Le fait de ne connaître qu'une seule approche du grattage Web résout le problème à court terme, mais toutes les méthodes ont leurs forces et leurs faiblesses. La prise de conscience de cela fait gagner du temps et aide à résoudre le problème plus efficacement.

De nombreuses ressources parlent de la seule véritable méthode de récupération des données d'une page Web. Mais la réalité est que pour cela, vous pouvez utiliser plusieurs solutions et outils.
- Quelles sont les options de récupération par programme des données d'une page Web?
- Avantages et inconvénients de chaque approche?
- Comment utiliser les ressources cloud pour augmenter le degré d'automatisation?
L'article aidera à obtenir des réponses à ces questions.
Je suppose que vous savez déjà ce que sont
les requêtes
HTTP ,
DOM (Document Object Model),
HTML , les
sélecteurs CSS et
Async JavaScript .
Sinon, je vous conseille de vous plonger dans la théorie, puis de revenir à l'article.
Contenu statique
Sources HTMLCommençons par l'approche la plus simple.
Si vous envisagez de supprimer des pages Web, c'est la première chose à commencer. Il nécessitera peu de puissance informatique et un minimum de temps.
Cependant, cela ne fonctionne que si le code source HTML contient les données que vous ciblez. Pour tester cela dans Chrome, cliquez avec le bouton droit sur la page et sélectionnez Afficher le code de page. Vous devriez maintenant voir le code source HTML.
Une fois que vous avez trouvé les données, écrivez un
sélecteur CSS qui appartient à l'élément d'habillage afin d'avoir un lien plus tard.
Pour l'implémentation, vous pouvez envoyer une requête HTTP GET à l'URL de la page et récupérer le code source HTML.
Dans
Node, vous pouvez utiliser l'outil
CheerioJS pour
analyser du code HTML brut et récupérer des données à l'aide d'un sélecteur. Le code ressemblera à ceci:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
Contenu dynamique
Dans de nombreux cas, vous ne pouvez pas accéder aux informations à partir du code HTML brut car le DOM était contrôlé par JavaScript exécuté en arrière-plan. Un exemple typique de ceci est un SPA (application d'une seule page), où un document HTML contient un minimum d'informations et JavaScript le remplit au moment de l'exécution.
Dans cette situation, la solution consiste à créer le DOM et à exécuter les scripts situés dans le code source HTML, comme le fait le navigateur. Après cela, les données peuvent être extraites de cet objet à l'aide de sélecteurs.
Navigateurs sans têteLe navigateur sans tête est le même qu'un navigateur normal, mais sans interface utilisateur. Il s'exécute en arrière-plan et vous pouvez le contrôler par programme au lieu de cliquer et de taper à partir du clavier.
Puppeteer est l' un des navigateurs sans tête les plus populaires. Il s'agit d'une bibliothèque de nœuds facile à utiliser qui fournit une API de haut niveau pour gérer Chrome hors connexion. Il peut être configuré pour fonctionner sans en-tête, ce qui est très pratique lors du développement. Le code suivant fait la même chose qu'auparavant, mais il fonctionnera avec les pages dynamiques:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
Bien sûr, vous pouvez faire des choses plus intéressantes avec Puppeteer, alors consultez la
documentation . Voici un extrait de code qui navigue dans l'URL, prend une capture d'écran et l'enregistre:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
Le navigateur nécessite beaucoup plus de puissance de calcul que d'envoyer une simple demande GET et d'analyser la réponse. Par conséquent, l'exécution est relativement lente. Non seulement cela, mais l'ajout d'un navigateur en tant que dépendance rend le package massif.
En revanche, cette méthode est très flexible. Vous pouvez l'utiliser pour parcourir les pages, simuler les clics, les mouvements de la souris et utiliser le clavier, remplir des formulaires, créer des captures d'écran ou créer des pages PDF, exécuter des commandes dans la console, sélectionner des éléments pour extraire du contenu texte. Fondamentalement, tout ce qui peut être fait manuellement dans un navigateur.
Construire un DOMVous penserez qu'il n'est pas nécessaire de simuler un navigateur entier juste pour créer un DOM. En fait, c'est vrai, du moins dans certaines circonstances.
