Bonjour à tous! Le printemps est arrivé, ce qui signifie qu'il reste moins d'un mois avant le début du
cours Python Developer . C'est à ce cours que sera consacrée notre publication d'aujourd'hui.

 Tâches:
Tâches:- En savoir plus sur la structure interne de Python;
- Comprendre les principes de construction d'un arbre de syntaxe abstraite (AST);
- Écrivez du code plus efficace en temps et en mémoire.
Recommandations préliminaires:- Connaissance de base de l'interprète (AST, jetons, etc.).
- Connaissance de Python.
- Connaissance de base de C.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
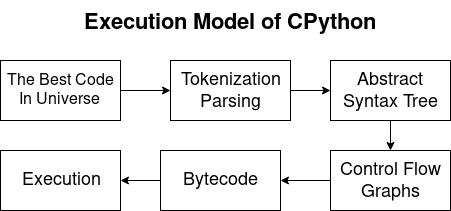
Modèle d'exécution CPythonPython est un langage compilé et interprété. Ainsi, le compilateur Python génère des bytecodes et l'interpréteur les exécute. Au cours de l'article, nous examinerons les problèmes suivants:
- Analyse et tokenisation:
- Transformation en AST;
- Graphique de flux de contrôle (CFG);
- Bytecode
- Exécution sur une machine virtuelle CPython.
Analyse et tokenisation.
Grammaire.La grammaire définit la sémantique du langage Python. Il est également utile pour indiquer la façon dont l'analyseur doit interpréter la langue. La grammaire Python utilise une syntaxe similaire à la forme étendue Backus-Naur. Il a sa propre grammaire pour un traducteur de la langue source. Vous pouvez trouver le fichier de grammaire dans le répertoire "cpython / Grammar / Grammar".
Ce qui suit est un exemple de grammaire,
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
Les expressions simples contiennent de petites expressions et crochets, et la commande se termine par une nouvelle ligne. Les petites expressions ressemblent à une liste d'expressions qui importent ...
Quelques autres expressions :)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
Tokenisation (Lexing)La tokenisation est le processus d'obtention d'un flux de données de texte et de division en jetons de mots significatifs (pour l'interprète) avec des métadonnées supplémentaires (par exemple, où le jeton commence et se termine, et quelle est la valeur de chaîne de ce jeton).
JetonsUn jeton est un fichier d'en-tête contenant les définitions de tous les jetons. Il existe 59 types de jetons en Python (Include / token.h).
Voici un exemple de certains d'entre eux,
Vous les voyez si vous cassez du code Python en jetons.
Tokenisation avec CLIVoici le fichier tests.py
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
Ensuite, nous le jetons en jetons à l'aide de la commande python -m tokenize et le résultat suivant est généré:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
Ici, les chiffres (par exemple, 1.4-1.13) montrent où le jeton a commencé et où il s'est terminé. Un jeton de codage est toujours le tout premier jeton que nous recevons. Il donne des informations sur l'encodage du fichier source et, en cas de problème, l'interpréteur lève une exception.
Tokenisation avec tokenize.tokenizeSi vous devez tokenize le fichier à partir de votre code, vous pouvez utiliser le module
tokenize de
stdlib .
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
Le type de jeton est son identifiant dans le fichier d'en-tête
token.h. La chaîne est la valeur du jeton. Début et fin indiquent respectivement le début et la fin du jeton.
Dans d'autres langages, les blocs sont indiqués par des crochets ou des instructions begin / end, mais Python utilise des retraits et des niveaux différents. Jetons INDENT et DEDENT et indiquent l'indentation. Ces jetons sont nécessaires pour créer des arbres d'analyse relationnelle et / ou des arbres de syntaxe abstraite.
Génération de l'analyseurGénération de l'analyseur - un processus qui génère un analyseur selon une grammaire donnée. Les générateurs d'analyseurs sont appelés PGen. Cpython possède deux générateurs d'analyseurs. L'un est l'original (
Parser/pgen ) et l'autre est réécrit en python (
/Lib/lib2to3/pgen2 ).
