Salut Habr.
Après la publication du classement des articles pour
2017 et
2018 , l'idée suivante était évidente: collecter une note généralisée pour toutes les années. Mais la simple collecte de liens serait banale (mais également utile), il a donc été décidé d'étendre le traitement des données et de collecter des informations plus utiles.

Notes, statistiques et un peu de code source en Python sous le chat.
Traitement des données
Ceux qui sont immédiatement intéressés par les résultats peuvent sauter ce chapitre. En attendant, nous découvrirons comment cela fonctionne.
En tant que données source, il existe un fichier csv approximativement du type suivant:
datetime,link,title,votes,up,down,bookmarks,views,comments 2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ ",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56 2006-07-13T20:45Z,https://habr.com/ru/post/2/," … !",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37 ... 2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — ",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6 2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda- SQL… ",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
L'index de tous les articles de ce formulaire prend 42 Mo, et pour le collecter, il a fallu environ 10 jours pour exécuter le script sur le Raspberry Pi (le téléchargement s'est déroulé en un seul flux avec des pauses afin de ne pas surcharger le serveur). Voyons maintenant quelles données peuvent être extraites de tout cela.
Audience du site
Commençons par une question relativement simple: nous évaluerons l'audience du site pour toutes les années. Pour une estimation approximative, vous pouvez utiliser le nombre de commentaires sur les articles. Téléchargez les données et affichez un graphique du nombre de commentaires.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') def to_int(s):
Les données ressemblent à ceci:

Le résultat est intéressant - il s'avère que depuis 2009 l'audience active du site (ceux qui laissent des commentaires sur les articles) n'a pratiquement pas augmenté. Bien que peut-être tous les employés des TI soient juste là?
Puisque nous parlons du public, il est intéressant de rappeler la dernière innovation de Habr - l'ajout d'une version anglaise du site. Liste des articles avec "/ en /" dans le lien.
df = df[df['link'].str.contains("/en/")]
Le résultat est également intéressant (l'échelle verticale est spécialement la même):

La flambée du nombre de publications a commencé le 15 janvier 2019, lors de l'annonce de
Hello world! Ou Habr en anglais , cependant, plusieurs mois avant la publication de ces 3 articles:
1 ,
2 et
3 . C'était probablement des tests bêta?
Identifiants
Le prochain point intéressant, que nous n'avons pas abordé dans les parties précédentes, est la comparaison des identifiants d'articles et des dates de publication. Chaque article a un lien de type
habr.com/en/post/N , la numérotation des articles est de bout en bout, le premier article a l'identifiant 1, et celui que vous lisez est 441740. Il semble que tout soit simple. Mais pas vraiment. Vérifiez la correspondance des dates et des identifiants.
Téléchargez le fichier dans le cadre de données Pandas, sélectionnez les dates et l'identifiant, puis tracez-les:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments']) dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f') dates += datetime.timedelta(hours=3) df['datetime'] = dates def link2id(link):
Le résultat est surprenant - les identifiants ne sont pas toujours pris dans une rangée, comme supposé à l'origine, il y a des «valeurs aberrantes» notables.
