Interface
Dans
le premier article , nous avons mentionné qu'une méthode d'accès doit fournir des informations sur elle-même. Examinons la structure de l'interface de la méthode d'accès.
Propriétés
Toutes les propriétés des méthodes d'accès sont stockées dans la table "pg_am" ("am" signifie méthode d'accès). Nous pouvons également obtenir une liste des méthodes disponibles à partir de ce même tableau:
postgres=# select amname from pg_am;
amname -------- btree hash gist gin spgist brin (6 rows)
Bien que l'analyse séquentielle puisse à juste titre être référée aux méthodes d'accès, elle ne figure pas sur cette liste pour des raisons historiques.
Dans les versions 9.5 et inférieures de PostgreSQL, chaque propriété était représentée avec un champ séparé de la table "pg_am". À partir de la version 9.6, les propriétés sont interrogées avec des fonctions spéciales et sont séparées en plusieurs couches:
- Propriétés de la méthode d'accès - "pg_indexam_has_property"
- Propriétés d'un index spécifique - "pg_index_has_property"
- Propriétés des colonnes individuelles de l'index - "pg_index_column_has_property"
La couche de méthode d'accès et la couche d'index sont séparées dans une perspective d'avenir: à partir de maintenant, tous les index basés sur une méthode d'accès auront toujours les mêmes propriétés.
Les quatre propriétés suivantes sont celles de la méthode d'accès (par un exemple de "btree"):
postgres=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name) from pg_am a, unnest(array['can_order','can_unique','can_multi_col','can_exclude']) p(name) where a.amname = 'btree' order by a.amname;
amname | name | pg_indexam_has_property --------+---------------+------------------------- btree | can_order | t btree | can_unique | t btree | can_multi_col | t btree | can_exclude | t (4 rows)
- can_order.
La méthode d'accès nous permet de spécifier l'ordre de tri des valeurs lors de la création d'un index (applicable jusqu'à présent à "btree"). - can_unique
Prise en charge de la contrainte unique et de la clé primaire (applicable uniquement à "btree"). - can_multi_col.
Un index peut être construit sur plusieurs colonnes. - can_exclude
Prise en charge de la contrainte d'exclusion EXCLUDE.
Les propriétés suivantes appartiennent à un index (considérons par exemple
un index existant):
postgres=# select p.name, pg_index_has_property('t_a_idx'::regclass,p.name) from unnest(array[ 'clusterable','index_scan','bitmap_scan','backward_scan' ]) p(name);
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | t (4 rows)
- groupable.
Possibilité de réorganiser les lignes en fonction de l'index (clustering avec la commande du même nom CLUSTER). - index_scan.
Prise en charge de l'analyse d'index. Bien que cette propriété puisse sembler étrange, tous les index ne peuvent pas renvoyer les TID un par un - certains renvoient les résultats d'un seul coup et ne prennent en charge que le scan bitmap. - bitmap_scan.
Prise en charge du scan bitmap. - backward_scan.
Le résultat peut être retourné dans l'ordre inverse de celui spécifié lors de la construction de l'index.
Enfin, les propriétés de colonne sont les suivantes: postgres=# select p.name, pg_index_column_has_property('t_a_idx'::regclass,1,p.name) from unnest(array[ 'asc','desc','nulls_first','nulls_last','orderable','distance_orderable', 'returnable','search_array','search_nulls' ]) p(name);
name | pg_index_column_has_property --------------------+------------------------------ asc | t desc | f nulls_first | f nulls_last | t orderable | t distance_orderable | f returnable | t search_array | t search_nulls | t (9 rows)
- asc, desc, nulls_first, nulls_last, commandable.
Ces propriétés sont liées à l'ordre des valeurs (nous en discuterons lorsque nous atteindrons une description des index "btree"). - distance_orderable.
Le résultat peut être renvoyé dans l'ordre de tri déterminé par l'opération (applicable uniquement aux index GiST et RUM jusqu'à présent). - consigné
Une possibilité d'utiliser l'index sans accéder à la table, c'est-à-dire la prise en charge des analyses d'index uniquement. - search_array.