"Le générateur d'origine était le premier code que j'ai écrit pour Python"
-GuidoDe la citation ci-dessus, il devient clair que
pgen est la chose la plus importante dans un langage de programmation. Lorsque vous appelez pgen (dans
Parser / pgen ), il génère un fichier d'en-tête et un fichier C (l'analyseur lui-même). Si vous regardez le code C généré, il peut sembler inutile, car son apparence significative est facultative. Il contient de nombreuses données et structures statiques. Ensuite, nous allons essayer d'expliquer ses principaux composants.
DFA (Machine à états définis)L'analyseur définit un DFA pour chaque terminal non. Chaque DFA est défini comme un tableau d'états.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
Pour chaque DFA, il existe un kit de démarrage qui montre avec quels jetons un non-terminal spécial peut commencer.
ConditionChaque état est défini par un tableau de transitions / arêtes (arcs).
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
Transitions (arcs)Chaque tableau de transition a deux nombres. Le premier nombre est le nom de la transition (étiquette d'arc), il fait référence au numéro de symbole. Le deuxième numéro est la destination.
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
Noms (étiquettes)Il s'agit d'un tableau spécial qui mappe l'ID du caractère au nom de la transition.
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
Le chiffre 1 correspond à tous les identifiants. Ainsi, chacun d'eux obtient des noms de transition différents, même s'ils ont tous le même identifiant de caractère.
Un exemple simple:Supposons que nous ayons un code qui renvoie «Hi» si 1 - vrai:
if 1: print('Hi')
L'analyseur considère ce code comme single_input.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
Ensuite, notre arbre d'analyse commence au nœud racine d'une entrée unique.

Et la valeur de notre DFA (single_input) est 0.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
Cela ressemblera à ceci:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2},
};
Ici
arc_0_0 compose de trois éléments. Le premier est
NEWLINE , le second est
simple_stmt et le dernier est
compound_stmt .
Étant donné l'ensemble initial de
simple_stmt nous pouvons conclure que
simple_stmt ne peut pas commencer par
if . Cependant, même si
if n'est pas une nouvelle ligne,
compound_stmt peut toujours commencer par
if . Ainsi, nous allons du dernier
arc ({4;2}) et ajoutons le nœud
compound_stmt à l'arbre d'analyse et avant de passer au numéro 2, nous passons au nouveau DFA. Nous obtenons un arbre d'analyse mis à jour:

Le nouveau DFA analyse les instructions composées.
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
Et nous obtenons ce qui suit:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
Seul le premier saut peut commencer par
if . Nous obtenons un arbre d'analyse mis à jour.
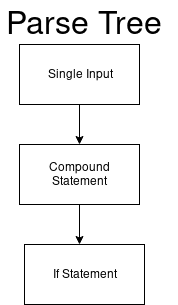
Ensuite, nous modifions à nouveau le DFA et les ifs DFA suivants.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
En conséquence, nous obtenons la seule transition avec la désignation 97. Elle coïncide avec le jeton
if .
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
Lorsque nous passons à l'état suivant, en restant dans le même DFA, le prochain arcs_41_1 n'a également qu'une seule transition. Cela est vrai pour le terminal de test. Il doit commencer par un nombre (par exemple, 1).
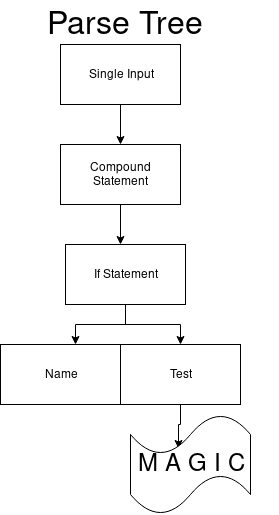
Il n'y a qu'une seule transition dans arc_41_2 qui obtient le jeton deux-points (:).

Nous obtenons donc un ensemble qui peut commencer par une valeur d'impression. Enfin, passez à arcs_41_4. La première transition dans l'ensemble est une expression elif, la seconde est un autre et la troisième est pour le dernier état. Et nous obtenons la vue finale de l'arbre d'analyse.
 Interface Python pour l'analyseur.
Interface Python pour l'analyseur.
Python vous permet de modifier l'arborescence d'analyse des expressions à l'aide d'un module appelé analyseur.
