Lorsque les participants de
HighLoad ++ sont arrivés au rapport d'
Alexander Krasheninnikov , ils espéraient entendre parler du traitement de 1 600 000 événements par seconde. Les attentes ne se sont pas réalisées ... Parce que lors de la préparation de la performance, ce chiffre a volé jusqu'à
1 800 000 - donc, sur HighLoad ++, la réalité dépasse les attentes.
Il y a 3 ans, Alexander a expliqué comment il avait construit un système évolutif de traitement des événements en temps quasi réel à Badoo. Depuis lors, il a évolué, les volumes ont augmenté dans le processus, il était nécessaire de résoudre les problèmes de mise à l'échelle et de tolérance aux pannes, et à un moment donné, des mesures radicales étaient nécessaires - un
changement dans la pile technologique .

Grâce au déchiffrement, vous apprendrez comment, dans Badoo, vous avez remplacé le pack Spark + Hadoop par ClickHouse,
économisé 3 fois le matériel et augmenté la charge 6 fois , pourquoi et par quels moyens collecter des statistiques dans le projet, puis quoi faire avec ces données.
À propos de l'orateur: Alexander Krasheninnikov (
alexkrash ) - Responsable de l'ingénierie des données chez Badoo. Il est engagé dans l'infrastructure BI, la mise à l'échelle des charges de travail et gère les équipes qui construisent l'infrastructure de traitement des données. Il aime tout ce qui est distribué: Hadoop, Spark, ClickHouse. Je suis sûr que des systèmes distribués sympas peuvent être préparés à partir d'OpenSource.
Collecte de statistiques
Si nous n'avons pas de données, nous sommes aveugles et ne pouvons pas gérer notre projet. C'est pourquoi nous avons besoin de statistiques - pour
contrôler la viabilité du projet. En tant qu'ingénieurs, nous devons nous efforcer d'améliorer nos produits et, si
vous voulez vous améliorer, les mesurer. C'est ma devise au travail. Tout d'abord, notre objectif est les avantages commerciaux. Les statistiques
fournissent des réponses aux questions des entreprises . Les métriques techniques sont des métriques techniques, mais l'entreprise est également intéressée par les indicateurs, et ils doivent également être pris en considération.
Cycle de vie des statistiques
Je définis le cycle de vie des statistiques par 4 points, dont nous discuterons chacun séparément.
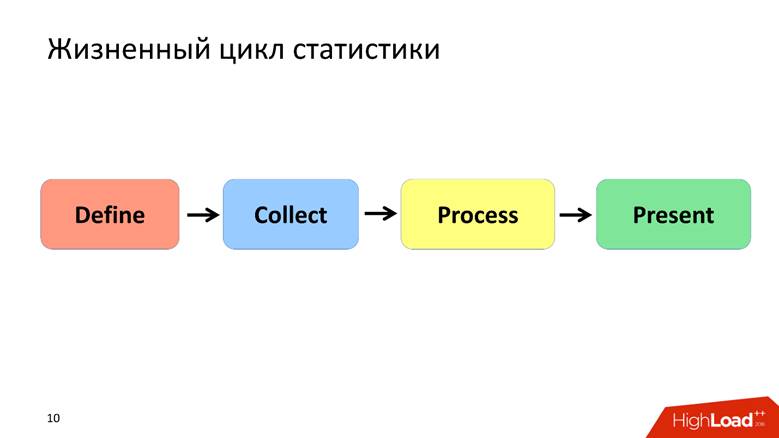
Définir la phase - Formalisation
Dans l'application, nous collectons plusieurs métriques. Tout d'abord, ce sont
des mesures commerciales . Si vous avez un service photo, par exemple, vous vous demandez combien de photos sont téléchargées par jour, par heure, par seconde. Les métriques suivantes sont
«semi-techniques» : réactivité d'une application ou d'un site mobile, travail de l'API, rapidité avec laquelle un utilisateur interagit avec un site, installation d'application, UX.
Le suivi du comportement des utilisateurs est la troisième mesure importante. Ce sont des systèmes comme Google Analytics et Yandex.Metrics. Nous avons notre propre système de suivi cool, dans lequel nous investissons beaucoup.
Dans le processus de travail avec les statistiques, de nombreux utilisateurs sont impliqués - ce sont des développeurs et des analyses commerciales. Il est important que tout le monde parle la même langue, vous devez donc être d'accord.
Il est possible de négocier verbalement, mais c'est beaucoup mieux lorsque cela se produit formellement - dans une structure claire des événements.
Formaliser la structure des événements commerciaux, c'est lorsque le développeur dit combien d'inscriptions nous avons, l'analyste comprend qu'il a reçu des informations non seulement sur le nombre total d'inscriptions, mais aussi par pays, sexe et autres paramètres. Et toutes ces informations sont formalisées et sont
dans le domaine public pour tous les utilisateurs de l'entreprise . L'événement a une structure typée et une description formelle. Par exemple, nous stockons ces informations au format
Protocol Buffers .