Prise en charge de la recherche de plusieurs valeurs avec l'expression " indexed-field IN ( list_of_constants )", qui est identique à " indexed -field = ANY ( array_of_constants )". - search_nulls.
Possibilité de rechercher par les conditions IS NULL et IS NOT NULL.
Nous avons déjà discuté de certaines propriétés en détail. Certaines propriétés sont spécifiques à certaines méthodes d'accès. Nous discuterons de telles propriétés lors de l'examen de ces méthodes spécifiques.
Classes d'opérateur et familles
En plus des propriétés d'une méthode d'accès exposées par l'interface décrite, des informations sont nécessaires pour savoir quels types de données et quels opérateurs la méthode d'accès accepte. À cette fin, PostgreSQL introduit
des concepts de
classe d' opérateur et de
famille d'opérateurs .
Une classe d'opérateurs contient un ensemble minimal d'opérateurs (et peut-être des fonctions auxiliaires) pour qu'un index manipule un certain type de données.
Une classe d'opérateur est incluse dans certaines familles d'opérateurs. De plus, une famille d'opérateurs commune peut contenir plusieurs classes d'opérateurs si elles ont la même sémantique. Par exemple, la famille "integer_ops" comprend les classes "int8_ops", "int4_ops" et "int2_ops" pour les types "bigint", "integer" et "smallint", ayant des tailles différentes mais la même signification:
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'integer_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype -------------+----------+----------- integer_ops | int2_ops | smallint integer_ops | int4_ops | integer integer_ops | int8_ops | bigint (3 rows)
Autre exemple: la famille "datetime_ops" comprend des classes d'opérateurs pour manipuler les dates (avec et sans heure):
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'datetime_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype --------------+-----------------+----------------------------- datetime_ops | date_ops | date datetime_ops | timestamptz_ops | timestamp with time zone datetime_ops | timestamp_ops | timestamp without time zone (3 rows)
Une famille d'opérateurs peut également inclure des opérateurs supplémentaires pour comparer les valeurs de différents types. Le regroupement en familles permet au planificateur d'utiliser un index pour les prédicats avec des valeurs de différents types. Une famille peut également contenir d'autres fonctions auxiliaires.
Dans la plupart des cas, nous n'avons besoin de rien savoir sur les familles et les classes d'opérateurs. Habituellement, nous créons simplement un index, en utilisant une certaine classe d'opérateur par défaut.
Cependant, nous pouvons explicitement spécifier la classe d'opérateur. Voici un exemple simple de cas où la spécification explicite est nécessaire: dans une base de données dont le classement est différent de C, un index régulier ne prend pas en charge l'opération LIKE:
postgres=# show lc_collate;
lc_collate ------------- en_US.UTF-8 (1 row)
postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ----------------------------- Seq Scan on t Filter: (b ~~ 'A%'::text) (2 rows)
Nous pouvons surmonter cette limitation en créant un index avec la classe d'opérateur "text_pattern_ops" (remarquez comment la condition dans le plan a changé):
postgres=# create index on t(b text_pattern_ops); postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ---------------------------------------------------------------- Bitmap Heap Scan on t Filter: (b ~~ 'A%'::text) -> Bitmap Index Scan on t_b_idx1 Index Cond: ((b ~>=~ 'A'::text) AND (b ~<~ 'B'::text)) (4 rows)
Catalogue système
En conclusion de cet article, nous fournissons un diagramme simplifié des tables du catalogue système qui sont directement liées aux classes et familles d'opérateurs.