Jsdom est une bibliothèque de nœuds qui analyse le HTML en cours de transmission, tout comme le fait un navigateur. Cependant, ce n'est pas un navigateur, mais un
outil pour construire le DOM à partir d'un code source HTML donné , ainsi que pour exécuter du code JavaScript dans ce HTML.
Grâce à cette abstraction, Jsdom peut fonctionner plus rapidement qu'un navigateur sans tête. Si c'est plus rapide, pourquoi ne pas l'utiliser tout le temps à la place des navigateurs sans tête?
Citation de la documentation :
Les gens ont souvent des problèmes avec le chargement asynchrone des scripts lors de l'utilisation de jsdom. De nombreuses pages chargent les scripts de manière asynchrone, mais il est impossible de déterminer quand cela s'est produit, et donc quand exécuter le code et vérifier la structure DOM résultante. Il s'agit d'une limitation fondamentale.
Cette solution est illustrée dans l'exemple. Toutes les 100 ms, il est vérifié si un élément est apparu ou un timeout s'est produit (après 2 secondes).
Il donne également souvent des messages d'erreur lorsque Jsdom n'implémente pas certaines fonctionnalités du navigateur sur la page, telles que: "
Erreur: Non implémenté: window.alert ..." ou "Erreur: Non implémenté: window.scrollTo ... ". Ce problème peut également être résolu avec certaines solutions de contournement (
consoles virtuelles ).
Il s'agit généralement d'une API de niveau inférieur à Puppeteer, vous devez donc implémenter certaines choses vous-même.
Cela complique un peu l'utilisation, comme le montre l'exemple.
Jsdom propose une solution rapide pour le même travail.
Regardons le même exemple, mais en utilisant
Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
Rétro-ingénierieJsdom est une solution rapide et facile, mais vous pouvez la rendre encore plus simple.
Faut-il modéliser le DOM?
La page Web que vous souhaitez supprimer est constituée des mêmes HTML et JavaScript, les mêmes technologies que vous connaissez déjà. Ainsi,
si vous trouvez un morceau de code à partir duquel les données cibles ont été obtenues, vous pouvez répéter la même opération pour obtenir le même résultat .
Pour simplifier les choses, les données que vous recherchez pourraient être:
- une partie du code source HTML (comme on peut le voir dans la première partie de l'article),
- partie d'un fichier statique référencé dans un document HTML (par exemple, une ligne dans un fichier javascript),
- réponse à une requête réseau (par exemple, du code JavaScript a envoyé une requête AJAX à un serveur qui a répondu avec une chaîne JSON).
Ces sources de données sont accessibles à l'aide de requêtes réseau . Peu importe si la page Web utilise HTTP, WebSockets ou tout autre protocole de communication, car ils sont tous reproductibles en théorie.
Une fois que vous avez trouvé une ressource contenant des données, vous pouvez envoyer une demande réseau similaire au même serveur que la page d'origine. En conséquence, vous obtiendrez une réponse contenant les données cibles, qui peuvent être facilement extraites en utilisant des expressions régulières, des méthodes de chaîne, JSON.parse, etc.
En termes simples, vous pouvez utiliser la ressource sur laquelle se trouvent les données, au lieu de traiter et de charger tout le matériel. Ainsi, le problème montré dans les exemples précédents peut être résolu avec une seule requête HTTP au lieu de contrôler un navigateur ou un objet JavaScript complexe.
Cette solution semble simple en théorie, mais dans la plupart des cas, elle peut prendre du temps et nécessite une expérience avec les pages Web et les serveurs.
Commencez par surveiller le trafic réseau. Un excellent outil pour cela est l'onglet
Réseau dans Chrome DevTools . Vous verrez toutes les demandes sortantes avec des réponses (y compris les fichiers statiques, les demandes AJAX, etc.) pour les parcourir et rechercher des données.
Si la réponse est modifiée par un code quelconque avant d'être affichée à l'écran, le processus sera plus lent. Dans ce cas, vous devez trouver cette partie du code et comprendre ce qui se passe.
Comme vous pouvez le voir, une telle méthode peut nécessiter beaucoup plus de travail que les méthodes décrites ci-dessus. En revanche, il offre les meilleures performances.
