
Qu'est-ce qui vous inquiète le plus lorsque vous pensez à vous connecter à NodeJS? Si vous me demandez, je vais dire le manque de normes de l'industrie pour créer des identifiants de trace. Dans cet article, nous allons présenter comment créer ces ID de trace (ce qui signifie que nous allons examiner brièvement comment fonctionne le stockage local de continuation aka CLS ) et approfondir la façon dont nous pouvons utiliser le proxy pour le faire fonctionner avec N'IMPORTE QUEL enregistreur.
Pourquoi est-ce même un problème d'avoir un ID de trace pour chaque demande dans NodeJS?
Eh bien, sur les plates-formes qui utilisent le multithread et génèrent un nouveau thread pour chaque demande. Il y a une chose appelée stockage local de thread aka TLS , qui permet de garder toutes les données arbitraires disponibles à quoi que ce soit dans un thread. Si vous avez une API native pour le faire, il est assez simple de générer un ID aléatoire pour chaque demande, mettez-le dans TLS et utilisez-le plus tard dans votre contrôleur ou service. Alors, quel est le problème avec NodeJS?
Comme vous le savez, NodeJS est une plate-forme monothread (qui n'est plus vraiment vraie car nous avons maintenant des travailleurs, mais cela ne change pas la vue d'ensemble), ce qui rend TLS obsolète. Au lieu d'utiliser différents threads, NodeJS exécute différents rappels dans le même thread (il y a une grande série d'articles sur la boucle d'événements dans NodeJS si vous êtes intéressé) et NodeJS nous fournit un moyen d'identifier de manière unique ces rappels et de tracer leurs relations les uns avec les autres .
Dans le passé (v0.11.11), nous avions addAsyncListener qui nous permettait de suivre les événements asynchrones. Sur cette base, Forrest Norvell a construit la première implémentation du stockage local de continuation aka CLS . Nous n'allons pas couvrir cette implémentation de CLS car nous, en tant que développeurs, avons déjà été dépouillés de cette API dans la v0.12.
Jusqu'à NodeJS 8, nous n'avions aucun moyen officiel de se connecter au traitement des événements asynchrones de NodeJS. Et enfin, NodeJS 8 nous a accordé le pouvoir que nous avons perdu via async_hooks (si vous voulez mieux comprendre async_hooks, jetez un œil à cet article ). Cela nous amène à l'implémentation moderne basée sur async_hooks de CLS - cls-hooked .
Présentation de CLS
Voici un flux simplifié du fonctionnement de CLS:
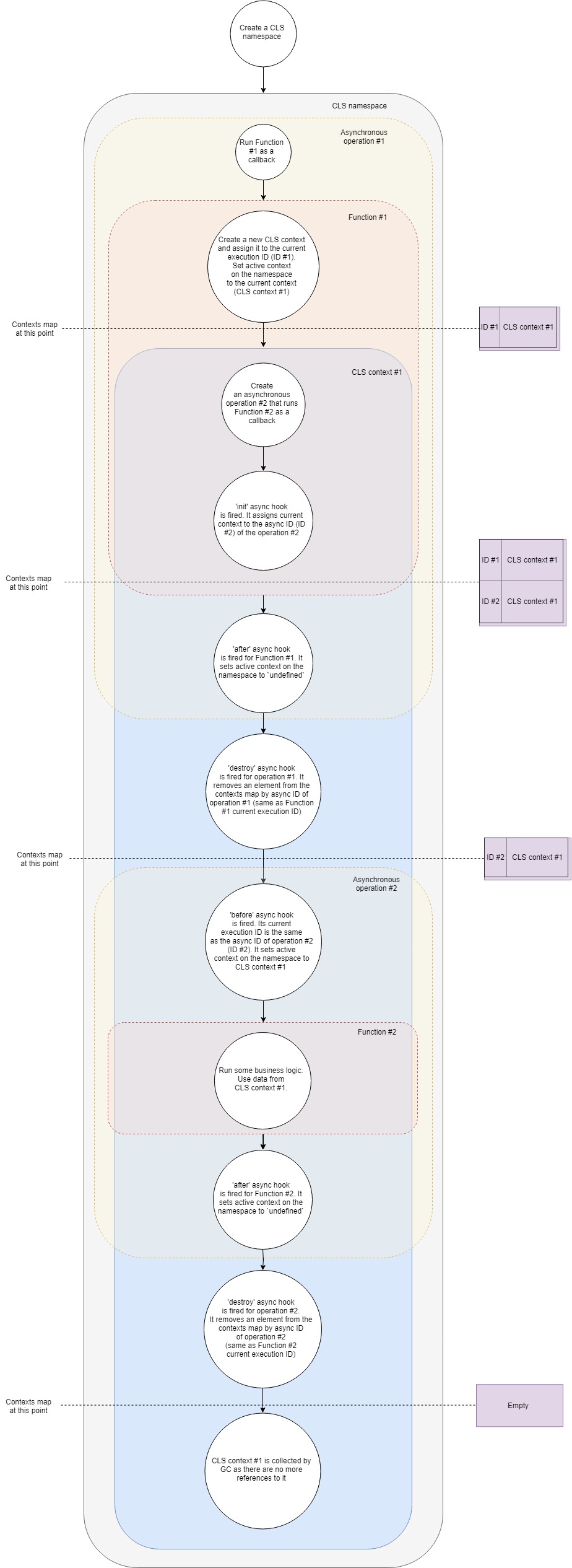
Décomposons-le étape par étape:
- Disons que nous avons un serveur Web typique. Nous devons d'abord créer un espace de noms CLS. Une fois pour toute la durée de vie de notre application.
- Deuxièmement, nous devons configurer un middleware pour créer un nouveau contexte CLS pour chaque demande. Par souci de simplicité, supposons que ce middleware est juste un rappel qui est appelé lors de la réception d'une nouvelle demande.
- Ainsi, lorsqu'une nouvelle demande arrive, nous appelons cette fonction de rappel.
- Dans cette fonction, nous créons un nouveau contexte CLS (l'une des façons consiste à exécuter l' appel de l'API).
- À ce stade, CLS place le nouveau contexte dans une carte des contextes par ID d'exécution en cours .
- Chaque espace de noms CLS a
active propriété active . À ce stade, CLS affecte des active au contexte. - À l'intérieur du contexte, nous appelons une ressource asynchrone, disons, nous demandons des données à la base de données. Nous passons un rappel à l'appel, qui va s'exécuter une fois la demande à la base de données terminée.
- init hook async est déclenché pour une nouvelle opération asynchrone. Il ajoute le contexte actuel à la carte des contextes par ID asynchrone (considérez-le comme un identifiant de la nouvelle opération asynchrone).
- Comme nous n'avons plus de logique à l'intérieur de notre premier rappel, il se termine effectivement mettant fin à notre première opération asynchrone.
- après que le crochet asynchrone est déclenché pour le premier rappel. Il définit le contexte actif de l'espace de noms sur
undefined (ce n'est pas toujours vrai car nous pouvons avoir plusieurs contextes imbriqués, mais dans le cas le plus simple, c'est vrai). - destroy hook est tiré pour la première opération. Il supprime le contexte de notre carte des contextes par son ID asynchrone (c'est le même que l'ID d'exécution actuel de notre premier rappel).
- La demande à la base de données est terminée et notre deuxième rappel est sur le point d'être déclenché.
- À ce stade, avant que le crochet asynchrone n'entre en jeu. Son ID d'exécution actuel est le même que l'ID asynchrone de la deuxième opération (requête de base de données). Il définit
active propriété active de l'espace de noms sur le contexte trouvé par son ID d'exécution actuel. C'est le contexte que nous avons créé auparavant. - Maintenant, nous exécutons notre deuxième rappel. Exécutez une logique métier à l'intérieur. Dans cette fonction, nous pouvons obtenir n'importe quelle valeur par clé du CLS et il va retourner tout ce qu'il trouve par la clé dans le contexte que nous avons créé auparavant.
