
Qu'est-ce qui vous exaspère le plus lorsque vous essayez d'organiser des journaux lisibles dans votre application NodeJS? Personnellement, je suis extrêmement ennuyé par l'absence de normes matures saines pour la création d'ID de trace. Dans cet article, nous parlerons des options pour créer un ID de trace, examinons comment fonctionne le stockage local continu ou CLS sur nos doigts et faisons appel à la force du proxy pour obtenir tout cela avec n'importe quel enregistreur.
Pourquoi y a-t-il un problème dans NodeJS avec la création d'un ID de trace pour chaque demande?
Dans les temps anciens, anciens et anciens, lorsque les mammouths parcouraient encore la terre, les serveurs tout-en-un étaient multithread et créaient un nouveau thread pour une demande. Dans le cadre de ce paradigme, la création d'un identifiant de trace est triviale, car il existe une chose telle que le stockage local par thread ou TLS , qui vous permet de mettre en mémoire certaines données disponibles pour n'importe quelle fonction de ce flux. Au début du traitement de la demande, vous pouvez utiliser l'ID de trace aléatoire, le mettre dans TLS, puis le lire dans n'importe quel service et faire quelque chose avec. Le problème est que cela ne fonctionnera pas dans NodeJS.
NodeJS est mono-thread (pas tout à fait, étant donné l'apparence des travailleurs, mais dans le cadre du problème avec l'ID de trace, les travailleurs ne jouent aucun rôle), vous pouvez donc oublier TLS. Ici, le paradigme est différent - pour jongler avec un tas de rappels différents au sein du même thread, et dès que la fonction veut faire quelque chose d'asynchrone, envoyez cette demande asynchrone et donnez du temps au processeur à une autre fonction dans la file d'attente (si vous êtes intéressé par le fonctionnement de cette chose, fièrement appelée boucle d'événement) sous le capot, je vous recommande de lire cette série d'articles ). Si vous pensez à la façon dont NodeJS comprend le rappel à appeler, vous pouvez supposer que chacun d'eux doit correspondre à un ID. De plus, NodeJS dispose même d'une API qui donne accès à ces ID. Nous allons l'utiliser.
Dans les temps anciens, lorsque les mammouths s'étaient éteints, mais les gens ne connaissaient toujours pas les avantages des eaux usées centrales, (NodeJS v0.11.11), nous avions addAsyncListener . Sur cette base, Forrest Norvell a créé la première implémentation de stockage local continu ou CLS . Mais nous ne parlerons pas de la façon dont cela a fonctionné alors, puisque cette API (je parle d’addAsyncLustener) a commandé une longue durée de vie. Il est déjà mort dans NodeJS v0.12.
Avant NodeJS 8, il n'existait aucun moyen officiel de suivre la file d'attente des événements asynchrones. Et enfin, dans la version 8, les développeurs de NodeJS ont rétabli la justice et nous ont présenté l' API async_hooks . Si vous souhaitez en savoir plus sur async_hooks, je vous recommande de lire cet article . Basé sur async_hooks, une refactorisation de la précédente implémentation de CLS a été effectuée. La bibliothèque est appelée cls-hooked .
