
À ce jour, tout étudiant ayant suivi un cours sur les réseaux de neurones peut faire reconnaître des caractères coréens. Donnez-lui un échantillon et un ordinateur avec une carte vidéo, et après un certain temps, il vous apportera un réseau qui reconnaîtra les caractères coréens sans presque aucune erreur.
Mais une telle solution aura plusieurs inconvénients:
Tout d'abord , un grand nombre de calculs nécessaires, ce qui affecte le temps de fonctionnement ou l'énergie requise (ce qui est très important pour les appareils mobiles). En effet, si nous voulons reconnaître au moins 3000 caractères, ce sera la taille de la dernière couche du réseau. Et si l'entrée de cette couche est d'au moins 512, alors nous obtenons 512 * 3000 multiplications. Trop.
Deuxièmement , la taille. La même dernière couche de l'exemple précédent pèsera 512 * 3001 * 4 octets, soit environ 6 mégaoctets. Ce n'est qu'une couche, l'ensemble du réseau pèsera des dizaines de mégaoctets. Il est clair que ce n'est pas un gros problème pour un ordinateur de bureau, mais tout le monde ne sera pas prêt à stocker autant de données sur un smartphone pour reconnaître une langue.
Troisièmement , un tel réseau donnera des résultats imprévisibles sur des images qui ne sont pas des caractères coréens, mais qui sont néanmoins utilisées dans les textes coréens. Dans des conditions de laboratoire, ce n'est pas difficile, mais pour l'application pratique de la technologie, ce problème devra être en quelque sorte résolu.
Et quatrièmement , le problème est le nombre de caractères: 3000 est très probablement suffisant pour, par exemple, distinguer un steak d'un concombre de mer frit dans le menu du restaurant, mais parfois il y a des textes plus complexes. Il sera difficile de former le réseau pour un plus grand nombre de caractères: ce sera non seulement plus lent, mais il y aura également un problème avec la collecte de l'échantillon d'apprentissage, car la fréquence des caractères diminue de façon approximativement exponentielle. Bien sûr, vous pouvez obtenir des images à partir de polices et les augmenter, mais cela ne suffit pas pour former un bon réseau.
Et aujourd'hui, je vais vous dire comment nous avons réussi à résoudre ces problèmes.
Comment fonctionne l'écriture coréenne?
L'écriture coréenne, Hangul, est un croisement entre l'écriture chinoise et européenne. Extérieurement, ce sont des caractères carrés ressemblant à des hiéroglyphes, et sur une page du texte, vous pouvez compter plus d'une centaine de caractères uniques. Par contre, c'est l'écriture phonétique, c'est-à-dire basée sur l'enregistrement des sons. Il existe un alphabet contenant 24 lettres (en plus, vous pouvez également compter les diffraphes et les diphtongues). Mais, contrairement à l'alphabet latin ou cyrillique, les sons ne sont pas écrits en ligne, mais combinés en blocs. Par exemple, si nous écrivions de la même manière, la phrase «Bonjour, Habr» pourrait être écrite en trois blocs comme ceci:

Chaque bloc peut être composé de deux, trois ou quatre lettres. Dans ce cas, la consonne vient toujours en premier, puis une ou deux voyelles, et à la fin il peut y avoir une autre consonne. Il existe plusieurs façons de combiner des lettres en blocs, c'est-à-dire que, dans différents blocs, la deuxième lettre, par exemple, se trouvera à différents endroits.
L'image ci-dessous montre deux blocs qui forment ensemble le mot "Hangul". La première lettre de chaque bloc est indiquée en rouge, les voyelles sont surlignées en bleu et la consonne finale est surlignée en vert.
Source de l'image: Wikipedia.Modifier le bloc Hangul
Autrement dit, il s'avère qu'un bloc Hangul peut être décrit par la formule: Ci V [V] [Cf], où Ci est la consonne initiale (éventuellement double), V est la voyelle et Cf est la consonne finale (peut également être double). Une telle représentation ne convient pas à la reconnaissance, nous la modifions donc.
Tout d'abord, combinez les deux voyelles. On obtient la formule Ci V '[Cf], où V' - toutes les options possibles pour combiner des lettres, compte tenu de l'absence de la deuxième lettre. Puisqu'il y a 10 voyelles dans la langue, on pourrait s'attendre à ce que nous obtenions 10 * (10 + 1) options, mais en pratique toutes ne sont pas possibles, seulement 21 sont obtenues.