Description de l'événement "Inscription":
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 userid =1; required Gender usergender = 2; required int32 time =3; required int32 countryid =4; }
L'événement d'enregistrement contient des informations sur l'
utilisateur, le champ, l'heure de l' événement et le
pays d' enregistrement de l'utilisateur. Ces informations sont disponibles pour les analystes et, à l'avenir, l'entreprise comprend ce que nous collectons.
Pourquoi ai-je besoin d'une description formelle?
Une description formelle est l'
uniformité pour les développeurs, les analystes et le service produit. Ensuite, ces informations imprègnent la description de la logique métier de l'application. Par exemple, nous avons un système interne pour décrire les processus métier et c'est dans un écran que nous avons une nouvelle fonctionnalité.
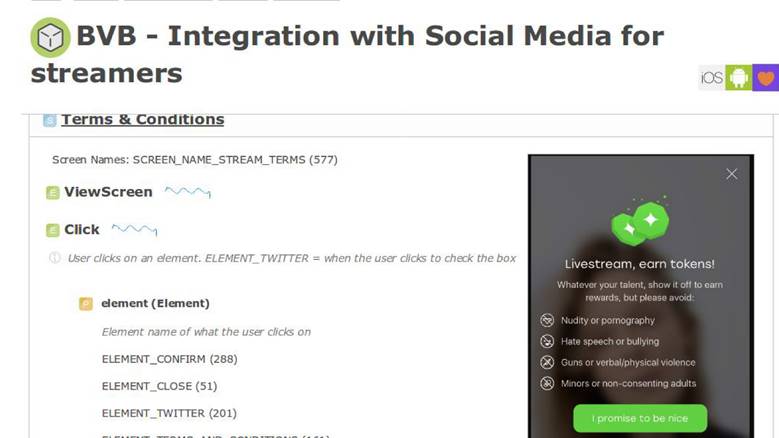
Dans le
document des exigences du
produit, il y a une section avec l'instruction que lorsque l'utilisateur interagit avec l'application de cette manière, nous devons envoyer un événement avec exactement les mêmes paramètres. Par la suite, nous serons en mesure de valider le fonctionnement de nos fonctionnalités et de les mesurer correctement. Une description formelle nous permet de mieux comprendre comment enregistrer ces données dans une base de données: NoSQL, SQL ou autres. Nous avons
un schéma de données , et c'est cool.
Dans certains systèmes analytiques fournis en tant que service, il n'y a que 10 à 15 événements dans le stockage secret. Dans notre pays, ce nombre a augmenté de plus de 1000 et ne va pas s'arrêter -
il est impossible de vivre sans un seul registre .
Définir le résumé de la phase
Nous avons décidé que les
statistiques - c'est important et
décrit un certain sujet - c'est bien, vous pouvez vivre.
Phase de collecte - collecte de données
Nous avons décidé de construire le système de sorte que lorsqu'un événement commercial se produit - enregistrement, envoi d'un message, comme - en même temps que l'enregistrement de ces informations, nous envoyions séparément un certain événement statistique.
Dans le code, les statistiques sont envoyées simultanément avec l'événement commercial.
Il est traité complètement indépendamment des magasins de données dans lesquels l'application s'exécute, car le
flux de données passe par un pipeline de traitement distinct.Description via EDL:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 user_id =1; required Gender user_gender = 2; required int32 time =3; required int32 country_id =4; }
Nous avons une description de l'événement d'inscription. Une API est générée automatiquement, accessible aux développeurs à partir de code, qui en 4 lignes vous permet d'envoyer des statistiques.
API basée sur EDL:
\EDL\Event\Regist ration::create() ->setUserId(100500) ->setGender(Gender: :MALE) ->setTime(time()) ->send();
Livraison d'événement
Ceci est notre système externe. Nous le faisons parce que nous avons des services incroyables qui fournissent une API pour travailler avec des données photo, sur autre chose. Ils stockent tous des données dans des bases de données innovantes, telles que Aerospike et CockroachDB.
Lorsque vous avez besoin de créer une sorte de rapport, vous n'avez pas à vous battre: "Les gars, combien avez-vous et combien?" - Toutes les données sont envoyées dans un flux séparé. Convoyeur de traitement - système externe. Dans le contexte de l'application, nous délions toutes les données du référentiel de logique métier et les envoyons vers un pipeline séparé.
La phase de collecte suppose la disponibilité des serveurs d'applications. Nous avons ce PHP.
Le transport
Il s'agit d'un sous-système qui nous permet d'envoyer à un autre pipeline ce que nous avons fait à partir du contexte d'application. Le transport est sélectionné uniquement selon vos besoins, en fonction de la situation du projet.
Le transport a des caractéristiques, et le premier est
les garanties de livraison. Caractéristiques du transport: au moins une fois, exactement une fois, vous choisissez des statistiques pour vos tâches, en fonction de l'importance de ces données. Par exemple, pour les systèmes de facturation, il est inacceptable que les statistiques montrent plus de transactions qu'il n'y en a - c'est de l'argent, ce n'est pas possible.
