Il y a un peu plus d'un mois à Moscou s'est tenue la plus grande conférence de la communauté post-gree PGConf.Russia 2019, qui a réuni plus de 700 personnes à l'Université d'État de Moscou. Nous avons décidé de publier une vidéo et une transcription des meilleurs reportages. La présentation d'
Ivan Frolkov sur les erreurs typiques lors de l'utilisation de PostgreSQL a été considérée comme la meilleure lors de la conférence, nous allons donc commencer par elle.
Pour plus de commodité, nous avons divisé le décryptage en deux parties. Dans cet article, nous parlerons de la dénomination incohérente, des contraintes, de l'endroit où il est préférable de concentrer la logique - dans la base de données ou dans l'application. La deuxième partie traitera du traitement des erreurs, des accès simultanés, des opérations non annulables, CTE et JSON.

Dans notre entreprise, je suis engagé dans le support client sur les problèmes liés aux applications, c'est-à-dire que j'aide en cas de problèmes de connexion, d'optimisation des requêtes et d'autres choses similaires. J'ai vu suffisamment d'applications parmi les plus diverses. Ce que je n'ai tout simplement pas vu! Peut-être même plus que nous ne le souhaiterions. Une partie de ce que je dirai s'applique non seulement à PostgreSQL, mais à toute base de données, mais quelque chose principalement à PostgreSQL.
La principale conclusion que j'ai pu tirer de ce que j'ai vu était plutôt inattendue: en fait, toute application avec la persistance voulue peut être mise au travail. Il y avait un merveilleux projet (je ne peux pas mentionner toutes les entreprises avec lesquelles nous avons travaillé) dans lequel une application encore plus merveilleuse a créé des tables par millions. Cela ressemblait à ceci: lundi, le système fonctionne bien et vendredi, il ne fonctionne pratiquement pas. Le week-end, ils lancent VACUUM FULL, et le lundi, cela fonctionne bien à nouveau. Il s'avère que vous pouvez vous moquer de PostgreSQL comme ça, et tout cela va vivre et fonctionner pendant un certain temps. Un autre camarade a fait une chose étrange: tout était construit sur des déclencheurs sur lui, il n'y avait aucune procédure du tout. Autrement dit, la plupart des tables ne peuvent pas être touchées, quelque chose ne pouvait pas être fait, mais cette base a également vécu.
Il l'explique ainsi: «la base passe d'un état cohérent à un autre cohérent. Si je télécharge à nouveau les données, elles se briseront. Mais comme j'ai des déclencheurs et une clé unique, je ne peux pas relancer les données. » L'approche est sauvage, mais en même temps, elle a du sens. Peut-être fallait-il faire différemment, mais il faut aussi prendre en compte les caractéristiques des clients. La première erreur dont je vais parler est:

Voici un vrai exemple que j'ai rencontré. Sur la diapositive, vous voyez comment la même entité a été nommée dans différentes colonnes. On pourrait aussi avec des espaces. D'autres objets ont également été nommés de manière incohérente. Si vous avez besoin de prendre quelque chose dans une autre table, alors vous devez voir comment cela s'appelle là, est-ce la même chose. Si vous avez id_user et user_id dans la même table, le travail commence par la recherche: qu'est-ce que tout cela signifierait.
Pour les autres clients, tous les objets ont été nommés comme ceci: deux lettres, puis cinq chiffres. Je dois dire que ce n'était pas «1C». Pourquoi ils ont fait ça - je ne sais pas: il n'y avait pas de logique là-dedans, mais c'est mon affaire d'optimiser les requêtes.
Un autre exemple: une partie des noms en russe, une partie en non russe, mais avec une sorte d'accent russe. Cela rend la compréhension difficile et crée de nouvelles erreurs. J'essaie moi-même de nommer les colonnes comme si je comptais sur un service, lequel de ces noms de colonne fera automatiquement des noms de colonne normaux dans certains rapports. Dans la vraie vie, malheureusement, ce n'est pas très réussi de nommer de manière cohérente - y compris la mienne. Cela est particulièrement difficile avec le développement collectif. Mais nous devons nous efforcer.
Une autre raison importante de nommer de manière séquentielle: les noms d'objets sont disponibles via des demandes de métadonnées, c'est-à-dire que les noms sont également des données. Vous pourrez rédiger une demande et sélectionner, disons, toutes les images - en général, toutes les images - de la base de données.

