Sous la coupe se trouve l'histoire de la façon dont la zone d'apprentissage automatique est apparue dans le Dodo. Spoiler: je l'ai lancé. Les détails techniques ne seront pas là, assurez-vous de leur consacrer un article séparé. Aujourd'hui, c'est plus sur la motivation et le soutien des collègues.

La préparation
Je suis tombé trois fois sur le sujet de l'apprentissage automatique, jusqu'à ce que quelque chose de valable en sorte.
École russe
La première fois que j'ai rencontré le machine learning au HSE - j'ai obtenu une deuxième tour en direction de Big Data Systems lorsque j'ai obtenu un emploi chez Dodo. Après avoir traversé cet énorme sujet de battage médiatique sur une tangente, je ne comprenais pas pourquoi j'avais passé trois ans de ma vie. Et plus encore, je n'ai pas pensé à comment cela pourrait être utile dans l'entreprise. Je n'étais alors pas prêt pour ce défi du destin.
Voyage tchèque
La deuxième fois que je suis tombé sur ce sujet à Prague, lors du hackathon fermé d'apprentissage automatique de Microsoft. Avec des gars d'autres sociétés, nous avons travaillé sur la tâche de prévoir la demande à Dodo pendant les vacances et les jours de pointe. Je suis revenu avec un modèle prêt à l'emploi qui prédit la demande. C'est après ce hackathon que des pensées sont apparues pour que je puisse appliquer les connaissances acquises dans l'entreprise. Ça y était.
Eh bien, avez-vous un modèle dans Jupyter, alors quoi? Comment l'utiliser? Toutes les tentatives pour expliquer cela aux entreprises étaient confrontées à une dure réalité: il est donc clair qu'il y aura de nombreuses commandes les jours fériés et les jours de pointe. Les pizzerias pour adultes sont capables de prédire les ventes sur la base des données de l'année dernière, et les nouvelles ont eu des problèmes sans cela. Nous avons reporté les tentatives de développement du machine learning. Mais l'idée que nous pouvons faire plus avec les données est trop fermement ancrée dans ma tête et ne voulait pas sortir de là. Maintenant, j'étais prêt à relever le défi, mais pas l'entreprise.
Rêve américain
La troisième réunion est devenue fatidique. Notre équipe a eu une tâche difficile mais intéressante: développer un module de pizza personnalisé pour les USA. C'est à ce moment-là que vous pouvez commander une pizza avec n'importe quel ensemble d'ingrédients, créez votre propre recette. Tout devait être élaboré dans le projet: des changements dans l'architecture de la base de données au code client sur le site. Nous nous sommes attaqués à la tâche et avons développé un produit que je considère comme une véritable victoire. La principale évaluation s'est envolée d'Alena, notre PDG aux États-Unis.

Nous avons fait le module, mais j'ai vu un problème de mise à l'échelle. Que faire si la fonctionnalité n'apparaît pas dans une ou deux pizzerias dans les états, mais dans un grand réseau? Comment gérer un tel produit, planifier des stocks? J'ai décidé que ce cas pourrait prouver la nécessité du développement de l'apprentissage automatique dans Dodo. Je sentais que cette fois-ci, l'entreprise et moi étions prêts à lancer une nouvelle direction.
Un à un avec des voitures
En arrière-plan, j'ai commencé à analyser les ventes de pizzas américaines personnalisées. En utilisant des algorithmes de clustering, il a été possible de montrer que toutes les recettes créées par les utilisateurs sont basées sur six ensembles d'ingrédients de base plus quelques ingrédients aléatoires. Même un simple rapport basé sur cet algorithme permettrait des prévisions de ventes semi-manuelles et un inventaire planifié. En raison du manque de bureaucratie et de la capacité de reconstruire sur le pouce, nous avons reçu le feu vert pour commencer à nous engager dans cette direction.
Le directeur technique et moi avons compris et discuté plus d'une fois que je devais quitter l'équipe actuelle et commencer à développer une nouvelle direction, pour montrer que nous en avions besoin. Je devais plonger dans une nouvelle sphère à un rythme rapide. J'ai compris que si ça ne marche pas, il y a deux façons. La première consiste à reprendre le développement dans une autre équipe Dodo. La seconde consiste à mettre à jour votre CV sur HH et à chercher un nouvel emploi. Je ne voulais ni l'un ni l'autre. J'étais dans cet état pendant environ trois mois, jusqu'à ce que je devienne accro au module de vente supplémentaire.
Premier projet
Un autre spoiler: il s'est avéré que pour exécuter ML, vous n'avez pas besoin de rencontrer quelque chose de compliqué. Évidemment, n'est-ce pas? Mais c'est très difficile à comprendre au début du voyage.
Le module, qui suggère d'ajouter un produit supplémentaire à la commande, n'est directement contrôlé par personne. Cela signifie que je peux faire tout ce que je veux avec lui. Cerise sur le gâteau - une opportunité d'augmenter les ventes à l'aide d'offres plus personnalisées. Auparavant, le module fonctionnait simplement: si de la pizza était ajoutée à la commande, la catégorie de boissons était affichée dans les ventes supplémentaires, si pizza et boisson, puis desserts et ainsi de suite.
L'indifférence d'un grand nombre de personnes a une fois de plus montré que je travaille dans une entreprise où le soutien peut être apporté par absolument tout le monde. J'ai passé des heures à travailler sur des données et des offres supplémentaires avec un collègue marketing. Nous avons réussi à regrouper tous les utilisateurs en fonction de leurs préférences gustatives et de leur fidélité, pour que chaque groupe fasse des offres statiques basées sur les meilleurs produits du cluster.
Chiffres et preuves
J'ai foiré l'enregistrement de produits supplémentaires et lancé de nouvelles offres sur un échantillon de 2 millions d'utilisateurs.
Un échantillon d'utilisateurs ne représente qu'une petite partie des ventes. Il fallait s'orienter vers de nouveaux clients non autorisés. J'ai pelleté suffisamment d'articles et de documentation sur le filtrage collaboratif et divers algorithmes d'offre pour les utilisateurs. L'idée de recommandations basées sur les produits du panier a gagné. Les recommandations basées sur les éléments et une mesure du cosinus de convergence ont constitué la base d'un nouveau modèle, bien que simple, mais déjà fonctionnel.
En décembre, nous avons lancé le module Recommandations par article. Les statistiques ont montré que les acheteurs peuvent en effet être intéressés par des produits complètement différents, pas seulement par des boissons. C'est peut-être après cela que le Dodo a cru que les données et le développement du machine learning leur permettraient de rivaliser sur les futurs marchés surchargés.
Quelques statistiques.
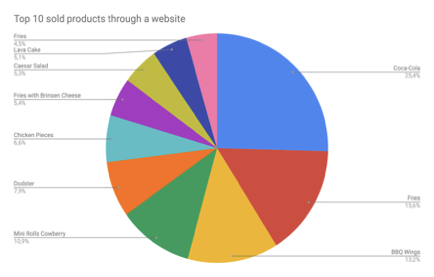
10 produits les plus vendus sur le site