Le deuxième paramètre concerne les
liaisons pour les langages de programmation. Nous devons en quelque sorte interagir avec le transport, il est donc sélectionné en fonction de la langue dans laquelle le projet est écrit.
Le troisième paramètre est l'
évolutivité. Comme nous parlons de millions d'événements par seconde, il serait bon de garder à l'esprit la future évolutivité.
Il existe de nombreuses options de transport: applications RDBMS, Flume, Kafka ou LSD. Nous utilisons du
LSD - c'est notre façon spéciale.
Démon de streaming en direct
Le LSD n'a rien à voir avec les substances interdites. Il s'agit d'un
démon de streaming très rapide et dynamique qui ne fournit aucun agent pour y écrire. Nous pouvons le régler, nous avons l'
intégration avec d'autres systèmes : HDFS, Kafka - nous pouvons réorganiser les données envoyées. Le LSD n'a pas d'appel réseau sur INSERT et vous pouvez y contrôler la topologie du réseau.
Plus important encore, c'est
OpenSource de Badoo - il n'y a aucune raison de ne pas faire confiance à ce logiciel.
Si c'était un démon parfait, au lieu de Kafka, nous discuterions du LSD à chaque conférence, mais chaque LSD a une mouche dans la pommade. Nous avons nos propres limites avec lesquelles nous sommes à l'aise: nous n'avons
pas de support de réplication en LSD et il a
au moins une garantie de livraison. En outre, pour les transactions monétaires, ce n'est pas le moyen de transport le plus approprié, mais vous devez généralement communiquer avec de l'argent exclusivement via des bases de données "acides" - prenant en charge
ACID .
Récapitulatif de la phase de collecte
Sur la base des résultats de la série précédente, nous avons reçu une
description formelle des données, généré une excellente
API pratique
pour les répartiteurs d'événements , et trouvé comment
transférer ces données
du contexte d'application vers un pipeline séparé . Déjà pas mal, et nous approchons de la prochaine phase.
Processus de phase - Traitement des données
Nous avons collecté des données sur les inscriptions, téléchargé des photos, des sondages - que faire de tout cela? À partir de ces données, nous voulons obtenir des
graphiques avec une longue histoire et
des données brutes . Les graphiques comprennent tout - vous n'avez pas besoin d'être un développeur pour comprendre à partir de la courbe que les revenus de l'entreprise augmentent. Nous utilisons des données brutes pour les rapports en ligne et ad-hoc. Pour les cas plus complexes, nos analystes souhaitent effectuer des requêtes analytiques sur ces données. Cela et cette fonctionnalité nous sont nécessaires.
Graphiques
Les graphiques se présentent sous plusieurs formes.
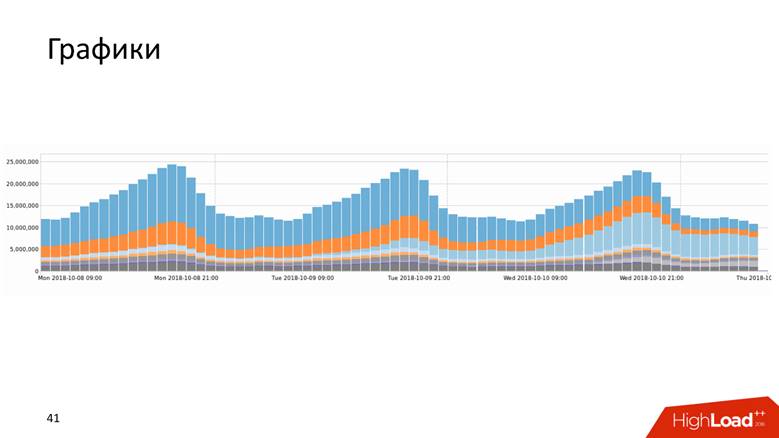
Ou, par exemple, un graphique avec un historique qui montre les données sur 10 ans.
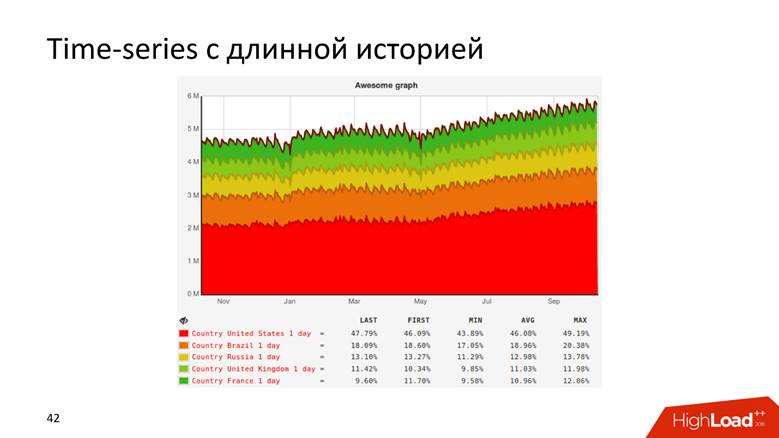
Les graphiques sont même comme ça.