- En supposant que c'est la fin du traitement de la demande, notre fonction retourne.
- après que le crochet asynchrone est déclenché pour le deuxième rappel. Il définit le contexte actif de l'espace de noms sur
undefined . destroy hook est déclenché pour la deuxième opération asynchrone. Il supprime notre contexte de la carte des contextes par son ID asynchrone le laissant absolument vide.- Comme nous ne détenons plus de références à l'objet contextuel, notre garbage collector libère la mémoire qui lui est associée.
C'est une version simplifiée de ce qui se passe sous le capot, mais il couvre toutes les étapes principales. Si vous voulez creuser plus profondément, vous pouvez jeter un œil au code source . C'est moins de 500 lignes.
Génération d'ID de trace
Donc, une fois que nous avons une compréhension globale de CLS, réfléchissons à comment nous pouvons l'utiliser pour notre propre bien. Une chose que nous pourrions faire est de créer un middleware qui enveloppe chaque demande dans un contexte, génère un identifiant aléatoire et le place dans CLS par clé traceID . Plus tard, à l'intérieur de l'un de nos contrôleurs et services gazillion, nous pourrions obtenir cet identifiant de CLS.
Pour exprimer ce middleware pourrait ressembler à ceci:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Ensuite, dans notre contrôleur, nous pourrions obtenir l'ID de trace généré comme ceci:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
Il n'y a pas tant d'utilisation de cet ID de trace que si nous l'ajoutons à nos journaux.
Ajoutons-le à notre winston .
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Eh bien, si tous les enregistreurs prenaient en charge les formateurs dans une forme de fonctions (beaucoup d'entre eux ne le font pas pour une bonne raison), cet article n'existerait pas. Alors, comment ajouter un identifiant de trace à mon pino bien-aimé? Procuration à la rescousse!
Combinaison de proxy et CLS
Le proxy est un objet qui enveloppe notre objet d'origine nous permettant de remplacer son comportement dans certaines situations. La liste de ces situations (elles sont en fait appelées pièges) est limitée et vous pouvez jeter un œil à l'ensemble ici , mais nous ne sommes intéressés que par get get . Il nous donne la possibilité d'intercepter l'accès à la propriété. Cela signifie que si nous avons un objet const a = { prop: 1 } et l'enveloppons dans un proxy, avec get trap, nous pourrions retourner tout ce que nous voulons pour a.prop .
L'idée est donc de générer un ID de trace aléatoire pour chaque demande et de créer un enregistreur de pino enfant avec l'ID de trace et de le mettre dans CLS. Ensuite, nous pourrions envelopper notre enregistreur d'origine avec un proxy, qui redirigerait toutes les demandes de journalisation vers l'enregistreur enfant dans CLS s'il en trouvait un et continuerait à utiliser l'enregistreur d'origine dans le cas contraire.
Dans ce scénario, notre proxy pourrait ressembler à ceci:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Notre middleware se transformerait en quelque chose comme ceci:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
Et nous pourrions utiliser l'enregistreur comme ceci:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Sur la base de l'idée ci-dessus, une petite bibliothèque appelée cls-proxify a été créée. Il a une intégration avec express , koa et fastify prêt à l' emploi .
Il s'applique non seulement à get piège sur l'objet d'origine, mais aussi sur bien d'autres . Il y a donc une infinité d'applications possibles. Vous pouvez utiliser des appels de fonction proxy, la construction de classes, à peu près n'importe quoi! Vous n'êtes limité que par votre imagination!
Jetez un œil aux démonstrations en direct de son utilisation avec pino et fastify, pino et express .
J'espère que vous avez trouvé quelque chose d'utile pour votre projet. N'hésitez pas à me faire part de vos retours! J'apprécie très certainement toute critique et question.