Des métadonnées claires sont très pratiques. Surtout lorsque vous considérez les problèmes typiques de la documentation - et d'après mon expérience, la documentation est généralement soit absente, incomplète ou incorrecte, ou les deux: parce que la tâche d'écrire une bonne documentation est comparable en complexité à la tâche d'écrire le code lui-même. C'est donc mieux lorsque le code est auto-documenté. Et une dénomination logique et cohérente des objets y contribue, et lorsque quelque chose n'est pas clair, vous devez écrire du code d'extrait et regarder comment cela fonctionne. Une fois ce n'est rien, deux rien, mais quand vous le faites toute la journée, c'est épuisant.
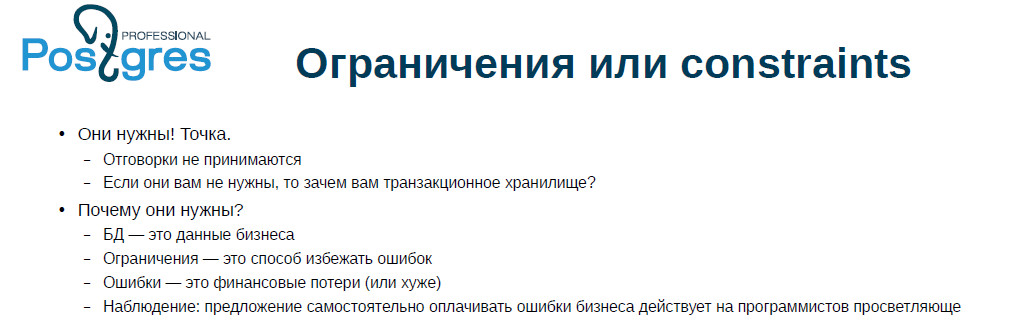
Le cas réel: une organisation très sérieuse avec laquelle nous avons travaillé avait un workflow de base sur Oracle. Nous l'avons déplacé vers Postgres. L'une des conditions du contrat était que nous imposions des CLÉS ÉTRANGÈRES. Ils n'étaient pas là et, malheureusement, nous n'avons pas pu les imposer: il s'est avéré que les tables avaient beaucoup de rangées «à gauche», et personne ne sait quoi en faire, y compris le client.
Lorsque vous n'avez pas besoin de regarder les barres de progression, mais de travailler avec des documents pour payer de l'argent, la situation est triste. Cela aide beaucoup lorsque, en vertu du contrat, le programmeur paie lui-même les erreurs, et il est souhaitable que les montants soient élevés - alors l'illumination se produit en quelques minutes, probablement quinze. Des contraintes apparaissent immédiatement, immédiatement tout commence à être vérifié.
Vous n’imaginez même pas (enfin, peut-être que quelqu'un l’imagine déjà) à quel point il est plus pratique de traiter l’affaire lorsque le paiement a échoué, que lorsqu’il a réussi, mais pas là. Surtout si le montant est important. C'est par expérience personnelle.

D'un autre côté, on peut souvent entendre que cette contrainte réduit les performances. Oui, ils le font, mais si vous voulez avoir les données correctes, il n'y a tout simplement pas d'autres options pour vous. Si vous avez une application qui prend en compte le nombre de visites au magasin par les clients, alors il peut y avoir des inexactitudes qui n'affecteront pas particulièrement les statistiques, et si nous comptons de l'argent, des contraintes sont nécessaires.
Les noms de contraintes sont généralement générés par un ORM ou un système, et généralement personne ne dérange spécifiquement pour nommer les contraintes - mais en vain! Lorsque vous continuez à traiter l'erreur, puis par le nom de la contrainte, vous pouvez envoyer un message clair à l'utilisateur, classer l'erreur et vous faire savoir si vous devez réessayer d'effectuer l'opération, si cette opération n'est plus nécessaire ou simplement ne peut pas être répétée.
Une autre chose que je n'ai pas vue, mais que je recommande fortement: pour toutes les opérations d'audit financier importantes (et pas seulement financières), il devrait y en avoir au moins deux. Le fait est que tôt ou tard vous entrerez dans quelque chose à changer dans le code, et il se pourrait très bien que vous cassiez l'une des vérifications. Ensuite, le second vous sauvera. Si vous en faites trois, ce n'est pas mal non plus.

La question se pose souvent: où vérifier l'exactitude des données. Sur le client ou sur le serveur? À mon avis, il est évident que vous devez vérifier à la fois là et là. Vous avez une erreur dans le client, alors le serveur n'est pas
va manquer, ou vous avez une erreur sur le serveur, alors au moins le client aidera à le suivre. La question est quelque peu discutable, et nous passons en douceur au sujet: où conserver la logique de base: dans l'application ou dans la base de données?
C'est pratique dans la base de données car, selon mon expérience, une entreprise émet régulièrement des changements urgents: supprimez ou insérez ceci et cela tout de suite. Si vous avez de la logique dans le code compilé, vous devez collecter, déployer, voir ce qui s'est passé. Souvent, cela est tout simplement impossible. Dans la base de données, c'est plus pratique. Mais il y a un aphorisme bien connu: les programmeurs expérimentés de Fortran écrivent en Fortran dans n'importe quelle langue. Environ 80 codes de serveur sont écrits dans un style complètement procédural: nous avons la fonction "get_user ()" et il retourne le type "user", et si "get_list_users ()", alors il retourne un tableau de "users". Il est vraiment plus pratique d'écrire de telles choses en Java qu'en SQL ou pgsql.

