 Projet de traduction Prometheus - Une solution de détection d'incendie basée sur l'IA
Projet de traduction Prometheus - Une solution de détection d'incendie basée sur l'IAMes collègues et moi travaillons sur le projet Prometheus (Prometheus), une solution de détection d'incendie précoce qui combine l'IA, la vision par ordinateur, les drones automatiques et les services de prévisions météorologiques. Ce complexe est conçu pour détecter les incendies de forêt avant qu'ils ne se transforment en véritable catastrophe. Nous voulons parler du projet plus en détail, comment il fonctionne et quel appareil théorique est à la base. Le matériel sera soumis aussi indépendamment que possible de technologies spécifiques, donc si vous êtes intéressé par des fonctionnalités d'implémentation spécifiques (CNTK, Faster R-CNN, conteneurs Docker, Python, framework .NET, etc.), accédez à notre
référentiel GitHub . Et nous ne mentionnons ici que les technologies utilisées.
Une petite introduction:
La motivation
En 2017, on estimait que les incendies de forêt coûtaient à l'économie américaine environ 200 milliards de dollars, ce qui représente un peu moins de dégâts causés par les ouragans. Mais la différence est que si vous éteignez les incendies avant qu'ils ne se développent, les pertes peuvent être considérablement réduites. Cependant, la tâche de détecter les incendies est une routine, difficile et nécessitant la participation de personnes: pour la plupart, ils sont assis sur les tours d'observation avec des jumelles, essayant de remarquer l'incendie à temps, ou survolent le territoire en hélicoptères ou en drones guidés. Le projet Prometheus est conçu pour automatiser toute cette routine à l'aide de drones automatiques qui détecteront les incendies à un stade précoce, sinon le vent, la sécheresse ou les caractéristiques du terrain aideront le feu à se propager à des hectares de la région en quelques minutes. De plus, la plupart de ces incendies se produisent dans des zones reculées où il y a peu de personnes et personne pour suivre la fréquence des foyers.
Si vous envoyez des drones pour patrouiller dans ces régions éloignées, ils aideront à détecter les incendies à temps et à minimiser les dommages.
Projet
Prométhée peut être divisé en trois parties:
- Le module de détection d'incendie utilise des algorithmes d'apprentissage en profondeur pour identifier les petits foyers à l'aide de la caméra RVB du drone (implémentée en tant que service REST cloud).
- Le module de planification de vol permet à l'utilisateur de sélectionner et de planifier des zones de patrouille (implémentées en tant qu'application Windows et intégrées aux services de cartographie météorologique).
- Le système d'avertissement permet à l'utilisateur d'informer rapidement l'équipe d'un incendie détecté (à l'aide d'Azure Functions et de Twilio).
Détection incendie
Nous utilisons des drones automatisés pour rechercher des incendies dans des zones reculées. Des caméras RVB embarquées sont utilisées pour photographier toute la zone, puis les photos sont transmises à un modèle d'apprentissage automatique qui recherche les incendies et avertit l'utilisateur. Merci à tous, tout le monde est libre. Mais bon ...
Première leçon: la taille compte
Déterminer les incendies en utilisant la vision par ordinateur dans les proportions dont nous avions besoin était une tâche difficile, et nous avons donc utilisé une approche différente. Vous pensiez probablement que l'utilisation de caméras RVB n'est pas pratique car les caméras infrarouges sont préférables dans ce cas. Mais après avoir parlé avec les pompiers, nous avons découvert que ce n'est pas si simple: les endroits avec une température de l'air élevée ressembleront à des incendies sur des caméras infrarouges, et certaines parties de la surface ressembleront à des sources de chaleur uniquement en raison des particularités de la réflexion de la lumière. De plus, ces caméras sont beaucoup plus chères. Les pompiers les utilisent surtout la nuit pour voir s'ils ont réussi à éteindre complètement le feu.
