
Je vais vous dire comment nous avons réussi à écrire un linter qui s'est avéré assez rapide pour vérifier les changements lors de chaque push git et le faire en 5-10 secondes avec une base de code de 5 millions de lignes en PHP. Nous l'avons appelé NoVerify.
NoVerify prend en charge des éléments de base tels que la transition vers la définition et la recherche d'utilisations et est capable de fonctionner en mode
Language Server . Tout d'abord, notre outil est axé sur la recherche d'erreurs potentielles, mais il peut également vérifier le style. Aujourd'hui, son code source est apparu en open-source sur GitHub. Recherchez le lien à la fin de l'article.
Pourquoi avons-nous besoin de notre linter
Mi-2018, nous avons décidé qu'il était temps d'implémenter un linter pour le code PHP. Il y avait deux objectifs: réduire le nombre d'erreurs visibles par les utilisateurs et surveiller plus strictement la conformité au style de code. L'accent principal était mis sur la prévention des erreurs typiques: la présence de variables non déclarées et inutilisées dans le code, le code inaccessible et d'autres. Je souhaitais également que l'analyseur statique fonctionne le plus rapidement possible sur notre base de code (5-6 millions de lignes de code PHP au moment de la rédaction).
Comme vous le savez probablement, le code source de la plupart du site est écrit en PHP et compilé en utilisant
KPHP , il serait donc logique d'ajouter ces vérifications au compilateur. Mais en fait, tout le code n'a pas de sens pour s'exécuter via KPHP - par exemple, le compilateur est faiblement compatible avec les bibliothèques tierces, donc pour certaines parties du site PHP standard est toujours utilisé. Ils sont également importants et doivent être vérifiés par le linter, donc, malheureusement, il n'y a aucun moyen de l'intégrer dans KPHP.
Pourquoi NoVerify
Compte tenu de la quantité de code PHP (je me souviens qu'il s'agit de 5-6 millions de lignes), il n'est pas possible de le "corriger" immédiatement pour qu'il passe nos vérifications dans le linter. Néanmoins, je veux que le code changeant devienne progressivement plus propre et suive plus strictement les normes de codage, et contienne également moins d'erreurs. Par conséquent, nous avons décidé que le linter devrait être en mesure de vérifier les modifications que le développeur allait lancer, et ne pas jurer sur le reste.
Pour ce faire, le linter doit indexer l'intégralité du projet, analyser complètement les fichiers avant et après les modifications et calculer la différence entre les avertissements générés. De nouveaux avertissements sont montrés au développeur, et nous exigeons qu'ils soient corrigés avant de pouvoir pousser.
Mais il y a des situations où ce comportement est indésirable, et les développeurs peuvent alors pousser sans hook local - en utilisant la commande
git push --no-verify . Option
--no-verify et a donné un nom à un linter :)
Quelles étaient les alternatives
La base de code dans VK utilise peu de POO et se compose essentiellement de fonctions et de classes avec des méthodes statiques. Si les classes en PHP prennent en charge le chargement automatique, les fonctions ne le font pas. Par conséquent, nous ne pouvons pas utiliser d'analyseurs statiques sans modifications importantes, qui fondent leur travail sur le fait que le chargement automatique chargera tout le code manquant. Ces linters comprennent, par exemple, le
psaume de Vimeo .
Nous avons examiné les outils d'analyse statique suivants:
- PHPStan - mono-thread, nécessite un chargement automatique, l'analyse de la base de code a atteint 30% en une demi-heure;
- Phan - même en mode rapide avec 20 processus, l'analyse a calé de 5% après 20 minutes;
- Psaume - nécessite un chargement automatique, l'analyse a pris 10 minutes (je voudrais quand même être beaucoup plus rapide);
- PHPCS - vérifie le style, mais pas la logique;
- phpcf - vérifie uniquement le formatage.
Comme vous pouvez le deviner d'après le titre de l'article, aucun de ces outils ne répond à nos exigences, nous avons donc rédigé les nôtres.
Comment le prototype a-t-il été créé?
Tout d'abord, nous avons décidé de construire un petit prototype afin de comprendre s'il valait la peine d'essayer de fabriquer un linterne à part entière. Étant donné que l'une des exigences importantes pour le linter est sa vitesse, au lieu de PHP, nous avons choisi Go. «Rapide» consiste à donner un feedback au développeur le plus rapidement possible, de préférence en 10 à 20 secondes maximum. Sinon, le cycle "corriger le code, relancer le linter" commence à ralentir considérablement le développement et à gâcher l'humeur des gens :)
Puisque Go est sélectionné pour le prototype, vous avez besoin d'un analyseur PHP. Il y en a plusieurs, mais le projet
php-parser nous a semblé le plus abouti. Cet analyseur n'est pas parfait et est toujours en cours de développement, mais pour nos besoins, il est tout à fait approprié.