D'un autre côté: pourquoi avez-vous besoin de la fonction "get_user ()"? Vous le prenez simplement dans une table ou dans une vue. Puisque vous avez une base de données relationnelle, vous devez écrire, comme il me semble, relationnel. Il est important, tout d'abord, de déterminer clairement les données avec lesquelles nous travaillons: si nos données sont des ordures ou des semi-ordures, le résultat sera approprié et ne devrait probablement pas être détruit. Si les données sont importantes pour nous, que ce soit de l'argent, des biens ou des opérations juridiques, alors la contrainte est nécessaire et plus c'est mieux. Je le répète: il vaut mieux ne pas effectuer l'opération que de l'exécuter incorrectement. Et n'écrivez pas de code procédural dans une base de données relationnelle: vous le regretterez beaucoup.

J'ai vu un tableau avec 30 000 lignes (produits), dans lequel la demande «afficher une liste des marchandises pertinentes» a été exécutée pendant environ une seconde. Apparemment, ils ont réussi à créer un schéma de base de données «beau et complexe». Personnellement, je pense que si vous faites quelque chose de très délicat, alors vous faites probablement quelque chose de mal ou vous avez vraiment une tâche très, très difficile. Si vous avez une sorte de magasin ou une application régulière pour les comptables, il est peu probable qu'il existe des relations très complexes entre les entités.
Lorsque j'ai commencé ma carrière professionnelle, la table dans un fichier DBF de 60 mégaoctets dans le système bancaire semblait très grande, et maintenant 60 mégaoctets ne sont rien du tout - le matériel est meilleur, les logiciels sont meilleurs, tout fonctionne plus rapidement, mais la question demeure: où obtenez-vous autant des données? Les très grandes bases gonflées le deviennent généralement à cause des archives. Dans n'importe quel SGBD et dans PostgreSQL, beaucoup d'efforts ont été consacrés à assurer un fonctionnement compétitif cohérent des applications. L'archive ne change probablement pas, et la plupart des capacités du SGBD pour travailler avec lui ne sont pas du tout nécessaires. Il vaut la peine de penser à le retirer du SGBD.

De temps en temps, avec une sorte de strabisme du commissaire, ils se posent la question: PostgreSQL tirera-t-il une base de tel ou tel volume. Mais ici, la question elle-même est étrange: vous pouvez mettre des données dans la base de données autant de fois que vous le souhaitez, tant qu'il y a suffisamment d'espace disque, tant il y en aura. La question est, par exemple, comment sauvegarder des archives en pétaoctets, où vous mettez la sauvegarde complète et combien vous l'enlèverez. Je soupçonne fortement qu'au moins partiellement ces besoins en volume sont liés au désir des vendeurs d'équipement de vous vendre davantage.
Si vous stockez des documents dans la base de données, il est peu probable que vous les y traitiez: la feuille de calcul Excel peut, bien sûr, être modifiée sur le serveur, mais c'est une occupation étrange. Ces fichiers seront probablement en lecture seule. Il est préférable de stocker des liens vers des documents et eux-mêmes dans un stockage externe. En fin de compte, vous pouvez conserver la signature numérique du tableau - afin qu'elle ne change pas (si vous décidez des questions législatives pertinentes).
Autre observation: si vous n'avez pas de méga-méga-entreprise, pas une sorte d'entreprise fédérale, par exemple, il est peu probable que vous ayez une très grande base. Si vous n'y stockez pas de vidéo, bien sûr.

Une autre raison pour laquelle la base de données est volumineuse est les index inutiles. Bases sans index Je n'ai pas rencontré, mais assez souvent j'ai rencontré des bases où plusieurs index sur les mêmes colonnes dans le même ordre. La base vous permet de le faire. Lorsque vous créez un index, vérifiez s'il en double un existant. Vous pouvez voir quels index ne sont pas nécessaires en consultant pg_stat_user_indexes pour voir dans quelle mesure l'index est utilisé activement. Peut-être qu'il n'est pas du tout requis.
Je suis tombé sur une situation (au fait, typique), quand une très grande table n'est pas partitionnée. Dans tous les SGBD, les grandes tables sont mieux partitionnées, mais dans PostgreSQL, cela est particulièrement vrai en raison de notre VACUUM bien-aimé. Je conseillerais de partitionner des tables commençant probablement par 100 gigaoctets. Peut-être à partir de 50. J'ai vu des tables de téraoctets non partitionnées et elles vivaient cependant sur des SSD. Mais c'est un peu trop, il vaudrait mieux les couper.

Et encore une observation: presque toutes les bases de données d'un grand volume ne sont que des archives. Des données en direct et changeantes sont rarement trouvées dans ces bases de données. Un déterminant de ce que vous avez - si l'archive, alors vous pouvez penser à la façon de l'emmener quelque part. Et, en passant, vous pouvez y accéder depuis la base de données. Ensuite, l'application n'a pas besoin d'être modifiée: rien ne changera pour elle.
Certaines de ces observations appartiennent à la catégorie «il vaut mieux être riche et en bonne santé que pauvre et malade». Souvent, tout d'abord, il existe un code hérité. Deuxièmement, quelque chose d'inattendu s'est produit, ils n'ont pas pensé à quelque chose, et il s'avère que tout n'est pas aussi beau que nous le souhaiterions. Mais néanmoins: ne soyez pas très intelligent. N'oubliez pas que si vous êtes très intelligent, vous faites probablement quelque chose de mal.
[À suivre.]