En général, si vous souhaitez utiliser l'apprentissage automatique pour classer une image dans une catégorie spécifique - feu / pas feu - vous utiliserez probablement les techniques de classification. C'est aussi simple que ça. Mais il se peut que les caractéristiques requises pour la classification soient trop petites par rapport à l'image complète. Par exemple, une petite source d'inflammation typique ressemble à ceci:

Dans de tels cas, y compris le nôtre, les meilleures performances dans la détermination des objets peuvent être obtenues si vous ne faites pas attention à leur emplacement spécifique ou comptez le nombre dans l'image. Mais le plus souvent, le système de dispositifs pour déterminer les objets est beaucoup plus compliqué. Il existe différentes façons de résoudre ce problème, et nous avons utilisé le réseau neuronal convolutif régional (R-CNN), ou plutôt, la mise en œuvre de Faster R-CNN.
YoLo et
Detectron sont également souvent utilisés (récemment passés à l'open source).
Le processus comprend les étapes suivantes:
- Localisation: vous devez générer des sections (échantillons) de zones dans l'image qui peuvent contenir les objets souhaités. Ces zones sont appelées régions d'intérêt (ROI). Ce sont de grands ensembles de cadres couvrant toute l'image. Nous générons un retour sur investissement à l'aide de la technique décrite dans Segmentation as Selective Search for Object Recognition par Koen EA van de Sande et d'autres. La technique est implémentée dans la bibliothèque Python dlib.
- Classification des objets: en outre, les propriétés visuelles sont extraites de chaque trame, leur évaluation est effectuée et le système suppose s'il y a des objets et ce qu'ils sont (voir ci-dessous).
- Suppression non maximale: il arrive que les images représentant le même objet se chevauchent partiellement ou complètement les unes sur les autres. Pour éviter une telle duplication, les trames qui se croisent sont combinées en une seule. Cette tâche peut nécessiter beaucoup de puissance de calcul, mais certaines optimisations sont implémentées dans la bibliothèque mathématique Intel.
Leçon deux: vos données peuvent avoir besoin d'aide
L'apprentissage automatique a besoin de données. Mais dans l'apprentissage en profondeur (c'est-à-dire dans un espace d'entrée multidimensionnel), vous aurez besoin de beaucoup de données pour extraire les propriétés visuelles d'intérêt. Comme vous le comprenez, il est difficile de trouver un grand ensemble de données d'objets qui nous intéressent (incendies). Pour résoudre ce problème, nous avons utilisé la technique d '«apprentissage par transfert» avec des modèles de classification d'images polyvalents pré-formés pour extraire les propriétés visuelles, car ils peuvent bien se généraliser. Autrement dit, vous prenez un modèle pré-formé pour définir quelque chose et le "configurez" à l'aide de votre ensemble de données. Autrement dit, ce modèle extraira des propriétés et vous essaierez déjà d'utiliser leurs représentations apprises pour la tâche A (généralement une tâche de haut niveau) pour résoudre le problème B (généralement de faible niveau). Le succès de la résolution du problème B indique dans quelle mesure le modèle de la tâche A a pu en apprendre davantage sur la tâche B. Dans notre cas, la tâche A était la tâche de classer les objets ImageNet et la tâche B d'identifier les incendies.
Cette technique peut être appliquée en supprimant la dernière couche d'un réseau neuronal pré-formé et en la remplaçant par votre propre classificateur. Ensuite, nous gelons les poids de toutes les autres couches et formons le réseau neuronal de la manière habituelle.
Le réseau de neurones résultant n'est pas disponible sur GitHub en raison de sa taille - environ 250 Mo. Si vous en avez besoin, écrivez-
nous .
Il existe de nombreux modèles déjà formés pour ImageNet (AlexNet, VGG, Inception, RestNet, etc.). Dans chacun d'eux, les auteurs ont utilisé différents compromis de vitesse, de précision et de structure. Nous avons choisi AlexNet, car il nécessite moins de ressources de calcul et les résultats de notre tâche diffèrent peu des autres réseaux.
Troisième leçon: les vidéos (en particulier leurs images individuelles) sont vos meilleures amies
Mais malgré le transfert de formation, nous avons encore besoin de beaucoup de données pour résoudre le problème de classification. Et puis nous avons profité de la vidéo. Vous pouvez extraire un tas d'images de chaque vidéo et obtenir rapidement un grand ensemble de données volumineux. La vidéo a une autre propriété utile: si un objet ou une caméra se déplace, vous obtenez des images de l'objet avec un éclairage différent, sous différents angles et dans différentes positions, de sorte que l'ensemble de données est de très haute qualité.