Pour le prototype, il a été décidé d'essayer de mettre en œuvre l'une des inspections les plus simples, à première vue: l'accès à une variable non définie.
L'idée de base pour implémenter une telle inspection semble simple: pour chaque branche (par exemple, pour if), créez une portée imbriquée distincte et combinez les types de variables à la sortie de celle-ci. Un exemple:
<?php if (rand()) { $a = 42;
Ça a l'air simple, non? Dans le cas des instructions conditionnelles ordinaires, tout fonctionne bien. Mais nous devons gérer, par exemple, passer sans interruption;
<?php switch (rand()) { case 1: $a = 1;
Il ne ressort pas immédiatement du code que $ c sera en fait toujours défini. Plus précisément, cet exemple est fictif, mais il illustre bien ce que sont les moments difficiles pour le linter (et pour la personne dans ce cas aussi).
Prenons un exemple plus complexe:
<?php exec("hostname", $out, $retval); echo $out, $retval;
Sans connaître la signature de la fonction exec, on ne peut pas dire si $ out et $ retval seront définis. Les signatures des fonctions intégrées peuvent être extraites du référentiel
github.com/JetBrains/phpstorm-stubs . Mais les mêmes problèmes se produiront lors de l'appel de fonctions définies par l'utilisateur, et leur signature ne peut être découverte qu'en indexant l'intégralité du projet. La fonction exec prend les deuxième et troisième arguments par référence, ce qui signifie que les variables $ out et $ retval peuvent être définies. Ici, l'accès à ces variables n'est pas nécessairement une erreur, et le linter ne doit pas jurer sur un tel code.
Des problèmes similaires avec le passage implicite de liens se posent avec les méthodes, mais en même temps, la nécessité de déduire des types de variables est ajoutée:
<?php if (rand()) { $a = some_func(); } else { $a = other_func(); } $a->some_method($b); echo $b;
Nous devons savoir quels types les fonctions some_func () et other_func () renvoient afin de trouver plus tard une méthode appelée some_method dans ces classes. Ce n'est qu'alors que nous pourrons dire si la variable $ b sera définie ou non. La situation est compliquée par le fait que souvent les fonctions et méthodes simples n'ont pas d'annotations phpdoc, vous devez donc toujours être en mesure de calculer les types de fonctions et de méthodes en fonction de leur implémentation.
Lors du développement du prototype, j'ai dû implémenter environ la moitié de toutes les fonctionnalités pour que l'inspection la plus simple fonctionne correctement.
Travailler comme serveur linguistique
Pour faciliter le débogage de la logique du linter et voir plus facilement les avertissements qu'il émet, nous avons décidé d'ajouter le mode de fonctionnement en tant que
