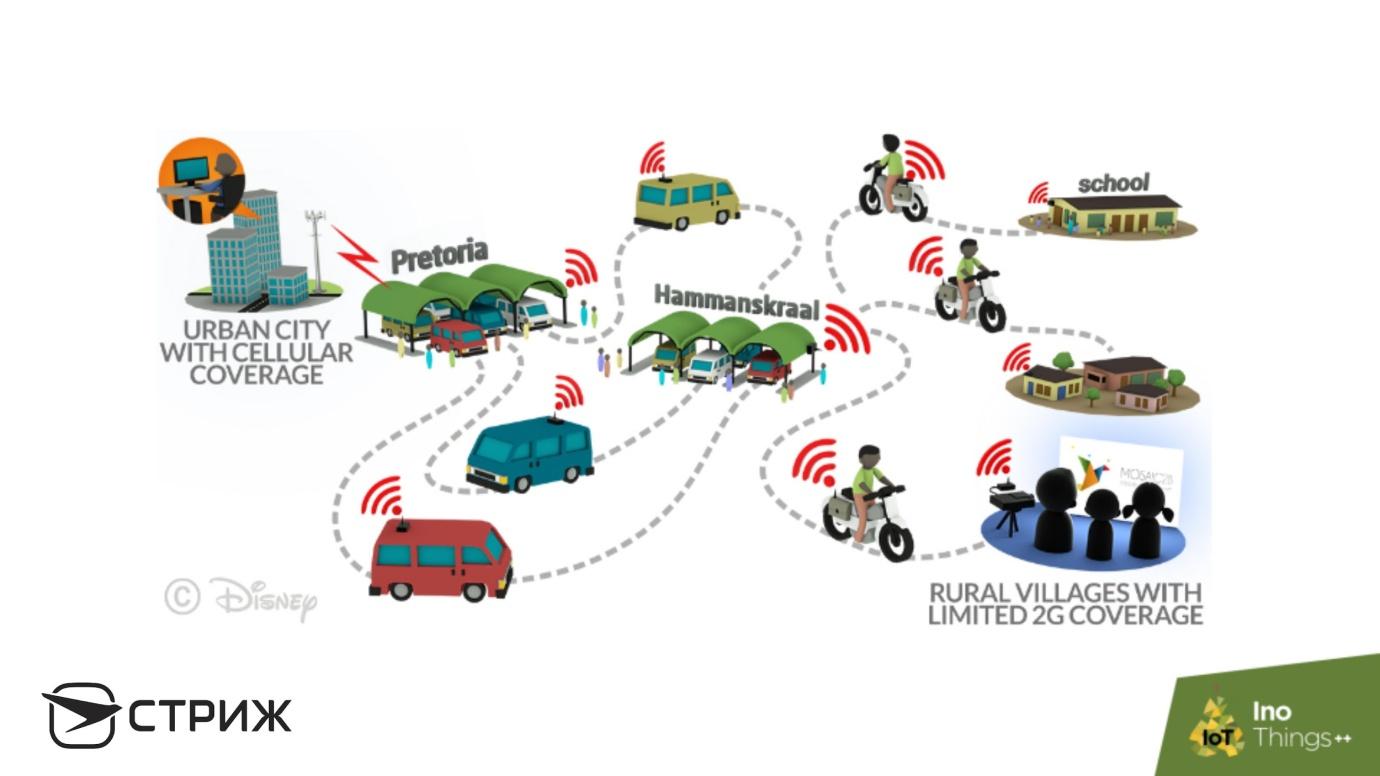
Des développements similaires existent à Disney pour l'envoi d'e-mails - une lettre vous parviendra par bus. Une technologie très amusante, mais Amazon, par exemple, l'adore.
Amazon dispose d'un service de transport d'
exaoctets de données - un million de téraoctets. Si vous avez un grand centre de données et que vous envisagez de déménager sur Amazon, car tout est déjà là, alors en Amérique, ils peuvent vous apporter un tel camion et transporter vos données. Si les retards ne sont pas importants pour vous, alors c'est un bon moyen: des taux de transfert de données de l'ordre de dizaines ou centaines de Gb / s. En plus des camions, Amazon peut vous envoyer un sac avec des disques durs - boule de neige.

Nous avons réalisé que la fiabilité est importante car les personnes et la technologie échouent. La fiabilité doit être considérée comme une sécurité. Pour les présentations pilotes, activez Watchdog, ajoutez de la redondance et simplifiez afin que vous ne puissiez pas vous tromper. Réfléchissez à la manière d'entrer dans les conditions dans lesquelles le système est garanti de fonctionner. Et maintenant passons à la dernière méthode, qui est différente des autres, et les techniciens l'ignorent souvent.
La beauté
Ils vous pardonneront beaucoup si votre prototype est magnifique. Si pendant la présentation quelque chose ne va pas et que tout échoue, vous entendrez: «Oui, tout est cassé, mais vous avez un produit tellement cool. Je pense que vous devez essayer à nouveau de vous améliorer. » Le principe fonctionne pour Tesla: l'entreprise a des problèmes d'expédition, de pilote automatique, d'accidents, mais tout le monde les aime, car les voitures ont un design cool. Pour cela, ils leur pardonnent tous.

Conclusions
L'avenir de l'Internet des objets est l'
insécurité : l'IoT est destiné aux marchés de masse, et pour le marché de masse, le facteur décisif est le prix. Ainsi, l'Internet des objets comprendra de nombreux appareils
bon marché et peu fiables . Avec le nombre croissant d'appareils, le nombre de pannes augmentera. Nous n'avons tout simplement pas assez de mains pour corriger toutes les erreurs. Par conséquent, la seule façon - les
appareils doivent gérer indépendamment les conséquences des pannes . Ce sont des systèmes autonomes qui doivent apprendre à se réparer.
Je vous suggère d'aborder le sujet de la fiabilité et d'apprendre à montrer les pilotes de manière cool en utilisant trois méthodes:
simplifier tout ce que vous pouvez,
ajouter de la redondance et
créer les conditions dans lesquelles le pilote est garanti de travailler. N'oubliez pas que nous sommes tous des gens et que nous ne sommes
pas guidés par la logique, mais par les sentiments , alors créez de
beaux projets .
Il n'y a aucun livre ni ensemble d'articles sur la fiabilité. Pour approfondir le sujet, commencez par un article sur l'
opérabilité, la fiabilité, la sécurité , puis étudiez l'expérience
du NASA Jet Propulsion Laboratory . Ils ont créé Voyager et Curiosity et
ils savent tout sur la fiabilité . Laissez-vous inspirer par les grands.
Il reste un peu plus d'un mois avant la prochaine conférence InoThings ++ Internet of Things Developers , qui aura lieu le 4 avril. Nous préparerons un programme qui couvrira tous les aspects du monde de l'Internet des objets: le développement de matériel et de logiciels pour les appareils, la sécurité des utilisateurs, les méthodes de transfert d'informations entre les appareils et le «serveur» et leurs tests, le fonctionnement et le changement des processus commerciaux sous l'influence des technologies IoT. Mais peut-être que votre rapport ne suffit pas pour couvrir tous les sujets - soumettez votre candidature avant le 1er mars.