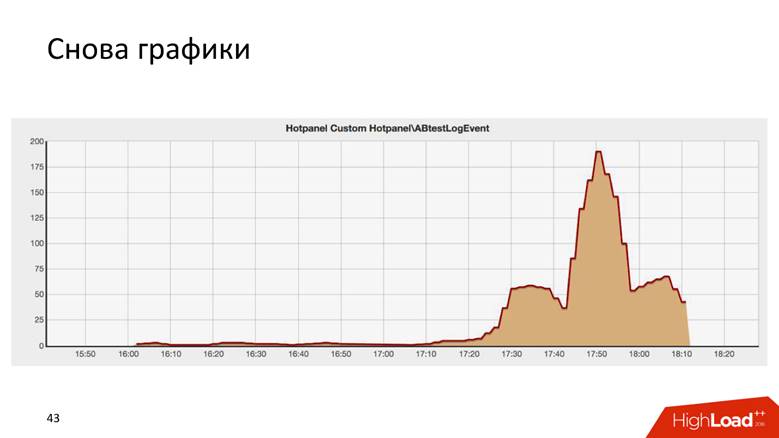
C'est le résultat d'un test AB, et il est étonnamment similaire au bâtiment Chrysler à New York.
Il existe deux façons de dessiner un graphique: une
requête de données brutes et une
série chronologique . Les deux approches présentent des inconvénients et des avantages sur lesquels nous ne nous attarderons pas en détail. Nous utilisons une
approche hybride : nous nous tenons à l'écart des données brutes pour les rapports opérationnels et des séries chronologiques pour le stockage à long terme. Le second est calculé à partir du premier.
Comment nous sommes passés à 1,8 million d'événements par seconde
C'est une longue histoire - des millions de RPS n'arrivent pas en une journée. Badoo est une entreprise avec une décennie d'histoire, et nous pouvons dire que le système de traitement des données a grandi avec l'entreprise.
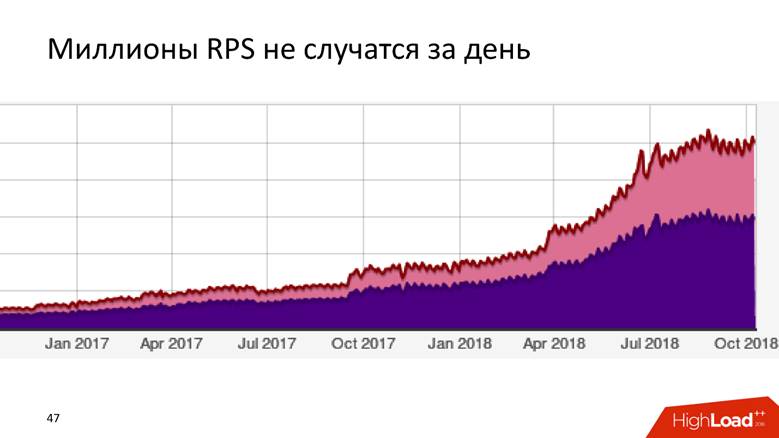
Au début, nous n'avions rien. Nous avons commencé à collecter des données - il s'est avéré
5000 événements par seconde. Un hôte MySQL et rien d'autre! N'importe quel SGBD relationnel fera face à cette tâche, et il sera à l'aise avec cela: vous aurez la transactionnalité - mettez les données, recevez des requêtes - tout fonctionne bien et bien. Nous avons donc vécu un certain temps.
À un moment donné, un partage fonctionnel s'est produit: les données d'enregistrement - ici et sur les photos - là. Nous avons donc vécu jusqu'à
200 000 événements par seconde et avons commencé à utiliser diverses approches combinées: pour stocker non pas des données brutes, mais
agrégées , mais jusqu'à présent dans la base de données relationnelle. Nous stockons des compteurs, mais l'essence de la plupart des bases de données relationnelles est telle qu'il sera alors impossible d'exécuter une
requête DISTINCT sur ces données - le modèle algébrique des compteurs ne permet pas de calculer DISTINCT.
Chez Badoo, nous avons la devise
«Force imparable» . Nous n'allions pas nous arrêter et grandir davantage. Au moment où nous avons franchi le seuil des
200 000 événements par seconde , nous avons décidé de créer une description formelle, dont j'ai parlé plus haut. Avant cela, il y avait du chaos, et maintenant nous avons un registre structuré des événements: nous avons commencé à faire évoluer le système,
Hadoop connecté , toutes les données sont
entrées dans les
tables Hive.Hadoop est un énorme progiciel, système de fichiers. Pour l'informatique distribuée, Hadoop dit: «Mettez les données ici, je vous laisse effectuer des requêtes analytiques sur elles.» Nous avons donc fait - écrit un
calcul régulier de tous les graphiques - cela s'est bien passé. Mais les graphiques sont utiles lorsqu'ils sont mis à jour rapidement - une fois par jour, regarder une mise à jour des graphiques n'est pas si amusant. Si nous déployions quelque chose conduisant à une erreur fatale sur la production, nous aimerions voir le graphique tomber immédiatement, et pas tous les deux jours. Par conséquent, l'ensemble du système a commencé à se dégrader après un certain temps. Cependant, nous avons réalisé qu'à ce stade, vous pouvez vous en tenir à la pile technologique sélectionnée.