serveur de langage pour PHP . En mode d'intégration avec Visual Studio Code, cela ressemble à ceci:
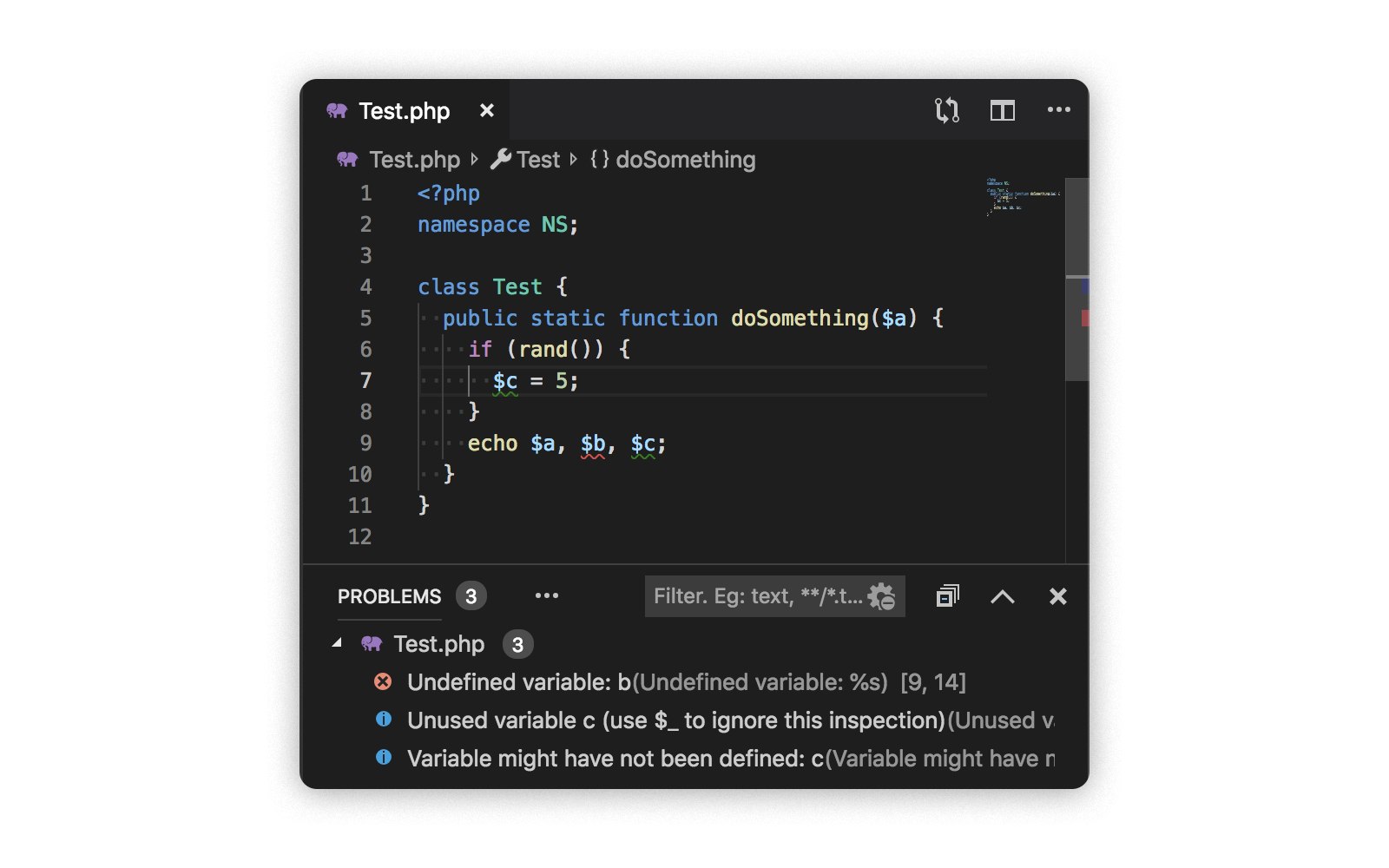
Dans ce mode, il est pratique de tester des hypothèses et de tester des cas complexes (après cela, vous devez bien sûr écrire des tests). Il est également bon de tester les performances: même sur des fichiers volumineux, l'analyseur php on Go affiche une bonne vitesse.
Le support du serveur de langue est loin d'être idéal, car son objectif principal est de déboguer les règles de linter. Cependant, dans ce mode, il existe plusieurs fonctionnalités supplémentaires:
- Conseils pour les noms de variables, les constantes, les fonctions, les propriétés et les méthodes.
- Mettez en surbrillance les types de variables dérivés.
- Allez à la définition.
- Rechercher des utilisations.
Inférence de type "paresseux"
En mode serveur de langue, les éléments suivants sont nécessaires pour fonctionner: vous modifiez le code dans un fichier, puis, lorsque vous passez à un autre, vous devez travailler avec des informations déjà mises à jour sur les types renvoyés dans les fonctions ou les méthodes. Imaginez les fichiers en cours d'édition dans l'ordre suivant:
<?php
Étant donné que nous ne forçons pas les développeurs à toujours écrire PHPDoc (en particulier dans de tels cas simples), nous avons besoin d'un moyen de stocker des informations sur le type de retour de la fonction B :: something (). De sorte que lorsque le fichier A.php change, les informations de type dans le fichier C.php sont immédiatement à jour.
Une solution possible consiste à stocker des "types paresseux". Par exemple, le type de retour de la méthode B :: something () est en fait un type d'expression (new A) -> prop. Dans ce formulaire, le linter stocke des informations sur le type, et grâce à cela, vous pouvez mettre en cache toutes les méta-informations pour chaque fichier et les mettre à jour uniquement lorsque ce fichier change. Cela doit être fait avec soin afin que des informations accidentellement trop spécifiques sur les types ne fuient pas. Il est également nécessaire de modifier la version du cache lorsque la logique d'inférence de type change. Néanmoins, un tel cache accélère la phase d'indexation (dont je parlerai plus tard) de 5 à 10 fois par rapport à l'analyse répétée de tous les fichiers.
Deux phases de travail: indexation et analyse
Comme nous nous en souvenons, même pour l'analyse de code la plus simple, des informations sont requises au moins sur toutes les fonctions et méthodes du projet. Cela signifie que vous ne pouvez pas analyser un seul fichier séparément du projet. Et pourtant - que cela ne peut pas être fait en un seul passage: par exemple, PHP vous permet d'accéder à des fonctions qui sont déclarées plus loin dans le fichier.