CLS sous le capot
De manière générale, le schéma de fonctionnement CLS peut être représenté comme suit:
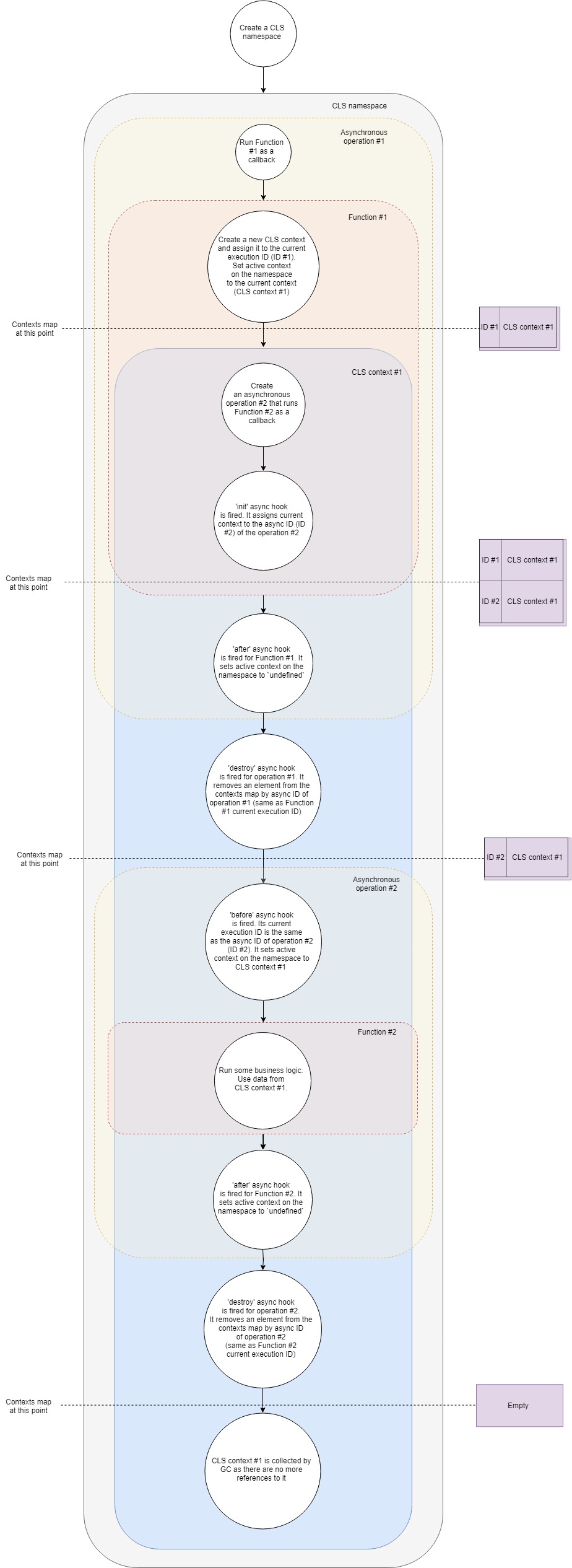
Prenons-le un peu plus en détail:
- Supposons que nous ayons un serveur Web Express typique. Créez d'abord un nouvel espace de noms CLS. Une fois pour toute la durée de vie de l'application.
- Deuxièmement, nous créerons un middleware, qui créera notre propre contexte CLS pour chaque requête.
- Lorsqu'une nouvelle demande arrive, ce middleware (Fonction # 1) est appelé.
- Dans cette fonction, créez un nouveau contexte CLS (comme une option, vous pouvez utiliser Namespace.run ). Dans Namespace.run, nous transmettons une fonction qui sera exécutée dans le cadre de notre contexte.
- CLS ajoute un contexte fraîchement créé à Map avec des contextes avec la clé d' ID d'exécution en cours .
- Chaque espace de noms CLS a une propriété
active . CLS attribue à cette propriété une référence à notre contexte. - Dans une portée de contexte, nous faisons une sorte de requête asynchrone, disons, à la base de données. Nous transmettons le rappel au pilote de base de données, qui sera appelé lorsque la demande sera terminée.
- Le crochet d' initialisation asynchrone se déclenche . Il ajoute le contexte actuel à la carte avec des contextes par ID asynchrone (ID de la nouvelle opération asynchrone).
- Parce que notre fonction n'a plus d'instructions supplémentaires, elle termine l'exécution.
- Un crochet asynchrone fonctionne pour elle. Il affecte la propriété
active à un espace de noms undefined (en fait, pas toujours, car nous pouvons avoir plusieurs contextes imbriqués, mais dans le cas le plus simple, c'est le cas). - Le crochet de destruction asynchrone se déclenche pour notre première opération asynchrone. Il supprime le contexte de la carte avec les contextes par l'ID asynchrone de cette opération (il est le même que l'ID d'exécution actuel du premier rappel).
- La requête dans la base de données est terminée et le deuxième rappel est appelé.