Pour nous, Java était nouveau, nous l'avons aimé et nous avons compris ce qui pouvait être fait différemment.
Au stade de 400 000 à
800 000 événements par seconde , nous avons remplacé Hadoop dans sa forme la plus pure et Hive, car l'exécuteur des requêtes analytiques, avec
Spark Streaming , a écrit une
carte générique / réduire et un calcul incrémentiel des métriques. Il y a 3 ans, j'ai
raconté comment nous l'avons fait. Ensuite, il nous a semblé que Spark vivrait éternellement, mais la vie en a décidé autrement - nous avons rencontré les limites de Hadoop. Peut-être que si nous avions d'autres conditions, nous continuerions à vivre avec Hadoop.
Un autre problème, en plus du calcul des graphiques sur Hadoop, était les incroyables requêtes SQL à quatre étages qui étaient conduites par les analystes, et les graphiques n'étaient pas mis à jour rapidement. Le fait est qu'il y a un travail assez délicat avec le traitement des données opérationnelles, de sorte qu'il est en temps réel, rapide et cool.
Badoo est desservi par deux centres de données situés des deux côtés de l'océan Atlantique - en Europe et en Amérique du Nord. Pour créer un rapport unifié, vous devez envoyer des données d'Amérique vers l'Europe. C'est dans le centre de données européen que nous conservons toutes les statistiques statistiques, car il y a plus de puissance de calcul.
Un aller -
retour entre les centres de données d'environ
200 ms - le réseau est assez délicat - faire une demande à un autre contrôleur de domaine n'est pas la même chose que d'aller au rack suivant.
Lorsque nous avons commencé à formaliser les événements et les développeurs, et que les chefs de produit se sont impliqués, tout le monde a tout aimé - il y avait juste une
croissance explosive des événements . À cette époque, il était temps d'acheter du fer dans le cluster, mais nous ne voulions pas vraiment le faire.
Lorsque nous avons dépassé le pic de
800 000 événements par seconde , nous avons découvert ce que Yandex avait téléchargé sur OpenSource
ClickHouse et
avons décidé de l'essayer.
Ils ont rempli un train de cônes pendant qu'ils essayaient de faire quelque chose, et en conséquence, quand tout a fonctionné, ils ont fait un petit buffet au sujet du premier million d'événements. Probablement, ClickHouse aurait pu terminer le rapport.
Prenez ClickHouse et vivez avec.
Mais ce n'est pas intéressant, nous allons donc continuer à parler de traitement des données.
Clickhouse
ClickHouse est un battage médiatique des deux dernières années et n'a pas besoin d'être introduit: seulement dans HighLoad ++ en 2018, je me souviens d'
environ cinq rapports à ce sujet, ainsi que de séminaires et de réunions.
Cet outil est conçu pour résoudre exactement les tâches que nous nous fixons. Il existe des
mises à jour et des puces en
temps réel que nous avons reçues à un moment donné de Hadoop: réplication, partitionnement. Il n'y avait aucune raison de ne pas essayer ClickHouse, car ils comprenaient qu'avec l'implémentation sur Hadoop, nous avions déjà cassé le fond. L'outil est cool, et la documentation est généralement du feu - j'y ai écrit moi-même, j'aime vraiment tout, et tout est super. Mais nous avons dû résoudre un certain nombre de problèmes.
Comment déplacer l'intégralité du flux d'événements dans ClickHouse? Comment combiner les données de deux centres de données? Du fait que nous sommes venus aux administrateurs et avons dit: "Les gars, installons ClickHouse", ils ne rendront pas le réseau deux fois plus épais, et le retard est moitié moins. Non, le réseau est toujours aussi mince et petit que le premier salaire.
Comment conserver les résultats ? Chez Hadoop, nous avons compris comment dessiner des graphiques - mais comment le faire sur la ClickHouse magique? La baguette magique n'est pas incluse.
Comment fournir des résultats au stockage de séries chronologiques?
Comme mon professeur à l'institut l'a dit, considérez 3 schémas de données: stratégique, logique et physique.
Schéma de stockage stratégique
Nous avons
2 centres de données . Nous avons appris que ClickHouse ne sait rien des contrôleurs de domaine et nous avons simplement ajouté le cluster dans chaque contrôleur de domaine. Maintenant, les
données ne transitent pas par le câble transatlantique - toutes les données qui se sont produites dans le contrôleur de domaine sont stockées localement dans son cluster. Lorsque nous voulons faire une demande sur les données combinées, par exemple, pour savoir combien d'inscriptions sont dans les deux contrôleurs de domaine, ClickHouse nous donne cette opportunité. Faible latence et disponibilité pour la demande - juste un chef-d'œuvre!