Nous n'avons pas non plus téléchargé notre ensemble d'images dans le référentiel, en raison de la taille, de la frappe.
Nous avons collecté des vidéos de drones de diverses sources et les avons étiquetées manuellement. Il existe plusieurs outils pour étiqueter des images dans différents formats, selon le cadre d'apprentissage approfondi utilisé. Je recommande LabelImg pour Linux / Windows et RectLabel pour Mac. Nous avons utilisé CNTK, nous avons donc opté pour un outil Microsoft VoTT qui peut exporter aux formats CNTK et TensorFlow.
Leçon quatre: acheter une carte vidéo (ou louer un cloud)
La formation d'un grand modèle comme le nôtre nécessite une puissance de calcul considérable, et le GPU sera d'une grande aide. Il nous a fallu environ 15 minutes pour apprendre à utiliser la NVIDIA GeForce GTX 1050. Mais même malgré l'utilisation d'une carte vidéo, la définition des paramètres du modèle est une grande difficulté. Microsoft dispose d'un bon outil appelé Azure Experimentation Service, qui vous permet d'exécuter plusieurs formations avec différents paramètres dans le cloud en parallèle et d'analyser la précision obtenue. Jetez également un œil à AWS SageMaker.
Notre référentiel contient
le script Sweep_parameters.py , qui
effacera automatiquement l'espace paramétrique et commencera les tâches d'entraînement.
C'est fait!
Nous avons donc formé notre R-CNN et nous en sommes débarrassés avec le transfert de formation, de deep learning, de cartes vidéo, etc. Comment partager maintenant notre travail avec les autres? Tout d'abord, nous avons lancé un service REST pour interagir avec le modèle. L'API vous permet d'envoyer des images pour évaluation et renvoie des zones d'images, la présence de feu pour laquelle le modèle a déterminé avec une certaine certitude. Vous pouvez également indiquer à l'API si l'image est réellement déclenchée ou non. D'autres points de terminaison sont utilisés pour les commentaires et les améliorations.
Le service API REST est conditionné dans un conteneur Docker et publié dans le cloud, ce qui vous permet de faire évoluer la solution à moindre coût. Dans le référentiel, vous pouvez trouver le fichier avec l'image Docker.
Planification de vol
Avertissements rouges