10 produits d'applications mobiles les plus vendus

Croissance hebdomadaire des ventes
Remorque technique
Voici quelques détails techniques expliquant pourquoi le modèle est basé sur une mesure de similitude en cosinus. Il s'agit d'un aperçu de l'article, qui sera publié dans quelques mois. Si vous n'aimez pas les mathématiques, n'hésitez pas à passer à la dernière section.
Le tableau initial ci-dessous montre le nombre de commandes avec les marchandises achetées de chaque utilisateur. Nous pouvons déterminer la similitude des achats d'un utilisateur avec un autre - pour cela, nous devons calculer la distance entre les vecteurs utilisateur.
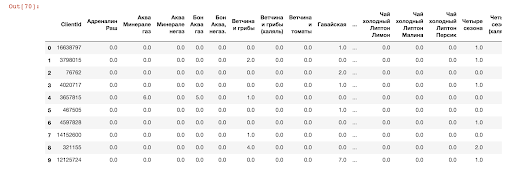
Tableau des ventes clients
La distance dépendra de la métrique sélectionnée. Le calcul de l'espace euclidien inclut le poids et la magnitude du vecteur:

où a et b sont deux vecteurs clients différents de la table. Voyons à quoi ressemblera cette distance sur un exemple abstrait.
Supposons que nous regardions l'histoire de trois clients - a, b et c. Construisons une matrice de leurs achats.

Après avoir calculé les distances euclidiennes entre les clients, nous obtenons les valeurs suivantes:
d (a, b) = 16,22;
d (b, c) = 13,38;
d (a, c) = 13,64.
Ces valeurs indiquent que les clients b et c sont les plus proches les uns des autres. Mais si vous regardez les données source, l'image est le contraire. Les clients a et b préfèrent commander plus de Pepperoni et parfois d'autres produits, tandis que le client c préfère la pizza suprême. Nous pouvons conclure que la magnitude du vecteur a un effet négatif pour le calcul des distances entre les clients. La mesure du cosinus de similitude ne prend en compte que l'angle entre les vecteurs, ignorant la signification de l'amplitude du vecteur:

En calculant la distance à l'aide de cette formule, nous obtenons:
d (a, b) = 0,9183;
d (b, c) = 0,5848;
d (a, c) = 0,7947;
Nous voyons que les clients a et b sont plus proches les uns des autres. Ils préfèrent un ensemble de marchandises sans tenir compte de la différence dans le nombre de commandes passées. Cette logique rejoint notre avis d'expert et suggère que les préférences des clients a et b sont les plus proches les unes des autres.
Ceci est une bande-annonce, détails dans deux mois.
Recherchez votre
Nous sommes maintenant au stade de former une équipe dans laquelle il y aura des spécialistes dans l'organisation du stockage de données, le développement de modèles d'apprentissage automatique et leur mise en production. Mais surtout, nous comprenons mieux maintenant pourquoi nous avons besoin de tout cela. Nous sommes libres de faire des choses vraiment cool, de l'organisation d'un système logistique intelligent et de la planification des stocks aux idées fantastiques pour automatiser les pizzerias à l'aide des technologies de vision par ordinateur.
Croyez en vous et en vos forces, même si le résultat n'est pas visible à l'horizon. Je voudrais terminer l'article par la pensée de quelqu'un d'autre - une citation de Max Weber de son rapport aux étudiants de l'Université de Munich: "Vous ne pouvez rien faire avec tristesse et attente, et vous devez agir différemment - vous devez vous tourner vers votre travail et répondre à la" demande du jour "- en tant qu'être humain, si professionnellement. Et cette exigence sera simple et claire si chacun trouve son propre démon et obéit à ce démon, tissant le fil de sa vie. » Trouvez le vôtre.