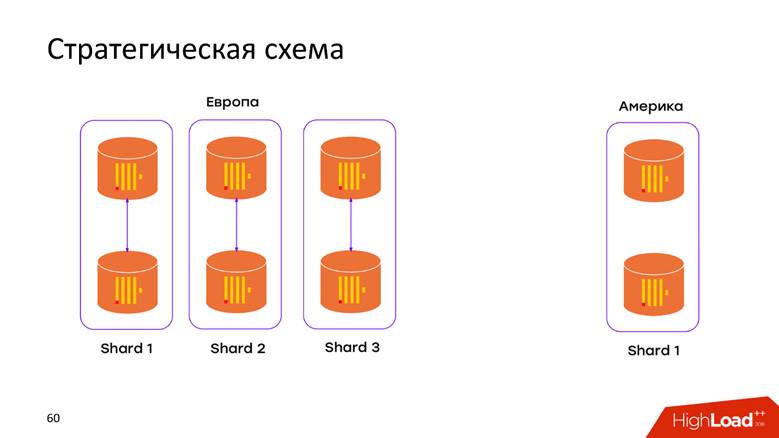
Schéma de stockage physique
Encore une fois, des questions: comment nos données entreront-elles dans le modèle relationnel ClickHouse, que faire pour ne pas perdre la réplication et le sharding? Tout est largement décrit dans la
documentation ClickHouse , et si vous avez plusieurs serveurs, vous rencontrerez cet article. Par conséquent, nous ne nous pencherons pas sur ce qui est dans le manuel: réplications, partitionnement et requêtes sur toutes les données sur les fragments.
Logique de stockage
Le diagramme logique est le plus intéressant. Dans un pipeline, nous traitons des événements hétérogènes. Cela signifie que nous avons un
flux d'événements hétérogènes : enregistrement, voix, téléchargement de photos, mesures techniques, suivi du comportement des utilisateurs - tous ces événements ont
des attributs complètement
différents . Par exemple, j'ai regardé l'écran sur un téléphone mobile - j'ai besoin d'un identifiant d'écran, j'ai voté pour quelqu'un - vous devez comprendre si le vote était pour ou contre. Tous ces événements ont des attributs différents, différents graphiques sont dessinés dessus, mais tout cela doit être traité dans un seul pipeline. Comment le mettre dans le modèle ClickHouse?
Approche n ° 1 - par table d'événements. Cette première approche, nous avons extrapolé à partir de l'expérience acquise avec MySQL - nous avons créé une
tablette pour chaque événement dans ClickHouse. Cela semble assez logique, mais nous avons rencontré un certain nombre de difficultés.
Nous n'avons aucune restriction quant au fait que l'événement changera de structure lorsque la version d'aujourd'hui sera publiée. Ce patch peut être réalisé par n'importe quel développeur. Le schéma est généralement modifiable dans toutes les directions. Le seul
champ obligatoire est l'
événement d'horodatage et ce qu'était l'événement. Tout le reste change à la volée et, en conséquence, ces plaques doivent être modifiées. ClickHouse a la capacité d'effectuer
ALTER sur un cluster , mais c'est une procédure délicate délicate qui est difficile à automatiser pour le faire fonctionner en douceur. Par conséquent, c'est un inconvénient.
Nous avons plus d'un millier d'événements différents, ce qui nous donne un
taux d'insertion élevé par machine - nous enregistrons constamment toutes les données dans mille tableaux. Pour ClickHouse, il s'agit d'un anti-motif. Si Pepsi a le slogan - "Live in big sips", alors ClickHouse -
"Live in big batch" . Si cela n'est pas fait, la réplication est étouffée, ClickHouse refuse d'accepter de nouvelles insertions - un schéma désagréable.
Approche n ° 2 - une large table . Des hommes sibériens ont tenté de glisser la tronçonneuse sur le rail et d'appliquer un modèle de données différent. Nous faisons un tableau avec
mille colonnes , où chaque événement a des colonnes réservées à ses données. Nous obtenons une énorme
table clairsemée - heureusement, cela ne va pas au-delà de l'environnement de développement, car dès les premiers inserts, il est devenu clair que le schéma est absolument mauvais, et nous ne le ferons pas.
Mais je veux toujours utiliser un produit logiciel aussi cool, un peu plus pour terminer - et ce sera ce dont vous avez besoin.
Approche n ° 3 - tableau générique. Nous avons une énorme table dans laquelle nous stockons les données dans des tableaux, car ClickHouse prend en charge
les types de données non scalaires . Autrement dit, nous commençons une colonne dans laquelle les noms des attributs sont stockés, et une colonne distincte avec un tableau dans lequel les valeurs des attributs sont stockées.