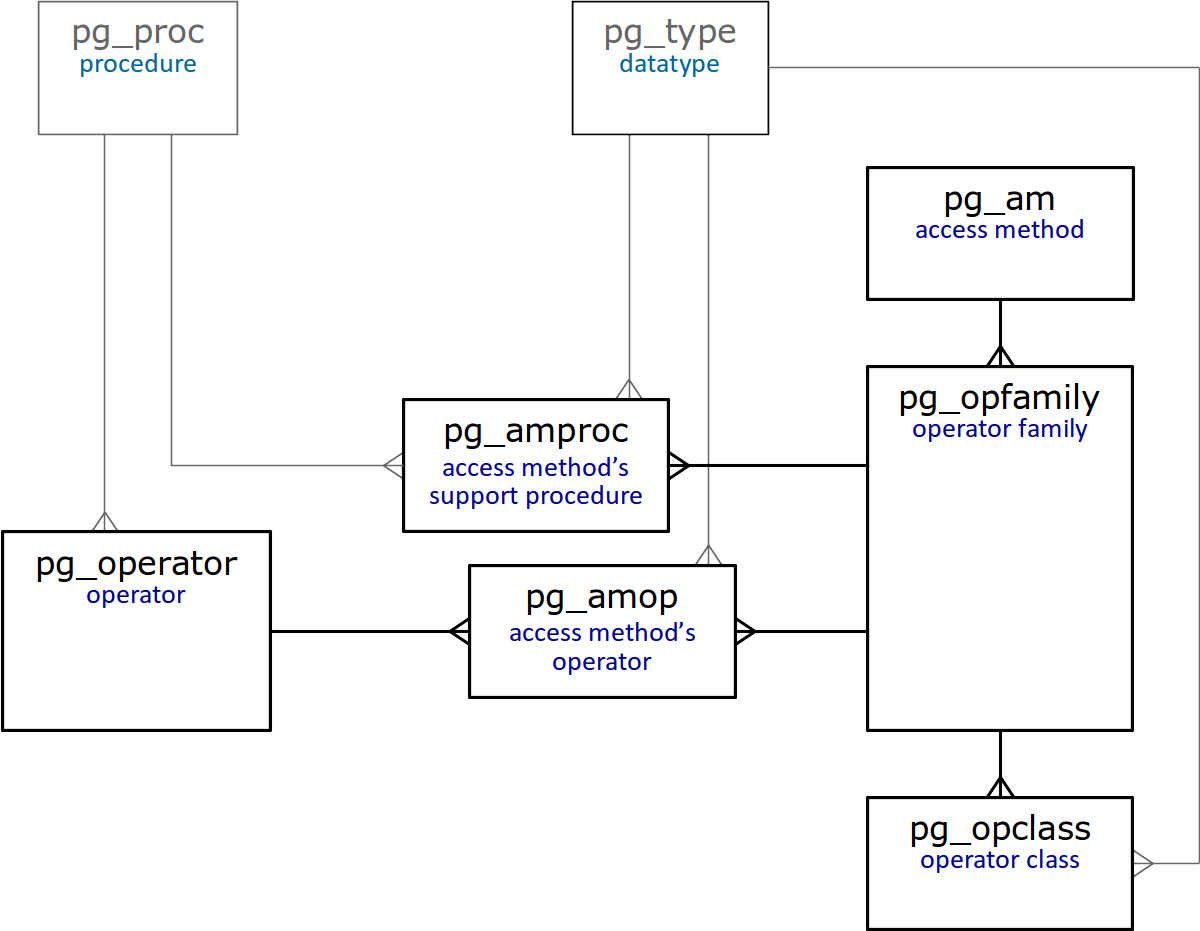
Il va sans dire que tous ces tableaux
sont décrits en détail .
Le catalogue système nous permet de trouver des réponses à un certain nombre de questions sans consulter la documentation. Par exemple, quels types de données une certaine méthode d'accès peut-elle manipuler?
postgres=# select opcname, opcintype::regtype from pg_opclass where opcmethod = (select oid from pg_am where amname = 'btree') order by opcintype::regtype::text;
opcname | opcintype ---------------------+----------------------------- abstime_ops | abstime array_ops | anyarray enum_ops | anyenum ...
Quels opérateurs une classe d'opérateurs contient-elle (et par conséquent, l'accès à l'index peut être utilisé pour une condition qui inclut un tel opérateur)?
postgres=# select amop.amopopr::regoperator from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'btree' and amop.amoplefttype = opc.opcintype;
amopopr ----------------------- <(anyarray,anyarray) <=(anyarray,anyarray) =(anyarray,anyarray) >=(anyarray,anyarray) >(anyarray,anyarray) (5 rows)
Continuez à lire .