>>> import parser >>> code = "if 1: print('Hi')"
Vous pouvez générer un arbre de syntaxe spécifique (Concrete Syntax Tree, CST) à l'aide de parser.suite.
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
La valeur de sortie sera une liste imbriquée. Chaque liste de la structure comporte 2 éléments. Le premier est l'id du caractère (0-256 - terminaux, 256+ - non-terminaux) et le second est la chaîne de jetons pour le terminal.
Arbre de syntaxe abstraiteEn fait, un arbre de syntaxe abstraite (AST) est une représentation structurelle du code source sous la forme d'un arbre, où chaque sommet dénote différents types de constructions de langage (expression, variable, opérateur, etc.)
Qu'est-ce qu'un arbre?Un arbre est une structure de données qui a un sommet racine comme point de départ. Le sommet racine est abaissé de branches (transitions) vers d'autres sommets. Chaque sommet, à l'exception de la racine, a un sommet parent unique.
Il existe une certaine différence entre l'arbre de syntaxe abstraite et l'arbre d'analyse.
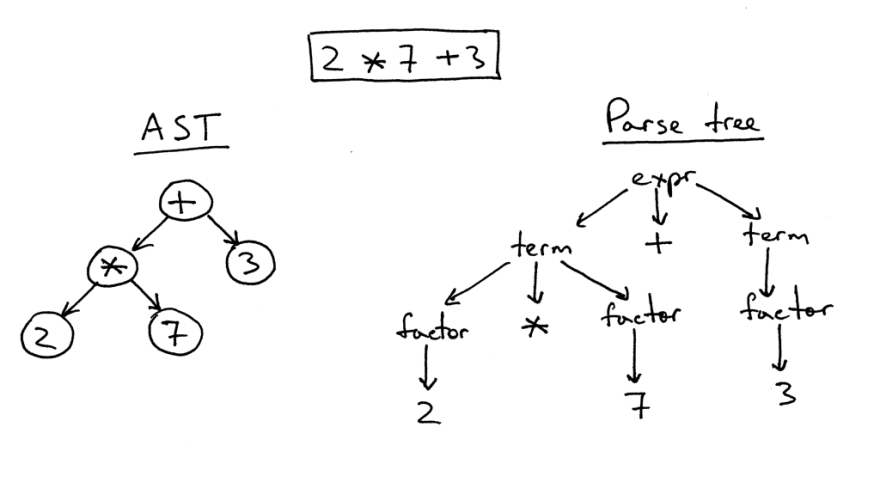
À droite, un arbre d'analyse de l'expression 2 * 7 + 3. Il s'agit littéralement d'une image source biunivoque sous la forme d'un arbre. Toutes les expressions, termes et valeurs y sont visibles. Cependant, une telle image est trop compliquée pour un simple morceau de code, nous pouvons donc simplement supprimer toutes les expressions syntaxiques que nous devions définir dans le code pour les calculs.
Un tel arbre simplifié est appelé arbre de syntaxe abstraite (AST). Sur la gauche de la figure, il est affiché exactement pour le même code. Toutes les expressions de syntaxe ont été supprimées pour une meilleure compréhension, mais n'oubliez pas que certaines informations ont été perdues.
Exemple
Python propose un module AST intégré pour travailler avec AST. Pour générer du code à partir d'arbres AST, vous pouvez utiliser des modules tiers, par exemple
Astor .
Par exemple, considérez le même code que précédemment.
>>> import ast >>> code = "if 1: print('Hi')"
Pour obtenir AST, nous utilisons la méthode ast.parse.
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
Essayez d'utiliser la méthode
ast.dump pour obtenir une arborescence de syntaxe abstraite plus lisible.
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
AST est généralement considéré comme plus visuel et plus facile à comprendre que l'arbre d'analyse.
Contrôle de flux Graf (CFG)Les graphiques de flux de contrôle sont des graphiques directionnels qui modélisent le flux d'un programme à l'aide de blocs de base qui contiennent une représentation intermédiaire.
En règle générale, CFG est l'étape précédente avant d'obtenir les valeurs de code de sortie. Le code est généré directement à partir des blocs de base à l'aide d'une recherche de profondeur en arrière dans CFG, en commençant par les sommets.