Le diagramme montre la durée d'exécution et la taille de paquet requises par rapport à Jsdom et Puppeteer:
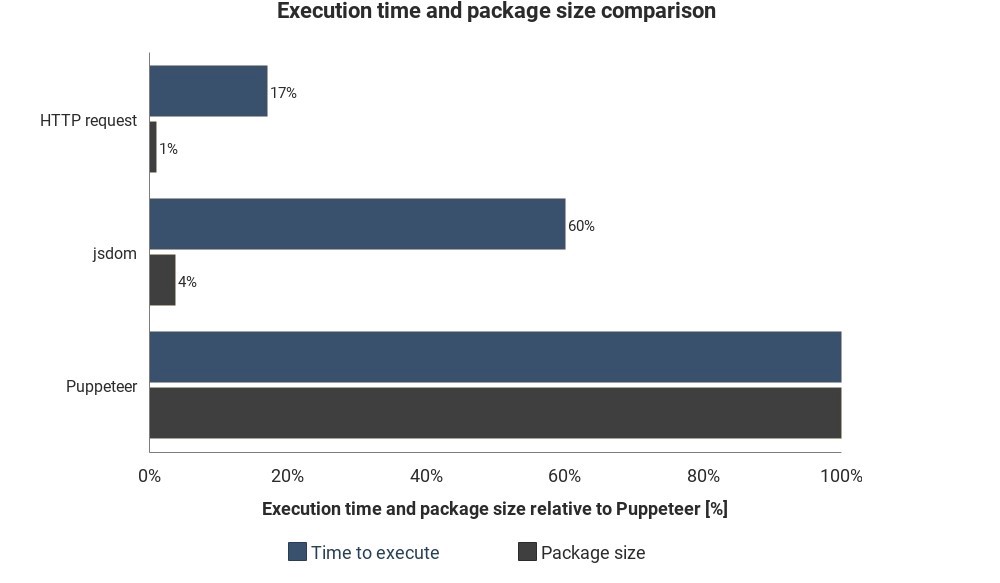
Les résultats ne sont pas basés sur des mesures précises et peuvent varier, mais montrent de bonnes différences approximatives entre ces méthodes.
Intégration de services cloud
Supposons que vous ayez implémenté l'une de ces solutions. Une façon d'exécuter le script consiste à allumer l'ordinateur, à ouvrir le terminal et à le démarrer manuellement.
Mais cela deviendra ennuyeux et inefficace, il serait donc préférable de simplement télécharger le script sur le serveur et d'exécuter le code régulièrement en fonction des paramètres.
Pour ce faire, démarrez le serveur réel et définissez les règles d'exécution du script. Dans d'autres cas, la fonction cloud est un moyen plus simple.
Les fonctions cloud sont des stockages conçus pour exécuter du code téléchargé lorsqu'un événement se produit. Cela signifie que vous n'avez pas besoin de gérer les serveurs, cela se fait automatiquement par votre fournisseur de cloud.
Un déclencheur peut être une planification, une demande réseau et de nombreux autres événements. Vous pouvez enregistrer les données collectées dans une base de données, les écrire sur une
feuille Google ou les envoyer par
e-mail . Tout dépend de votre imagination.
Fournisseurs de cloud populaires -
Amazon Web Services (AWS),
Google Cloud Platform (GCP) et
Microsoft Azure :
Vous pouvez utiliser ces services gratuitement, mais pas pour longtemps.
Si vous utilisez Puppeteer,
les fonctionnalités de Google Cloud sont la solution la plus simple. La taille du package au format Headless Chrome (~ 130 Mo) dépasse la taille d'archive maximale autorisée dans AWS Lambda (50 Mo). Il existe plusieurs méthodes pour le faire fonctionner avec Lambda, mais les fonctions GCP
prennent en charge par défaut
Chrome sans en-tête , il vous suffit d'inclure Puppeteer comme dépendance dans
package.json .
Si vous souhaitez en savoir plus sur les fonctionnalités du cloud en général, consultez les informations sur l'architecture sans serveur. De nombreux bons didacticiels ont déjà été écrits sur ce sujet, et la plupart des fournisseurs ont une documentation facile à comprendre.