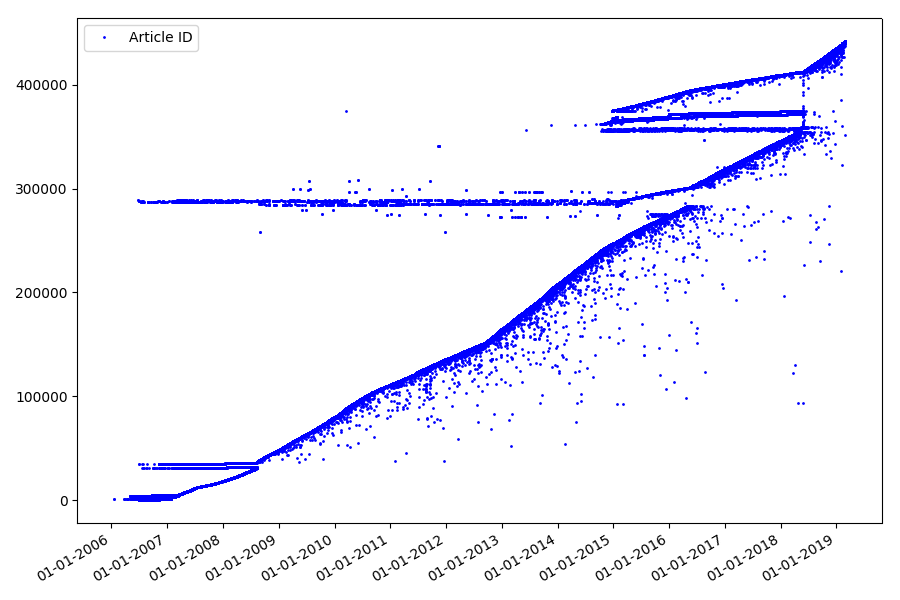
En partie à cause d'eux, le public a posé des questions sur les notes pour 2017 et 2018 - ces articles avec la «mauvaise» pièce d'identité n'ont pas été pris en compte par l'analyseur. Pourquoi si difficile à dire et pas si important.
Qu'est-ce qui pourrait être intéressant avec les identifiants? Il y a une hypothèse que je ne peux pas prouver formellement, mais qui semble évidente. Un identifiant est attribué au moment de la rédaction du projet d'article, et la date de publication vient évidemment plus tard. Quelqu'un publie l'article le même jour, quelqu'un publie le matériel plus tard. Pourquoi tout ça? Plaçons les identifiants sur l'axe X et les dates verticalement et voyons un fragment du graphique plus en détail:
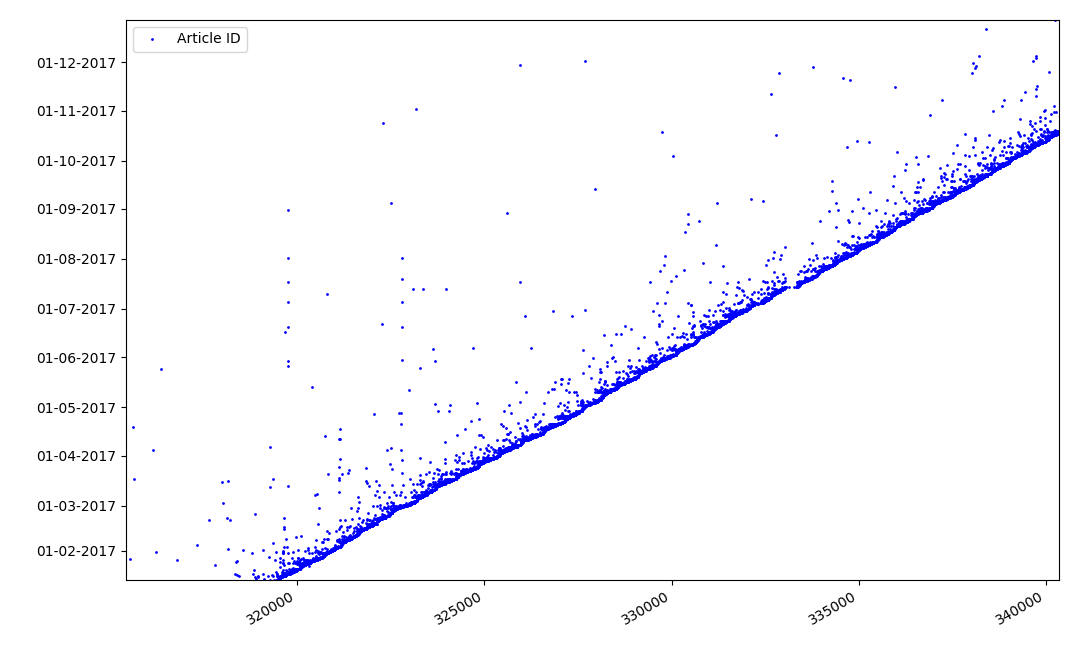
Résultat - nous voyons un nuage de points au-dessus de la ligne continue, qui nous montre la répartition du temps pour la
durée de la création d'articles . Comme vous pouvez le voir, le maximum tombe sur l'intervalle jusqu'à 1-2 semaines. La quasi-totalité de la masse d'articles est créée en moins d'un mois, bien que certains articles soient publiés plusieurs mois après la création du projet (bien sûr, cela ne nous garantit pas que l'auteur a travaillé sur l'article pendant plusieurs mois quotidiennement, mais le résultat est encore assez intéressant).