De plus, la dernière lettre ne l'est peut-être pas. Ajoutez aux nombreuses lettres attendues à la fin une lettre vide. On obtient alors la formule Ci V 'Cf *. Ainsi, il s'avère que maintenant le symbole coréen se compose toujours de trois «lettres». Vous pouvez apprendre la grille.
Nous construisons un réseau
L'idée est qu'au lieu de reconnaître le caractère entier, nous allons reconnaître les lettres individuelles en eux. Ainsi, au lieu d'un énorme softmax à la fin, nous obtenons trois petits, chacun d'environ quelques dizaines de taille. Ils correspondent aux première, deuxième et troisième «lettres» de la syllabe. En conséquence, nous avons obtenu l'architecture suivante:
image cliquable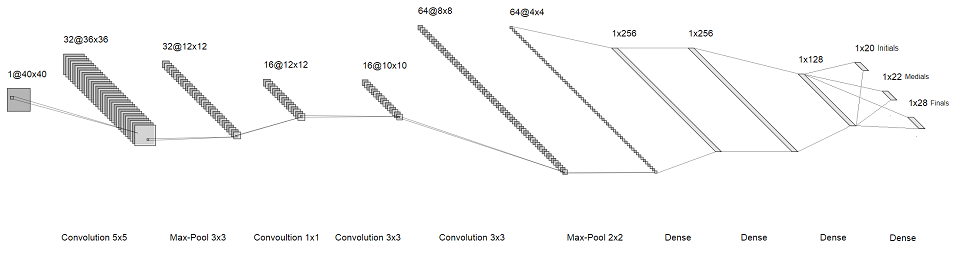
Nous nous entraînons sur un échantillon séparé. La qualité est bonne, la grille est rapide et elle pèse peu. Essayons de le sortir du laboratoire dans le monde réel.
Nous résolvons des problèmes
Nous aurons tout de suite le premier problème: parfois des images qui ne sont pas du tout des caractères coréens entrent dans l’entrée, et le réseau sur celles-ci se comporte de façon extrêmement imprévisible. Vous pouvez bien sûr former un autre réseau qui distinguera les blocs coréens de tout le reste, mais nous vous faciliterons la tâche.
Faisons la même chose que nous avons fait avec le troisième groupe de lettres: ajoutez une sortie pour l'absence de lettre. Ensuite, la formule du symbole ressemblera à ceci: Ci * V '* Cf *. Et dans l'ensemble de formation, nous ajouterons toutes sortes de déchets - caractères chinois, caractères mal coupés, lettres européennes, et nous apprendrons au réseau à y marquer trois lettres vides.
Nous nous entraînons, testons. Cela fonctionne, mais les problèmes persistent. Il s'avère que très souvent, par exemple, de telles images tombent dans la grille:
Il s'agit du bloc coréen correct auquel une seule citation est collée. Et il est évident que sur eux le réseau trouve parfaitement les trois lettres dont se compose le bloc. C'est juste que l'image n'est pas correcte, et nous devons signaler à ce sujet. Il est faux de renvoyer des lettres vides ici, car elles sont dans l'image. Essayons d'appliquer ce qui a déjà fait ses preuves: ajoutez deux sorties supplémentaires pour reconnaître ces ponctuateurs collants. Dans chacun d'eux, il y aura une sortie supplémentaire pour une situation où il n'y a rien de superflu dans l'image, mais en plus il faut ajouter une sortie supplémentaire pour la situation "il y a un ponctuateur, mais il n'est pas reconnu, probablement des ordures".
Formé Il est mauvais sur une telle grille de reconnaître des ponctuateurs: cela distingue une virgule d'une parenthèse, mais c'est déjà difficile d'un point. Vous pouvez augmenter la complexité de la grille, mais vous ne le souhaitez pas. Nous traiterons de la reconnaissance des ponctuateurs plus tard, mais pour l'instant, nous indiquerons simplement s'il y a quelque chose ou non. Cette grille a bien appris.
Nous avons compris les ponctuateurs collés, mais que se passe-t-il si, au contraire, une partie de la clé manque dans l'image? Il y avait un tel mot à deux caractères, mais nous l'avons coupé de manière incorrecte:
Le réseau ici sans aucun problème détermine la lettre centrale. Ce serait une qualité très utile si notre tâche consistait à reconnaître uniquement une sélection de caractères, mais dans le monde réel, cela serait nocif: lorsque nous coupons incorrectement la chaîne en caractères, nous devons transmettre ces informations ci-dessus, car sinon la pièce restante est alors reconnue comme une sorte de ponctuation, et dans le texte résultant il y aura un caractère supplémentaire.