BytecodeLe bytecode Python est un ensemble intermédiaire d'instructions qui fonctionnent dans une machine virtuelle Python. Lorsque vous exécutez le code source, Python crée un répertoire appelé __pycache__. Il stocke le code compilé afin de gagner du temps en cas de redémarrage de la compilation.
Considérons une simple fonction Python dans func.py.
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
Le
say_hello objet
say_hello est une fonction.
>>> type(say_hello) <class 'function'>
Il a l'attribut
__code__ .
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
Objets de codeLes objets de code sont des structures de données immuables qui contiennent les instructions ou les métadonnées nécessaires pour exécuter le code. Autrement dit, ce sont des représentations de code Python. Vous pouvez également obtenir des objets de code en compilant des arbres de syntaxe abstraite à l'aide de la méthode de
compilation .
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
Chaque objet de code possède des attributs qui contiennent certaines informations (préfixées par co_). Nous n'en mentionnons ici que quelques-uns.
co_namePour commencer - un nom. Si une fonction existe, elle doit avoir un nom, respectivement, ce nom sera le nom de la fonction, une situation similaire avec la classe. Dans l'exemple AST, nous utilisons des modules et nous pouvons dire au compilateur exactement comment nous voulons les nommer. Qu'ils ne soient qu'un
module .
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnamesIl s'agit d'un tuple contenant toutes les variables locales, y compris les arguments.
>>> say_hello.__code__.co_varnames ('name',)
co_contsUn tuple contenant tous les littéraux et les valeurs constantes auxquels nous avons accédé dans le corps de la fonction. Il convient de noter la valeur Aucune. Nous n'avons pas inclus None dans le corps de la fonction, cependant, Python l'a indiqué, car si la fonction commence à s'exécuter puis se termine sans recevoir de valeurs de retour, elle renverra None.
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
Bytecode (co_code)Ce qui suit est le bytecode de notre fonction.
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
Ce n'est pas une chaîne, c'est un objet d'octets, c'est-à-dire une séquence d'octets.
>>> type(bytecode) <class 'bytes'>
Le premier caractère imprimé est «t». Si nous demandons sa valeur numérique, nous obtenons ce qui suit.
>>> ord('t') 116
116 est identique au bytecode [0].
>>> assert bytecode[0] == ord('t')
Pour nous, une valeur de 116 ne veut rien dire. Heureusement, Python fournit une bibliothèque standard appelée dis (from disassembly). Il est utile lorsque vous travaillez avec la liste des noms d'opérations. Il s'agit d'une liste de toutes les instructions de bytecode, où chaque index est le nom de l'instruction.
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
Créons une autre fonction plus complexe.
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
Et nous découvrons la première instruction en bytecode.
>>> dis.opname[bytecode[0]] 'LOAD_FAST
L'instruction LOAD_FAST se compose de deux éléments.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
L'instruction Loadfast 0 arrive à rechercher des noms de variables dans un tuple et à pousser un élément avec un index zéro dans le tuple de la pile d'exécution.
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
Notre code peut être démonté en utilisant dis.dis et convertir le bytecode en une vue familière. Ici, les nombres (2,3,4) sont les numéros de ligne. Chaque ligne de code en Python est développée comme un ensemble d'instructions.
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
Délai de livraisonCPython est une machine virtuelle orientée pile, pas une collection de registres. Cela signifie que le code Python est compilé pour une machine virtuelle avec une architecture de pile.
Lors de l'appel d'une fonction, Python utilise deux piles ensemble. Le premier est la pile d'exécution et le second est la pile de blocs. La plupart des appels se produisent sur la pile d'exécution; la pile de blocs conserve une trace du nombre de blocs actuellement actifs, ainsi que d'autres paramètres liés aux blocs et aux étendues.
Nous attendons avec impatience vos commentaires sur le matériel et vous invitons à
un webinaire ouvert sur le sujet: «Libérez-le: aspects pratiques de la publication d'un logiciel fiable», qui sera dirigé par notre enseignant, le programmeur du système publicitaire de Mail.Ru,
Stanislav Stupnikov .