- Crochet asynchrone avant . Son ID d'exécution actuel est le même que l'ID asynchrone de la deuxième opération (requête de base de données). La propriété
active espace de noms se voit attribuer le contexte trouvé dans la carte avec les contextes par l'ID d'exécution en cours. C'est le contexte que nous avons créé auparavant. - Maintenant, le deuxième rappel est exécuté. Une logique commerciale fonctionne, les démons dansent, la vodka coule. À l'intérieur de cela, nous pouvons obtenir n'importe quelle valeur du contexte par clé . CLS essaiera de trouver la clé donnée dans le contexte actuel ou retournera
undefined . - Le hook asynchrone après pour ce rappel est déclenché lorsqu'il est terminé. Il définit la propriété
active de l'espace de noms sur undefined . - Le crochet asynchrone destroy se déclenche pour cette opération. Il supprime le contexte de la carte avec les contextes par l'ID asynchrone de cette opération (il est le même que l'ID d'exécution actuel du deuxième rappel).
- Le garbage collector (GC) libère la mémoire associée à l'objet contextuel, car dans notre application, il n'y a plus de liens vers elle.
Il s'agit d'une vue simplifiée de ce qui se passe sous le capot, mais elle couvre les principales phases et étapes. Si vous avez envie de creuser un peu plus, je vous recommande de vous familiariser avec les tris . Il n'y a que 500 lignes de code.
Créer un ID de trace
Donc, après avoir traité avec le CLS, nous allons essayer d'utiliser cette chose au profit de l'humanité. Créons un middleware, qui pour chaque demande crée son propre contexte CLS, crée un ID de trace aléatoire et l'ajoute au contexte à l'aide de la clé traceID . Ensuite, à l'intérieur de l'ofigilliard de nos contrôleurs et services, nous obtenons cet ID de trace.
Pour express, un middleware similaire pourrait ressembler à ceci:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Et dans notre contrôleur ou service, nous pouvons obtenir ce traceID dans une seule ligne de code:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
Certes, sans ajouter cet ID de trace aux journaux, il en profite, comme une souffleuse à neige en été.
Écrivons un simple formateur Winston qui ajoutera automatiquement l'ID de trace.
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Et si tous les enregistreurs prenaient en charge le formateur personnalisé sous forme de fonctions (beaucoup d'entre eux ont des raisons de ne pas le faire), cet article ne se serait probablement pas produit. Alors, comment pourriez-vous ajouter un ID de trace aux journaux du pino adoré?
Nous faisons appel à Proxy afin de se faire des amis TOUT logger et CLS
Quelques mots sur Proxy lui-même: c'est une chose qui enveloppe notre objet d'origine et nous permet de redéfinir son comportement dans certaines situations. Dans une liste limitée de situations strictement définies (en science, on les appelle des traps ). Vous pouvez trouver la liste complète ici , nous ne sommes intéressés que par get trap. Cela nous donne la possibilité de remplacer la valeur de retour lors de l'accès à la propriété de l'objet, c'est-à-dire si nous prenons l'objet const a = { prop: 1 } et l'enveloppons dans Proxy, alors avec l'aide de trap, nous pouvons retourner tout ce que nous aimons en accédant à a.prop .
Dans le cas de pino idée est la suivante: nous créons un ID de trace aléatoire pour chaque demande, créons une instance enfant pino dans laquelle nous transmettons cet ID de trace et mettons cette instance enfant dans le CLS. Ensuite, nous encapsulons notre enregistreur source dans Proxy, qui utilisera cette même instance enfant pour la journalisation, s'il y a un contexte actif et s'il y a un enregistreur enfant, ou utilisez l'enregistreur d'origine.
Dans un tel cas, le proxy ressemblera à ceci:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Notre middleware ressemblera à ceci:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
Et nous pouvons utiliser l'enregistreur comme ceci:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Sur la base de l'idée ci-dessus, une petite bibliothèque cls-proxify a été créée. Elle travaille hors de la boîte avec express , koa et fastify . En plus de créer un piège pour get , il crée d' autres pièges pour donner plus de liberté au développeur. Pour cette raison, nous pouvons utiliser Proxy pour encapsuler des fonctions, des classes et plus encore. Il y a une démo en direct sur la façon d'intégrer pino et fastify, pino et express .
J'espère que vous n'avez pas perdu de temps en vain, et l'article vous a au moins été un peu utile. Veuillez donner un coup de pied et critiquer. Nous apprendrons à mieux coder ensemble.