Pour résoudre ce problème, nous utiliserons ce qui reste de certaines anciennes expériences d'il y a de nombreuses années. L'idée de reconnaître les caractères coréens par des lettres est apparue il y a très longtemps, et les premières tentatives ont été faites avant même l'ère des réseaux de neurones, mais elles n'ont pas trouvé d'application pratique. Mais depuis lors, des choses intéressantes sont restées:
- Marquer où chaque bloc a une lettre.
- De haute qualité, quoique rapide, découpant ces lettres des symboles.
Après avoir balayé la poussière, à l'aide de ce truc, nous générerons un nombre suffisant d'images problématiques sans l'une des lettres et nous apprendrons spécialement au réseau à répondre qu'il s'agit d'une lettre vide.
C'est tout, il n'y a plus de problème avec la reconnaissance des caractères coréens, mais la vie remet les bâtons dans les roues.
Le fait est qu'en plus des caractères Hangeul, les textes coréens se composent également d'un grand nombre d'autres caractères: ponctuateurs, caractères européens (au moins des nombres) et caractères chinois. Mais ils se produisent naturellement beaucoup moins fréquemment. Nous les diviserons en deux groupes: les hiéroglyphes et tout le reste, et nous formerons notre grille pour chacun d'eux. Et nous ferons un classificateur simple qui, selon les résultats du réseau de reconnaissance des caractères coréens et de certains autres signes (géométriques, en premier lieu) répondra si au moins l'un d'entre eux doit être lancé, et si oui, lequel. Vous devez reconnaître un peu de caractères européens, donc la grille sera petite, mais pour les hiéroglyphes ... Cela évite qu'ils soient rarement trouvés dans les textes, alors tournons notre classificateur pour qu'il suggère très rarement de les reconnaître.
En général, avec ces deux grilles, le problème d'une réponse adéquate se pose dans des images qui ne sont pas des symboles sur lesquels elle a été formée, mais nous parlerons de la façon de résoudre ce problème une autre fois.
Mener des expériences
Le premier . Il existe deux bases d'images, appelons-les réelles et synthétiques. Réel consiste en images réelles obtenues à partir de documents numérisés et en images synthétiques obtenues à partir de polices. Dans la première base, il y a des images pour 2374 blocs (les autres sont très rares), et des polices nous avons obtenu tous les 11172 caractères possibles. Essayons de former le réseau sur les blocs qui sont en réel (nous prendrons les images des deux bases), et testons sur ceux qui ne sont qu'en synthétique. Résultats:

Autrement dit, dans environ 60% des cas, le réseau est capable de reconnaître ces blocs, dont il n'a pas vu d'exemples du tout pendant la formation. La qualité aurait pu être meilleure sans un seul problème: parmi les dernières lettres, il y en a de très rares et pendant la formation, le réseau a vu très peu d'images de blocs. Cela explique la faible qualité de la dernière colonne. S'il était possible de choisir les 2374 blocs sur lesquels nous étudions, d'une manière différente, alors la qualité serait probablement beaucoup plus élevée.
Deuxième . Comparez notre réseau avec un réseau «normal», qui a softmax à la fin. Je voudrais le faire en taille 11172, mais nous ne pouvons pas trouver un nombre suffisant d'images réelles pour des blocs rares, nous nous limitons donc à 2374. La qualité et la vitesse de ce réseau dépendent de la taille des couches cachées. Nous n'enseignerons que sur Real, testerons dessus (d'autre part, bien sûr).

Autrement dit, même si nous nous limitons à ne reconnaître que 2374 blocs, notre réseau est plus rapide et au même niveau de qualité.
Troisièmement . Supposons que nous ayons pu obtenir quelque part une énorme base de tous les 11172 blocs coréens. Si nous formons un réseau avec softmax dessus, combien de temps cela fonctionnera-t-il à temps? La réalisation de toutes les expériences coûte cher, nous ne considérerons donc qu'un réseau avec 256 tailles de couches masquées:

Nous obtenons les résultats
Sans eux, rien ne serait arrivé
J'exprime ma gratitude à mon collègue Jura Chulinin, l'auteur original de l'idée. Il est
breveté en Russie et, en outre, une demande similaire a été
déposée auprès de l'Office américain des brevets (USPTO). Un grand merci au développeur Misha Zatsepin, qui a mis en œuvre tout cela et mené toutes les expériences.
Yuri Vatlin,
Responsable du groupe Scripts complexes