
Je vais partager une histoire sur un petit projet: comment trouver les réponses de l'auteur dans les commentaires sans savoir qui est l'auteur de l'article.
J'ai commencé mon projet avec un minimum de connaissances sur l'apprentissage automatique et je pense qu'il n'y aura rien de nouveau pour les spécialistes ici. Ce matériel est, en un sens, une compilation de différents articles, je vais y dire comment il a abordé la tâche, dans le code, vous pouvez trouver des petites choses et des astuces utiles avec le traitement du langage naturel.
Mes données initiales étaient les suivantes: une base de données contenant 2,5 millions de supports et 39,5 millions de commentaires à leur sujet. Pour 1M de messages, d'une manière ou d'une autre, l'auteur du matériel était connu (ces informations étaient soit présentes dans la base de données, soit obtenues en analysant des données pour des motifs indirects). Sur cette base,
un ensemble de données a été créé à partir de 215 000 enregistrements balisés.
Au départ, j'ai utilisé une approche heuristique émise par l'intelligence naturelle et traduite en requêtes SQL avec recherche plein texte ou expressions régulières. Les exemples les plus simples de texte à analyser: "merci pour le commentaire" ou "merci pour les bonnes notes" c'est l'auteur dans 99,99% des cas, et "merci pour le travail" ou "merci!" Envoyez du matériel par la poste. Merci! " - révision ordinaire. Avec une telle approche, seules les coïncidences évidentes pourraient être filtrées, à l'exception des cas de fautes de frappe banales ou lorsque l'auteur est en dialogue avec des commentateurs. Par conséquent, il a été décidé d'utiliser des réseaux de neurones, cette idée n'est pas venue sans l'aide d'un ami.
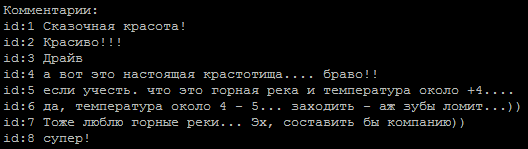
Une séquence typique de commentaires, lequel d'entre eux est l'auteur?
La méthode de détermination de la tonalité du texte a été prise comme base, la tâche est simple pour nous en deux classes: l'auteur et non l'auteur. Pour former des modèles, j'ai utilisé un
service de Google qui fournit des machines virtuelles avec un GPU et une interface notebook Jupiter.
Exemples de réseaux trouvés sur Internet:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
sur les lignes débarrassées des balises html et des caractères spéciaux, ils ont donné environ 65 à 74% de précision, ce qui ne différait pas beaucoup du lancer d'une pièce.
Un point intéressant est que l'alignement des séquences d'entrée via
pad_sequences(x_train, maxlen=max_len, padding='pre') donné une différence significative dans les résultats. Dans mon cas, le meilleur résultat était avec padding = 'post'.
L'étape suivante a été l'utilisation de la lemmatisation, qui a immédiatement permis d'augmenter la précision jusqu'à 80% et cela pourrait être approfondi. Maintenant, le principal problème est l'effacement correct du texte. Par exemple, les fautes de frappe dans le mot «merci» ont été converties (les fautes de frappe ont été sélectionnées en fonction de la fréquence d'utilisation) en une telle expression régulière (ces expressions ont accumulé une demi-à deux douzaines).
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
Ici, je voudrais remercier tout particulièrement les personnes trop polies qui jugent nécessaire d'ajouter ce mot à chacune de leurs phrases.
Il était nécessaire de réduire la proportion de fautes de frappe, car à la sortie du lemmatiseur ils donnent des mots étranges et on perd des informations utiles.
Mais il y a une doublure argentée, nous en avons assez de faire face aux fautes de frappe, au nettoyage de texte complexe, j'ai utilisé la représentation vectorielle des mots - word2vec. La méthode a permis de traduire toutes les fautes de frappe, les fautes de frappe et les synonymes en vecteurs étroitement espacés.

Mots et leurs relations dans l'espace vectoriel.
Les règles de nettoyage ont été considérablement simplifiées (aha, conteur), tous les messages, noms d'utilisateurs, ont été divisés en phrases et téléchargés dans un fichier. Un point important: en raison de la brièveté de nos commentateurs, pour construire des vecteurs de haute qualité, les mots ont besoin d'informations contextuelles supplémentaires, par exemple du forum et de Wikipedia. Trois modèles ont été formés sur le fichier résultant: word2vec classique, Glove et FastText. Après de nombreuses expériences, il a finalement choisi FastText, comme le groupe de mots le plus qualitatif dans mon cas.
Tous ces changements ont apporté une précision stable de 84 à 85%.
Exemples de modèles def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
et 6 autres modèles en
code . Certains modèles sont issus du réseau, d'autres sont inventés indépendamment.
Il a été remarqué que différents commentaires se démarquaient sur différents modèles, ce qui a donné l'idée d'utiliser des ensembles de modèles. J'ai d'abord assemblé l'ensemble manuellement, en choisissant les meilleures paires de modèles, puis j'ai fait un générateur. Afin d'optimiser la recherche exhaustive, j'ai pris le code gris comme base.
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
Avec l'ensemble, «la vie est devenue plus amusante» et le pourcentage actuel de précision du modèle est de 86 à 87%, ce qui est principalement associé à la classification de mauvaise qualité de certains auteurs dans l'ensemble de données.

Les problèmes que j'ai rencontrés:
- Ensemble de données déséquilibré. Le nombre de commentaires des auteurs était nettement inférieur à celui des autres commentateurs.
- Les classes de l'échantillon vont dans un ordre strict. L'essentiel est que le début, le milieu et la fin diffèrent considérablement dans la qualité de la classification. Cela est clairement visible dans le processus d'apprentissage sur le calendrier de la mesure f1.
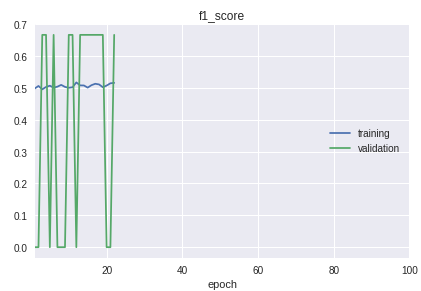
Pour la solution, un vélo a été fabriqué pour la séparation en échantillons de formation et de validation. Bien que dans la pratique dans la plupart des cas, la procédure train_test_split de la bibliothèque sklearn est suffisante.
Graphique du modèle de travail actuel:

En conséquence, j'ai obtenu un modèle avec une définition sûre des auteurs à partir de courts commentaires. D'autres améliorations seront associées au nettoyage et au transfert des résultats de la classification des données réelles dans l'ensemble de données de formation.
Tout le code avec des explications supplémentaires se trouve dans le
référentiel .
En post-scriptum: si vous avez besoin de classer de grandes quantités de texte, jetez un œil au
modèle VDCNN «Very Deep Convolutional Neural Network» (
implémentation sur keras), il s'agit d'un analogue de ResNet pour les textes.
Matériaux utilisés:
•
Aperçu des cours d'apprentissage automatique•
Analyse de convolution utilisant la convolution•
Réseaux convolutifs en PNL•
Mesures dans l'apprentissage automatiquehttps://ld86.imtqy.com/ml-slides/unbalanced.html•
Un regard à l'intérieur du modèle