Comment Prométhée sait-il où envoyer des drones? Nous nous intégrons aux services météorologiques nationaux pour identifier les «alertes rouges». Ce sont des domaines dans lesquels la température de l'air, la direction et la force du vent, l'humidité et la pression atmosphérique augmentent la probabilité d'incendies. Étant donné que les services météorologiques sont orientés vers leur pays, ils peuvent difficilement être utilisés pour des recherches à l'étranger. Aujourd'hui, nous travaillons avec des services américains et argentins.
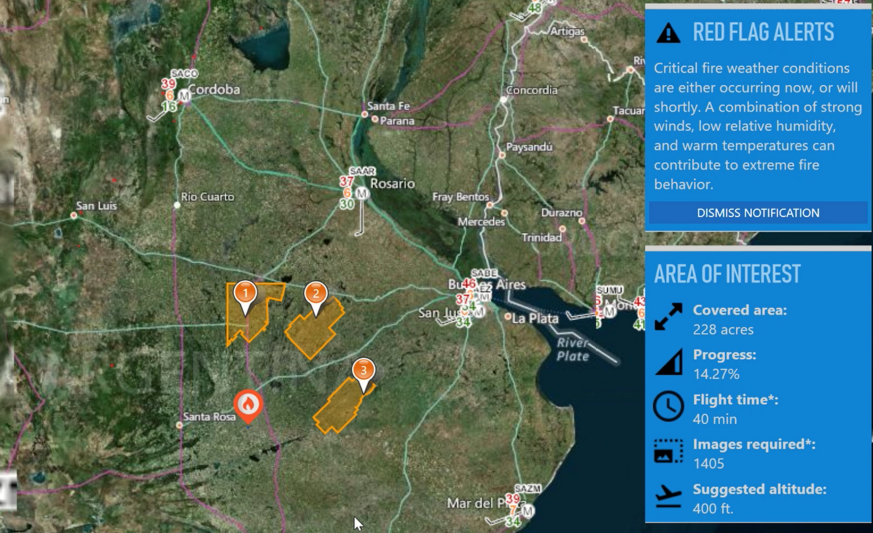
Information météo
Il est très important d'avoir des données météorologiques précises dans les zones d'intérêt. Les pompiers nous ont posé des questions sur cette fonction. Nous obtenons des données météorologiques en sondant les stations météorologiques via le serveur de cartes du National Weather Service et en superposant les informations reçues sur la carte. Nous soulignons qu'il ne s'agit pas d'une prévision météo, mais de vraies mesures:
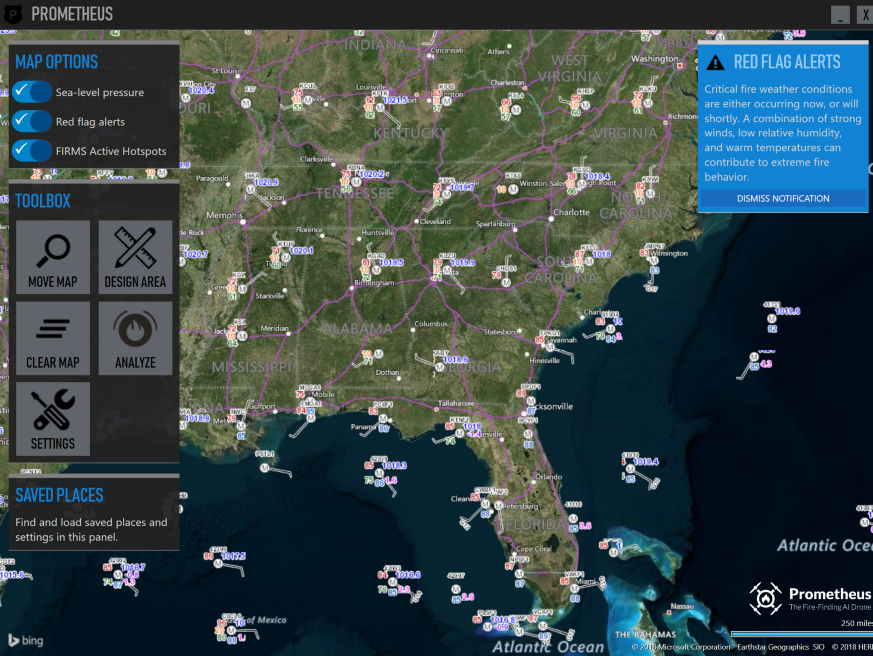 Stations météorologiques aux États-Unis
Stations météorologiques aux États-Unis .
Vous ne comprenez pas comment fonctionne cette carte? Vous n'êtes pas seul dans ce domaine. Il nous a fallu plusieurs semaines pour comprendre comment l'utiliser. Il y a peu d'informations sur le net. Si vous souhaitez expérimenter avec les données des stations météorologiques, vous devrez obtenir des clés API auprès des fournisseurs, car nous n'avons pas le droit de les partager.
Système d'alerte
Lorsque le système détecte un incendie, il demande à l'opérateur de confirmer le fait de la détection. L'interface ressemble à ceci:
 Fenêtre de confirmation d'incendie
Fenêtre de confirmation d'incendie .
Comme vous pouvez le voir, le système fonctionne de manière assez précise même dans des cas difficiles comme celui-ci. Un petit cadre rouge décrit les limites du feu avec une probabilité de 67%. En fait, Prometheus essaie de détecter les grands incendies et est instable lors du calcul des zones dans des scénarios comme celui-ci. Tout est en ordre, comme prévu. Nous n'étions tout simplement pas intéressés par de telles situations.
Le système d'avertissement envoie une notification par SMS avec les coordonnées GPS de l'incendie aux numéros de téléphone pré-enregistrés. La distribution est effectuée à l'aide de Twilio, une plateforme cloud dont les API permettent, entre autres, d'envoyer et de recevoir des messages texte par programmation.
Vous voulez jeter un œil?
→
Le code source est iciRemerciements
Prometheus a été développé en collaboration avec le service d'incendie de Tempe en Arizona, le service des incendies d'Argentine et l'Institut national argentin de technologie agricole d'Argentine.