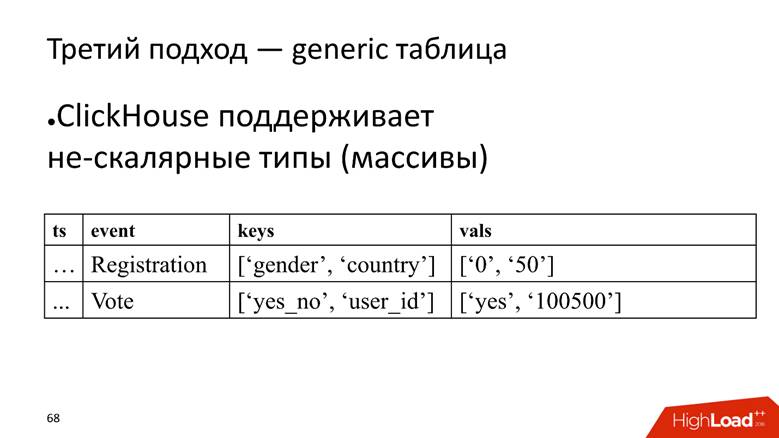
ClickHouse ici remplit très bien sa tâche. Si nous n'avions qu'à insérer des données, nous serions probablement extirper 10 fois de plus dans l'installation actuelle.
Cependant, la mouche dans la pommade est qu'elle est également un anti-modèle pour ClickHouse -
pour stocker des tableaux de chaînes . C'est mauvais car les tableaux de lignes
occupent plus d'espace disque - ils rétrécissent moins que les colonnes simples et sont
plus difficiles à traiter . Mais pour notre tâche, nous fermons les yeux sur cela, car les avantages l'emportent.
Comment faire SELECT à partir d'une telle table? Notre tâche consiste à compter les inscriptions groupées par sexe. Vous devez d'abord trouver dans un tableau quelle position correspond à la colonne genre, puis monter dans une autre colonne avec cet index et obtenir les données.
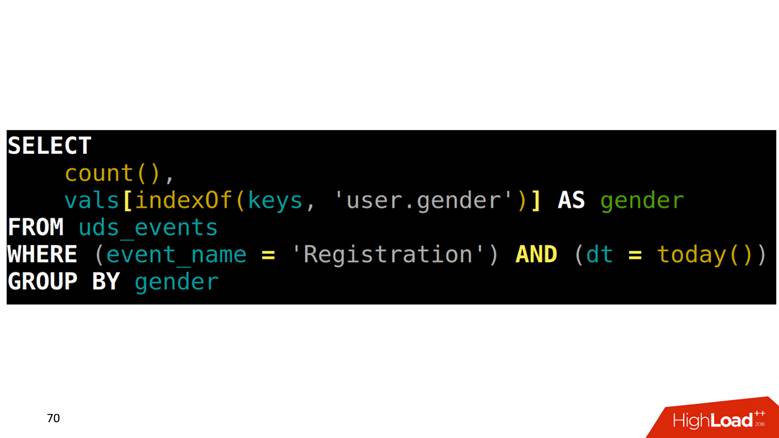
Comment dessiner des graphiques sur ces données
Étant donné que tous les événements sont décrits, ils ont une structure stricte, nous formons une requête SQL à quatre étages pour chaque type d'événement, l'exécutons et enregistrons les résultats dans une autre table.
Le problème est que pour dessiner deux points adjacents sur le graphique, vous devez
numériser la table entière . Exemple: nous regardons l'inscription par jour. Cet événement va de la première ligne à l'avant-dernière. Numérisé une fois - excellent. Après 5 minutes, nous voulons dessiner un nouveau point sur le graphique - encore une fois, nous analysons la plage de données qui croise avec l'analyse précédente, et ainsi de suite pour chaque événement. Cela semble logique, mais ça n'a pas l'air génial.
De plus, lorsque nous prenons certaines lignes, nous devons également
lire les résultats sous agrégation . Par exemple, il est un fait que le serviteur de Dieu était enregistré en Scandinavie et était un homme, et nous devons calculer les statistiques sommaires: combien d'inscriptions, combien d'hommes, combien d'entre eux sont des personnes et combien sont de Norvège. Cela s'appelle en termes de bases de données analytiques
ROLLUP, CUBE et
GROUPING SETS - transformez une ligne en plusieurs.
Comment traiter
Heureusement, ClickHouse dispose d'un outil pour résoudre ce problème, à savoir l'
état sérialisé des fonctions d'agrégation . Cela signifie que vous pouvez numériser une fois une donnée et enregistrer ces résultats. Ceci est une
fonctionnalité qui tue . Il y a 3 ans, nous avons fait exactement cela sur Spark et Hadoop, et c'est cool qu'en parallèle avec nous, les meilleurs esprits Yandex aient implémenté un analogue dans ClickHouse.
Demande lente
Nous avons une demande lente - compter les utilisateurs uniques pour aujourd'hui et hier.
SELECT uniq(user_id) FROM table WHERE dt IN (today(), yesterday())
Dans le plan physique, nous pouvons faire SELECT pour l'état d'hier, obtenir sa représentation binaire, l'enregistrer quelque part.
SELECT uniq(user_id), 'xxx' AS ts, uniqState(user id) AS state FROM table WHERE dt IN (today(), yesterday())
Pour aujourd'hui, nous modifions simplement la condition qu'il sera aujourd'hui:
'yyy' AS ts et
WHERE dt = today() et horodatage que nous appellerons «xxx» et «yyy». , , 2 .