En raison de ces limitations, le fonctionnement du linter comprend deux phases: l'indexation principale et l'analyse ultérieure des seuls fichiers nécessaires. Maintenant, plus sur ces deux phases.
Phase d'indexation
Dans cette phase, tous les fichiers sont analysés et une analyse locale du code des méthodes et fonctions, ainsi que du code au niveau supérieur est effectuée (par exemple, pour déterminer les types de variables globales). Les informations sur les variables globales déclarées, les constantes, les fonctions, les classes et leurs méthodes sont collectées et écrites dans le cache. Pour chaque fichier du projet, le cache est un fichier distinct sur le disque.
Un dictionnaire global de toutes les méta-informations sur le projet, qui ne changera pas à l'avenir, * est compilé à partir de pièces individuelles.
* En plus du mode de fonctionnement en tant que serveur de langue, lors de l'indexation et de l'analyse du fichier modifié est effectuée pour chaque édition.Phase d'analyse
Dans cette phase, nous pouvons utiliser des méta-informations (sur les fonctions, les classes ...) et déjà analyser directement le code. Voici une liste de ce que NoVerify peut vérifier par défaut:
- code inaccessible;
- accès aux objets sous forme de tableau;
- nombre d'arguments insuffisant lors de l'appel de la fonction;
- appeler une méthode / fonction non définie;
- accès à la propriété / constante de classe manquante;
- manque de classe;
- PHPDoc non valide
- accès à une variable non définie;
- accès à une variable qui n'est pas toujours définie;
- absence de "pause"; après cas dans les constructions switch / case;
- erreur de syntaxe
- variable inutilisée.
La liste est assez courte, mais vous pouvez ajouter des contrôles spécifiques à votre projet.
Pendant le fonctionnement du linter, il s'est avéré que l'inspection la plus utile n'est que la dernière (variable inutilisée). Cela se produit souvent lorsque vous refactorisez le code (ou en écrivez un nouveau) et que vous le scellez dans le nom de la variable: ce code est valide du point de vue de PHP, mais erroné en logique.
Vitesse de travail
Combien de temps le changement que nous souhaitons pousser est-il vérifié? Tout dépend du nombre de fichiers. Avec NoVerify, le processus peut prendre jusqu'à une minute (c'était lorsque j'ai changé 1400 fichiers dans le référentiel), mais s'il y avait peu de modifications, alors généralement toutes les vérifications passent en 4-5 secondes. Pendant ce temps, le projet est complètement indexé, analysant les nouveaux fichiers, ainsi que leur analyse. Nous avons réussi à créer un linter pour PHP, qui fonctionne rapidement même avec notre large base de code.
Quel est le résultat?
Puisque la solution est écrite en Go, il est nécessaire d'utiliser le référentiel
github.com/JetBrains/phpstorm-stubs afin d'avoir des définitions de toutes les fonctions et classes intégrées dans PHP. En retour, nous avons obtenu une vitesse de travail élevée (indexation de 1 million de lignes par seconde, analyse de 100 000 lignes par seconde) et avons pu ajouter des vérifications avec un linter comme l'une des premières étapes des git push hooks.
Une base pratique a été développée pour créer de nouvelles inspections et un niveau de compréhension du code proche de PHPStorm a été atteint. En raison du fait que le mode de calcul différentiel est pris en charge, il est possible d'améliorer progressivement le code, en évitant de nouvelles constructions potentiellement problématiques dans le nouveau code.
Compter diff n'est pas idéal: par exemple, si un gros fichier a été divisé en plusieurs petits, alors git, et donc NoVerify, ne sera pas en mesure de déterminer que le code a été déplacé, et le linter devra résoudre tous les problèmes trouvés. À cet égard, le calcul de diff empêche le refactoring à grande échelle, donc dans de tels cas, il est souvent désactivé.
Écrire un linter sur Go a un autre avantage: non seulement l'analyseur AST est plus rapide et consomme moins de mémoire qu'en PHP, mais l'analyse ultérieure est également très rapide par rapport à tout ce qui pourrait être fait en PHP. Cela signifie que notre linter peut effectuer une analyse plus complexe et plus approfondie du code, tout en conservant des performances élevées (par exemple, la fonctionnalité "types paresseux" nécessite un nombre assez important de calculs dans le processus).
Open source
NoVerify disponible en open source sur GitHubProfitez de votre utilisation dans votre projet!
UPD: J'ai préparé une
démo qui fonctionne via WebAssembly . La seule limitation de cette démo est le manque de définitions de fonctions des phpstorm-stubs, donc le linter jurera sur les fonctions intégrées.
Yuri Nasretdinov, développeur du département d'infrastructure de VKontakte