Date et heure de publication
Un point intéressant, quoique intuitif, est le moment de la publication des articles.
Statistiques de sortie les jours ouvrables:
print("Group by hour (average, working days):") df_workdays = df[(df['day'] < 5)] g = df_workdays.groupby(['hour']) hour_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = hour_count['counts'] print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_hours = grouped['hour'].values view_hours_avg = grouped['counts'].values fig, ax = plt.subplots() plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)') ax.set_xticks(range(24)) ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00')) plt.legend(loc='best') fig.autofmt_xdate() plt.tight_layout() plt.show()
La dépendance du nombre d'articles au moment de la publication en semaine:
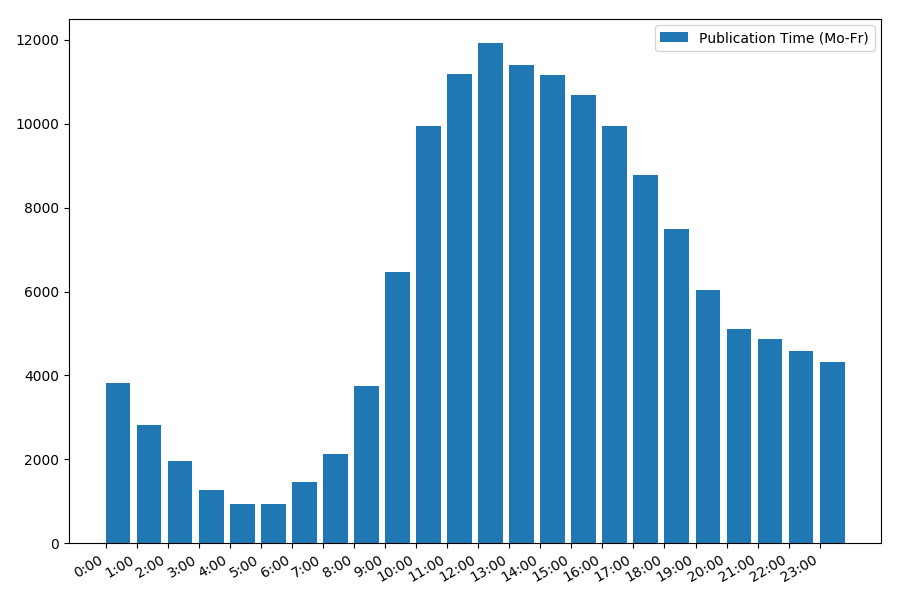
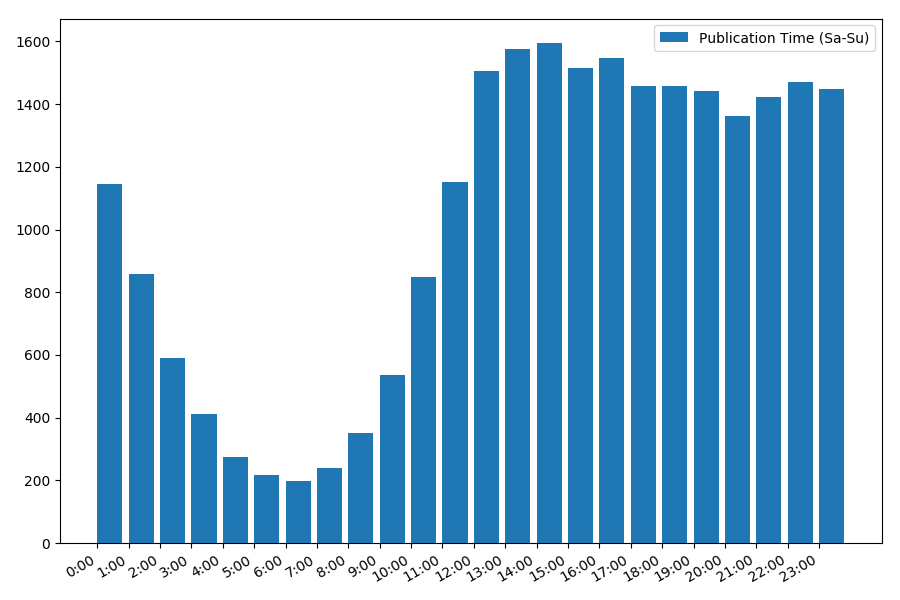
L'image est intéressante, la plupart des publications tombent sur les heures de travail. Toujours intéressant, pour la plupart des auteurs, écrire des articles est le travail principal, ou le font-ils simplement pendant les heures de travail? ;) Mais le calendrier de distribution du week-end donne une image différente:
Puisque nous parlons de date et d'heure, voyons la valeur moyenne des vues et le nombre d'articles par jour de la semaine.
g = df.groupby(['day', 'dayofweek']) dayofweek_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = dayofweek_count['counts'] grouped.sort_values('day', ascending=False) print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_days = grouped['day'].values view_per_day = grouped['views'].values counts_per_day = grouped['counts'].values days_of_week = grouped['dayofweek'].values plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day') plt.bar(view_days, counts_per_day, align='edge', label='Amount/day') plt.xticks(view_days, days_of_week) plt.ylim(bottom=0, top=10000) plt.show()
Le résultat est intéressant:
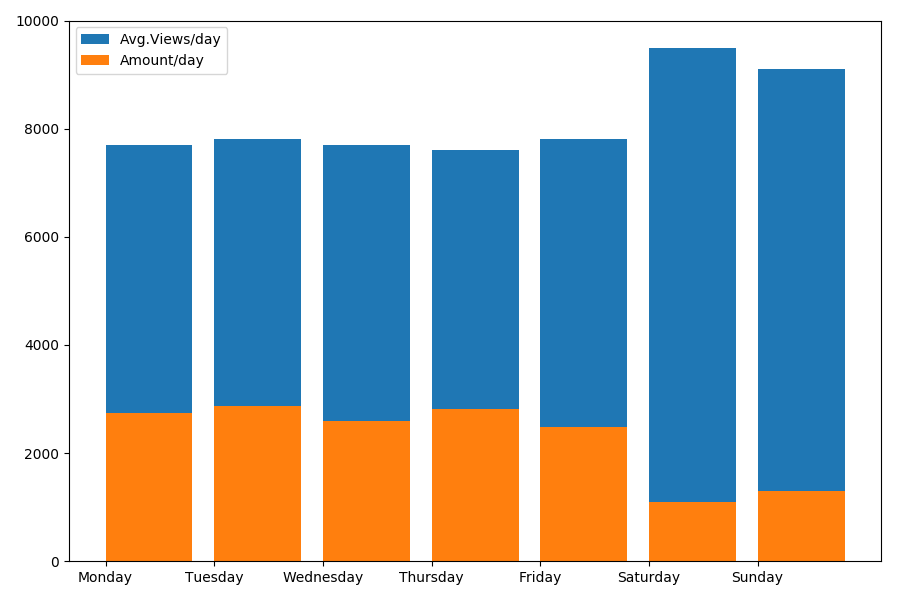
Comme vous pouvez le voir, il y a sensiblement moins d'articles publiés le week-end. Mais ensuite, chaque article gagne plus de vues, donc publier des articles le week-end semble tout à fait conseillé (comme cela a été trouvé dans la
première partie , la durée de vie active de l'article ne dépasse pas 3-4 jours, donc les premiers jours sont assez critiques).
L'article devient peut-être trop long. La fin dans la
deuxième partie .