SELECT uniqMerge(state) FROM ageagate_table WHERE ts IN ('xxx', 'yyy')
:
, - .
. , , , , ClickHouse, : «, ! , !»
, , .
, . . — SQL-, . , , .

, - time series. : , , , time series.
time series : , , timestamp . , , . . , , , — , . , , ClickHouse -, , .
, , ClickHouse:
— « », — .
time series 2 , 20 20-80 . . ClickHouse
GraphiteMergeTree , time series, .
8 ClickHouse , 6 - , 2 : 2 — , .
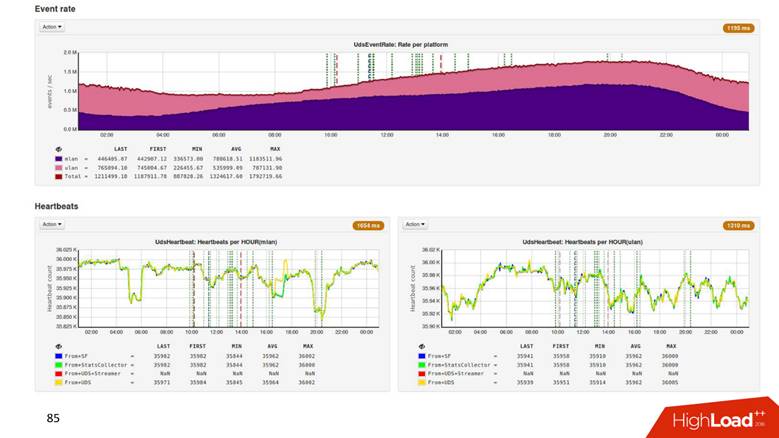
1.8 . ,
500 . , 1,8 , 500 ! .
Hadoop
2 . .
3 , CPU —
4 . , .
Process
, , , . , , ClickHouse 3 000 . , , , overkill.
, , . ClickHouse,
. , , , . , 8 3–4 . — .
Present —
, ? time series,
time series , , , .
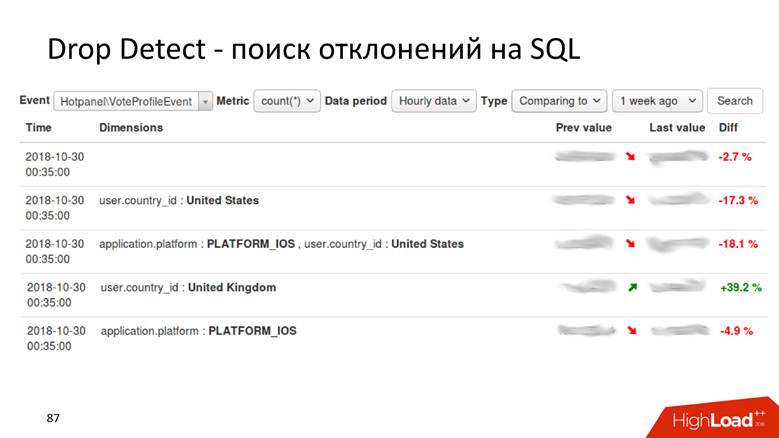
 Drop Detect — SQL
Drop Detect — SQL : SQL- , , .
 Anomaly Detection
Anomaly Detection — . , , 2% , — 40, , , , .
— , , - , Anomaly Detection.
Anomaly Detection
, time series . : , , . time series
. , , . ,
drop detection — , .
UI.
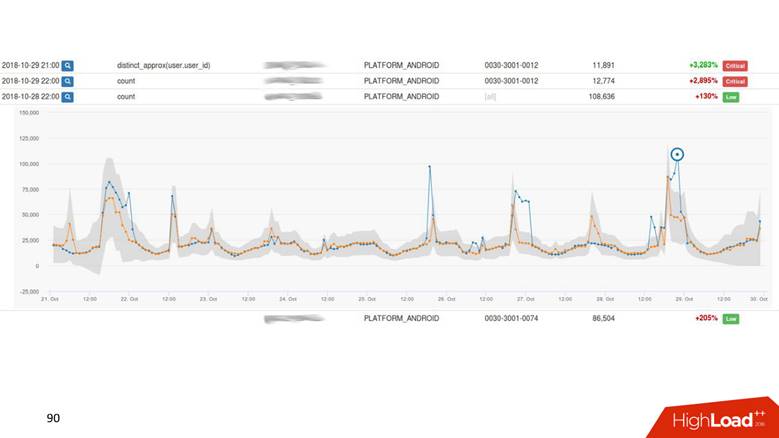
. - , — . -, .
Present
, ,
.
, : 1000 — alarm, 0 — alarm. .
Anomaly Detection , . Anomaly Detection
Exasol , ClickHouse. Anomaly Detection 2 , .
, , 4 .
,
, , . ,
, . ,
.
HighLoad++ , HighLoad++ - . , , :)
, PHP Russia , , . , , , 1,8 /, , 1 .